Overview
Performance tuning in Apache Kafka involves optimizing various components to achieve efficient operation and maximize throughput while maintaining acceptable latency. This report examines key performance tuning strategies based on authoritative sources to help you optimize your Kafka deployment for high performance and reliability.
Understanding Kafka Performance Fundamentals
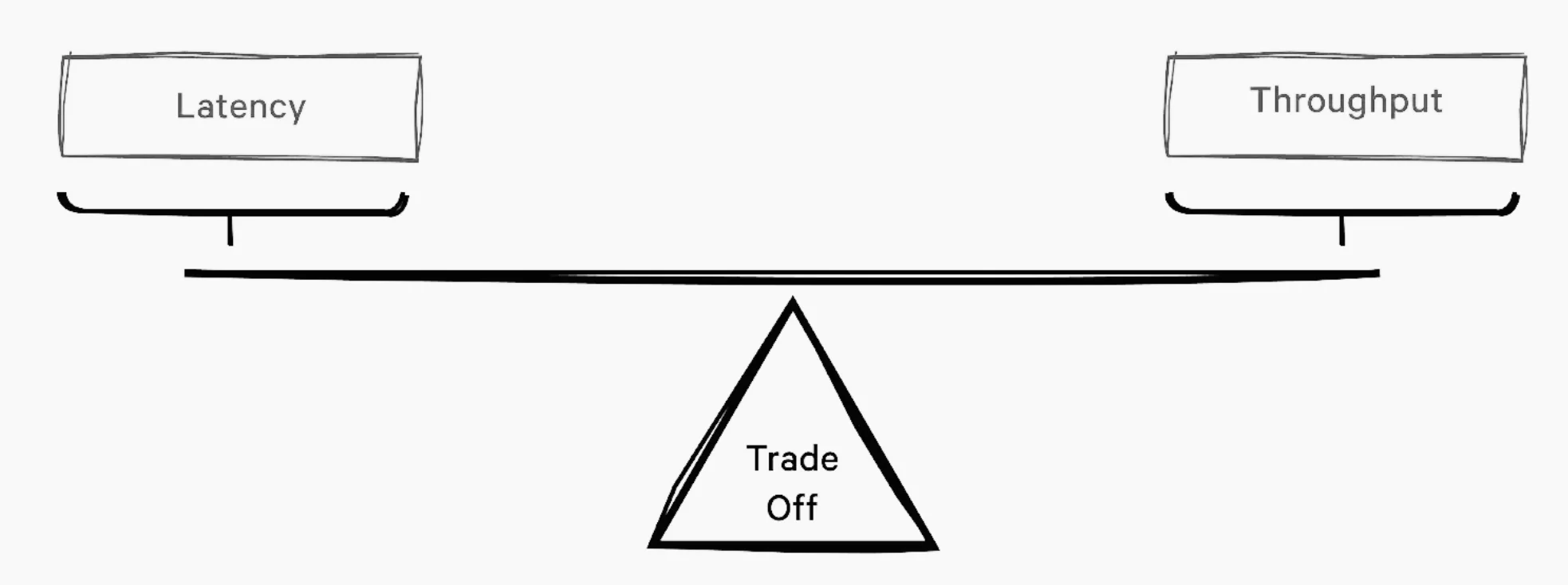
Kafka's performance is primarily measured through two critical metrics: throughput and latency. Kafka latency measures how long it takes for Kafka to fetch or pull a single message, while throughput measures how many messages Kafka can process in a given period. Achieving optimal performance requires carefully balancing these often competing objectives.
Performance tuning in Kafka encompasses multiple layers, from broker configurations to client-side settings, hardware specifications, and operating system parameters. According to Instaclustr, "Successful Kafka performance tuning requires a deep understanding of Kafka's internal mechanisms and how different components interact". This holistic approach ensures that all aspects of the Kafka ecosystem are optimized for peak performance.
Key Performance Metrics
Monitoring appropriate metrics is essential for identifying bottlenecks and opportunities for optimization. The most important metrics fall into several categories:
Broker Metrics : Network throughput, disk I/O rates, request latency, CPU utilization, memory usage, and under-replicated partitions provide insights into broker health and performance limitations.
Producer Metrics : Production rate, request latency, acknowledgment latency, error rates, and retry rates help identify issues in data production and transmission.
Consumer Metrics : Consumer lag, fetch rates, fetch latency, commit latency, and rebalance frequency highlight problems in data consumption and processing.
System Metrics : Underlying system metrics such as CPU load, memory usage, disk I/O, network bandwidth, and JVM metrics (garbage collection times, heap memory usage) affect overall Kafka performance.
Component-Level Optimization
Broker Tuning Strategies
Brokers form the backbone of a Kafka cluster, making their optimization crucial for overall system performance. The following configurations significantly impact broker performance:
Thread and Socket Configuration
The number of network and I/O threads directly affects how efficiently brokers can handle incoming connections and disk operations. Instaclustr recommends adjusting num.network.threads and num.io.threads based on your hardware capabilities. For systems with more CPU cores, increasing these values can enhance network and I/O operations, respectively.
Socket buffer sizes should be tuned to match network interface card (NIC) buffer sizes. The socket.send.buffer.bytes and socket.receive.buffer.bytes settings can significantly improve data transfer rates when properly configured.
Log Segment Management
Segments are the fundamental units in which Kafka stores log files. The log.segment.bytes configuration defines the size of a single log segment. Instaclustr notes that "a larger segment size means the Kafka broker creates fewer segments, reducing the required file descriptors and handles. However, a larger segment may also increase the time to clean up old messages".
For log compaction, which can dramatically reduce streams restoration time but may affect performance, Reddit discussions highlight the importance of tuning the log.cleaner parameters. Specifically, throttling I/O with log.cleaner.io.max.bytes.per.second can help balance compaction benefits with performance concerns.
Partition and Replication Settings
The number of partitions per broker influences throughput and resource utilization. While higher partition counts enable more parallelism, they also create additional overhead. Finding the right balance is essential for optimizing broker performance.
Similarly, replication factor affects data durability and availability but impacts resource usage. Instaclustr recommends setting the min.insync.replicas parameter appropriately "to ensure a minimum number of replicas are in sync before acknowledging writes".
Producer Optimization
Kafka producers are responsible for sending messages to the Kafka cluster. Their configuration significantly impacts overall system throughput and latency.
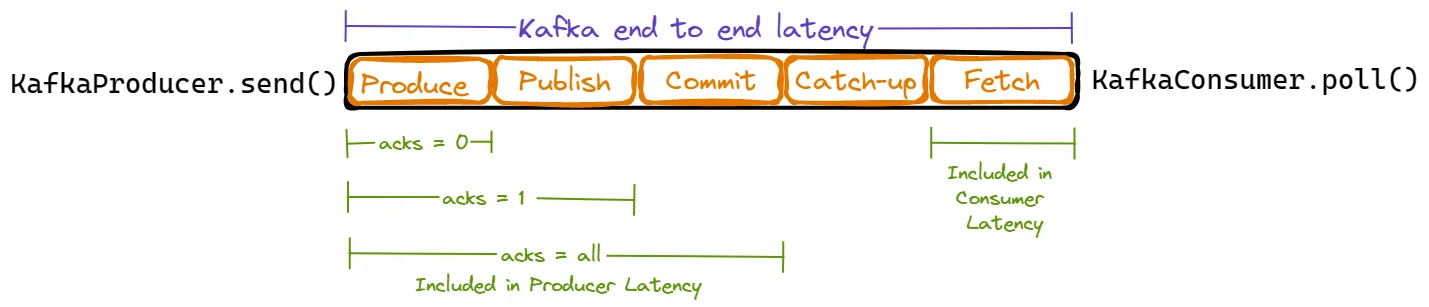
Kafka end-to-end latency is the time between an application publishing a record via KafkaProducer.send() and consuming that record via KafkaConsumer.poll(). A Kafka record goes through several distinct phases:
-
Produce Time - The duration from when an application calls KafkaProducer.send() until the record reaches the topic partition's leader broker.
-
Publish Time - The duration from when Kafka's internal Producer sends a batch of messages to the broker until those messages are appended to the leader's replica log.
-
Commit Time - The duration needed for Kafka to replicate messages across all in-sync replicas.
-
Catch-up Time - When a message is committed and the Consumer lags N messages behind, this is the time needed for the Consumer to process those N messages.
-
Fetch Time - The duration needed for the Kafka Consumer to retrieve messages from the leader broker.
Batching and Linger Time
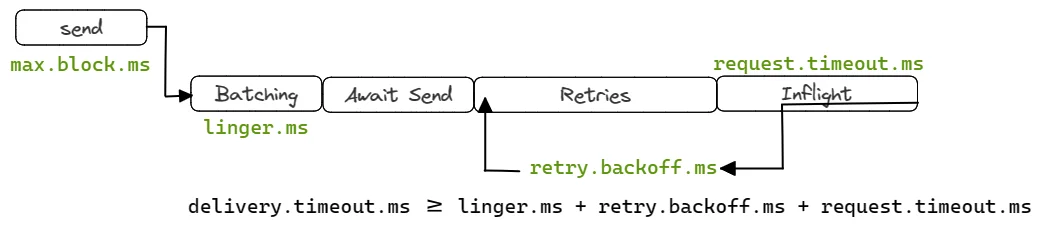
Batching multiple messages together before sending them to Kafka brokers reduces overhead and improves throughput. The batch.size parameter defines the maximum batch size in bytes, while linger.ms specifies how long the producer waits to accumulate messages before sending a batch.
Increasing the batch size leads to higher throughput but may also increase latency as the producer waits to accumulate enough messages to fill the batch. A Confluent Developer tutorial emphasizes testing different combinations of these parameters to find the optimal settings for specific workloads.
max.inflight.requests.per.connection - Controls the number of message batches a Producer can send without receiving responses. A higher value improves throughput but increases memory usage.
Compression
Enabling compression reduces network bandwidth and storage requirements, potentially leading to increased throughput. The compression.type parameter determines which algorithm to use:
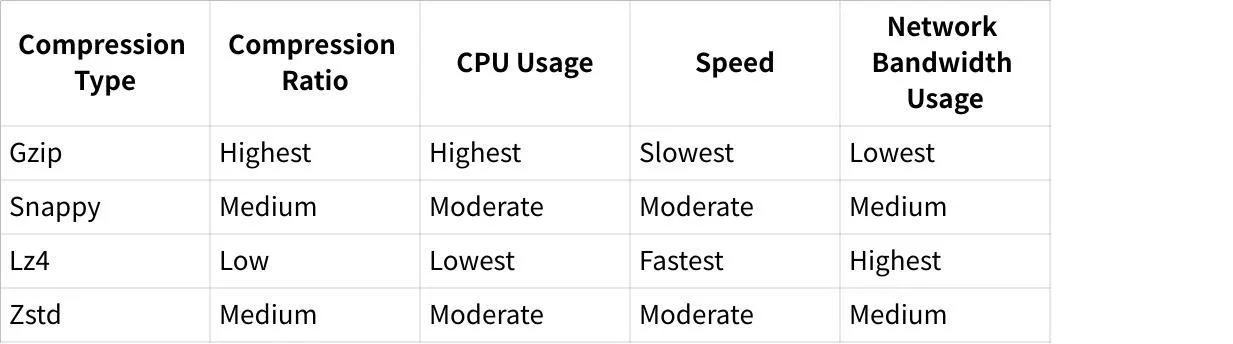
Choosing a compression algorithm that best balances resource usage and bandwidth savings for your specific use case is crucial.
Asynchronous Production
Conduktor strongly recommends using asynchronous message production: "Using asynchronous is extremely recommended to improve throughput and performance significantly. By sending messages asynchronously, the producer can continue processing additional messages without waiting for each individual send() operation to complete".
Consumer Tuning
Optimizing Kafka consumers is essential for achieving low latency and high throughput in data consumption and processing.
Fetch Configuration
The fetch size directly impacts how many messages a consumer retrieves from brokers in a single request. Strimzi notes that the fetch.min.bytes parameter "defines the minimum amount of data, in bytes, that the broker should return for a fetch request".
Increasing this value leads to fewer fetch requests, reducing network communication overhead. However, it may also increase latency as the consumer waits for enough messages to accumulate. Balancing these trade-offs is crucial for optimal performance.
Consumer Group Rebalancing
Consumer group rebalancing occurs when consumers join or leave a group, or when partitions are reassigned. Frequent rebalancing can disrupt processing and affect performance.
The session.timeout.ms parameter defines how long a consumer can be idle before triggering a rebalance. The heartbeat.interval.ms setting determines how often consumers send heartbeats to the group coordinator.
Properly configuring these parameters helps minimize unnecessary rebalances while ensuring failed consumers are detected promptly. As noted in a Reddit discussion, "You don't really have to worry about cluster rebalance events. The kafka libraries and brokers should handle that automatically".
Parallel Consumption
For topics with multiple partitions, using an appropriate number of consumers can significantly improve throughput. As highlighted in a Reddit thread, "If your topic has 10 partitions you can run anywhere from 1 to 10 consumers at the same time. If you run 1 consumer it will read from all 10 partitions. If you run 2 consumers each will read from 5 partitions".
This principle allows for horizontal scaling of consumption capacity, but requires careful configuration to avoid over-allocation of resources.
Kafka - Producer Consumer Optimization Axes
We can visualize this understanding by creating a Kafka Producer-Consumer axis diagram that illustrates key configurations and their impact on application performance.
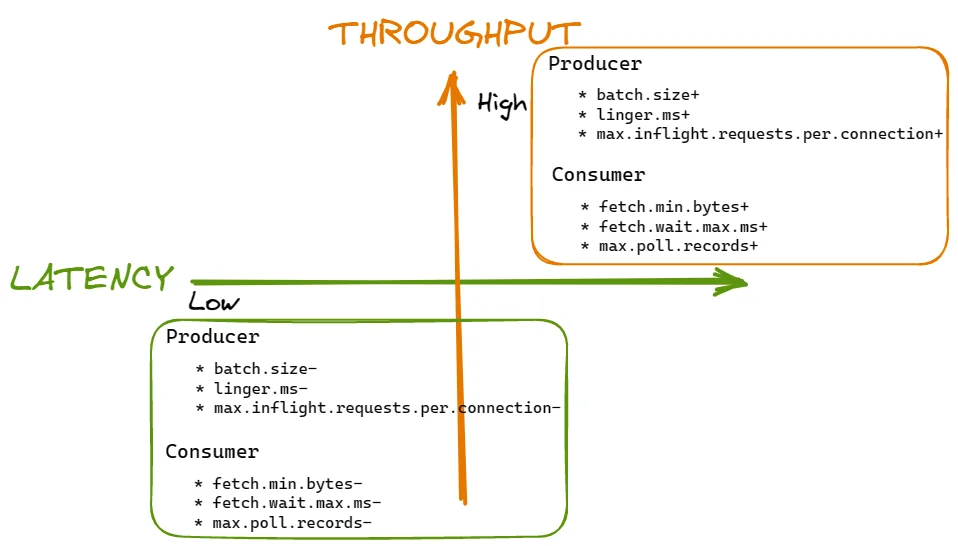
Infrastructure Optimization
Topic and Partition Strategies
Effective partitioning is critical for performance and scalability in Kafka.
Partition Count Considerations
Conduktor warns about the dangers of incorrect partition counts: "Avoiding too many or too few partitions" is crucial for performance. Too few partitions limit parallelism and throughput, while too many increase broker overhead and can lead to resource contention.
When increased throughput is needed, increasing the number of partitions in a Kafka topic improves low-latency message delivery by increasing the parallelism of message processing. However, this must be balanced against the additional resource requirements.
Partition Key Selection
Proper partition key selection ensures even distribution of messages across partitions. A Reddit discussion highlighted an issue where using string keys caused "excessive increase in resource usage". The resolution involved adjusting the linger.ms and batch.size parameters to optimize batching behavior.
For real-time applications with high message volumes, the partitioning strategy significantly impacts performance. In a case involving streaming Postgres changes to Kafka, the implementation specifically noted, "We have full support for Kafka partitioning. By default, we set the partition key to the source row's primary key", ensuring related messages are processed in the correct order.
