
Background
In recent years, both overseas and domestically, despite the impact of the pandemic slowing the growth rate of the public cloud market, the total market size of the cloud is still growing. As a strategic direction being heavily invested in by various countries, and with its own positioning in the trillion-dollar market, it is very necessary for us to learn how to use the cloud effectively.
AutoMQ Kafka fully recognizes the importance of a 'cloud-first' approach and has redesigned Kafka around the scalable benefits and technical dividends of cloud infrastructure. While ensuring 100% compatibility with Apache Kafka, it brings extreme cloud cost advantages and elasticity, with a comprehensive cost savings of more than 10 times on the cloud. Today, I want to share with you one of AutoMQ Kafka's cost-saving tools on the cloud, Spot instances.
Challenges of Using Spot Instances
Spot instances are essentially a type of instance purchase. Spot instances are the product of the cost benefits of cloud computing instance scaling, offering a cheaper type of instance purchase by improving utilization through time-sharing of machines. This is also a scalable advantage brought by cloud manufacturers compared to the fixed resource reservations of private IDC self-built data centers. The hardware capabilities of Spot instances are no different from those of regular-priced on-demand instances, but their price can be as low as one-tenth of the price of on-demand instances. Using Spot instances well can result in significant cost savings for software systems in the cloud.
Using Spot instances is essentially taking advantage of cloud manufacturers. The attractive price of Spot instances is tempting, but the biggest problem is their uncertainty. Cloud manufacturers do not provide SLAs for the availability of Spot instances, and according to the rules of cloud manufacturers, they will initiate the Spot instance recovery process and terminate Spot instances when necessary. For AutoMQ, the main challenge is how to use Spot instances in a deterministic way to provide users with SLA, reliable Kafka services. AutoMQ Kafka significantly reduces overall computing costs by using Spot instances extensively. After many practices, we have found some methods to provide reliable Kafka services on Spot instances.
Providing Reliable Services on Unreliable Spot Instances
Broker Stateless
Due to the inherent interruptible nature of Spot instances, the best practices for cloud manufacturers' Spot instances will mostly emphasize that Spot instances are suitable for stateless applications. Therefore, the more thoroughly a software system achieves 'statelessness', the more thoroughly Spot instances will be utilized.
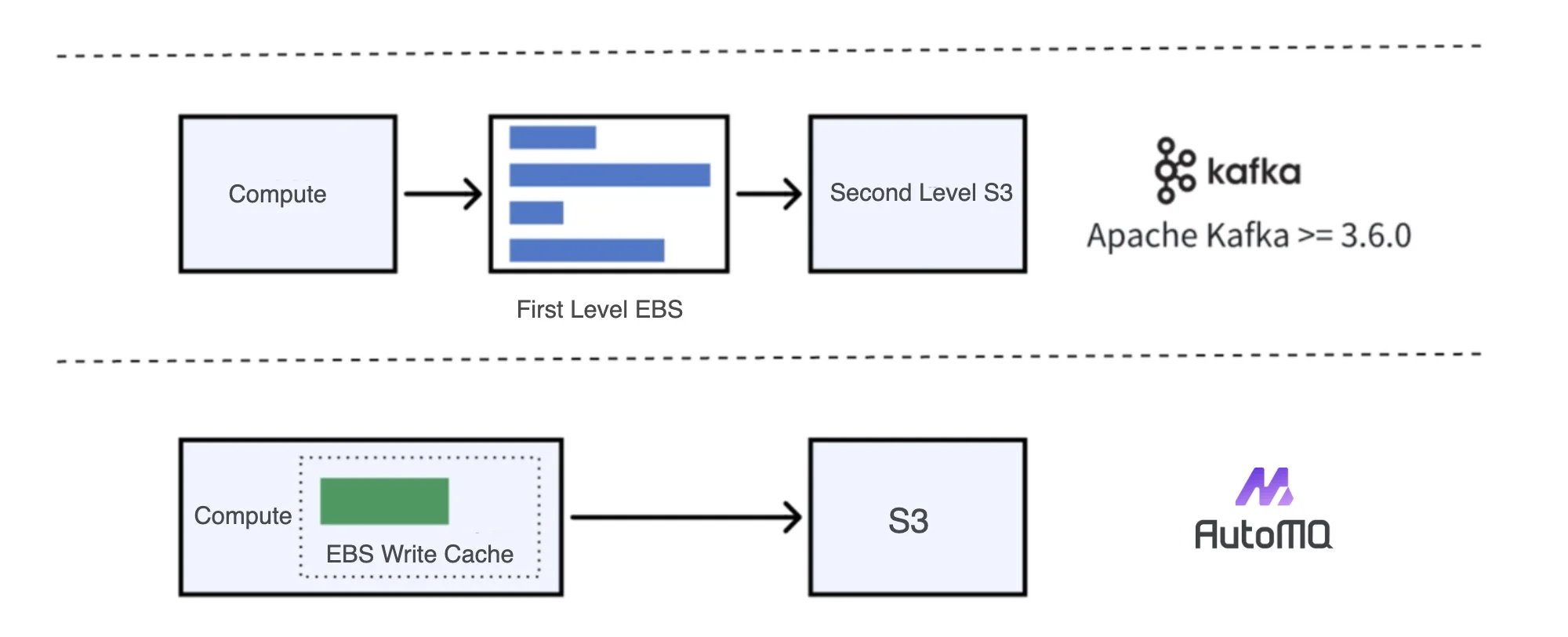
The biggest problem with stateful applications is the migration and recovery of their state data. Taking Apache Kafka as an example, even after version 3.6.0 supports tiered storage (non GA), its broker is still a stateful design, requiring the last log segment for each partition data on each broker to be on primary storage. When this log segment is very large, the occupied primary storage space will be very large, and the migration of this state data is very time-consuming when the associated broker is offline. If tiered storage is not used, it is common for this migration to take several hours or even days.
Although AutoMQ Kafka relies on EBS block storage in addition to object storage in its architecture, it essentially uses a stateless architecture. Primary storage is loosely coupled and acts as a buffer. The following diagram reveals the difference between Apache Kafka's multi-tier storage and AutoMQ's storage architecture. The EBS write buffer used by AutoMQ Kafka defaults to a fixed 3GB, which can be downsized to the second or even millisecond level in scaling scenarios (depending on the specific model used).
Using a large number of Spot instances will result in frequent up and down lines of computing instances in the cluster. If Apache Kafka is used, not only does it require manual intervention to replace Spot instances, but this frequent up and down line and partition data movement will cause obvious system jitter, significantly affecting data production and consumption. AutoMQ Kafka, due to its stateless design, has effectively avoided this problem. Even when using a large number of Spot instances, it can minimize the system jitter caused by instance replacement and complete the replacement of Spot instances in a business-insensitive manner.
Rapid Elasticity and Serverless
AutoMQ Kafka natively supports serverless. The speed and quality of the system's own elasticity determine the quality of the Serverless service it can provide. The extensive use of Spot instances, due to their unpredictable recovery behavior, will result in the computing instances used by the entire system being frequently replaced. In this process, the time it takes for the computing instance where AutoMQ Kafka is located to receive the instance termination signal to the replacement of the new Spot instance to start AutoMQ Kafka and re-accept traffic determines the efficiency of AutoMQ Kafka's elasticity.
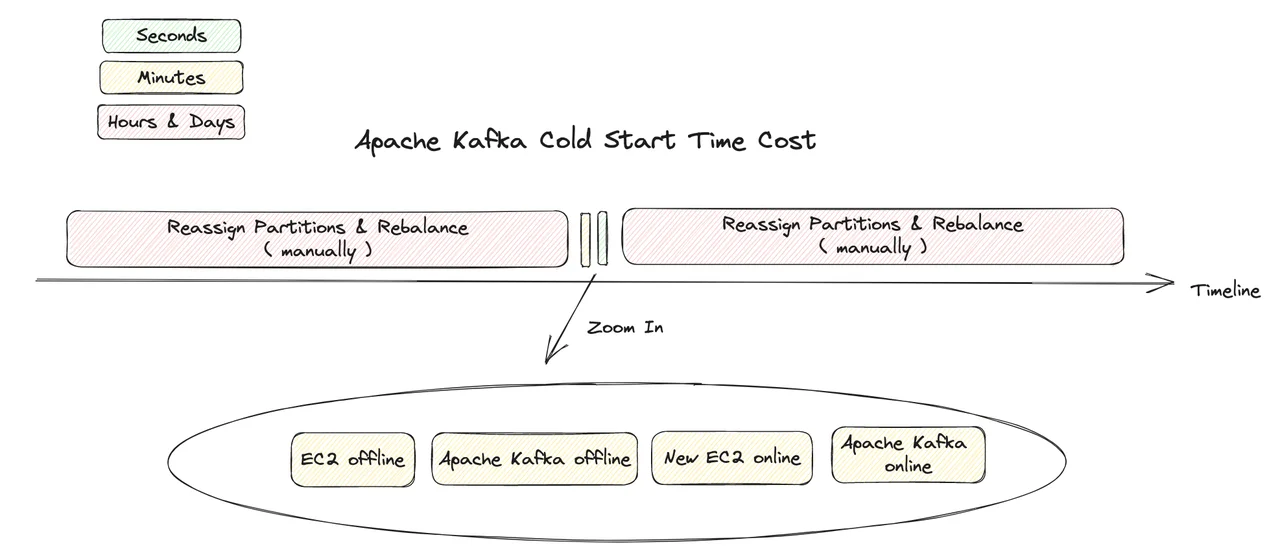
Taking Apache Kafka as an example, if Spot instances are used and instance replacement occurs, the entire cold start process is as follows. From the diagram, we can clearly see that when the data scale is large (TB level) or there are partition hotspots, the process of manually completing partition migration, data copying, and traffic rebalancing in Apache Kafka's entire cold start time is very time-consuming, reaching hours or even days, while AutoMQ Kafka, due to its reliability and availability separation design, high reliability with a single replica, and no data copying in the entire partition movement process. The following diagram clearly shows that if Apache Kafka is used in scenarios with a large data scale, it is completely impossible to use Spot instances and provide serverless capabilities, because on the entire timeline of cold start, Apache Kafka's time consumption in partition movement and traffic rebalancing occupies an absolute proportion of the total time consumption. Without reducing these two time consumptions to the same order of magnitude as other cold start stages, the application of spot instances and serverless is out of the question.
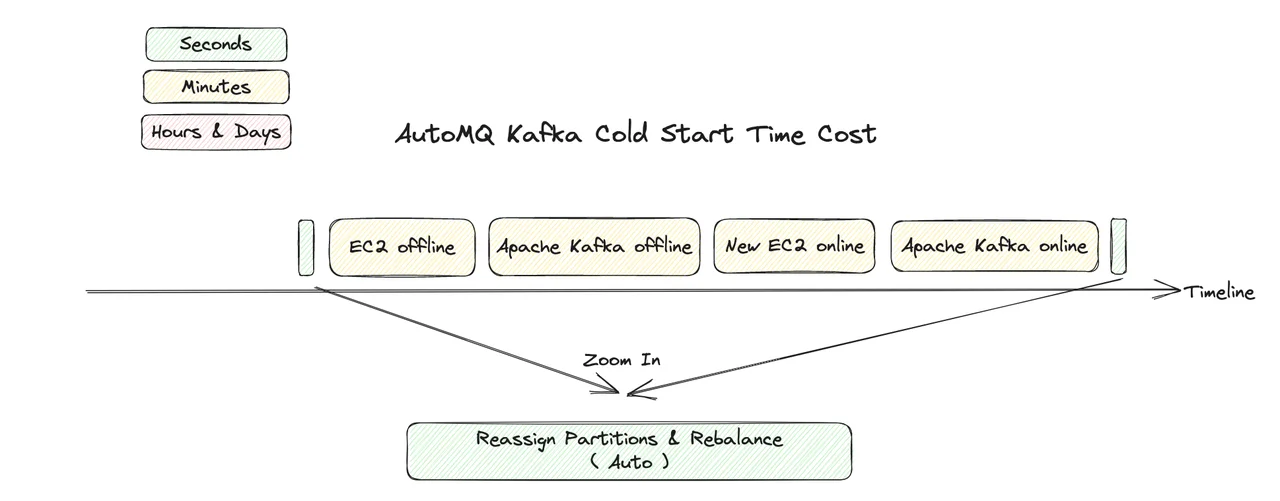
In contrast, AutoMQ Kafka, with its killer features such as second-level partition migration and continuous traffic rebalancing, not only reduces the time-consuming partition migration and rebalancing, which are high-risk and heavy-operation, to seconds, but also automates the entire process, making a leap forward compared to Apache Kafka. Once the software system itself has a short cold start time, it makes sense to optimize other stages around cold start. With the AutoMQ kernel no longer being the bottleneck for cold start, AutoMQ will continue to explore the use of container technology, GraalVM AOT compilation and other means to improve the efficiency of the entire end-to-end cold start, bringing faster and better elasticity.
Fully Utilizing Cloud Spot Instance Termination Signals
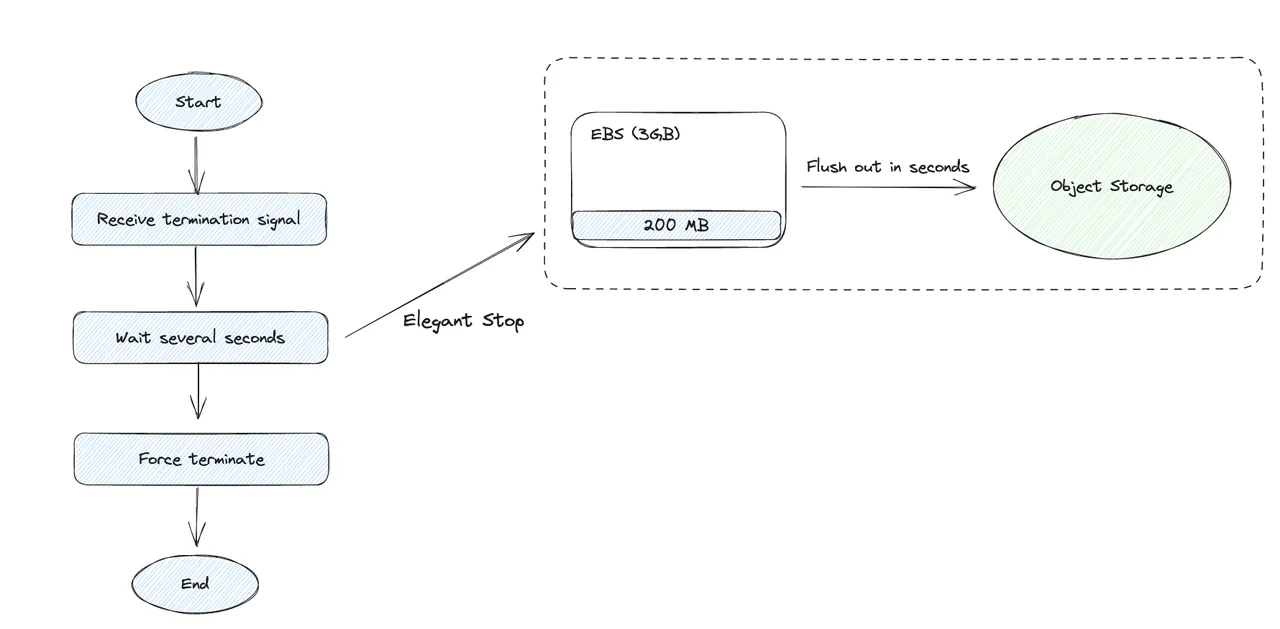
The general process of Spot instance recovery follows the following process: first send a termination signal, then wait for a few seconds before forcibly terminating the machine. The termination process of Spot instances from different cloud manufacturers is basically a variant of the following process, with the core path basically the same. The architecture of AutoMQ Kafka uses a very small (default 3GB) cloud disk SSD (EBS on AWS, hereafter referred to as EBS to represent cloud disk SSD) to act as a buffer, ensuring low latency for AutoMQ Kafka's tail reads. Thanks to AutoMQ Kafka's stateless Broker design, only a few hundred MB of cache data will remain on EBS. As long as these data are flushed to object storage during the waiting period after the Spot instance receives the termination signal, a graceful shutdown can be completed.
AutoMQ makes full use of this instance termination signal. By sensing this instance termination signal and then executing the operation of flushing the EBS cache data in advance during the waiting time after the instance receives the termination signal, a graceful shutdown can be completed. Different cloud manufacturers have different ways of allowing users to sense this termination signal, but they basically reserve at least 10 seconds of waiting time to allow the application to execute a graceful shutdown, which is completely sufficient for AutoMQ.
Spot Instance-Friendly Disaster Recovery Mechanism
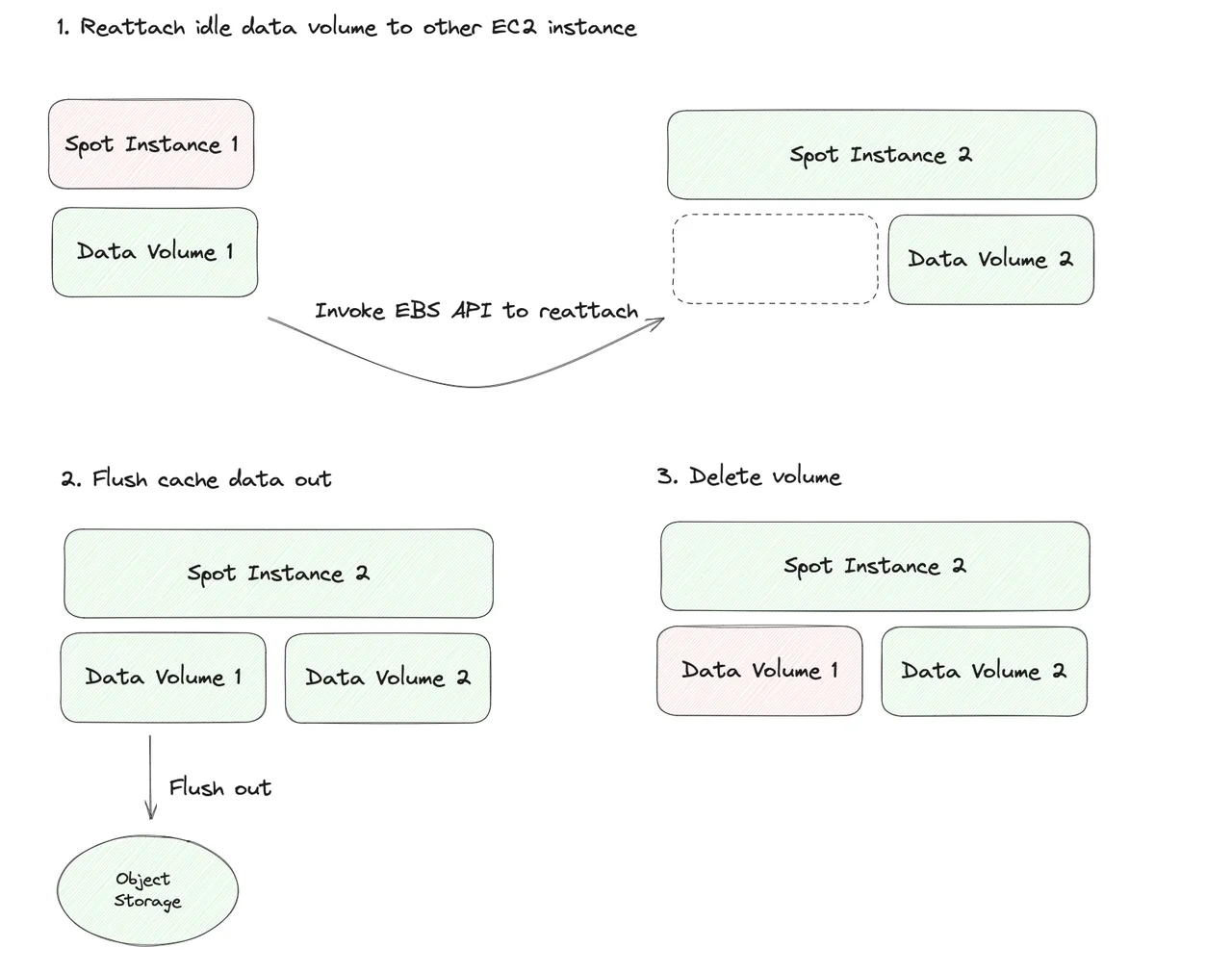
The previous section mentioned that AutoMQ Kafka uses a short waiting time after Spot instances send the termination signal to complete a graceful shutdown. At this point, some smart partners will surely question: we should consider a failure-oriented design. What if, in the worst case, network anomalies or system load anomalies cause AutoMQ to fail to flush the data in time during the waiting time after the termination signal? In fact, AutoMQ has considered this situation and has specifically designed a Spot instance-friendly disaster recovery mechanism. The following diagram is a simple schematic of the entire disaster recovery mechanism, which can be summarized as follows:
- AutoMQ detects and promptly discovers orphaned data volumes left behind by Spot instance recovery, and mounts them to a suitable new computing instance via the API for cloud disk management.
- Flush the small amount of data remaining on the orphaned data volume to object storage.
- Delete the now-empty data volume.
Through this disaster recovery mechanism, even in the worst case, AutoMQ Kafka can still complete automated disaster recovery, and the entire process is business-insensitive.
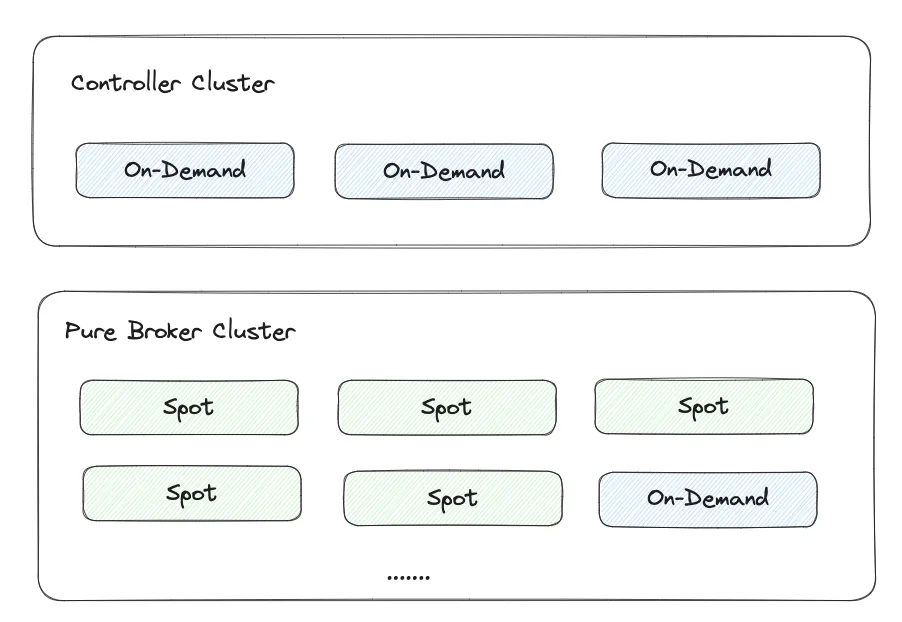
Mixed Deployment of On-Demand and Spot Instances
Although AutoMQ Kafka uses a large number of Spot instances to reduce costs, it still retains the use of a small number of on-demand instances in two dimensions to ensure that AutoMQ can provide users with reliable Kafka services.
- Kraft nodes use on-demand instances : The core capabilities that AutoMQ relies on depend on KRaft. To ensure the reliability of metadata, the nodes that participate in Raft elections and ensure metadata consistency still use on-demand instances to ensure their stability.
- Broker clusters support mixed deployment of on-demand and Spot instances : Looking at the actual usage of AWS Spot instances, for a 30-machine AutoMQ Kafka cluster, there will be several instance replacements within a day. This kind of sporadic instance replacement is basically business-insensitive in AutoMQ's stateless and extreme elasticity design. The replacement of Spot instances will only cause second-level RT jitter on some partition data reads and writes at certain times, which can meet the vast majority of Kafka application scenarios. Even so, AutoMQ has fully taken into account the demands of a part of users who are not sensitive to cost but have very strict requirements for RT jitter, allowing users to adjust the proportion of on-demand instances in the Broker cluster to balance cost and jitter frequency.
Fallback to On-Demand Instances
In addition to the problem of being interruptible, Spot instances also have the problem of being prone to inventory shortages. For cloud manufacturers, on-demand instances have SLAs and need to be prioritized to ensure sufficient inventory. If a region or availability zone is short of computing instance inventory, it will be prioritized to meet the supply of on-demand instances. Under this rule, the Spot instance inventory capacity in some unpopular regions or availability zones is prone to shortages, and there may be situations where Spot instances cannot be purchased when instance replacement is needed.
