Background
In the realm of modern data architecture, even the most basic data applications involve a multi-layered infrastructure. This may include computing and storage services provided by AWS, Kafka service layered atop the IaaS, and various clients tailored to different business scenarios.
Each layer carries its own responsibility to enhance availability. However, the upper layers maintain a healthy skepticism towards the reliability of the underlying layers. This is because failures are an inherent part of any system, and no single layer can guarantee 100% uptime.
Even as AWS strives to provide high SLA for services like S3 and EBS, Kafka vendors such as AutoMQ do not place blind trust in these guarantees. Instead, AutoMQ designs systems with the expectation of failures. This approach has led to many strategies being developed to tolerate potential failures of EBS, EC2, and S3.
The same principle applies to the client side. When we develop Kafka data applications, we must also design with failures in mind. Given the potential unreliability of the underlying layers, what proven client-side strategies can we adopt to improve the SLA further? This is the topic we aim to explore in this article.
Tradeoffs
Unfortunately, there is no single strategy that can tolerate all the failures of the underlying Kafka service and also apply to all business scenarios. Things aren't that simple—many trade-offs are involved in this topic.
When designing failover strategies for our client applications, we often consider the following dimensions: latency, availability, ordering, and consistency.
Latency : Can we tolerate data latency for our producer and consumer applications?
-
For consumers, can we accept that data is stored on the server but remains inaccessible to them for ten minutes or even hours?
-
For producers, who may be the data sources, what if the Kafka service is down or slow to ingest data? Can we backpressure to the producer clients, causing them to stop pulling data from upstream sources like databases or to write new data to local devices as a failover mechanism?
Availability is crucial, no one wants to sacrifice it. We're often willing to compromise other factors, such as latency and ordering, to ensure availability. For example, in a CDC pipeline, maintaining order is essential—we can't tolerate out-of-order data. This means we can't failover data from partition A to partition B when an error occurs. However, if we can tolerate latency, we can simply accumulate the data in the database, perhaps slowing down the process to wait for the service to become available again.
Ordering is fundamental to Kafka. Data within a partition is naturally ordered, stored one by one, and consumed in the same sequence. Typically, we assign the same key to all records that need to be totally ordered, ensuring they are sent to the same partition by producers. For this use case, we cannot sacrifice ordering. However, in many cases, such as clickstream data or logs, strong ordering guarantees are not necessary. We can send this data to any partition, which means we can automatically switch or isolate unavailable partitions to enhance availability.
Consistency : Let's define a new type of consistency for streaming. Consider a logical partition from the consumer's perspective. A consumer processes the data of this logical partition in a sequence from 1 to N. For this sequence, the offsets are sequential, with no gaps, no data loss, no redundancy, and the ability to repeatedly consume 1 to N at any time with the same result. It's clear that AutoMQ and Kafka natively provide consistency guarantees. However, if we want to use two clusters to serve the same business, ensuring the consistency we've defined becomes very difficult. If this isn't clear, consider the exact-once semantics provided by AutoMQ and Kafka.
Solutions
Client reliability engineering demands SLA-driven design: explicitly trading ordering, latency, and consistency models against failure resilience. Every solution maps to specific business tolerance levels — there's no universal approach, only intentional compromises aligned to your system's non-negotiable requirements.
Single cluster failover
Adaptive or Circuit Breaker Pattern
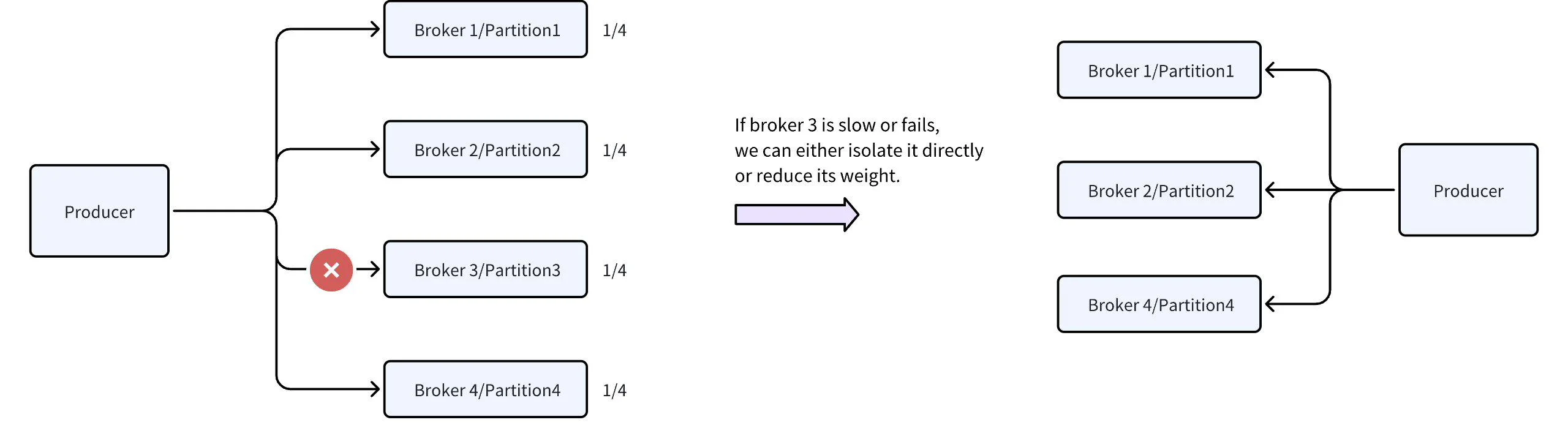
It's the easiest way to tolerate underlying service failures. As long as your cluster has sufficient capacity, it's no big deal if some nodes fail. On the client side, we use an adaptive partitioner to select healthy partitions or isolate brokers following the circuit breaker pattern.
Obviously, you can't ensure ordering when a failure occurs. But luckily, many scenarios can tolerate that.
KIP-794 has a detailed discussion about Adaptive Partition Switching , and there are two important parameters of this feature for Java clients. Other language clients may also support this KIP. If not, it’s easy for us to implement a custom partitioner. In fact, many large companies had already implemented it on their own before KIP-794.
partitioner.adaptive.partitioning.enable. The default would be 'true', if it's true then the producer will try to adapt to broker performance and produce more messages to partitions hosted on faster brokers. If it's 'false', then the producer will try to assign partitions randomly.
partitioner.availability.timeout.ms. The default would be 0. If the value is greater than 0 and adaptive partitioning is enabled, and the broker cannot accept a produce request to the partition for partitioner.availability.timeout.ms milliseconds, the partition is marked as not available.Backpressure to the source or buffer locally