Hardware and System Configuration
Storage Considerations
Reddit discussions highlight the performance difference between SSDs and HDDs for Kafka: "I suspect compaction would run way better with SSDs but I cannot find any documents supporting this". Instaclustr confirms this, recommending SSDs for Kafka storage "due to their high I/O throughput and low latency".
An expert from Instaclustr advises: "Kafka benefits from fast disk I/O, so it's critical to use SSDs over HDDs and to avoid sharing Kafka's disks with other applications. Ensure you monitor disk usage and use dedicated disks for Kafka's partitions".
Scaling Strategies
Aiven documentation outlines two primary scaling approaches for Kafka clusters:
Vertical Scaling : Replacing existing brokers with higher capacity nodes while maintaining the same number of brokers. This is appropriate when application constraints prevent increasing partition or topic counts.
Horizontal Scaling : Adding more brokers to distribute the load. This approach shares the work across more nodes, improving overall cluster capacity and fault tolerance.
Aiven recommends "a minimum of 6 cluster nodes to avoid situations when a failure in a single cluster node causes a sharp increase in load for the remaining nodes".
TLS Performance Considerations
Enabling TLS for security can impact performance. Jack Vanlightly's comparative analysis revealed that "With TLS, Redpanda could only manage 850 MB/s with 50 producers, where as Kafka comfortably managed the target 1000 MB/s". This highlights the importance of considering security overhead when planning for performance requirements.
System-Level Optimization
Operating System Tuning
File system optimization, network settings, and kernel parameters should be tuned for Kafka workloads. Key areas include "file system tuning, network settings, and kernel parameters".
JVM Garbage Collection
An expert from Instaclustr provides specific recommendations for JVM garbage collection settings:
-
For high throughput: Use Parallel GC (-XX:+UseParallelGC)
-
For low latency: Choose G1GC (-XX:+UseG1GC)
-
For minimal pauses: Try ZGC or Shenandoah
-
Avoid CMS, as it is deprecated
Common Performance Issues and Solutions
Several common issues can impact Kafka performance. Understanding these problems and their solutions can help maintain optimal operation.
Producer Count Impact
Jack Vanlightly's benchmarking revealed that "By simply changing the producer and consumer count from 4 to 50, Redpanda performance drops significantly". This highlights how client scaling can unexpectedly impact performance, requiring careful testing with realistic workloads.
Handling Large Data Volumes
For applications managing large data volumes, optimizing for real-time processing presents challenges. A Reddit discussion about handling >40,000 rows in a real-time searchable table using Kafka revealed the importance of properly configuring the entire pipeline, from producers through Kafka to consumers and the application layer.
Log Compaction Performance
Log compaction can dramatically reduce streams restoration time but may impact performance, especially with HDDs. A Reddit discussion noted significant parallel I/O issues with compaction on SATA disks. Tuning log.cleaner.io.max.bytes.per.second was suggested as a solution to throttle I/O and reduce impact.
Conclusion
Kafka performance tuning is a multifaceted process requiring careful consideration of brokers, producers, consumers, topics, hardware, and operating system components. The optimal configuration depends on specific use cases, data volumes, and performance requirements.
Key recommendations include:
-
Monitor critical metrics to identify bottlenecks and opportunities for optimization
-
Tune broker configurations based on hardware capabilities and workload characteristics
-
Optimize producer settings to balance throughput and latency
-
Configure consumers to efficiently process messages without unnecessary overhead
-
Design an appropriate partition strategy for your specific workload
-
Select hardware that meets your performance requirements, particularly storage
-
Consider both vertical and horizontal scaling approaches based on application constraints
-
Optimize operating system and JVM settings for Kafka workloads
Remember that performance tuning is an iterative process. As workloads evolve, continuous monitoring and adjustment are necessary to maintain optimal performance. By following these best practices, you can achieve a high-performance Kafka deployment that meets your specific requirements for throughput, latency, and reliability.
Still struggling with skyrocketing Kafka bills and the "ops tax" of manual disk management? It's time to stop babysitting your clusters. Try AutoMQ Cloud for Free and experience how diskless architecture slashes costs and automates scaling—no credit card required. See how others made the switch in our case studies or explore the project on GitHub.


