


.png)
Data is a critical asset in the modern enterprise, and its entire journey from creation to deletion demands strategic oversight. While unmanaged data can quickly become a liability, well-managed data drives immense value. Data Lifecycle Management provides the essential framework for this control, ensuring security, compliance, and quality. This blog post offers a comprehensive technical guide to understanding and implementing effective DLM strategies, detailing its core stages, key concepts, and best practices.
Understanding the Data Lifecycle
The data lifecycle describes the various stages data passes through from its inception to its retirement. While different models exist, they generally cover similar core phases. A common understanding of these stages is crucial for effective data management.
Typical Stages of the Data Lifecycle:
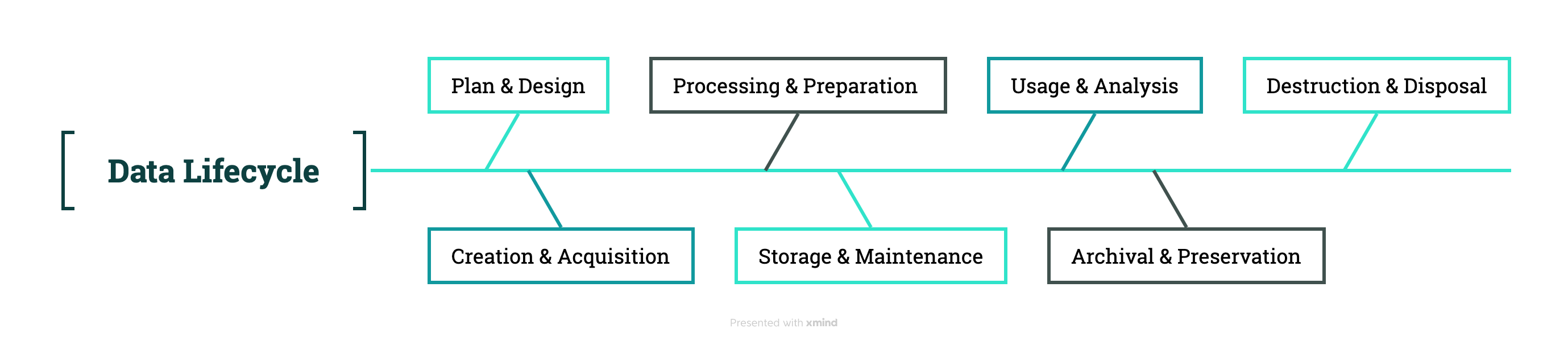
Plan & Design : This foundational stage involves defining business needs and how data will support them . Activities include outlining data requirements, establishing governance policies (including security, privacy, and compliance frameworks), defining retention schedules, and planning for necessary resources and technologies. The objective is to create a clear roadmap for how data will be collected, managed, used, and protected in alignment with strategic goals.
Key Activities : Data modeling, defining data standards, risk assessment.
Tools : Data modeling tools, collaboration platforms, Governance, Risk, and Compliance (GRC) software.
Creation & Acquisition (Generation/Collection/Capture) : This is where data is born or brought into the organization . Data can be generated internally (e.g., through transactions, application logs, IoT devices) or acquired from external sources (e.g., third-party data providers, public datasets, user-submitted information). The focus is on gathering relevant and high-quality raw data.
Key Activities : Data entry, sensor data collection, web scraping, API integration, data discovery.
Tools : Data ingestion tools, ETL (Extract, Transform, Load) platforms, streaming data platforms (like Apache Kafka), APIs, survey tools.
Processing & Preparation (Cleaning/Wrangling/Transformation) : Raw data is often inconsistent, incomplete, or inaccurate. This stage involves refining it to make it usable . Activities include validating data against defined rules, cleaning errors, removing duplicates, transforming data into suitable formats or structures, enriching it with additional information, and masking or encrypting sensitive data elements.
Key Activities : Data validation, data cleansing, deduplication, data normalization, data enrichment, data masking.
Tools : Data integration platforms, data quality tools, scripting languages (e.g., Python with libraries like Pandas), distributed processing frameworks (e.g., Apache Spark).
Storage & Maintenance (Management) : Processed data needs to be stored securely and efficiently . This stage involves selecting appropriate storage systems (e.g., relational databases, NoSQL databases, data warehouses, data lakes, or lakehouse architectures) based on data characteristics and access requirements. It also includes ongoing maintenance activities like metadata management, implementing backup and recovery procedures, managing access controls, and monitoring performance.
Key Activities : Database management, metadata cataloging, backup and disaster recovery planning, security administration.
Tools : Relational Database Management Systems (RDBMS) like PostgreSQL, MySQL; NoSQL databases; cloud storage (e.g., Google Cloud Storage, Azure Blob Storage, Amazon S3); data warehousing solutions (e.g., Snowflake, Google BigQuery); data lakehouse platforms (e.g., Databricks).
Usage & Analysis (Visualization/Interpretation/Sharing/Deployment) : This is where the value of data is realized . Data is accessed and utilized for various purposes, including operational tasks, business intelligence (BI), reporting, advanced analytics (such as machine learning and AI), and data-driven decision-making. Insights are often shared through visualizations and reports.
Key Activities : Data querying, statistical analysis, machine learning model training, report generation, dashboard creation, data sharing.
Tools : BI tools (e.g., Tableau, Microsoft Power BI), SQL, analytical programming languages (Python, R), machine learning platforms, API endpoints for data access.
Archival & Preservation : Data that is no longer actively used but needs to be retained for legal, regulatory, historical, or compliance reasons is moved to an archive . Archival strategies focus on cost-effective, long-term storage while ensuring data integrity and accessibility if needed. This may involve format migration to ensure future readability.
Key Activities : Identifying inactive data, data compression, transferring data to archive storage, ensuring long-term retrievability.
Tools : Archive-tier cloud storage, tape storage systems, digital preservation software, Information Lifecycle Management (ILM) tools (e.g., from SAP or Informatica).
Destruction & Disposal (Deletion/Purging) : At the end of its lifecycle, data must be securely and permanently destroyed in accordance with retention policies and legal obligations . This minimizes risks associated with holding unnecessary data and frees up storage resources. Proper documentation of destruction is also important.
Key Activities : Secure data wiping, degaussing of magnetic media, physical destruction of media, cryptographic erasure, certificate of destruction.
Tools/Standards : Data destruction services, shredders, software-based data sanitization tools, adherence to standards like NIST SP 800-88 .
Key Concepts in Data Lifecycle Management
Several overarching concepts are critical to successfully managing data throughout its lifecycle:
Data Governance : This is the framework of rules, policies, standards, processes, and controls for managing and using an organization's data assets . Effective data governance ensures data is accurate, consistent, secure, and used appropriately at every stage of its lifecycle. It defines roles and responsibilities (e.g., data owners, data stewards) and provides oversight.
Data Quality : Maintaining high data quality is essential for deriving reliable insights and making sound business decisions. Data quality management involves processes to measure, monitor, and improve the accuracy, completeness, consistency, timeliness, validity, and uniqueness of data throughout its lifecycle.
Data Security : Protecting data from unauthorized access, use, disclosure, alteration, or destruction is paramount . Security measures include encryption, access controls, authentication, regular security audits, and threat detection and response. These must be applied at each lifecycle stage.
Data Privacy : With regulations like GDPR and CCPA, ensuring data privacy is a legal and ethical obligation . This involves handling personal data transparently, obtaining consent where required, and upholding data subject rights (e.g., the right to access, rectify, or erase data). Privacy-enhancing techniques like anonymization and pseudonymization are often employed.
Metadata Management : Metadata, or "data about data," provides context and understanding for data assets . It includes information about data definitions, formats, structures, lineage, and usage. Effective metadata management is crucial for data discovery, integration, governance, and understanding data flow.
Data Lineage : Data lineage tracks the origin, movement, transformations, and dependencies of data throughout its lifecycle . It provides an audit trail that is vital for troubleshooting data quality issues, understanding the impact of changes, and meeting regulatory compliance requirements.
Data Retention & Disposal : Data retention policies define how long specific types of data should be kept and when they should be securely disposed of . These policies are driven by legal, regulatory, and business requirements. Secure disposal ensures data cannot be recovered and misused.
Common Issues and Challenges in DLM
Organizations often face several challenges when implementing DLM:
Data Volume & Variety (Big Data) : The sheer volume, velocity, and variety of data generated today can overwhelm traditional data management systems and practices .
Data Silos : Data is often fragmented across different departments and systems, making it difficult to get a unified view and manage consistently .
Ensuring Data Quality : Maintaining data accuracy and consistency across disparate sources and throughout transformations is a continuous challenge .
Security and Compliance Risks : Protecting sensitive data and adhering to complex and evolving regulations (e.g., GDPR, CCPA, HIPAA) requires significant effort and expertise .
Managing Costs : Storing and managing vast amounts of data, especially high-performance storage for active data, can be expensive. Optimizing storage through tiering and timely archival/deletion is key .
Lack of Skilled Personnel : Effective DLM requires expertise in data governance, security, data engineering, and analytics, which can be hard to find and retain.
Integrating New Technologies : Incorporating new technologies like AI/ML or new data platforms into existing DLM frameworks can be complex.
Defining and Enforcing Policies : Creating comprehensive data policies and ensuring they are consistently applied across the organization is a significant undertaking.
Solutions and Technologies by Lifecycle Stage
Different tools and technologies support various stages of the data lifecycle:
Plan & Design : Data modeling tools (e.g., Erwin, ER/Studio), GRC platforms, Project management software.
Creation & Acquisition : ETL tools (Informatica PowerCenter, Talend Data Fabric), Streaming platforms (Apache Kafka), Data ingestion services (Azure Data Factory, Google Cloud Dataflow), APIs.
Processing & Preparation : Data integration platforms (Databricks, Talend), Data quality tools (Collibra DQ), Scripting (Python/Pandas, R), Apache Spark.
Storage & Maintenance : RDBMS (PostgreSQL, Oracle Database), NoSQL DBs (MongoDB, Cassandra), Cloud Storage (Google Cloud Storage, Azure Blob Storage, S3), Data Warehouses (Snowflake, Google BigQuery), Data Lakes, Data Lakehouses (Databricks), Metadata catalogs (Alation, Collibra Catalog).
Usage & Analysis : BI Platforms (Tableau, Power BI, Qlik Sense), SQL clients, Python/R IDEs, AI/ML platforms (Vertex AI, Azure Machine Learning), Data APIs.
Archival & Preservation : Cloud archive storage (Google Cloud Archive, Azure Archive Storage, Amazon S3 Glacier), Tape libraries, ILM solutions (SAP ILM, Informatica ILM), Digital preservation tools.
Destruction & Disposal : Data sanitization software, Physical shredders, Degaussers, Cryptographic erasure methods, Certified destruction services.
Cloud providers like Google Cloud, Microsoft Azure, and AWS offer a suite of services that cover many aspects of the data lifecycle, including storage tiering, automated lifecycle policies, data integration, analytics, and machine learning tools .
Best Practices for Data Lifecycle Management
Implementing effective DLM requires a strategic approach and adherence to best practices:
Establish Strong Data Governance : Implement a clear governance framework with defined roles, responsibilities, policies, and standards from the outset .
Understand Your Data : Discover, classify, and understand your data assets, including their sensitivity, value, and regulatory requirements .
Develop Comprehensive Policies : Create clear, actionable policies for data quality, security, privacy, retention, and disposal .
Automate Where Possible : Use automation for repetitive tasks like data ingestion, quality checks, backups, tiering, and enforcement of retention policies to improve efficiency and consistency .
Prioritize Data Security and Privacy : Embed security and privacy considerations into every stage of the data lifecycle ("security by design" and "privacy by design") .
Focus on Data Quality : Implement processes and tools to monitor and improve data quality continuously.
Manage Metadata Actively : Maintain a robust metadata repository to ensure data is discoverable, understandable, and trustworthy .
Implement Robust Backup and Recovery : Ensure critical data can be recovered in case of system failures, disasters, or cyberattacks .
Regularly Review and Update : Periodically review and update DLM policies, procedures, and technologies to adapt to changing business needs, regulations, and technological advancements .
Foster a Data-Driven Culture : Educate employees on the importance of data management and their roles in upholding data policies. Encourage responsible data handling and usage across the organization .
Plan for End-of-Life : Define clear processes for data archival and secure destruction based on legal and business requirements .
By adopting a structured approach to data lifecycle management, organizations can mitigate risks, reduce costs, ensure compliance, and unlock the full strategic value of their data assets.
Conclusion
Effectively managing the data lifecycle is no longer a luxury but a necessity for modern organizations. From initial planning and creation through processing, storage, usage, and eventual disposal, each stage presents unique opportunities and challenges. By implementing robust data lifecycle management practices, underpinned by strong governance, a commitment to data quality, and proactive security measures, businesses can transform data from a potential liability into a powerful strategic asset.
Addressing common issues such as data silos, security risks, and compliance complexities requires a holistic approach that integrates people, processes, and technology. Leveraging appropriate frameworks, tools, and automation, and fostering a data-driven culture are key to navigating the complexities of DLM. Ultimately, a well-executed DLM strategy enables organizations to make better decisions, improve operational efficiency, reduce costs, meet regulatory obligations, and gain a significant competitive advantage in an increasingly data-centric world. The journey requires ongoing commitment and adaptation, but the rewards of treating data as a critical asset throughout its lifecycle are substantial.
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
JD.comx AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging