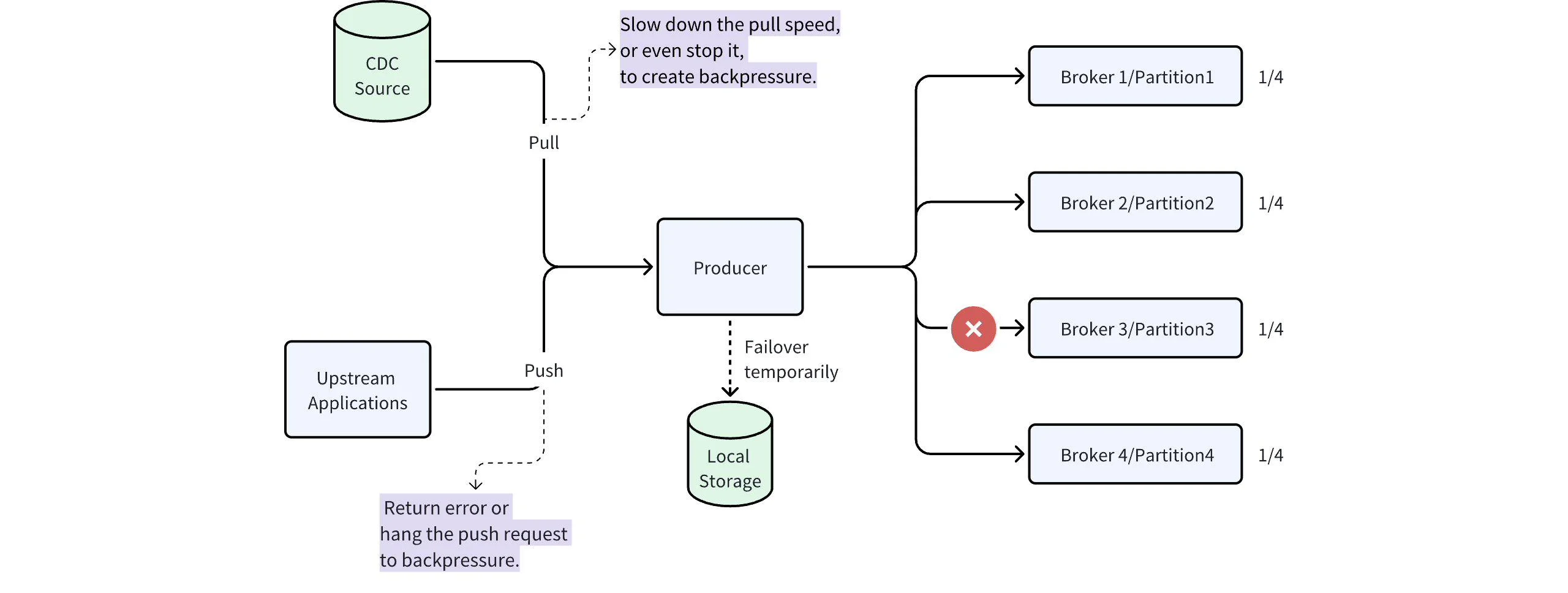
In some cases, the order of the data is crucial, but we can compute it later. It doesn't matter if the data is delayed by ten minutes or even hours. In such cases, we can backpressure the produce request to the sources when the underlying cluster is unavailable.
-
If your clients have local storage devices, you can temporarily buffer data to them and resend the data once your cluster recovers. In the trading systems of Taobao, clients support this capability, and it continues to function even if the entire cluster fails. To be honest, this feature has saved my career at Alibaba.
-
If it's a CDC pipeline, things are simpler—you can just slow down the pull speed and let data accumulate in the database, or even stop pulling, if your downstream system is unavailable.
-
Things could get more complicated if your upstream is a microservice that uses push requests to send data. However, backpressure can work if the upstream can handle your error codes or slow down when your latency increases.
Two clusters failover
In some ways, two clusters offer higher availability than a single cluster, but they are more complex and involve higher IT costs.
Two clusters without ordering
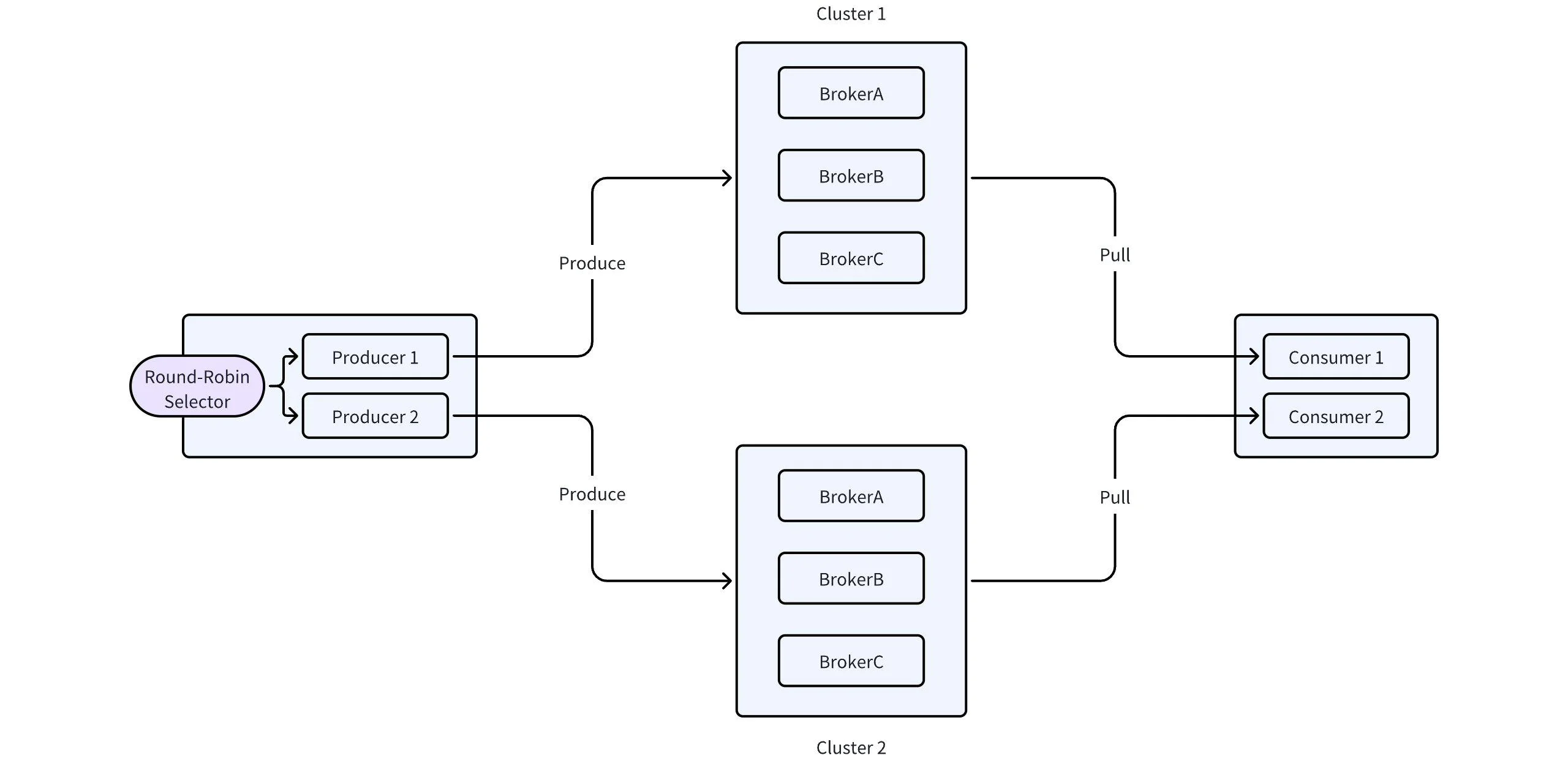
