Overview
Messaging systems are the backbone of modern distributed architectures, enabling applications to communicate effectively while remaining decoupled. Apache Kafka and Google Cloud Pub/Sub represent two of the most powerful options in this space, each with distinct characteristics that make them suitable for different use cases. This comparison examines their key differences, architectural approaches, performance metrics, and implementation considerations to help you make an informed decision.
Architecture and Core Concepts
Fundamental Design Philosophy
Apache Kafka was designed as a distributed streaming platform with a focus on high throughput and fault tolerance. In contrast, Google Pub/Sub was built as a fully managed messaging service optimized for cloud environments. This fundamental difference shapes many of their capabilities and limitations.
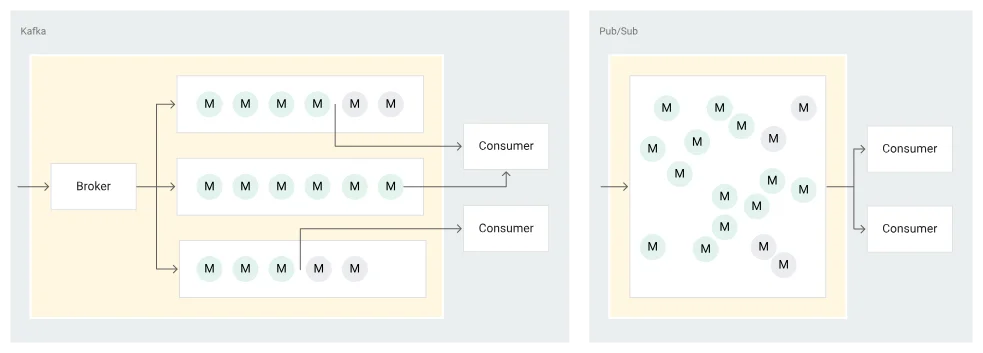
Kafka's architecture revolves around a distributed server/client model with topics, brokers, producers, and consumers as its core components. The Kafka cluster can span across multiple servers, regions, or data centers. Messages in Kafka are published to topics that are partitioned and distributed across multiple brokers for scalability.
Pub/Sub's architecture, on the other hand, is divided into two planes:
-
Data plane : Manages messages moving between publishers and subscribers via servers called "forwarders"
-
Control plane : Assigns publishers and subscribers to data plane servers via "routers"
Message Handling and Storage
A critical architectural difference lies in how messages are stored and consumed:
-
Kafka : Functions as a streaming log where messages remain available for a configurable retention period (default 7 days) regardless of consumption. This allows multiple consumers to read the same messages independently.
-
Pub/Sub : Operates more like a traditional message queue. Once a message is acknowledged by a subscription, it's typically removed and unavailable for future reads (although newer versions support message replay via the "seek" feature).
Performance and Operations
Throughput and Latency
Both systems can handle high message volumes, but Kafka generally demonstrates superior raw performance metrics:
| Metric | Apache Kafka | Google Pub/Sub |
|---|---|---|
| Throughput (Low Concurrency) | 250,000 msg/s | 180,000 msg/s |
| Throughput (High Concurrency) | 850,000 msg/s | 600,000 msg/s |
| Latency (Low) | 25 ms | 35 ms |
| Latency (High) | 50 ms | 60 ms |
Table: Performance comparison of Kafka vs Pub/Sub
The performance gap becomes particularly pronounced in high-throughput scenarios requiring massive parallelism. Kafka's architecture allows it to distribute workload more efficiently across clients, resulting in better performance at scale.
Latency Optimization
For latency-sensitive applications, both platforms offer optimization paths:
-
Kafka : Reduce batch size, implement efficient compression, optimize network settings, increase partitions and consumer instances
-
Pub/Sub : Send messages in optimized batches, tune network configurations, distribute publishers across regions
Data Management
Message Retention
Kafka offers superior message retention capabilities, allowing you to configure retention periods based on time or size. You can even set retention to infinite, effectively using Kafka as an immutable datastore.
Pub/Sub, being primarily designed as a messaging service rather than a storage system, typically retains messages only until they're acknowledged by subscriptions. However, it now supports message replay through the "seek" feature, which allows changing the acknowledgment status of messages to replay them.
Replication Mechanisms
Both platforms implement replication to ensure data durability:
-
Kafka : Replicates partitions across multiple brokers. Each partition has one leader and multiple follower replicas. In-sync replicas (ISR) remain synchronized with the leader and can take over if the leader fails.
-
Pub/Sub : Replicates data across multiple zones within Google Cloud infrastructure, ensuring availability and durability. The fully-managed nature of the service means replication details are abstracted away from users.
