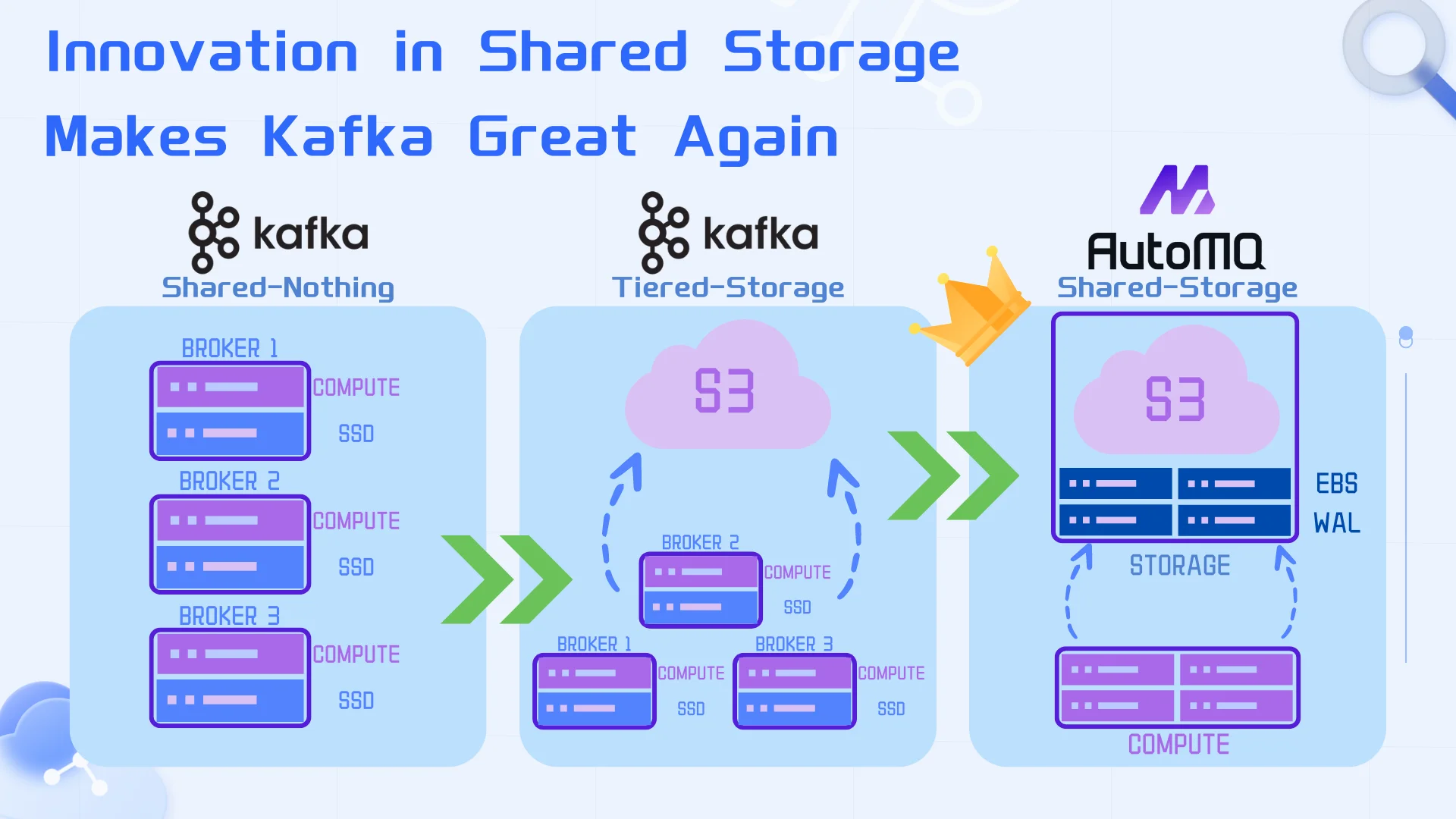
Introduction
Since its inception, Apache Kafka has set a benchmark in the stream processing domain with its outstanding design and powerful capabilities. It not only defined modern stream processing architectures but also provided unparalleled abilities for real-time data stream processing and analysis through its unique distributed log abstraction. Kafka's success lies in its ability to meet the high throughput and low latency data processing needs of businesses of all sizes, forging an incredibly rich Kafka ecosystem and becoming the de facto industry standard.
However, as cloud computing and cloud-native technologies rapidly advance, Kafka faces increasing challenges. Traditional storage architectures are struggling to meet the demands for better cost efficiency and flexibility in cloud environments, prompting a reevaluation of Kafka's storage model. Tiered storage was once seen as a potential solution, which aimed to reduce costs and extend the lifespan of data by layering storage across different mediums. However, this approach has not fully addressed Kafka's pain points and has instead increased system complexity and operational challenges.
In the context of this new era, with the maturation of cloud computing and cloud services like S3, we believe that shared storage is the "right remedy" for addressing the original pain points of Kafka. Through an innovative shared storage architecture, we offer a storage solution that surpasses Tiered Storage and Freight Clusters, allowing Kafka to continue leading the development of stream systems in the cloud era. We[10] replaced Kafka's storage layer with a shared stream storage repository using a separation of storage and compute approach, reusing 100% of its computation layer code, ensuring full compatibility with the Kafka API protocol and ecosystem. This innovative architecture combines a pluggable Write-Ahead Log (WAL) for low-latency writes and S3 for cost-effective long-term storage. AutoMQ supports multiple WAL backends—S3 WAL (the default for AutoMQ Open Source), EBS WAL, Regional EBS WAL, and NFS WAL—so users can choose the right trade-off between latency and cost. By integrating Apache Kafka's storage layer with object storage, we fully leverage the technological and cost benefits of shared storage, thoroughly resolving the original issues of cost and elasticity faced by Kafka.
This article will delve into the evolutionary journey of Kafka's storage architecture and the innovative shared storage architecture we have developed, hoping to inspire readers with modern stream storage system design insights.
Share-Nothing on Local Disks: Outdated
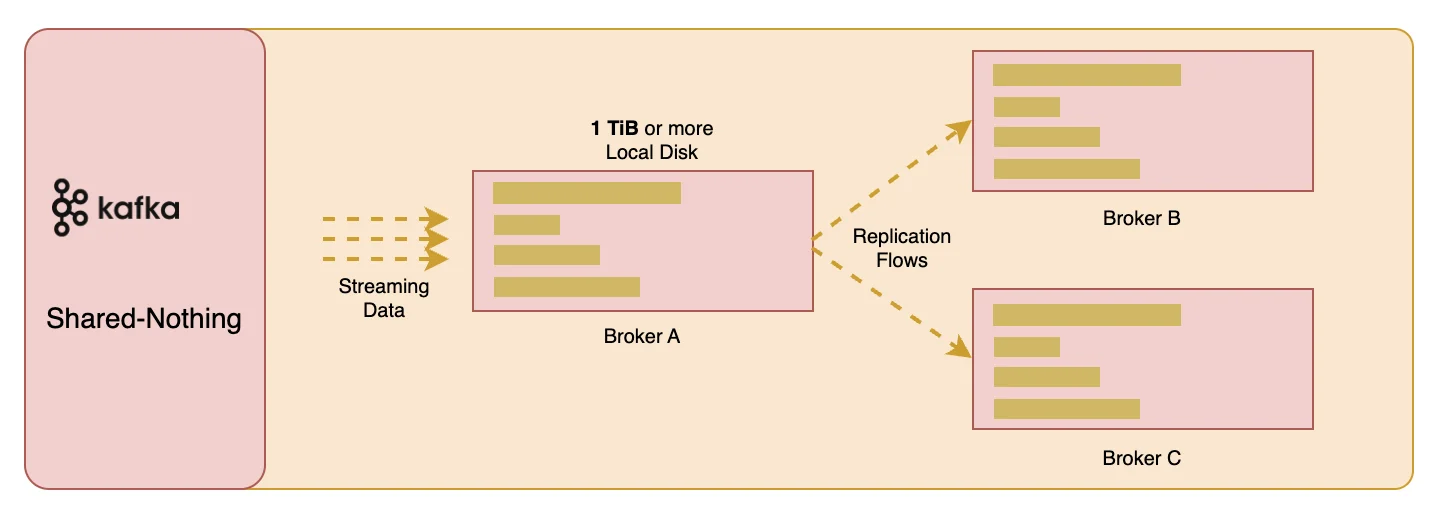
Apache Kafka®, widely used as a stream processing platform, has traditionally centered around a local disk-based Shared Nothing architecture. However, as cloud computing technologies advance, this traditional architecture is facing unprecedented challenges. The Shared Nothing architecture means there are no shared resources in the system; each node possesses its own storage and computing resources and performs tasks independently. While this architecture offers good scalability and fault tolerance in certain scenarios, its limitations in cloud environments are becoming increasingly apparent:
-
Storage cost issues: Local disk storage costs are high, especially when considering the adoption of three replicas. According to reference [1], taking EBS GP3 volumes as an example, although the price is $0.08/GiB/month, when Kafka uses three replicas, the actual cost rises to $0.24/GiB. If reserving 50% of the storage space to cope with data growth and disaster recovery, the total cost doubles to $0.48/GiB. This cost structure is unsustainable for systems that store large amounts of data over the long term. We have also encountered many customers who use Kafka for long-term storage of historical data, which can be replayed when necessary. In such application scenarios, the resulting cost issues will become increasingly significant.
-
Operational complexity: Although the Shared Nothing architecture provides Kafka with distributed processing capabilities, it brings significant complexity in operational practice. This architecture requires each node to independently manage its own storage, resulting in a strong coupling between the compute node (Broker) and local storage, which leads to a series of problems. Horizontal scaling of Kafka Brokers involves a resource-intensive process of partition reassignment. During this process, a large amount of network bandwidth and disk I/O is occupied, affecting normal read and write operations. If there are a large number of partition data, this process can last for several hours or even days [2], severely affecting the overall availability of the Kafka cluster.
-
Performance bottlenecks: The limitations of Kafka's local disk I/O are particularly evident when handling cold reads of historical data [3][4]. Due to the limited I/O throughput of local disks, when the system needs to read large amounts of historical data from disks, it conflicts with I/O operations for processing real-time data streams. This resource contention not only slows down the system's response time but may also cause service delays, affecting the overall data processing performance. For instance, when using Kafka for log analysis or data replay, the high latency of cold reads directly impacts the timeliness of analysis results [14].
-
Lack of elasticity: The Shared Nothing architecture of Kafka clusters lacks flexibility in scaling. Each Broker node is strongly coupled with local disks, limiting the cluster's ability to adapt to dynamic workloads and achieve automatic scaling [5]. When data traffic surges, because partitions cannot be reassigned quickly, Kafka clusters struggle to rapidly expand resources to meet demand. Similarly, when the load decreases, it is also difficult to reduce resources in a timely manner, leading to low resource utilization and cost wastage. Users cannot take advantage of public cloud features such as resource sharing and pay-as-you-go, and must revert to the traditional data center practice of reserving resources, resulting in idle resource wastage. Even if scaling is manually performed, due to the replication of partition data, it remains a high-risk operation. Due to the lack of elasticity, it is not possible to scale the cluster in/out quickly, thus true pay-as-you-go, the application of cloud Spot instances, and genuine Serverless are out of the question.