If you have two clusters and don't care about the ordering, it's easy to build a highly available architecture. Simply configure your clients with two producers and two consumers. The consumers will pull data from the two clusters, while the producers will write data to both clusters in a round-robin manner, isolating any failed cluster if necessary.
Two clusters with ordering
If you don't care about the order, you can optionally write the data to two clusters, and consumers will eventually fetch all the data. However, if order matters, you can't write data to both clusters simultaneously. Instead, you should follow a primary-secondary architecture and carefully switch the traffic.
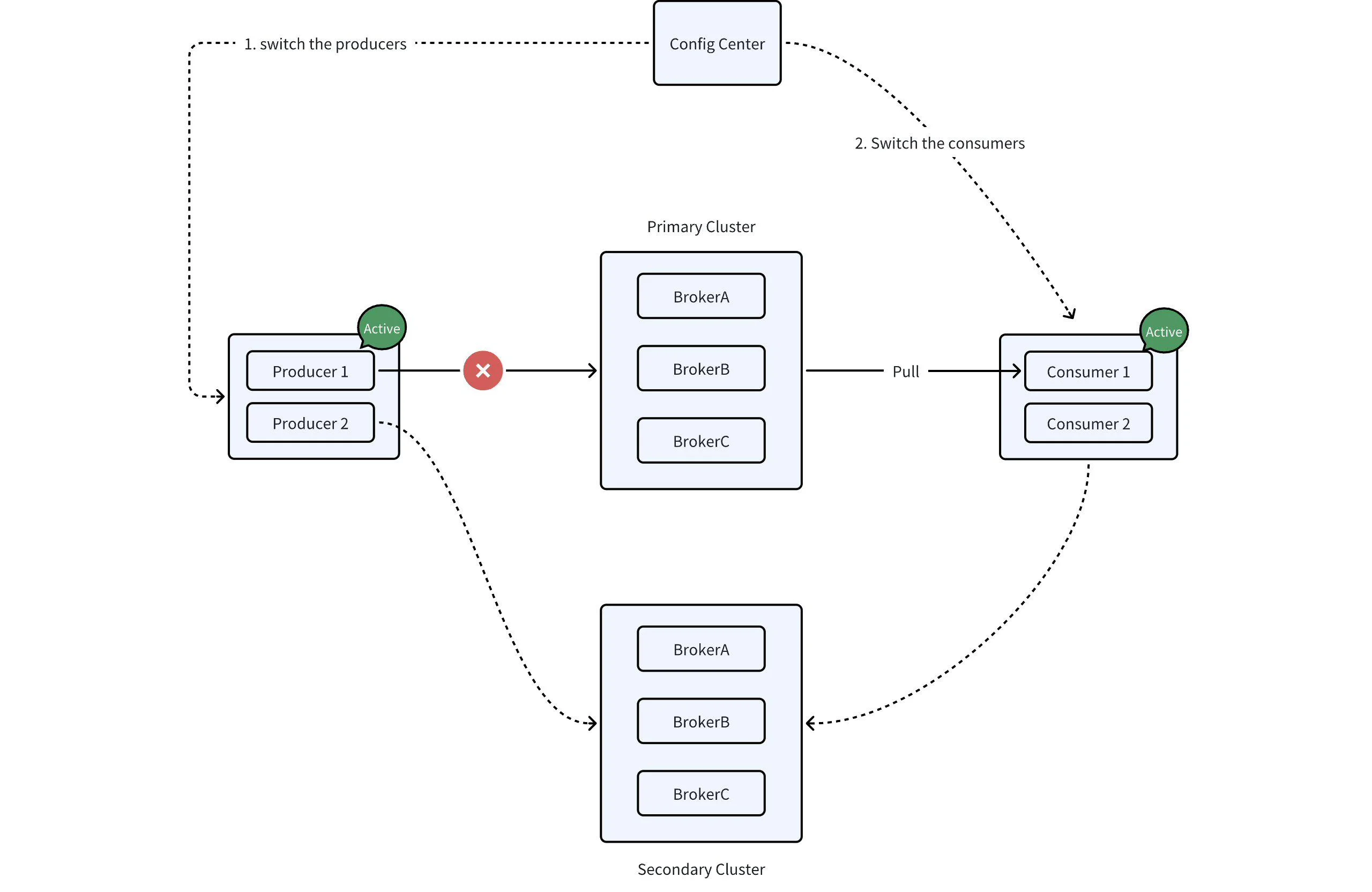
When the primary cluster is unavailable, you can switch to the secondary cluster. Remember the sequence of operations:
-
Switch the producers to the secondary cluster.
-
Wait for the switch to complete and for all data to be consumed by the consumers.
-
Switch the consumers to the secondary cluster.
There are two main challenges:
-
Who is responsible for making the decision to switch, and by what criteria?
-
The secondary cluster is on standby and doesn't handle traffic under normal conditions. So, when a switch is needed, can we ensure that the cluster is ready and has sufficient capacity?
Two clusters with replication
We've proposed two solutions for failover using two clusters, with no replication involved. So far, we've only focused on availability. However, if we're concerned about the durability of the AutoMQ cluster, what if there's a bug in the storage layer that causes data loss? Yes, we know that S3 provides 11 nines of durability through erasure coding, but that doesn't account for potential bugs.
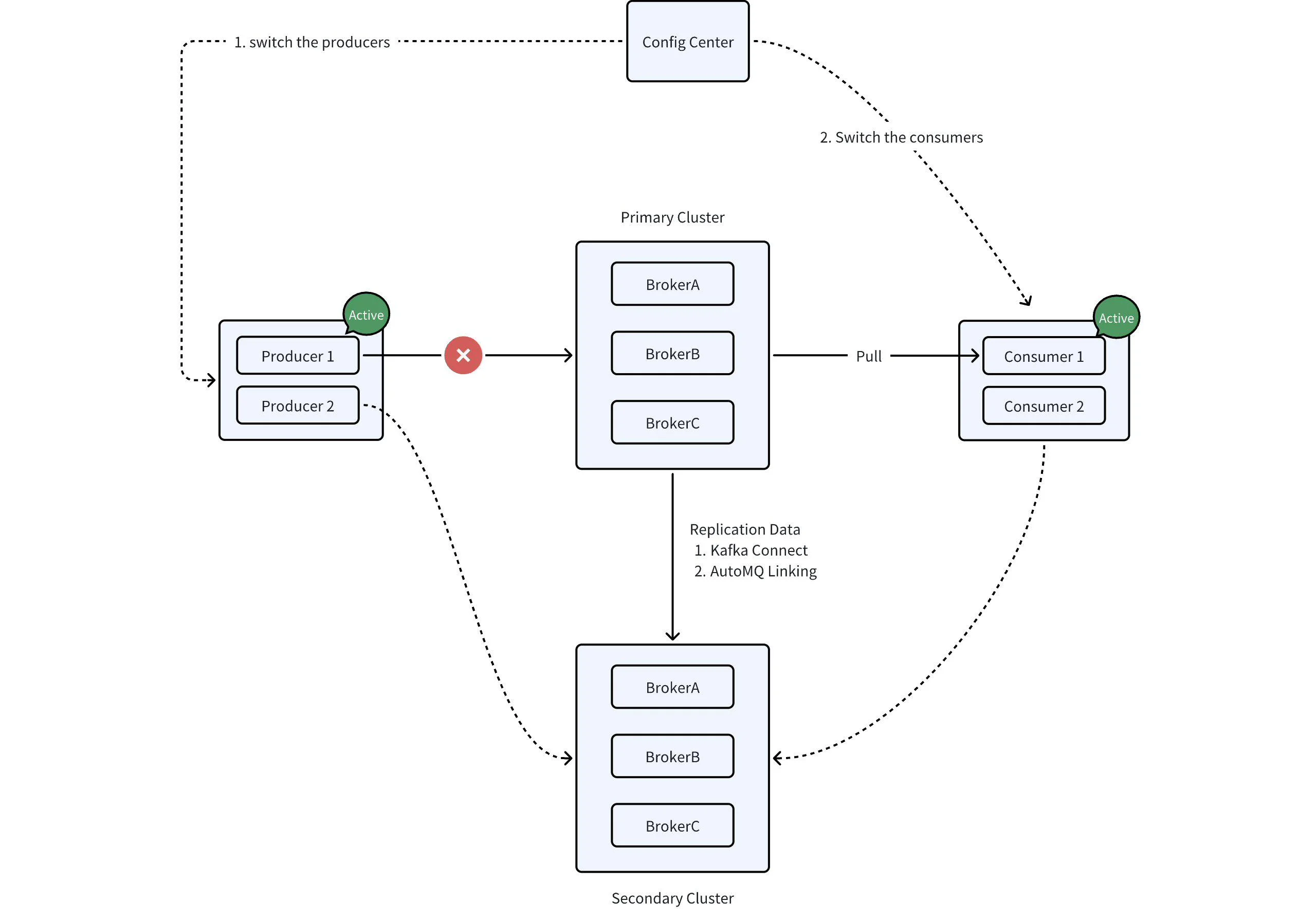
This is why some companies replicate data between clusters to enhance availability and durability. However, since replication occurs across two clusters, it is asynchronous. This means that if a disaster occurs and we switch to the new cluster, some data may be lost, resulting in an RPO that is not zero. Another issue is that clients must be able to tolerate a small number of duplicate messages (idempotency).
Additionally, there's a challenge: how can we switch back to the primary cluster after recovery?
Two clusters with bidirectional replication
It's very complex, and the resource naming conflict should be handled by the business application. You can contact us for more details: https://www.automq.com/contact
Is there a one-size-fits-all solution?
Can we use two clusters to ensure latency, availability, ordering, and consistency together? I don't think so. Consistency is the challenge here. Essentially, we need a single Raft or Paxos controller to achieve consensus. But if we use a Paxos controller to combine two clusters, I believe they would ultimately merge into one cluster again.
If you opt for failover support between two Kafka clusters, AutoMQ is your best choice. It is highly scalable, allowing you to maintain a small, cost-effective standby AutoMQ cluster for recovery. In the event your primary cluster goes down, you can quickly scale out your secondary AutoMQ cluster within a minute to handle your traffic seamlessly.
Conclusion
This article has examined various client-side strategies for enhancing the reliability and resilience of Kafka applications in the face of underlying service failures. Each strategy involves trade-offs between latency, availability, ordering, and consistency, emphasizing the need for SLA-driven design tailored to specific business requirements. While single-cluster strategies like adaptive partitioning and backpressure offer balanced trade-offs, multi-cluster approaches provide higher availability but often sacrifice consistency.
In summary, achieving a perfect solution that satisfies all dimensions is challenging, but vendors like AutoMQ(https://github.com/AutoMQ/automq) offer scalable and efficient failover support. By carefully selecting and combining these strategies, organizations can significantly improve the reliability of their Kafka applications, ensuring they meet the unique needs of their data architecture.


