Apache Kafka and Confluent Platform represent two interconnected but distinct options for implementing event streaming architecture. While Apache Kafka provides the foundational open-source framework, Confluent Platform extends it with enterprise-grade features and tools. This report examines their key differences, capabilities, configuration approaches, and best practices to help organizations make informed decisions.
Overview and Core Differences
Apache Kafka is an open-source distributed event streaming platform developed by the Apache Software Foundation. Written in Scala and Java, it provides a unified, high-throughput, low-latency platform for handling real-time data feeds. Kafka's core capabilities include fault-tolerant storage, processing streams of records, and performing real-time analysis.
Confluent Platform, on the other hand, is a commercial distribution built on top of Apache Kafka, developed by Confluent—a company founded by the original creators of Kafka. It extends Kafka's capabilities with additional enterprise-grade tools and services.
Key Differences
| Feature | Apache Kafka | Confluent Platform |
|---|---|---|
| Origin | Open-source project primarily for stream processing | Commercial offering built on Kafka with enhanced features |
| Feature Set | Core features: publish-subscribe messaging, fault tolerance, high throughput | All Kafka features plus schema registry, REST proxy, and various connectors |
| Ease of Use | Requires manual setup and configuration | More user-friendly with additional tools and pre-built connectors |
| Support | Community support; professional support via third parties | Professional support, training, and consultancy included |
| Pricing | Free and open-source | Free community version and paid enterprise options |
| Licensing | Apache 2.0 License | Confluent Community License (with restrictions) and Enterprise License |
Architecture and Components
Apache Kafka Architecture
Kafka's architecture is distributed, fault-tolerant, and scalable. The key components include:
-
Brokers : Kafka servers responsible for receiving, storing, and replicating data
-
Topics : Logical groupings of events
-
Partitions : Append-only, ordered log files holding subsets of topic data
-
Producers : Applications that publish data to topics
-
Consumers : Applications that subscribe to and process data from topics
-
Consumer Groups : Logical groupings of consumers sharing processing load
-
Zookeeper/KRaft : For coordination and configuration management
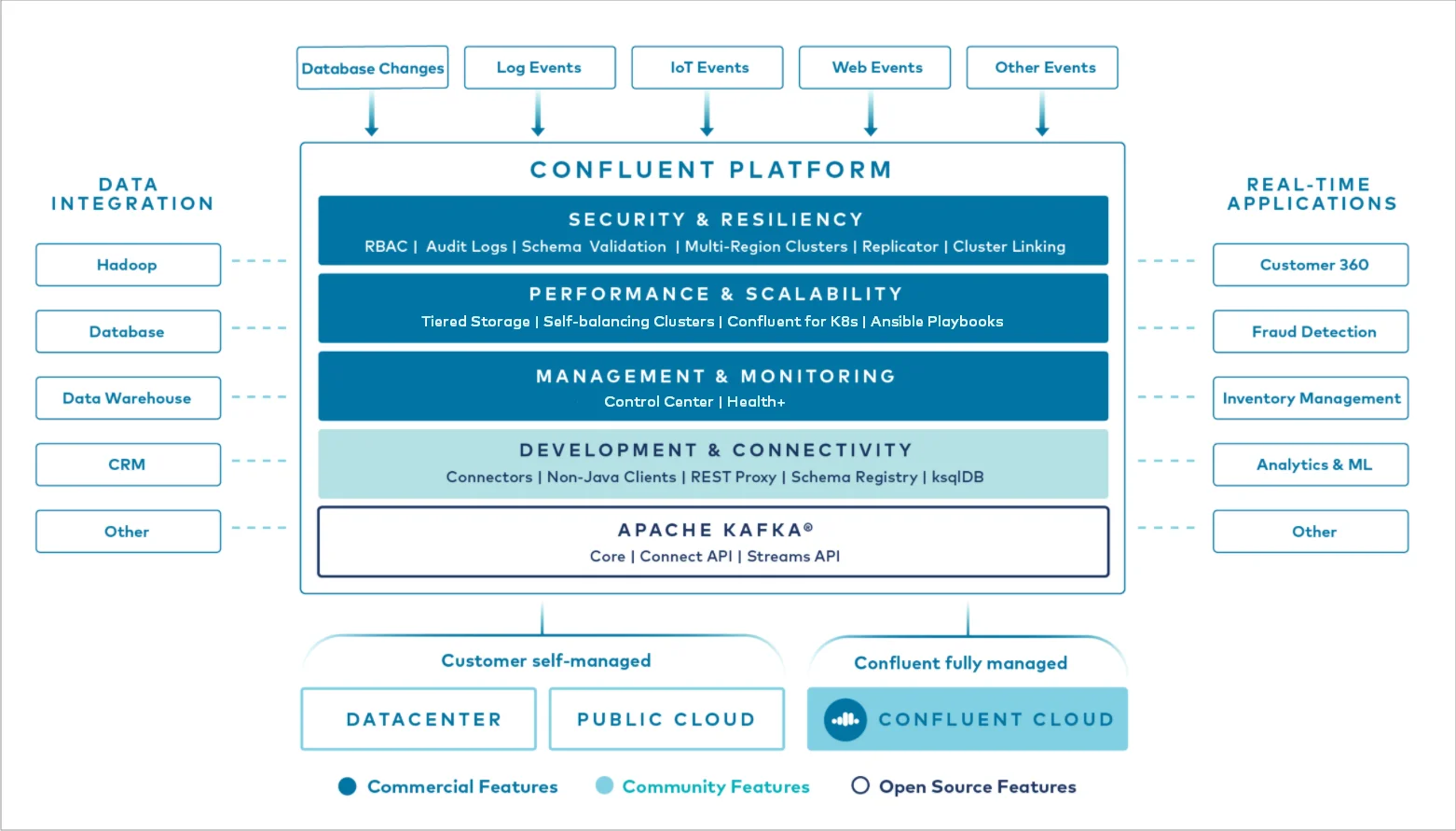
Confluent Platform Extensions
Confluent extends Kafka with several enterprise components:
-
Schema Registry : Enforces schemas for message consistency
-
ksqlDB : SQL-based stream processing
-
Kafka Connect : Pre-built connectors for integrating with external systems
-
Control Center : GUI for monitoring and managing clusters
-
Enhanced Security : LDAP integration, Role-Based Access Control (RBAC)
-
Cluster Linking : Simplifies replication between Kafka clusters
Performance and Configuration
Performance Comparison
Confluent claims significant performance advantages over Apache Kafka, particularly with their cloud-native Kafka engine called Kora.
Benchmarking Results
According to Confluent's benchmarks:
-
Confluent Cloud is up to 10x faster than Apache Kafka
-
End-to-end latency improvements of up to 12x at higher throughputs
-
More consistent performance at tail latencies (p99), showing 16x better performance
Redpanda, another streaming platform, also published comparisons showing performance differences with Kafka using KRaft, demonstrating the ongoing competition in the streaming platform space.
Performance Factors
Several factors influence Kafka/Confluent performance:
-
Partitioning strategy : Proper partition design is crucial for parallelism and load balancing
-
Compression : Using compression for producers reduces network bandwidth requirements
-
Network and I/O threads : Tuning these parameters affects throughput and latency
-
Replica fetchers : Increasing these can improve replication performance
Configuration Best Practices
Kafka Configuration Tweaks
Top configuration parameters to tune for better performance include:
-
Partitioning : Increase partition numbers based on workload requirements
-
Replica lag time : Tune
replica.lag.time.max.msfor optimal replication -
Threading : Adjust
num.network.threadsandnum.io.threadsfor better concurrency -
Compression : Enable compression for producers to reduce network bandwidth
-
Batch size : Increase producer batch size for higher throughput at the cost of latency
Confluent-Specific Configuration
Confluent Platform offers additional configuration options:
-
Schema Validation : Enable with
confluent.value.schema.validation=truefor data quality -
Quotas : Configure client quotas to prevent resource starvation
-
Secret Protection : Use envelope encryption instead of plaintext configuration
-
Structured Audit Logs : Enable for capturing security events
Security Features
Basic Kafka Security
Apache Kafka provides fundamental security features:
-
Authentication via SASL mechanisms
-
Authorization with ACLs
-
Encryption with SSL/TLS
-
Network segmentation
Confluent Enhanced Security
Confluent Platform adds enterprise security capabilities:
-
Role-Based Access Control (RBAC) : More granular access control than Kafka ACLs
-
Secret Protection : Protects encrypted secrets through envelope encryption
-
Structured Audit Logs : Records authorization decisions in structured format
-
Connect Secret Registry : Manages secrets for Kafka Connect through REST API
Management and Operations
Deployment Options
Apache Kafka :
-
Self-managed deployment requiring manual setup and configuration
-
Requires expertise in Kafka administration and operations
Confluent Platform :
-
Self-managed Confluent Platform: Enhanced tools but still requires internal operations
-
Confluent Cloud: Fully-managed SaaS offering with minimal operational overhead
Monitoring and Management
Apache Kafka :
-
Requires third-party monitoring tools
-
Manual management of logging and metrics
-
Controller logs in
logs/controller.logand state change logs inlogs/state-change.log
Confluent Platform :
-
Confluent Control Center for monitoring and management
-
Integrated metrics and alerting
-
Simplified cluster management
Common Issues and Troubleshooting
Several common Kafka issues affect both platforms:
-
Broker Not Available : When producers/consumers can't connect to brokers
- Resolution: Check if broker is running, verify network connectivity
-
Leader Not Available : When a partition leader is unavailable
- Resolution: Restart failed brokers or force leader election manually
-
Offset Out of Range : When consumers request unavailable offsets
- Resolution: Adjust consumer configurations or reset offsets
-
Authentication Errors : When security settings are misconfigured
- Resolution: Verify credentials and security protocols
Confluent-specific tools can help troubleshoot these issues more efficiently but may introduce their own complexity.
Use Cases
Common Use Cases for Both Platforms
-
Real-time analytics : Processing and analyzing data streams
-
Data integration : Connecting disparate systems
-
Event-driven architectures : Building reactive applications
-
Stream processing : Transforming data in motion
When to Choose Confluent Platform
Confluent Platform is particularly valuable when:
-
Enterprise-level support and SLAs are required
-
Pre-built connectors would accelerate development
-
Schema management is critical for data governance
-
Complex security requirements exist
-
Management tooling would reduce operational burden
Confluent Alternatives
For organizations seeking alternatives to Confluent, several options are available, each offering unique advantages. One of the most promising alternatives is AutoMQ , a cloud-native solution designed to reimagine Kafka's architecture for cost efficiency and scalability.
AutoMQ Overview
AutoMQ is built as a replacement for Apache Kafka, leveraging shared storage like Amazon S3 and stateless brokers to significantly reduce operational costs. It offers 10x cost-effectiveness compared to traditional Kafka setups by eliminating data replication and utilizing Spot instances for compute resources. AutoMQ's architecture ensures single-digit millisecond latency while maintaining high throughput, making it suitable for real-time data streaming applications. It also provides 100% compatibility with Kafka protocols, allowing seamless integration with existing Kafka ecosystems.
Key Features of AutoMQ
-
Cost Efficiency : AutoMQ reduces costs by up to 90% compared to Apache Kafka and Confluent, primarily through optimized EC2 resource usage and shared storage.
-
Stateless Brokers : Enables elastic scaling and reduces operational complexity by eliminating the need for data replication across brokers.
-
Shared Storage : Utilizes object storage like S3, eliminating cross-AZ replication costs and improving scalability.
-
Latency Performance : Offers superior latency compared to other Kafka alternatives like WarpStream, with single-digit millisecond P99 latency.
-
Compatibility : Fully compatible with Kafka protocols, ensuring easy migration from existing Kafka environments.
Conclusion
The choice between Apache Kafka and Confluent Platform ultimately depends on organizational needs, resources, and priorities. Apache Kafka provides a robust open-source foundation for event streaming, suitable for organizations with the technical expertise to manage complex distributed systems. Confluent Platform enhances Kafka with enterprise features, management tools, and support services that can reduce operational burden and accelerate development.
For organizations just starting with event streaming or with limited Kafka expertise, Confluent's offerings—especially Confluent Cloud—can provide a more accessible entry point. For those with existing Kafka expertise and a desire for maximum control and customization, the open-source Apache Kafka may be sufficient.
When evaluating either option, organizations should consider performance requirements, operational capabilities, budget constraints, and specific use cases to determine the best fit for their event streaming needs.
Still struggling with skyrocketing Kafka bills and the "ops tax" of manual disk management? It's time to stop babysitting your clusters. Try AutoMQ Cloud for Free and experience how diskless architecture slashes costs and automates scaling—no credit card required. See how others made the switch in our case studies or explore the project on GitHub.


