.png)
Overview
Change Data Capture (CDC) is a powerful approach for tracking database changes in real-time, enabling organizations to build responsive, event-driven architectures that keep multiple systems synchronized. This comprehensive blog explores how Debezium and Apache Kafka work together to provide robust CDC capabilities for modern data integration needs.
Understanding Change Data Capture
Change Data Capture refers to the process of identifying and capturing changes made to data in a database, then delivering those changes to downstream systems in real-time. CDC serves as the foundation for data integration patterns that require immediate awareness of data modifications across distributed systems.
CDC has become increasingly important as organizations move toward event-driven architectures and microservices. Traditional batch-oriented ETL processes often create data latency issues that can impact decision-making and operational efficiency. By implementing CDC with Kafka and Debezium, organizations can achieve near real-time data synchronization between disparate systems, enabling more responsive applications and accurate analytics.
The technology works by monitoring database transaction logs (such as binlog in MySQL or WAL in PostgreSQL) which contain records of all changes made to the database, including insertions, updates, and deletions. CDC software reads these logs and captures the changes, which are then propagated to target systems[17].
What is Debezium?
Debezium is an open-source distributed platform specifically designed for change data capture. It continuously monitors databases and lets applications stream row-level changes in the same order they were committed to the database. Debezium is built on top of Apache Kafka and leverages the Kafka Connect framework to provide a scalable, reliable CDC solution[9].

The name "Debezium" (DBs + "ium") was inspired by the periodic table of elements, following the pattern of metallic element names ending in "ium"[11]. Unlike manually written CDC solutions, Debezium provides a standardized approach to change data capture that handles the complexities of database transaction logs and ensures reliable event delivery.
Debezium allows organizations to:
Monitor databases in real-time without modifying application code
Capture every row-level change (inserts, updates, and deletes)
Maintain event ordering according to the transaction log
Convert database changes into event streams for processing
Enable applications to react immediately to data changes
Architecture of CDC with Kafka and Debezium
The CDC architecture with Debezium and Kafka involves several key components working together to capture, store, and process change events.
Core Components
Debezium is most commonly deployed through Apache Kafka Connect, which is a framework and runtime for implementing and operating source connectors (that send records into Kafka) and sink connectors (that propagate records from Kafka to other systems)[12].
The basic architecture includes:
Source Database : The database being monitored (MySQL, PostgreSQL, MongoDB, etc.)
Debezium Connector : Deployed via Kafka Connect, monitors the database's transaction log
Kafka Brokers : Store and distribute change events
Schema Registry : Stores and manages schemas for events (optional but recommended)
Sink Connectors : Move data from Kafka to target systems
Target Systems : Where the change events are ultimately consumed (databases, data lakes, search indices, etc.)
Each Debezium connector establishes a connection to its source database using database-specific mechanisms. For example, the MySQL connector uses a client library to access the binlog, while the PostgreSQL connector reads from a logical replication stream[12].
How Debezium Works with Kafka
When Debezium captures changes from a database, it follows a specific workflow:
Connection Establishment : Debezium connects to the database and positions itself in the transaction log.
Initial Snapshot : For new connectors, Debezium typically performs an initial snapshot of the database to capture the current state before processing incremental changes.
Change Capture : As database transactions occur, Debezium reads the transaction log and converts changes into events.
Event Publishing : Change events are published to Kafka topics, typically one topic per table by default.
Schema Management : If used with Schema Registry, event schemas are registered and validated.
Consumption : Applications or sink connectors consume the change events from Kafka topics.
Debezium uses a "snapshot window" approach to handle potential collisions between snapshot events and streamed events that modify the same table row. During this window, Debezium buffers events and performs de-duplication to resolve collisions between events with the same primary key[8].
Implementation Guide
Configuring Debezium for CDC
Setting up a CDC pipeline with Debezium and Kafka involves several configuration steps:
Basic Setup Requirements
Kafka Cluster : Set up a Kafka cluster with at least three brokers for fault tolerance
Zookeeper : Configure Zookeeper for cluster coordination (if using older Kafka versions)
Kafka Connect : Deploy Kafka Connect workers to run Debezium connectors
Debezium Connector : Configure the specific connector for your database
Sink Connectors : Configure where the data should flow after reaching Kafka
Connector Configuration Example
Below is an example configuration for a MongoDB connector[16]:
{
"name": "mongodb-connector",
"config": {
"connector.class": "io.debezium.connector.mongodb.MongoDbConnector",
"mongodb.hosts": "rs0/localhost:27017",
"mongodb.user": "debezium",
"mongodb.password": "dbz",
"mongodb.name": "dbserver1",
"database.include.list": "mydb",
"collection.include.list": "mydb.my_collection"
}
}
Common Challenges and Solutions
While CDC with Debezium offers significant benefits, several challenges must be addressed:
Complex Setup and Configuration
The initial setup of Debezium with Kafka involves multiple components and configurations. Each component must be properly configured to work together seamlessly[16].
Solution : Consider using managed services such as Confluent Cloud, which provides pre-configured environments for Debezium and Kafka. Alternatively, use containerization with Docker and Kubernetes to simplify deployment.
Limited Exactly-Once Delivery Guarantees
Debezium provides at-least-once delivery semantics, meaning duplicates can occur under certain conditions, especially during failures or restarts[16].
Solution : Implement idempotent consumers that can handle duplicate messages gracefully. Use Kafka's transaction support where possible and design systems to be resilient to duplicate events.
Schema Evolution Management
As databases evolve over time, managing schema changes becomes challenging for CDC pipelines[13].
Solution : Implement a Schema Registry to manage schema evolution. Follow best practices for schema evolution such as providing default values for fields and avoiding renaming existing fields.
High Availability and Failover
Database failovers can interrupt CDC processes, especially for databases like PostgreSQL where replication slots are only available on primary servers[16].
Solution : Configure Debezium with appropriate heartbeat intervals and snapshot modes. Set the snapshot mode to 'when_needed' to handle recovery scenarios efficiently[3].
Best Practices
Security Configuration
Enable SSL/TLS for all connections
Implement authentication with SASL mechanisms
Configure proper authorization controls
Use HTTPS for REST API calls
High Availability Setup
Deploy multiple Kafka Connect instances for redundancy
Use a virtual IP (VIP) in front of Kafka Connect instances
Ensure consistent configuration across all instances
Configure unique hostnames for each instance
Topic Configuration
Use topic compaction for Debezium-related topics (especially schemas, configs, and offsets)
Configure adequate replication factors (at least 3)
Protect critical topics from accidental deletion
Consider topic naming strategies based on your use case
Schema Evolution
Provide default values for all fields that might be removed
Never rename existing fields - instead, use aliases
Never delete required fields from schemas
Add new fields with default values to maintain compatibility
Create new topics with version suffixes for complete schema rewrites
Performance Tuning
Configure appropriate batch sizes and linger times for producers
Tune consumer fetch sizes and buffer memory
Monitor and adjust connector tasks based on workload
Consider disabling tombstones if deleted records don't need to be propagated
Use Cases
CDC with Debezium and Kafka is particularly well-suited for:
Real-time Data Synchronization : Keeping multiple databases in sync with minimal latency
Event-Driven Architectures : Building reactive systems that respond to data changes
Microservices Integration : Enabling communication between services via data change events
Data Warehousing : Continuously updating analytics systems with fresh data
Cache Invalidation : Automatically refreshing caches when source data changes
However, for scenarios where real-time updates are not critical, simpler alternatives like JDBC Source connectors that periodically poll for changes might be sufficient[3].
Conclusion
Change Data Capture with Kafka and Debezium provides a powerful framework for real-time data integration. By capturing changes directly from database transaction logs and streaming them through Kafka, organizations can build responsive, event-driven architectures that maintain data consistency across diverse systems.
While implementing CDC with Debezium presents certain challenges around configuration, schema management, and delivery guarantees, these can be addressed through proper architecture design and adherence to best practices. The benefits of real-time data integration, reduced system coupling, and improved data consistency make CDC with Kafka and Debezium an essential approach for modern data architectures.
As data volumes and velocity continue to increase, the ability to respond immediately to data changes becomes increasingly valuable. Organizations that implement CDC effectively gain a competitive advantage through more timely insights and more responsive applications, enabling better decision-making and improved customer experiences.
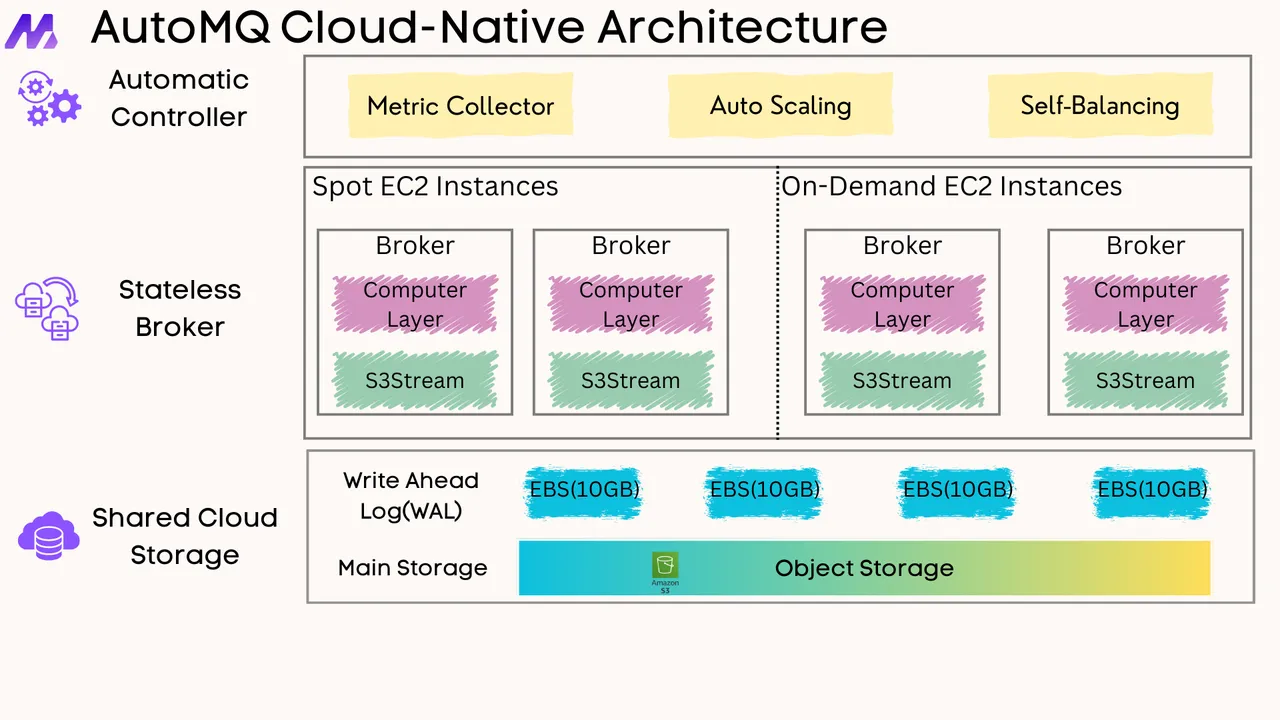
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
JD.comx AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging