


.png)
Overview
Apache Kafka has revolutionized how organizations handle real-time data streams, becoming a cornerstone of modern data architectures. This blog explores the landscape of ETL (Extract, Transform, Load) tools for Kafka in 2025, analyzing their strengths, limitations, and use cases to help organizations make informed decisions about their data integration strategies.
The Evolution of ETL with Kafka
Traditional ETL processes were designed for batch processing, where data is collected, transformed, and loaded periodically. However, the increasing demand for real-time insights has driven a fundamental shift toward streaming ETL. Kafka stands at the center of this transformation, offering a platform that enables continuous data processing rather than periodic batch jobs.
As one industry expert noted in a Confluent blog post, "Apache Kafka is more disruptive than merely being faster ETL. The future of how data moves in the enterprise isn't just a real-time Informatica." Indeed, Kafka represents a paradigm shift where event streams become first-class citizens in the data architecture, rather than mere byproducts of moving data between databases.
From ETL to Streaming ETL
The transition from traditional ETL to streaming ETL has several important implications:
"Real-time ETL or streaming ETLs are the future as they enable near-real-time data processing, helping organizations respond more quickly to changing conditions and opportunities. They also provide greater flexibility, allowing organizations to add new data sources or target systems without disrupting existing pipelines."
Unlike batch ETL tools that run on schedules, streaming ETL with Kafka processes data continuously as it arrives, enabling immediate analysis and action. This capability has transformed how organizations approach data integration, breaking down the historical separation between operational and analytical systems.
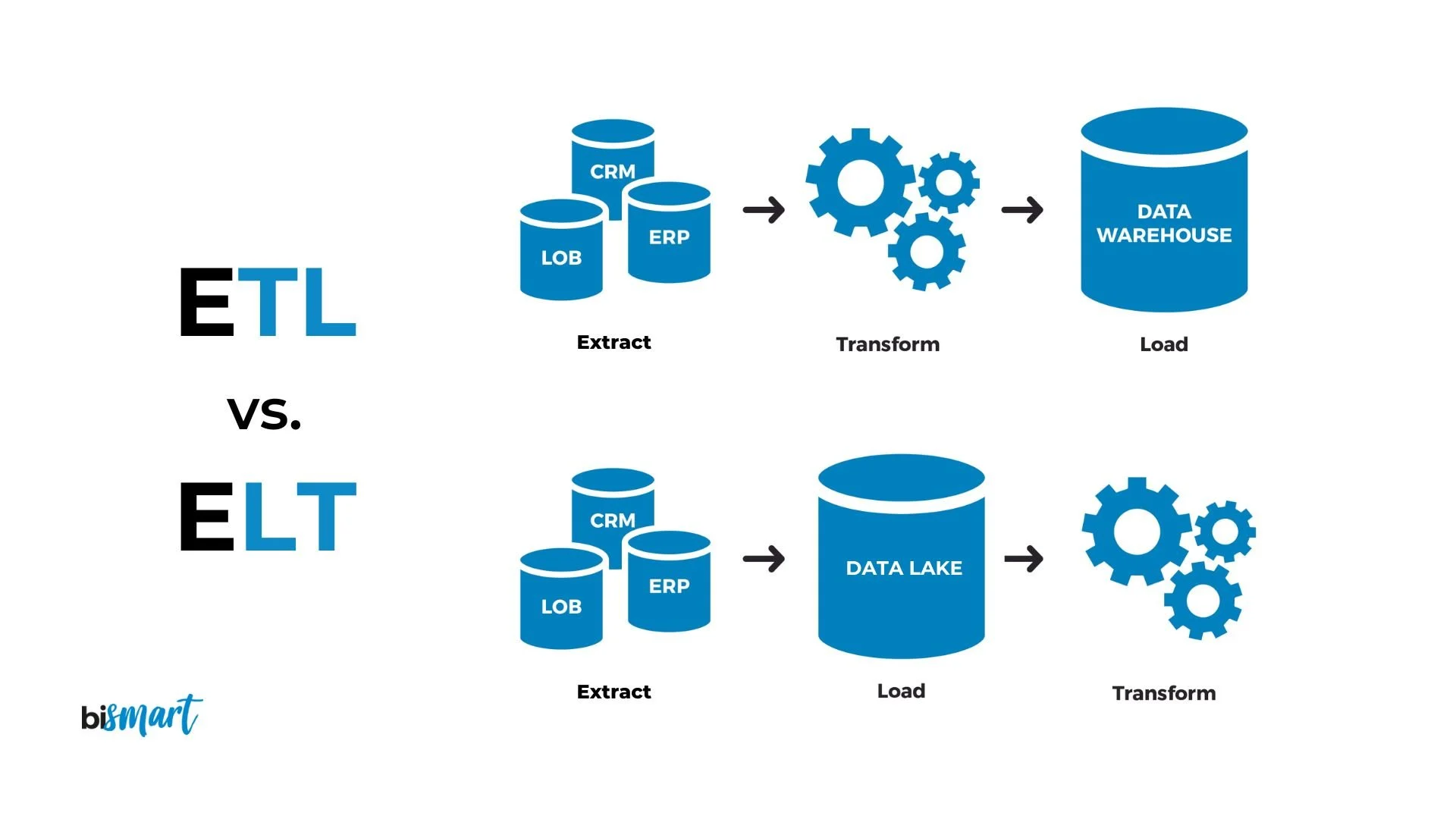
Core ETL Tools for Kafka in 2025
The ecosystem of ETL tools compatible with Kafka has expanded significantly, with options ranging from native Kafka components to third-party solutions designed for different use cases and technical requirements.