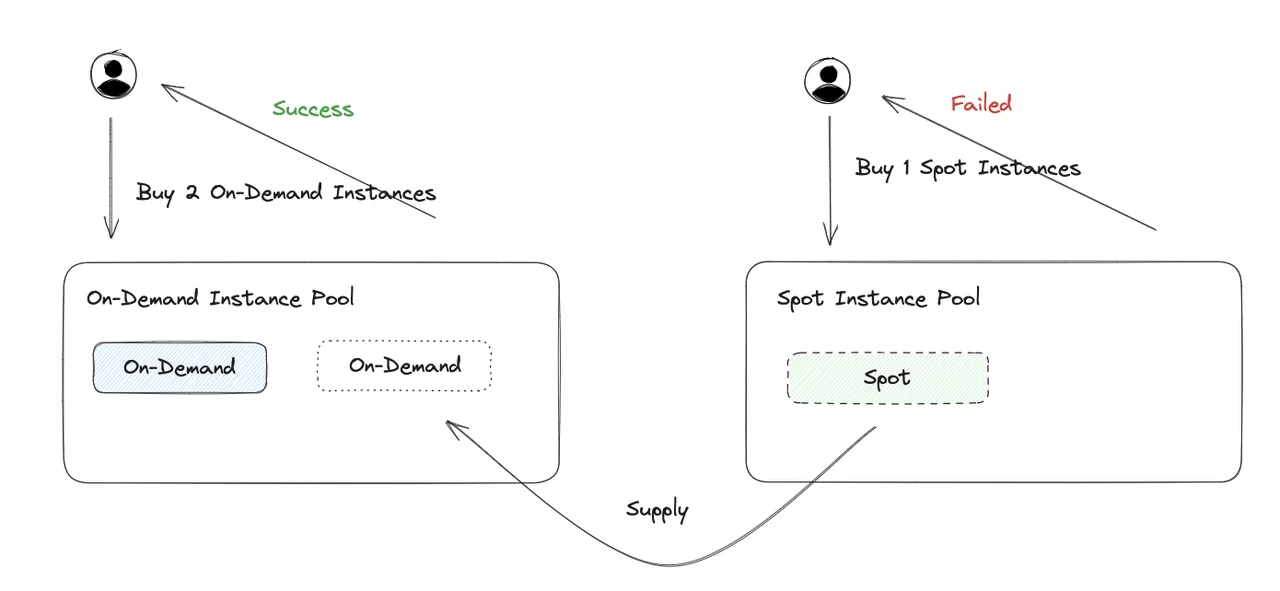
AutoMQ Kafka, in order to cope with the possible shortage of Spot instance inventory, provides the ability to fallback to on-demand instances (hereinafter referred to as fallback). Fallback is essentially to detect and identify the situation of Spot instance inventory shortage, and then repurchase on-demand instances to supplement capacity in this situation. And fallback supports when Spot instances can be repurchased, automatically replacing the on-demand instances in the cluster with on-demand instances. This feature is mainly achieved by using the capacity management features of the elastic scaling group, due to space reasons, a separate article will be released later to introduce the implementation of the fallback capability.
Balancing Stability and Cost
The inherent uncertainty and inventory issues of Spot instances make many system designers and developers hesitate to use them, holding excessive prejudices. In fact, this doubt is essentially due to a lack of understanding. Just as there is no absolute safety in the world, there is also no absolute stability. The definition of stability varies with the application scenario, as different scenarios have different standards for 'stability'. In software system design, the key is to make the right trade-off.
Taking the Kafka provided by AutoMQ as an example, if you can tolerate the second-level RT jitter on some partitions at certain times due to Spot instance replacement, then you can confidently use a larger proportion of Spot instances to achieve huge cost savings; but if you are a user who is extremely sensitive to RT jitter, then you can still use all on-demand instances, just enjoy the extreme elasticity brought by AutoMQ. Simply put, what suits you is the best, and we also welcome everyone to truly experience AutoMQ and see how much we weigh. The core source code of AutoMQ Kafka is available on GitHub, and we welcome community discussions.
Last but not least, if this article has been helpful and insightful to you, come to the AutoMQ Github repository and give us a little star.