Deployment and Management
Deployment Options
Kafka and Pub/Sub differ significantly in deployment flexibility:
-
Kafka : Can be deployed on-premises, in private data centers, or in any cloud environment. Runs on Windows, Linux, and macOS.
-
Pub/Sub : Available only as a cloud service within the Google Cloud Platform ecosystem.
Management Overhead
-
Kafka : Requires more active management, including cluster sizing, broker configuration, monitoring, and maintenance. While powerful, it demands deeper technical expertise.
-
Pub/Sub : Offers a fully managed experience with reduced operational overhead. Google handles infrastructure maintenance, scaling, and upgrades.
Platform Capabilities
Scaling Approach
Both platforms support horizontal scaling but with different approaches:
-
Kafka : Scales by adding more brokers to clusters and increasing partition counts for topics. This provides granular control but requires careful planning.
-
Pub/Sub : Automatically scales based on demand, leveraging Google's global infrastructure. Uses load-balancing to distribute traffic to the nearest Google Cloud data center.
Cost Considerations
-
Kafka : Open-source with no licensing costs, but requires infrastructure and operational expenses. Under low concurrency conditions, estimated costs are approximately $0.35 per hour for comparable throughput.
-
Pub/Sub : Follows a pay-as-you-go model with charges for throughput, storage, and data transfer. Typically costs around $0.50 per hour under similar low concurrency conditions.
Integration Capabilities
-
Kafka : Offers extensive integration options through Kafka Connect, supporting connections to diverse data systems including PostgreSQL, AWS S3, Elasticsearch, and others.
-
Pub/Sub : Seamlessly integrates with Google Cloud services like BigQuery, Dataflow, and Cloud Functions. Integration with non-GCP systems is possible through APIs but may require additional development.
Use Cases and Implementation
Ideal Scenarios for Kafka
Kafka excels in scenarios requiring:
-
High-throughput, real-time data streaming
-
Long-term event storage and replay capabilities
-
Stream processing and analytics
-
Event sourcing patterns
-
Log aggregation at scale
-
Complex data pipeline architectures
Ideal Scenarios for Pub/Sub
Pub/Sub is particularly well-suited for:
-
Cloud-native applications on Google Cloud
-
Scenarios requiring minimal operational overhead
-
Asynchronous task processing
-
Simple event-driven architectures
-
System monitoring and alerting
-
Google Cloud ecosystem integration
Configuration Best Practices
To maximize Kafka performance:
-
Partition Management : Increase partition count for higher throughput, but be aware that more partitions also mean higher replication latency and more open server files
-
Replication Settings : Consider increasing default replication factor from two to three for production environments
-
Thread Tuning : Adjust
num.network.threadsandnum.io.threadsbased on workload -
Compression : Enable compression for producers to reduce network bandwidth usage
-
Batch Messaging : Configure producer batching for higher throughput (balancing against latency needs)
For optimal Pub/Sub implementation:
-
Subscription Preparation : Always attach a subscription or enable topic retention before publishing messages
-
Batch Configuration : Configure batch messaging appropriately for your throughput vs. latency requirements
-
Flow Control : Implement flow control mechanisms for handling transient message spikes
-
Acknowledgment Deadlines : Set appropriate acknowledgment deadlines to avoid message duplication
Security
Security Features
Both platforms offer robust security capabilities:
-
Kafka : Provides encryption, SSL/SASL authentication, and authorization through access control lists (ACLs)
-
Pub/Sub : Integrates with Google Cloud IAM for access control, offers encryption in transit and at rest, and supports private connectivity options
Conclusion
Choosing between Apache Kafka and Google Pub/Sub ultimately depends on your specific requirements, existing infrastructure, and team expertise.
Kafka represents the better choice when you need:
-
Maximum performance and throughput
-
Full control over infrastructure
-
Long-term message retention and replay capabilities
-
Deployment flexibility across environments
Google Pub/Sub is more suitable when:
-
Operational simplicity is a priority
-
You're already invested in the Google Cloud ecosystem
-
Automatic scaling without management overhead is desired
-
Pay-as-you-go pricing aligns with your usage patterns
Both systems continue to evolve, with Kafka expanding its cloud capabilities and Pub/Sub enhancing its feature set to address more complex use cases. By understanding their fundamental differences, you can select the messaging platform that best supports your architecture and business requirements.
Still struggling with skyrocketing Kafka bills and the "ops tax" of manual disk management? It's time to stop babysitting your clusters. Try AutoMQ Cloud for Free and experience how diskless architecture slashes costs and automates scaling—no credit card required. See how others made the switch in our case studies or explore the project on GitHub.


