


.png)
Overview
Apache Kafka and HiveMQ serve different yet complementary roles in modern data architectures. While often perceived as competing technologies, they actually address different aspects of data streaming and messaging, particularly in IoT contexts. This comprehensive comparison examines their architectures, capabilities, use cases, and integration patterns.
Understanding the Core Technologies
Apache Kafka
Apache Kafka is a distributed event streaming platform designed for high-throughput, fault-tolerant data pipelines and real-time analytics. Written in Java, Kafka has established itself as the de facto standard for data streaming. It excels at processing large volumes of data between enterprise systems and applications in stable network environments.
HiveMQ
HiveMQ is an enterprise MQTT (Message Queuing Telemetry Transport) platform specifically designed for IoT device connectivity. It enables reliable, scalable real-time communication with constrained IoT devices and works effectively over unreliable networks. HiveMQ implements the complete MQTT protocol specification, supporting both MQTT 3.1.1 and MQTT 5.
Architectural Differences
The fundamental architectural differences between Kafka and HiveMQ reflect their distinct design goals:
| Feature | Apache Kafka | HiveMQ |
|---|---|---|
| Protocol | Kafka protocol | MQTT protocol |
| Primary design | Server-to-server communication | Device-to-server communication |
| Client complexity | Complex, resource-intensive | Lightweight, suitable for constrained devices |
| Connection model | Direct addressing of brokers required | Works through load balancers and proxies |
| Network requirements | Stable IP connections | Works over unreliable networks |
| Topic scalability | Limited number of topics | Supports millions of topics with wildcards |
Why Kafka Alone Isn't Ideal for IoT
Kafka's architecture presents several challenges for IoT implementations:
Direct broker addressing : Kafka requires clients to directly address brokers, which isn't practical for IoT devices connecting through load balancers.
Topic limitations : Kafka doesn't efficiently support the vast number of topics typically needed in large IoT deployments.
Network stability requirements : Kafka clients require stable IP connections, while IoT devices often connect over unreliable cellular networks.
Client complexity : Kafka clients are complex and resource-intensive, making them unsuitable for constrained IoT devices.
Performance and Scalability
Kafka Performance
Handles millions of messages per second
Processes multiple GB of data per second
Delivers very low latencies (millisecond range)
Scales to handle petabytes of data across hundreds of brokers
Provides data replication for fault tolerance and high availability
HiveMQ Performance
Supports millions of concurrent device connections
Handles high message throughput
Optimized for constrained devices
Designed for unreliable network environments
Provides clustering for scalability and resilience
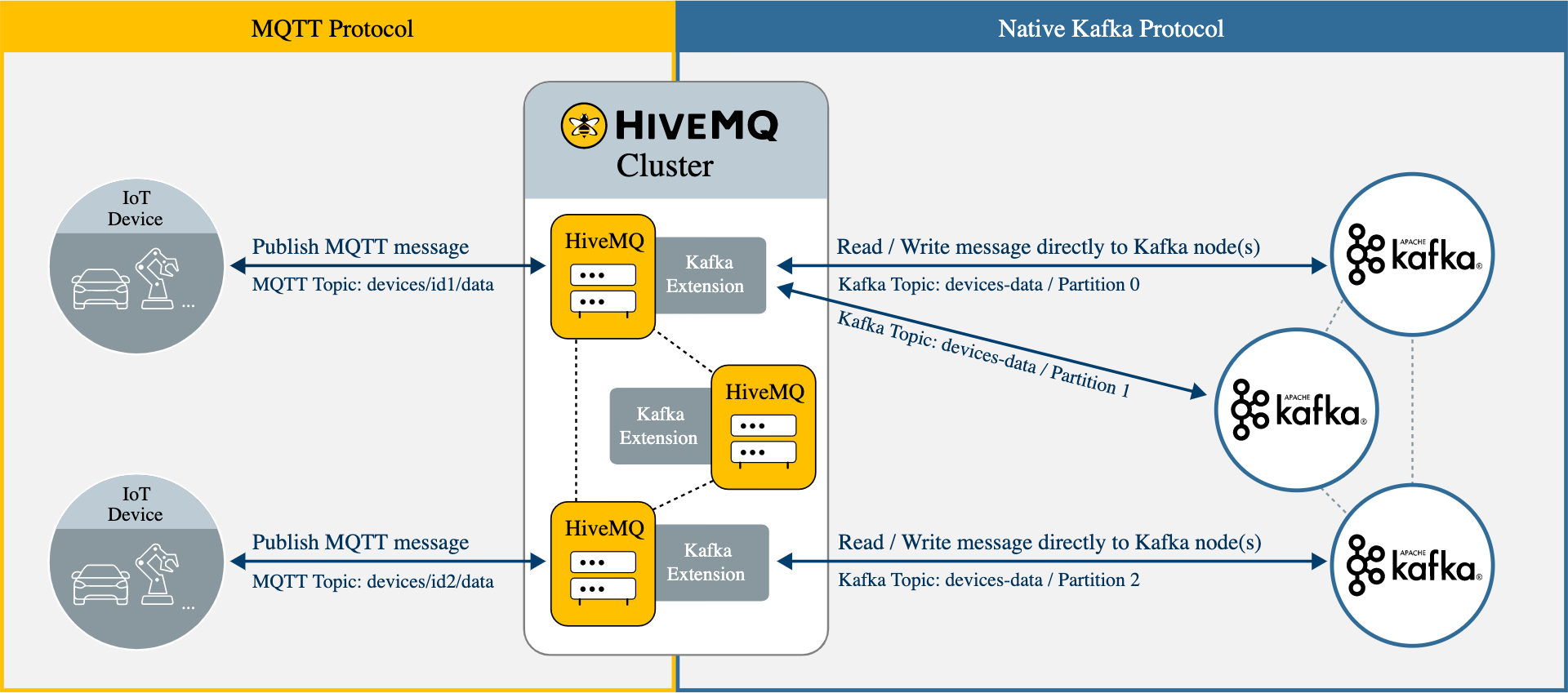
Integration: HiveMQ and Kafka Working Together
Rather than competing, HiveMQ and Kafka often complement each other in IoT architectures. HiveMQ offers the Enterprise Extension for Kafka, which implements the native Kafka protocol within the HiveMQ MQTT broker.
Integration Benefits
Bidirectional communication : Enables seamless message flow between IoT devices and Kafka clusters
Protocol translation : Bridges the gap between lightweight MQTT clients and enterprise Kafka systems
End-to-end persistence : Ensures no messages are lost from device to Kafka
Scalable connectivity : Connects millions of IoT devices to Kafka clusters
Integration Architecture
The HiveMQ Enterprise Extension for Kafka enables:
MQTT-to-Kafka : Acts as multiple Kafka producers that route MQTT messages to designated Kafka topics
Kafka-to-MQTT : Functions as a consumer group to retrieve data from Kafka topics and publish to MQTT clients
Topic mapping : Maps between MQTT topic structures and Kafka topics, supporting wildcards
Message transformation : Provides customization capabilities for transforming messages between formats
Configuration and Setup
HiveMQ Kafka Extension Configuration
Setting up the HiveMQ Enterprise Extension for Kafka involves five key steps:
Connect to Kafka : Configure bootstrap servers for the Kafka cluster
Secure the connection : Add Kafka credentials using SASL mechanisms
Configure MQTT-to-Kafka flow : Map source MQTT topics to destination Kafka topics
Configure Kafka-to-MQTT flow : Set up bidirectional communication if needed
Enable the configuration : Start the data flow between HiveMQ and Kafka
A basic configuration example for the extension looks like this:
<?xml version="1.0" encoding="UTF-8" ?>
<kafka-configuration xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="config.xsd">
<kafka-clusters>
<kafka-cluster>
<id>cluster01</id>
<bootstrap-servers>your-kafka-servers:9092</bootstrap-servers>
</kafka-cluster>
</kafka-clusters>
<mqtt-to-kafka-mappings>
<mqtt-to-kafka-mapping>
<id>mapping01</id>
<cluster-id>cluster01</cluster-id>
<mqtt-topic-filters>
<mqtt-topic-filter>data/#</mqtt-topic-filter>
</mqtt-topic-filters>
<kafka-topic>your-kafka-topic</kafka-topic>
</mqtt-to-kafka-mapping>
</mqtt-to-kafka-mappings>
</kafka-configuration>
Key Features of the Integration
Topic Mapping and Message Flow
HiveMQ's Kafka extension provides sophisticated topic mapping capabilities:
Map millions of MQTT topics to a limited number of Kafka topics using wildcards
Support bidirectional communication
Transform messages between formats
Enable message multicasting
Schema Support
The extension supports schema registries for message validation:
Local schema registry
Confluent Schema Registry integration
Message validation against schemas
Monitoring and Observability
Comprehensive monitoring features include:
Monitor MQTT messages written to Kafka using HiveMQ Control Center
Track message flow in both directions
Observe communication patterns
Export diagnostic information for troubleshooting
Use Cases and Applications
When to Use Kafka
Kafka excels in scenarios involving:
High-throughput data streaming between server applications
Real-time analytics
Log aggregation and processing
Event sourcing architectures
Data pipelines between enterprise systems
When to Use HiveMQ
HiveMQ is ideal for:
IoT device connectivity
Machine-to-machine communication
Edge computing scenarios
Mobile application messaging
Scenarios with unreliable networks or constrained devices
When to Use Both Together
The combination of HiveMQ and Kafka creates powerful solutions for:
Manufacturing and Industrial IoT
Connect factory equipment using MQTT via HiveMQ
Process high-volume sensor data with Kafka
Create unified namespaces with SparkPlug
Connected Vehicles
Connect vehicles using MQTT over cellular networks
Process telematics and diagnostics data with Kafka
Enable real-time analytics and predictive maintenance
Smart Cities
Connect distributed sensors and devices via MQTT
Process and analyze city-wide data streams with Kafka
Enable real-time decision making and automation
Performance Comparison
| Attribute | Kafka | HiveMQ | Integration Benefit |
|---|---|---|---|
| Throughput | Very high (millions of messages/sec) | High (optimized for IoT scale) | End-to-end high throughput pipeline |
| Latency | Very low (milliseconds) | Low (optimized for IoT) | Minimal added latency in most scenarios |
| Scalability | Petabytes of data across brokers | Millions of concurrent connections | Seamless scaling from device to data center |
| Resilience | Replication across nodes | Clustering for high availability | Fault-tolerant end-to-end message delivery |
Best Practices
Integration Architecture Best Practices
Efficient topic mapping : Design your MQTT topic hierarchy and Kafka topics to minimize transformation overhead
Message format consistency : Standardize message formats when possible to simplify processing
Error handling : Implement proper error handling and retry mechanisms
Monitoring : Set up comprehensive monitoring across both systems
Security : Implement end-to-end security from devices through to Kafka
Performance Optimization
Right-size your clusters : Ensure both HiveMQ and Kafka clusters are properly sized for expected load
Buffer configuration : Configure appropriate buffer settings for your message patterns
QoS selection : Choose appropriate MQTT QoS levels based on use case requirements
Topic partitioning : Design Kafka topic partitioning to align with expected throughput
Conclusion
Apache Kafka and HiveMQ serve different yet complementary purposes in modern data architectures. While Kafka excels at high-throughput data streaming between enterprise systems, HiveMQ specializes in connecting IoT devices using the lightweight MQTT protocol. The HiveMQ Enterprise Extension for Kafka bridges these worlds, enabling seamless integration between device-oriented MQTT messaging and enterprise data streaming.
Rather than competing technologies, they represent different layers in a comprehensive IoT data pipeline, with HiveMQ managing the device connectivity layer and Kafka handling the data streaming and processing layer. Organizations implementing IoT solutions at scale can benefit tremendously from leveraging both technologies together, using each for what it does best.
As suggested by the title of one of the resources, MQTT and Kafka truly represent "a match made in heaven" when it comes to building robust, scalable IoT data pipelines.
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
JD.comx AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging