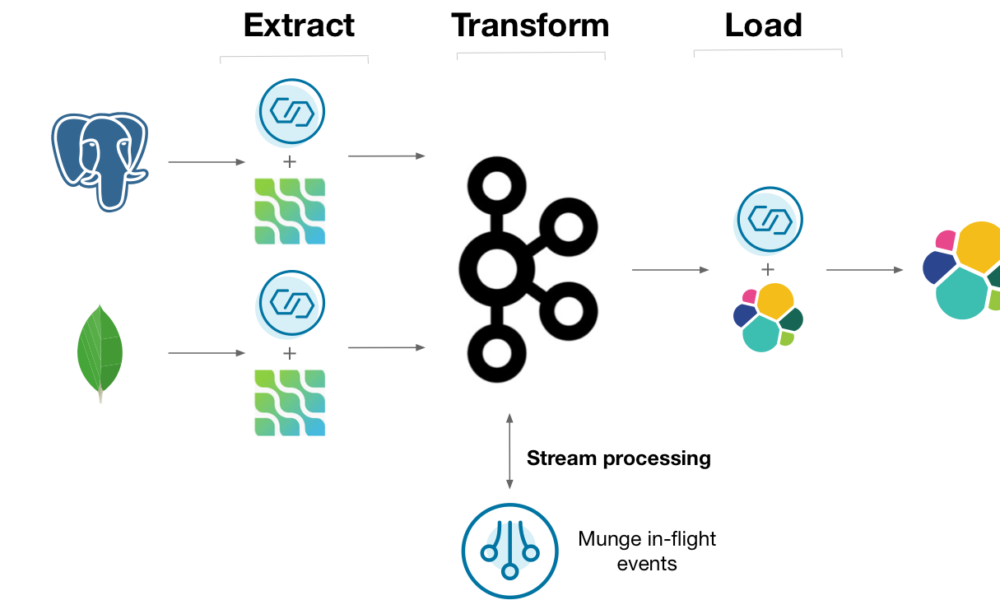
Native Kafka ETL Solutions
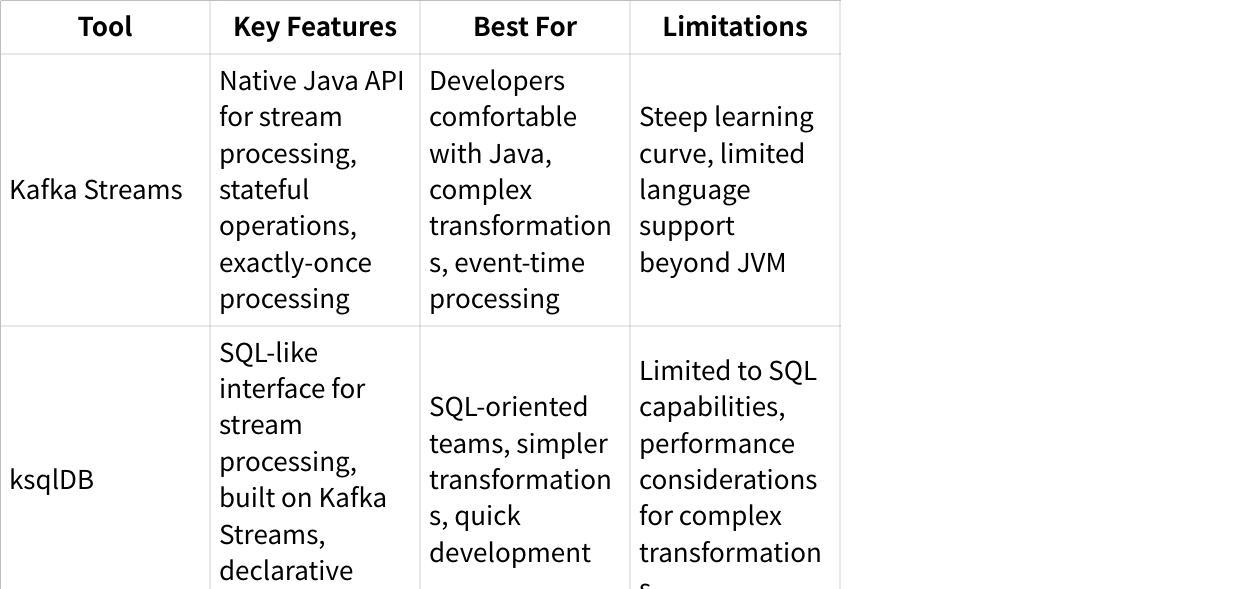
"Kafka streams 100%. It integrates with Kafka better than any other ETL framework." This sentiment reflects the preference for native solutions when deep integration with Kafka is required.
Third-Party Stream Processing Solutions
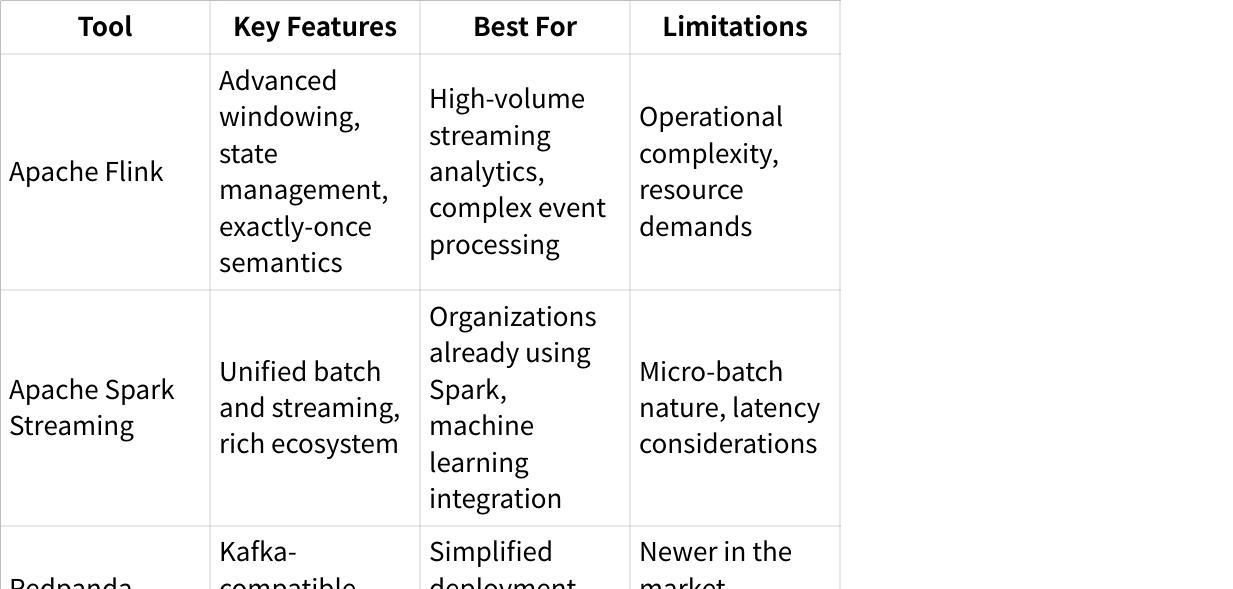
"Flink is technically superior to KStreams/KSQL. Companies that go for a kafka centric EDA integration architecture may be encouraged to build new solutions and replace legacy spaghetti/tool based point to point integrations standardizing on confluent."
General-Purpose ETL Tools with Kafka Support
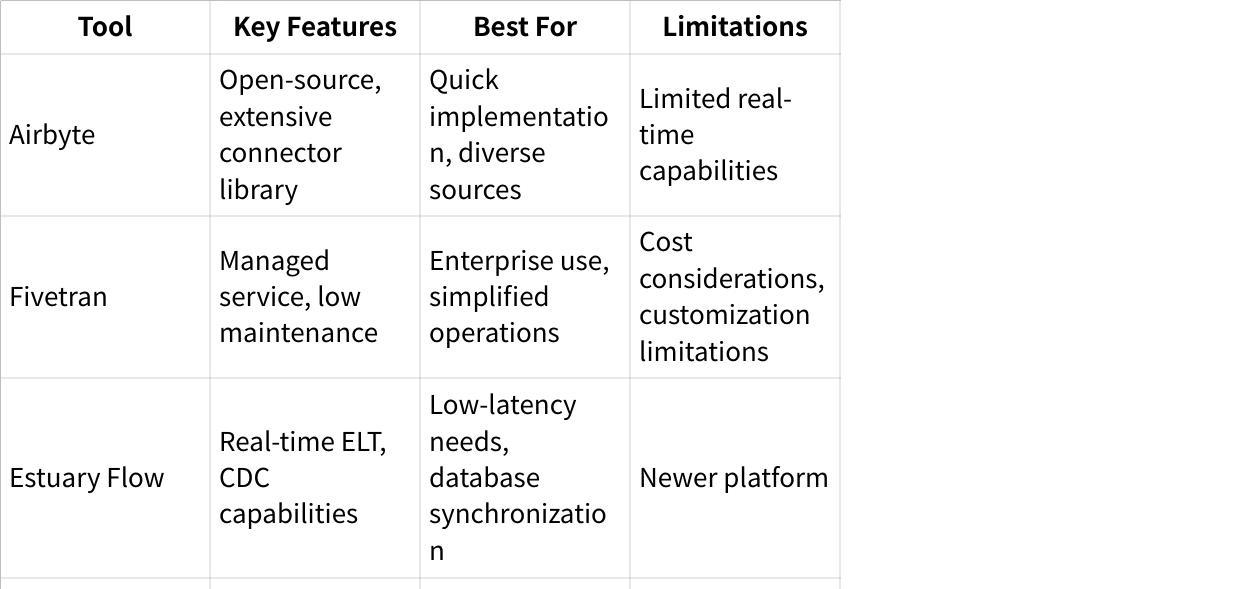
"Estuary Flow(estuary.dev) is a strong contender. It integrates seamlessly with platforms like Snowflake and Google Cloud, simplifying data source connections. Estuary excels at capturing data changes in real-time, keeping your pipelines brimming with the latest data."
Specialized ETL Use Cases for Kafka
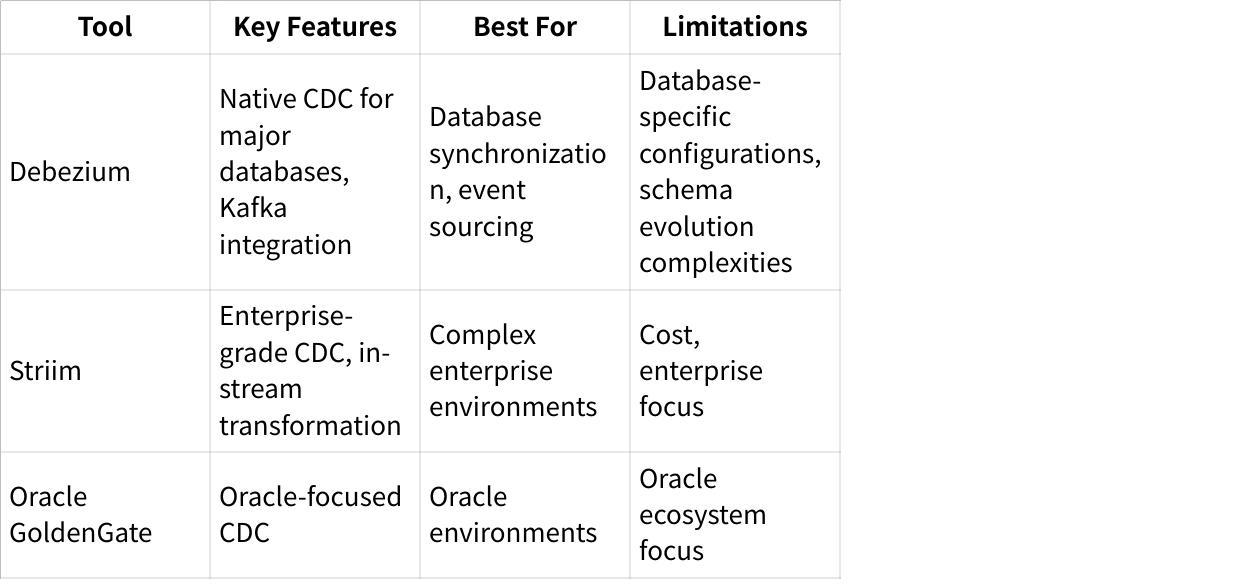
Change Data Capture (CDC)
CDC has become a critical use case for Kafka-based ETL solutions, enabling real-time database synchronization and event sourcing:
Cloud Provider Integrations
Major cloud providers offer their own Kafka-compatible streaming ETL solutions:

"Standard pattern I've seen for this is to use a combination of SQS, lambda, step functions, and EventBridge (formerly cloudwatch events)."
