Background
Apache Kafka (hereinafter referred to as Kafka) has been widely used in various industries as a successful stream processing platform and has a very powerful software ecosystem. However, some of its shortcomings have posed significant challenges to its users. AutoMQ is a new generation of Kafka based on a cloud-native architecture and is 100% fully compatible with Kafka. It is dedicated to solving the inefficiency of Kafka's original migration replication, lack of elasticity, and high cost, becoming a new generation of cloud-native Kafka solution.
To help readers better understand the advantages of AutoMQ compared to Kafka, we have launched the "Kafka Pain Point Series" to help readers better understand the current pain points of Kafka and how AutoMQ solves these problems. Today, we mainly share the principle of the occurrence of cold reads (also known as catch-up reads. This happen when you read historical data from Kafka and it will do disk read) side effects in Kafka, and how AutoMQ avoids the side effects brought about by the original Kafka cold read through cloud-native architectural design.
How Cold Reads Occur
In message and stream systems, cold reads are common and valuable scenarios, including the following points:
- Ensure the effect of peak shaving and valley filling : The messaging system is usually used for business decoupling and peak shaving and valley filling. In the peak shaving and valley filling scenario, the message queue can temporarily save upstream data for gradual downstream consumption. These data are usually not in memory and need to be read coldly. Therefore, optimizing cold read efficiency is crucial for improving the effect of peak shaving and valley filling.
- Widely used in batch processing scenarios : When combined with big data analysis scenarios, Kafka is often used for batch processing. In this case, the task needs to start scanning and calculating data from a few hours or even a day ago. The efficiency of cold reading directly affects the timeliness of batch processing.
- Fault recovery efficiency : In the actual production environment, it is a common problem that consumers fail and crash due to logical problems or business bugs. After the consumer recovers, it needs to consume the accumulated historical data quickly. Improving cold read efficiency can help the business recover faster from consumer downtime, reducing downtime.
- Cold reading triggered by data replication during Kafka partition migration : Kafka needs to migrate partition data during expansion, which will also trigger cold reading.
Cold reading is a normal demand that Kafka must face in practical applications. For AutoMQ, we will not try to eliminate cold reads, but focus on solving the side effects brought by Kafka cold reads.
Side Effects of Cold Reading
Next, we will analyze what specific side effects Kafka cold reading will bring, and why Kafka cannot solve these problems.
Hard Disk I/O Contention Issue
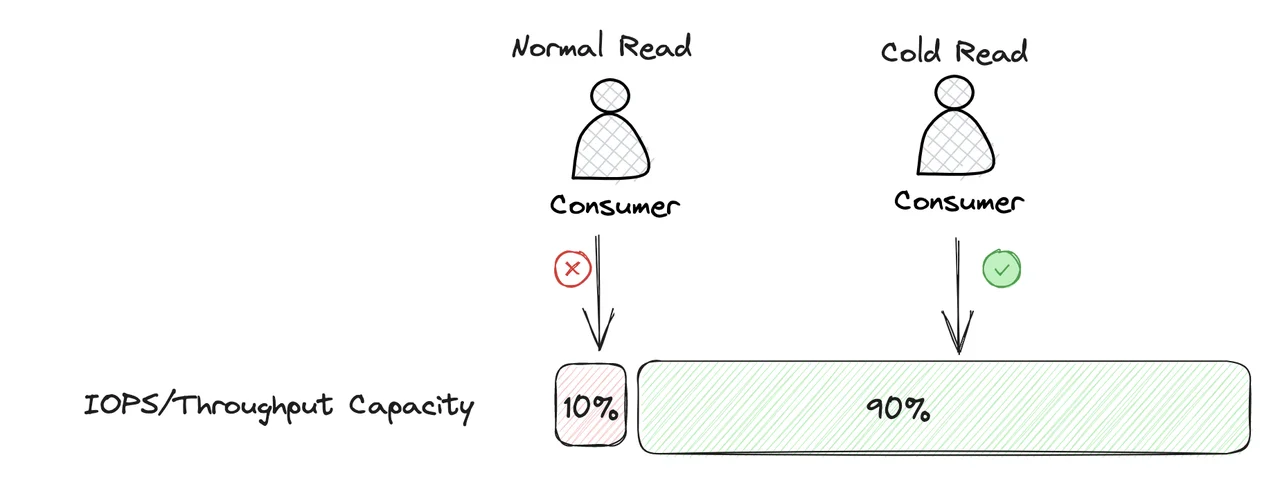
An important challenge in Kafka operation and maintenance is to deal with the large use of hard disk I/O during cold reading. The single-disk IOPS and throughput capabilities of hard disks or cloud disks are limited. Cold reading will cause a large amount of data to be read from the hard disk. When some partition data is unevenly distributed on the node, it is easy to cause hotspot access. Cold reading of a large amount of data partition will quickly occupy the IOPS and throughput resources of a single disk, directly affecting the read and write performance of other Topic partition data on the node.
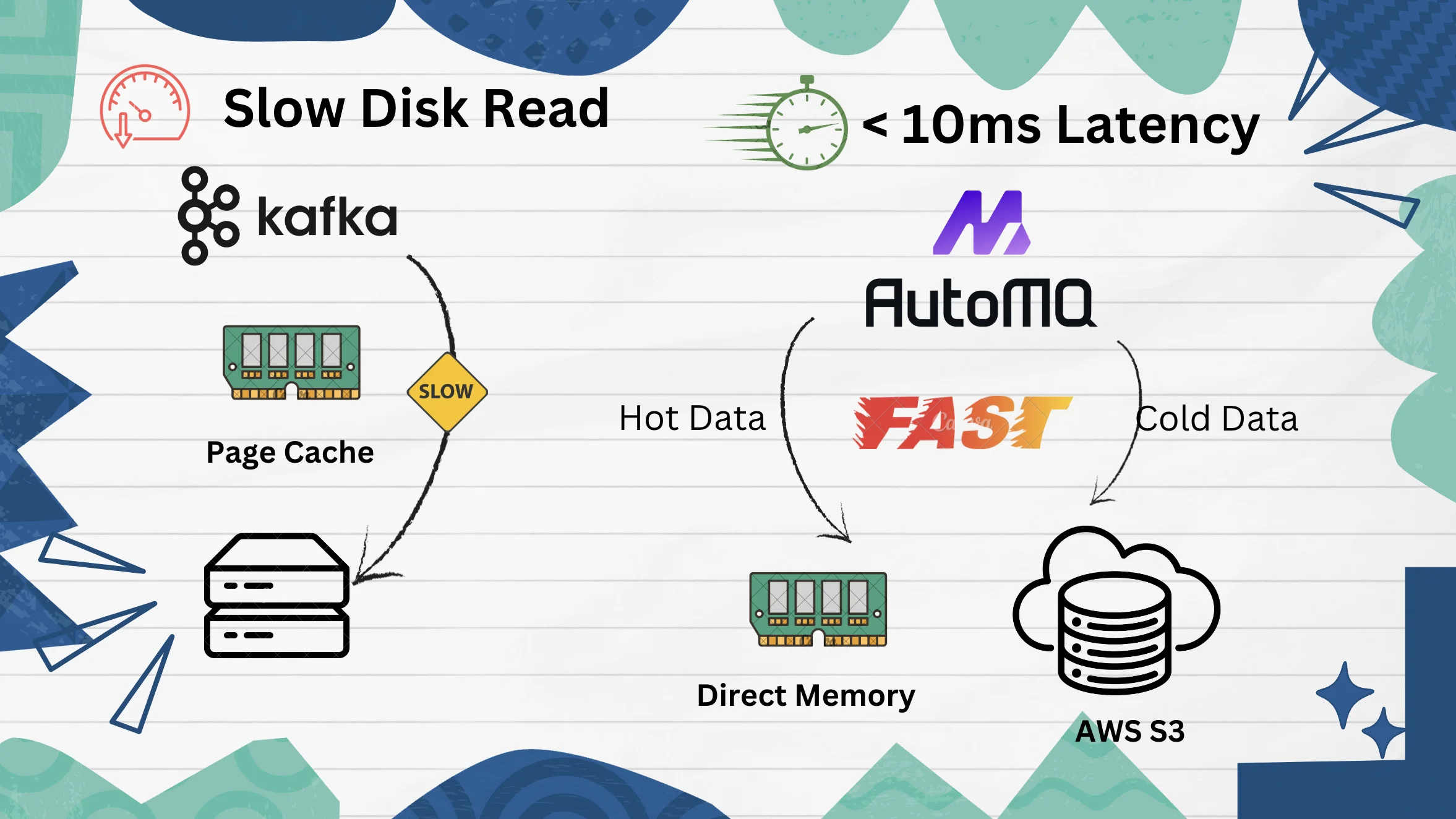
The main reason why Kafka cannot solve this side effect is that its own storage implementation strongly depends on local storage. All Kafka data is stored on the local disk of the Broker. During cold reading, a large amount of disk I/O is consumed, which limits the performance when other read and write requests need to access the disk. Even if the commercialized company of Kafka, Confluent, implements the tiered storage depicted by KIP-405, the problem has not been completely solved. In the implementation of Kafka tiered storage, Kafka still requires the last LogSegment of the partition to be on the local disk, and the Broker and local storage are still strongly dependent. Therefore, Kafka cannot completely read data from S3 or memory during cold reading, and there must be requests that need to read data from the last LogSegment of the partition. When the data of LogSegment is relatively large, the problem of hard disk I/O contention will be more serious. In general, Kafka uses tiered storage to try to reduce the impact of cold reading side effects to a certain extent, but it does not fundamentally solve the problem.
Page Cache Pollution
During Kafka's cold read, a large amount of data loaded from the disk goes through Page Cache for consumers to read, which will cause data pollution in Page Cache. The size of Page Cache is relatively limited, and because it is essentially a cache, when a new object needs to be added to Page Cache, if its capacity is insufficient, some old objects will be evicted.
Kafka does not do cold and hot isolation. When cold reading occurs, a large amount of cold data reading will quickly occupy the capacity of Page Cache, and the data of other Topics in it will be evicted. When consumers of other Topics need to read data from Page Cache, a Cache Miss will occur, and then data must be read from the hard disk, at which time the reading latency will greatly increase. In this case, because data is loaded from the hard disk, the overall throughput performance will quickly degrade. Kafka uses Pache Cache in combination with the sendfile system call to have a good performance when there is no cold read, but once a cold read occurs, its impact on throughput and read-write latency will be very headache-inducing.
The main reason why Kafka cannot solve this problem well is that its read-write model itself is strongly dependent on Page Cache to deliver its powerful performance and throughput.
Zero Copy Blocks Network Requests During Cold Reads
Kafka's use of zero-copy technology sendfile to avoid the overhead of kernel and user mode interaction to improve performance has always been talked about. However, it is undeniable that sendfile will bring additional side effects during cold reads.
In Kafka's network thread model, read and write requests will share a network thread pool to handle network requests. In the ideal scenario without cold reading, after the network thread is processed by Kafka, when data needs to be returned to the network, it directly loads data from Page Cache and returns, and the entire request response can be completed within a few microseconds. The whole read-write process is very efficient.
But if a cold read occurs, when the Kafka network thread writes data to the network kernel's send buffer, the sendfile call needs to first load the disk into Page Cache, and then write to the network kernel's send buffer. In this zero-copy process, the process of the Linux kernel loading data from the disk to Page Cache is a synchronous system call, so the network thread can only synchronously wait for its associated data to finish loading data from the disk before it can continue to handle other work.
Kafka's network thread pool is shared by the client's read and write network requests. During cold reading, a large number of network threads in the Kafka network thread pool are synchronously waiting for the system call to return, which will block new network requests from being processed, and also further increase the delay of consumer consumption. The following figure shows how sendfile affects the processing of network threads during cold reading, thereby further slowing down the overall production and consumption efficiency.
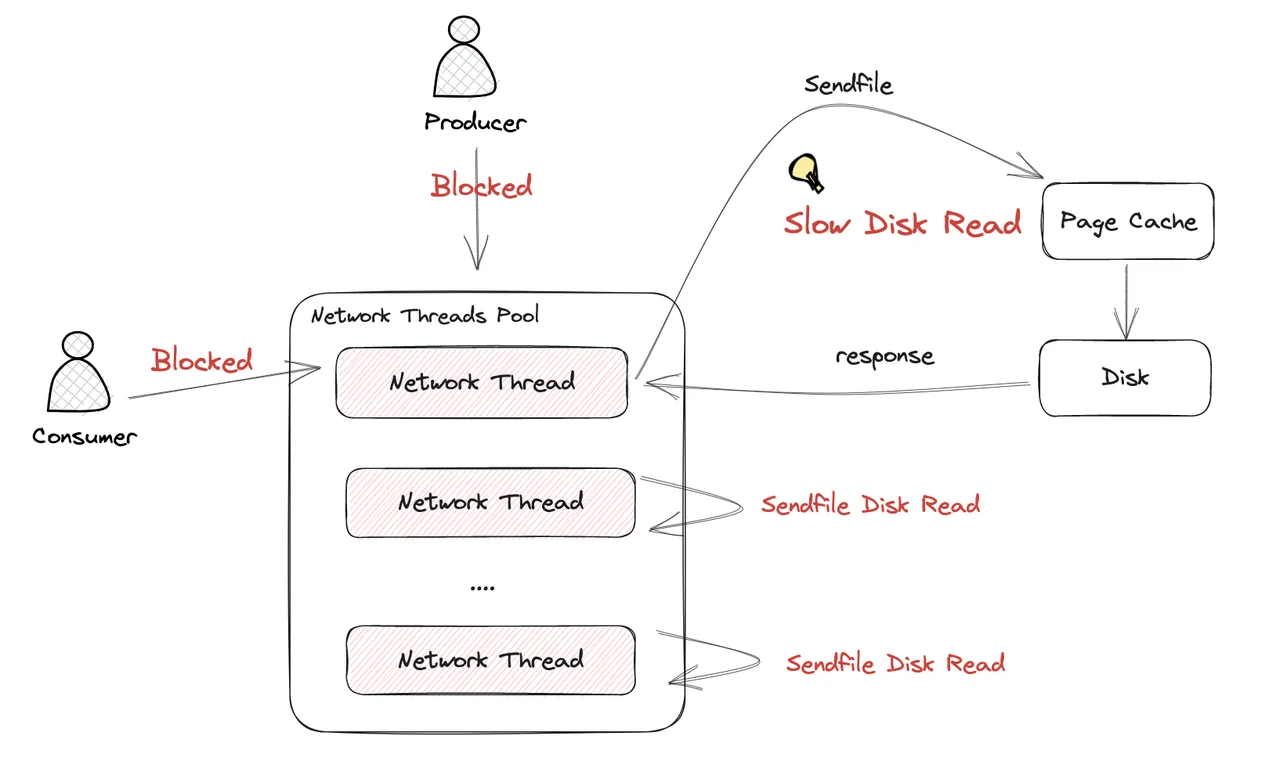
According to the principle analysis above, the main reason why Kafka cannot solve this problem well is mainly limited by the design of its thread model. In Kafka's read-write thread model, read and write share the network thread pool. The slow operation of sendfile during cold reading is not asynchronously decoupled from the read and write core process, which causes the network thread to become a bottleneck during cold reading, and then causes a significant decrease in throughput performance.
How AutoMQ Solves Cold Read Side Effects
Cold and Hot Isolation
Object storage is the most scalable, cost-effective, and technically beneficial cloud service. We can see that companies like Confluent and Snowflake are reshaping their software services based on cloud object storage to provide users with lower cost, more stable, and elastic storage capabilities. Redesigning basic software based on cloud object storage has also become a new trend in the design of Infra field software. AutoMQ, as a truly cloud-native software, decided at the beginning of the design to use object storage as its main storage, and thus designed the S3Stream, a stream storage library for object storage in the stream scenario. This stream storage library has also been open-sourced on Github. You can search for automq-for-kafka to follow.
AutoMQ's use of object storage as the main storage not only brings ultimate cost and elasticity advantages, but another very important benefit is that it effectively isolates cold and hot data, fundamentally solving the problem of Kafka's hard disk I/O contention. In AutoMQ's read-write model, during cold reading, data will be directly loaded from object storage, rather than reading data from the local disk, which naturally isolates cold reading, and naturally will not occupy the local disk's I/O.
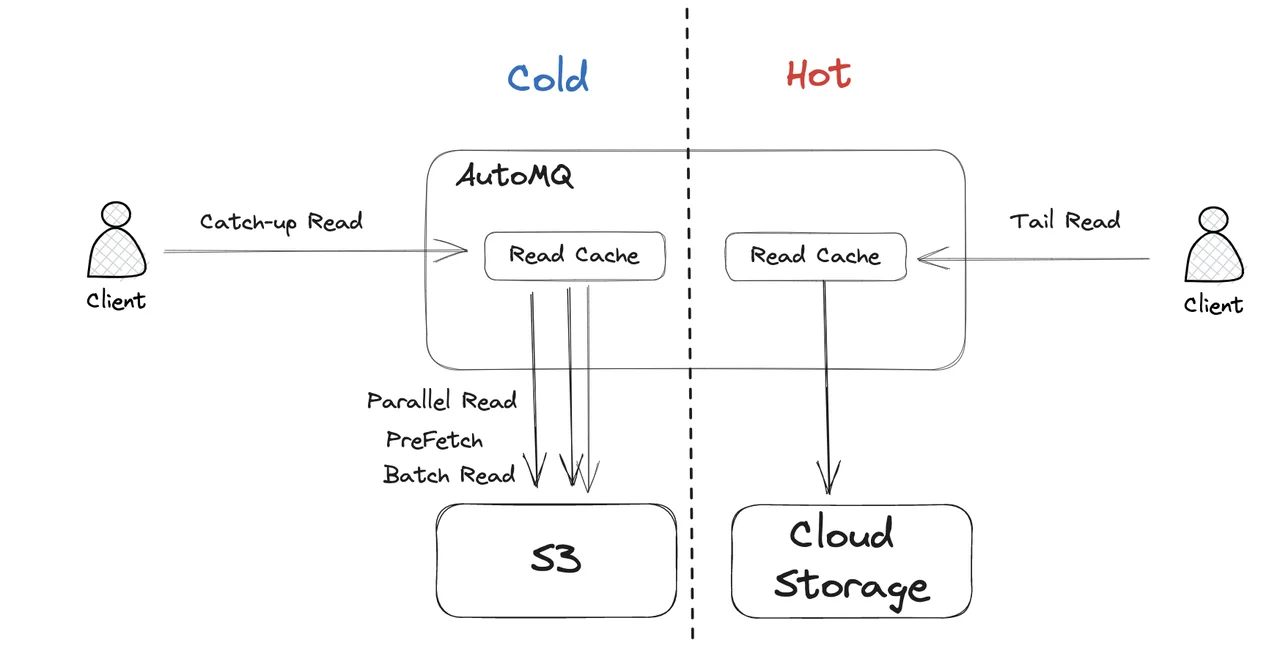
In addition, cold read isolation implemented by AutoMQ based on object storage will not have performance side effects. Through concurrent, pre-read, and batch reading and other technical optimization measures, the throughput performance during cold reading can fully rival Kafka.
Self-managed Memory Independent of Page Cache
AutoMQ's read-write model does not rely on Page Cache, so naturally there will be no side effects of Kafka Page Cache pollution. Although Page Cache is abandoned, AutoMQ does not compromise in performance, mainly because of the following series of technical means.
Using Direct I/O to Read and Write Raw Devices
AutoMQ bypasses the file system and reads and writes raw devices directly through Direct I/O. The main benefits of this are:
- Avoid Page Cache pollution : Bypassing the file system naturally eliminates Page Cache pollution.
- Reduce data copying: Using Direct I/O to directly read raw devices, data is copied only once, from hardware directly to the user mode of the application.
- Reduce file system overhead : The file system generally needs to write a Journal, manage Metadata, and consume more bandwidth and IOPS than actual writing, and the writing path is also longer, so the performance is worse than raw devices.
- Faster disaster recovery speed : AutoMQ's WAL data will be kept on the cloud disk and then flushed asynchronously to object storage. When the computing instance goes down, the cloud disk will automatically drift and mount to other available machines, and AutoMQ will complete the disaster recovery operation, that is, flush the remaining WAL on its cloud disk to object storage and then delete the cloud disk. In this disaster recovery process, since it directly operates the raw device, it can avoid the time overhead of file system recovery and improve the timeliness of disaster recovery.
- Avoid Kafka data loss : AutoMQ needs to persist data to the cloud disk before returning a successful response to the client. In the default recommended configuration of Kafka, data is usually persisted asynchronously to ensure performance. In scenarios such as data center power outage, file system residual dirty pages will be lost, resulting in data loss.
Self-managed Off-heap Memory
Using the file system's Page Cache to improve performance is a somewhat opportunistic approach. For Kafka, it means that it does not need to implement a set of memory Cache itself, and it does not have to worry about its JVM object overhead and GC problems. It must be said that in non-cold read scenarios, this method does indeed perform well. But once a cold read occurs, Kafka's user mode's default behavior intervention ability for Page Cache is very limited, and it cannot do some fine-grained management. Therefore, it is difficult to handle problems like Kafka's Page Cache pollution during cold reading.
AutoMQ fully considered the pros and cons of using Page Cache at the beginning of its design, and in its self-developed S3Strean stream storage library, it implemented efficient self-management of JVM off-heap memory. By designing the cache BlockCache and LogCache with cold and hot isolation, it can ensure efficient memory read and write in various scenarios. In future iterations, AutoMQ can also manage and optimize memory read and write more finely according to the stream scenario.
Asynchronous I/O Response to Network Layer
Kafka's thread model is essentially designed around Page Cache and zero-copy technology. The previous text also pointed out that its core problem is that during cold reading, the network thread synchronously waits for disk reading, which obstructs the entire read-write process and affects performance.
The problem that AutoMQ did not encounter is also due to its self-implemented memory management mechanism. Since it does not rely on Page Cache, AutoMQ's storage layer implementation will asynchronously load data before responding to the network layer, so read and write requests will not synchronously wait for disk I/O to complete before handling other work. This makes the overall read and write processing more efficient.
Cold Reading Performance
Cold reading is a common application scenario in Kafka. When AutoMQ deals with Kafka's cold read side effects, it not only achieves cold and hot isolation, but also considers the importance of ensuring that cold read performance is not affected.
AutoMQ ensures the performance during cold reading through the following technical means:
- Object storage read performance optimization : Data is directly read from object storage through pre-reading, concurrency, and caching, ensuring overall excellent throughput performance.
- Cloud-native storage layer implementation, reducing network overhead : AutoMQ uses the multi-replica mechanism of the underlying cloud disk to ensure data reliability, so it can reduce the network latency overhead of replica replication at the Broker level. Therefore, it has better latency and overall throughput performance compared to Kafka.
The results in the following table come from the actual performance comparison report of AutoMQ vs Kafka, showing that under the same load and machine type compared to Kafka, AutoMQ can ensure the same level of cold read performance as Kafka without affecting write throughput and delay during cold reading.
| Compare Item | Time spent in the catch-up reading process. | Impact on sending traffic during the catch-up reading process. | Peak throughput during catch-up reading. |
|---|---|---|---|
| AutoMQ | < 3ms | Reading and writing is isolated, keeping 800 MiB/s | 2500 ~ 2700 MiB/s |
| Apache Kafka | ~ 800ms | Reading and writing affect each other ,fail to 150 MiB/s | 2600 ~ 3000 MiB/s ( Sacrifice writing) |
Summary
This article focuses on the principles of the problems Kafka encounters during cold reads, as well as the solutions provided by AutoMQ. In the next article of "Kafka Pain Points Series", we will explore the No.1 pain point of Kafka, that is, elasticity. Please stay tuned.


