Overview
Amazon Web Services (AWS) offers multiple messaging and streaming services, with Amazon Kinesis and Amazon Simple Queue Service (SQS) being two of the most widely used options. While both facilitate data movement between application components, they serve fundamentally different purposes and excel in different scenarios. This comprehensive comparison explores their key differences, use cases, and technical considerations.
Before diving into the detailed comparison, the key finding is that Kinesis is optimized for real-time, high-volume data streaming with multiple consumers, while SQS excels at reliable message queuing for decoupling application components with simpler operational requirements.
Core Concepts and Architecture
Amazon Kinesis
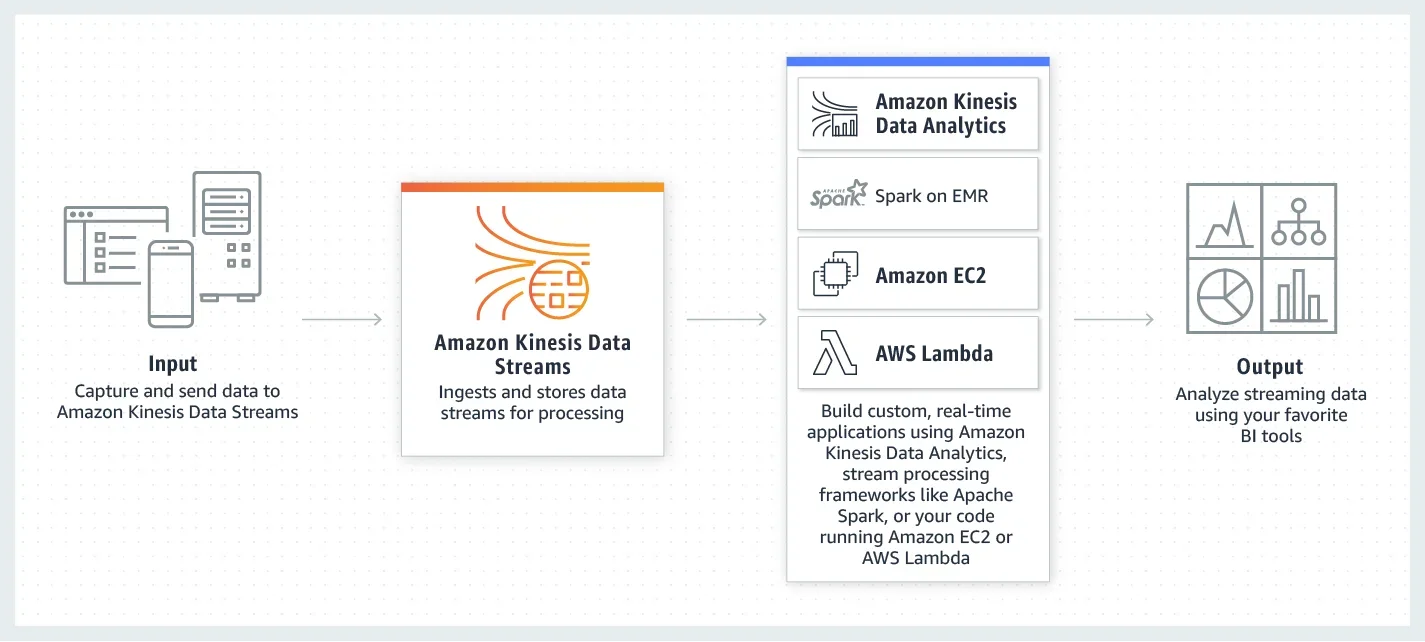
Kinesis is a platform for streaming data on AWS, allowing real-time processing of high-volume data streams. It's built on the concept of persistent data streams composed of shards, which represent the base throughput unit.
Key components include:
-
Data Streams : Core service for capturing and storing streaming data
-
Shards : Base throughput units (1MB/sec input, 2MB/sec output per shard)
-
Records : Data units with partition keys for distribution across shards
-
Retention : Data persists for 24 hours by default, configurable up to 365 days
Amazon SQS
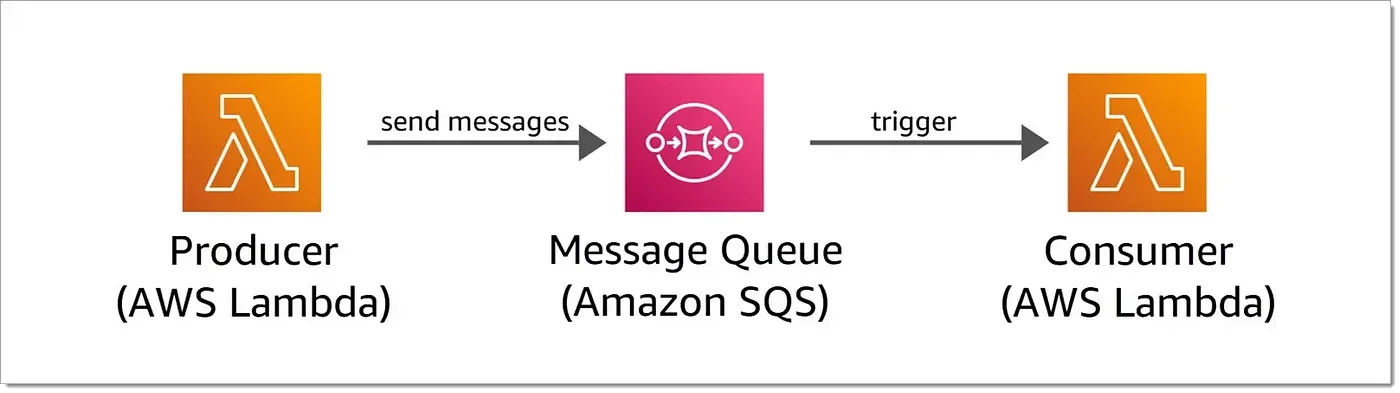
SQS is a fully managed message queuing service designed to decouple and scale microservices, distributed systems, and serverless applications. It provides a simple queue model with guaranteed at-least-once delivery.
Key components include:
-
Queues : Standard (high throughput) or FIFO (ordered delivery)
-
Messages : Individual data units (up to 256KB each)
-
Visibility Timeout : Period during which messages are invisible after being retrieved
-
Retention : Messages persist up to 4 days by default, configurable from 1 minute to 14 days
Key Differences
Purpose and Design Philosophy
| Aspect | Kinesis | SQS |
|---|---|---|
| Primary Purpose | Real-time data streaming and analytics | Message queuing and application decoupling |
| Design Focus | High-volume streaming data processing | Reliable message delivery between components |
| Processing Model | Stream processing with multiple consumers | Queue processing with individual consumers |
| Data Lifecycle | Persistent with configurable retention | Deleted after successful processing |
Kinesis is primarily designed for real-time data streaming applications that need to process and analyze large volumes of continuous data. SQS, on the other hand, focuses on reliable message queuing to decouple application components and ensure message delivery.
Data Model and Consumption Patterns
Kinesis maintains data streams that can be read by multiple consumers simultaneously, allowing for different applications to process the same data independently. With SQS, each message is typically processed by a single consumer and then deleted from the queue.
Message Ordering and Delivery Guarantees
Kinesis preserves the ordering of records at the shard level, meaning records with the same partition key will be processed in order. SQS offers two queue types:
-
Standard queues : High throughput with at-least-once delivery but no guaranteed order
-
FIFO queues : Exactly-once processing with guaranteed ordering but lower throughput
Scalability Characteristics
| Feature | Kinesis | SQS |
|---|---|---|
| Scaling Model | Manual provisioning or on-demand | Fully automatic |
| Throughput Limits | 1MB/s in, 2MB/s out per shard | 3,000 msgs/sec standard, 30,000 msgs/sec high throughput |
| Maximum Message Size | 1MB | 256KB |
| Operational Overhead | Higher (shard management) | Lower (fully managed) |
Kinesis requires explicit capacity planning through shard provisioning, whereas SQS scales automatically to match demand. However, Kinesis can achieve higher overall throughput with appropriate shard allocation.
Use Cases
When to Use Kinesis
-
Real-time Analytics : Processing streaming data for immediate insights
-
IoT Data Processing : Handling large-scale data from IoT devices
-
Log and Event Data Collection : Centralized collection of logs and events
-
Clickstream Analysis : Processing website user activity in real-time
-
Multiple Consumer Applications : When multiple applications need to process the same data
When to Use SQS
-
Application Decoupling : Separating components of distributed applications
-
Task Queues : Managing job processing and workload distribution
-
Batch Processing : Queuing items for batch processing workflows
-
Microservice Communication : Reliable messaging between microservices
-
Load Leveling : Smoothing out traffic spikes to backend systems
Hybrid Approaches
Some architectures benefit from using both services together:
-
Using Kinesis for initial high-volume data capture and SQS for specific processing tasks
-
Implementing Kinesis for real-time processing and SQS for task distribution to workers
Implementation Details
Configuration and Management
Kinesis Configuration
# AWS CLI example for creating a Kinesis stream
aws kinesis create-stream --stream-name MyDataStream --shard-count 5Considerations:
-
Shard count determines throughput capacity and cost
-
Partition key design affects data distribution across shards
-
Enhanced fan-out for high-demand consumers requires explicit configuration
-
Consumer applications often use Kinesis Client Library (KCL) with DynamoDB for checkpointing
SQS Configuration
# AWS CLI example for creating an SQS queue
aws sqs create-queue --queue-name MyQueue --attributes DelaySeconds=0,MaximumMessageSize=262144Considerations:
-
Queue type selection (Standard vs. FIFO) based on ordering requirements
-
Appropriate visibility timeout to prevent duplicate processing
-
Dead-letter queue configuration for handling failed message processing
-
Message retention period based on application requirements
Integration with AWS Ecosystem
Kinesis Integrations
Kinesis integrates seamlessly with many AWS services:
-
Lambda : For serverless stream processing
-
Firehose : For delivery to S3, Redshift, Elasticsearch, or Splunk
-
Analytics : For SQL queries against streaming data
-
Data Warehouse Services : Direct integration with Redshift and S3
SQS Integrations
SQS works well with:
-
Lambda : Direct invocation when messages arrive
-
EC2/ECS : For traditional worker patterns
-
Step Functions : For complex workflows
-
EventBridge : For event-driven architectures
Best Practices
Kinesis Best Practices
-
Use shard-level metrics to monitor performance and identify hotspots
-
Monitor IteratorAge metric to prevent data loss from expired iterators
-
Implement proper exception handling for "poison messages" that can cause batch failures
-
Design partition keys to distribute data evenly across shards
-
Consider enhanced fan-out for high-throughput consumers
SQS Best Practices
-
Configure appropriate visibility timeout based on expected processing time
-
Implement dead-letter queues to capture and analyze failed messages
-
Use batch operations (SendMessageBatch, ReceiveMessage with MaxNumberOfMessages) for efficiency
-
Implement exponential backoff for handling throttling conditions
-
Consider long polling to reduce empty responses and API calls
Cost and Comparison
Pricing and Cost Optimization
| Aspect | Kinesis | SQS |
|---|---|---|
| Pricing Model | Pay per shard-hour or on-demand | Pay per million requests |
| Small Volume Cost | Higher cost floor | More cost-effective |
| Large Volume Cost | More efficient at very high throughput | Can become expensive at extreme scales |
| Cost Estimation | Based on shard count and data volume | Based on request count and retention |
At small data volumes (1GB/day), SQS is significantly less expensive ($0.20/month vs. $10.82/month for Kinesis). However, as volume increases to 1TB/day, Kinesis becomes more cost-effective ($158/month vs. $201/month for SQS).
Comparison with Alternative Solutions
Kinesis vs. Confluent (Kafka)
| Aspect | Kinesis | Confluent |
|---|---|---|
| Focus | Streaming data service | Complete streaming platform |
| Data Model | Streams & Shards | Distributed commit logs (topics) |
| Retention | Up to 365 days | Unlimited potential retention |
| Ecosystem | AWS services integration | Rich connector ecosystem |
| Management | Fully managed by AWS | Self-managed or Confluent Cloud |
Confluent offers greater flexibility and unlimited retention compared to Kinesis' maximum 365-day retention. However, Kinesis provides tighter integration with AWS services and lower operational overhead.
Kinesis vs. Redpanda
Redpanda offers higher performance than Kinesis with fewer resources due to its C++ foundation and efficient design. It excels in self-hosted environments with three times fewer nodes than traditional Kafka setups. However, Kinesis benefits from being a fully managed AWS service with automatic scaling and tight AWS ecosystem integration.
Decision Framework
When choosing between these services, consider:
-
Data Characteristics :
-
Volume: High-volume streaming data favors Kinesis
-
Ordering: If strict ordering is required, use Kinesis or SQS FIFO
-
Retention: Long retention needs favor Kinesis
-
-
Consumption Pattern :
-
Single consumer: SQS is simpler
-
Multiple consumers: Kinesis allows multiple applications to process the same data
-
-
Operational Preferences :
-
Fully managed with minimal configuration: SQS
-
Control over scaling and processing: Kinesis
-
-
Integration Requirements :
-
Deep AWS integration: Both work well
-
Event-driven architectures: SQS often simpler
-
Real-time analytics pipeline: Kinesis preferred
-
Conclusion
Amazon Kinesis and SQS serve different but complementary purposes in distributed architectures. Kinesis excels at high-volume, real-time data streaming with multiple consumers, while SQS provides simple, reliable message queuing for decoupling application components.
Many modern architectures leverage both: Kinesis for capturing and processing high-volume streaming data and SQS for reliable task distribution and application decoupling. Understanding their distinct characteristics and selecting the right service (or combination) for your specific use case is essential for building efficient, scalable, and cost-effective cloud-native applications.
Still struggling with skyrocketing Kafka bills and the "ops tax" of manual disk management? It's time to stop babysitting your clusters. Try AutoMQ Cloud for Free and experience how diskless architecture slashes costs and automates scaling—no credit card required. See how others made the switch in our case studies or explore the project on GitHub.