Key Considerations for Selecting Kafka ETL Tools
Performance and Scalability
Performance remains a critical consideration for Kafka ETL tools, particularly for high-volume streaming scenarios:
"Streaming ETL systems can be resource-intensive, and performance tuning is critical to ensure that the system handles the load. This includes optimizing data serialization, compression, partitioning, and tuning batch and buffer sizes to balance throughput and latency."
Organizations should evaluate tools based on their throughput requirements, latency expectations, and scaling capabilities. Native solutions like Kafka Streams generally offer better performance integration, while managed services may provide easier scaling with some performance tradeoffs.
Ease of Use vs. Flexibility
ETL tools for Kafka span a spectrum from highly code-centric (Kafka Streams, Flink) to more visual, low-code approaches (NiFi, some commercial platforms). Organizations must balance the need for flexibility and customization against development speed and accessibility.
Data Quality and Error Handling
Data quality becomes increasingly important in streaming contexts where errors can propagate quickly:
"Implement error handling. Streaming ETL systems are complex and can fail unexpectedly... ensure you have a robust error-handling mechanism that can recover from failures. Another critical component is dead-letter topic (DLT) events. If a message fails while processing, it can be put into the DLT and recovered later, without losing the original message."
Cost Considerations
Cost structures vary significantly across the Kafka ETL ecosystem:
"Confluent is EXPENSIVE. We have worked with 20+ large enterprises this year, all of which are moving or unhappy with the costs of Confluent..."
While open-source solutions may appear cost-effective initially, organizations must consider the total cost of ownership, including development, operation, and maintenance. Managed services typically have higher direct costs but can reduce operational overhead.
Schema Management
Schema evolution management is critical for long-running Kafka ETL pipelines:
"As databases evolve over time, managing schema changes becomes challenging for CDC pipelines."
Tools that offer strong schema registry integration and compatible schema evolution patterns help mitigate this challenge.
Common Challenges and Best Practices
Addressing Schema Evolution
Schema evolution remains one of the most significant challenges in Kafka ETL pipelines. The best approaches include:
Using Schema Registry for centralized schema management
Following compatibility rules (backward, forward, or full compatibility)
Employing data contracts between producers and consumers
Planning for schema changes from the outset
Managing State and Failures
Stateful processing in streaming ETL introduces complexity around failure handling:
Implement idempotent transformations where possible
Use dead-letter queues for failed messages
Design for exactly-once processing semantics when required
Implement robust monitoring and alerting
Security Considerations
"Implement data security. Streaming ETL systems can handle sensitive data, and it is essential to secure your data at rest and in transit. This includes encrypting data, using secure connections, and implementing access controls."
Operational Excellence
For production Kafka ETL pipelines:
Monitor system health and performance
Implement comprehensive logging
Use Kafka's partition model effectively for parallelism
Design for horizontal scaling
Test thoroughly, including failure scenarios
Future Trends in Kafka ETL for 2025
The Kafka ETL landscape continues to evolve rapidly, with several key trends emerging for 2025:
Increased AI Integration : ETL tools are incorporating AI for anomaly detection, data quality, and optimization.
Low-Code/No-Code Expansion : More visual interfaces and simplified development experiences are emerging.
Convergence of Batch and Streaming : Tools that unify batch and streaming paradigms (Lambda and Kappa architectures).
Edge Processing Integration : Extending ETL capabilities to edge environments.
Serverless Processing Models : Growth in event-driven, serverless processing options.
"Kafka is streaming so look for streaming data sources. It allows for brokering of streams across different services. Like think setting up a web cam on your fish tank and streaming that to multiple services for processing real'ish time."
Conclusion
The Kafka ETL landscape for 2025 offers a rich ecosystem of tools, each with distinct strengths and limitations. Organizations must carefully evaluate their specific requirements, technical capabilities, and strategic objectives when selecting the appropriate solution.
Native Kafka solutions like Kafka Streams and ksqlDB offer deep integration and performance advantages for teams with the technical expertise to utilize them. General-purpose ETL tools with Kafka support provide easier implementation but may have limitations for complex streaming scenarios. Specialized solutions for CDC and other use cases address specific needs but may introduce additional complexity.
As one expert noted, "ETL as we have known it is under the same evolutionary pressures as any other part of the technology ecosystem, and is changing rapidly." By understanding the capabilities, limitations, and best practices of the available ETL tools for Kafka, organizations can navigate this changing landscape effectively and build data integration pipelines that deliver real-time insights and value.
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
JD.comx AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging