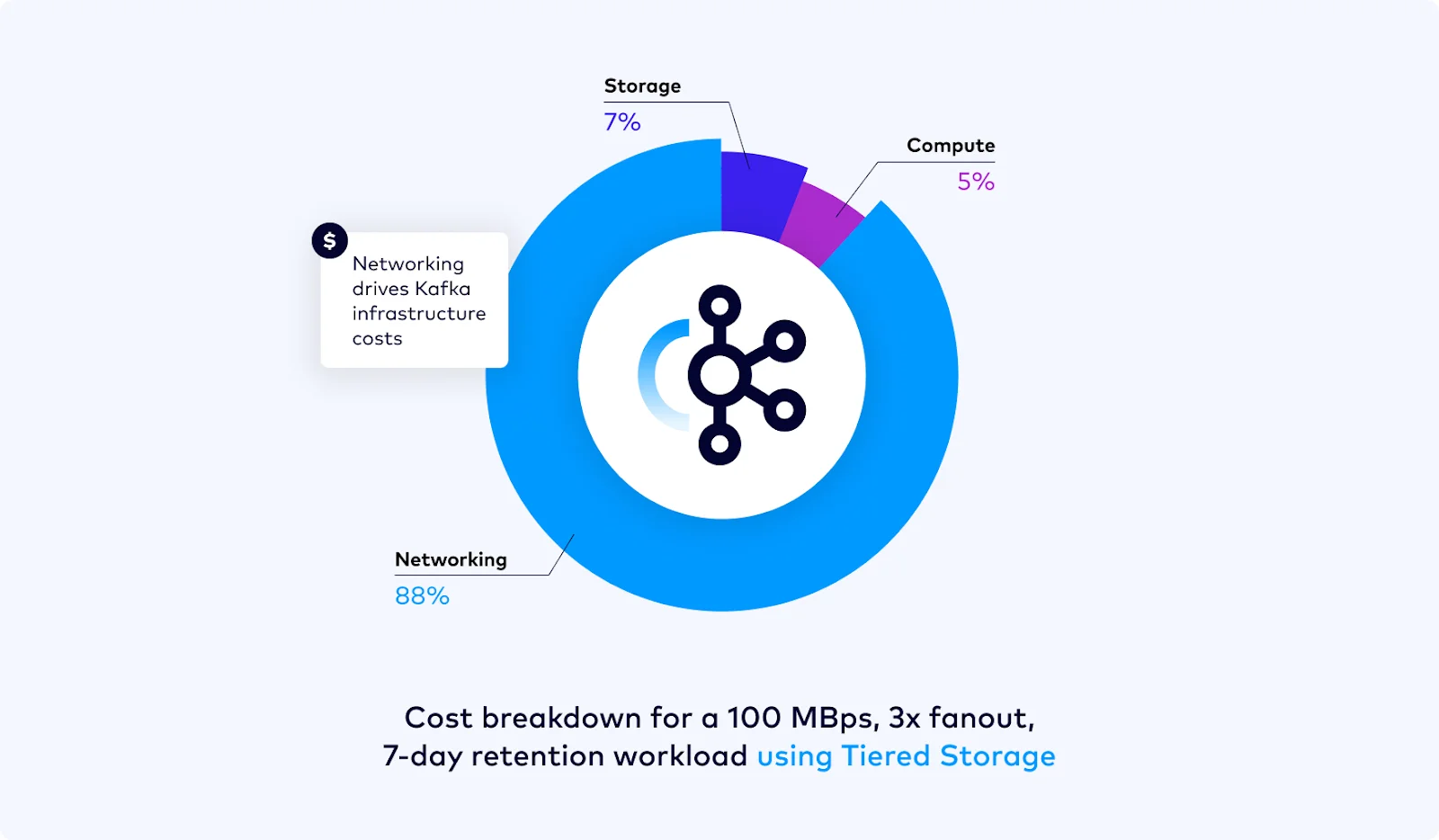
- Multi-AZ network traffic costs: Cloud providers charge substantial fees for network transfers between multiple AZs. An analysis of Kafka's costs on Confluent's blog found that network costs can account for over 80% [6]. Deploying a Kafka cluster that supports multi-AZ disaster recovery with three replicas, based on the local disk-based Shared Nothing architecture, incurs significant network I/O and associated costs during client read/write operations and scaling, making it an uneconomical approach.
Tiered Storage Won't Fix Kafka
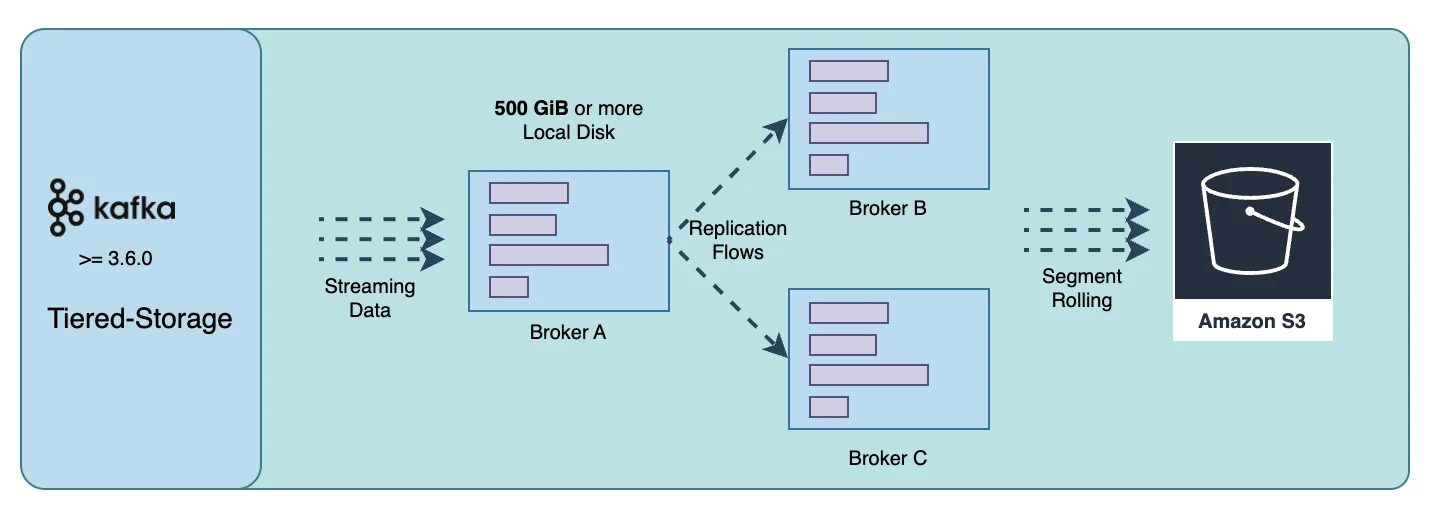
The concept of Tiered Storage has been discussed in the Apache Kafka® community for years, but as of version 3.7, Kafka itself still does not offer a mature, production-level tiered storage capability. Despite this, some Kafka vendors such as Confluent and Aiven have launched their own tiered storage solutions. These solutions leverage the low-cost advantage of object storage to move older data from expensive local disks to object storage, aiming to reduce the cost of long-term storage. However, these attempts at tiered storage have not fundamentally solved some of the core pain points that Kafka faces:
-
Network traffic cost issues across multiple AZs: The essence of Tiered Storage is still based on Kafka's local storage logs, and the relationship between brokers and local disks has not changed. By moving some historical data to S3, it reduces costs and the volume of partition data replication, but it is still a superficial solution. Kafka's implementation of tiered storage requires that the last log segment of a partition must still be on a local disk, meaning brokers in a tiered storage scenario remain stateful. When the last log segment of a partition is large, extensive partition data replication is still inevitable during horizontal scaling.
-
Operational complexity: Although tiered storage is adopted, the operational complexity of Kafka has not been simplified; rather, it has introduced additional complexities due to the integration of object storage. Using tiered storage does not truly decouple brokers from local disks. Data reassignment during scaling and partition reassignment remains a complex and error-prone task. For example, even Confluent's Dedicated clusters, which use tiered storage, can still take several hours or longer to scale [[7]].
- High infrastructure costs: As mentioned earlier, even with tiered storage, you may still have a significant amount of data on local disks. Often, workloads are difficult to predict. To ensure normal operation during peak throughput, users still need to reserve a large amount of local disk space (or cloud disks in the cloud). Due to the high costs of cloud disks [[1]], this significantly increases storage costs.
From the analysis above, it is clear that while tiered storage has somewhat addressed the issue of historical data storage costs and reduced the volume of data in some partition reassignments, it has not fundamentally resolved the pain points of Kafka. The issues of storage costs and elasticity that existed in the past based on the Local Disk's Shared Nothing architecture still persist.
Writing S3 directly Won't Fix Kafka Either

Although writing data directly into S3 object storage is an appealing solution [6], it is not a panacea for Kafka's problems. This method might solve elasticity and cost issues in a Shared Nothing architecture, but it sacrifices latency. If there could be a solution that balances latency and elasticity, why would I need to compromise? For streaming systems, latency is extremely important [8]. In scenarios such as financial transactions, online gaming, and streaming media, latency is a crucial and non-negotiable metric. Latency directly relates to the user experience, data processing efficiency, and the competitive edge of businesses. Sacrificing latency would cause streaming systems to lose key application scenarios, which contradicts Kafka's original design intention to achieve low latency.
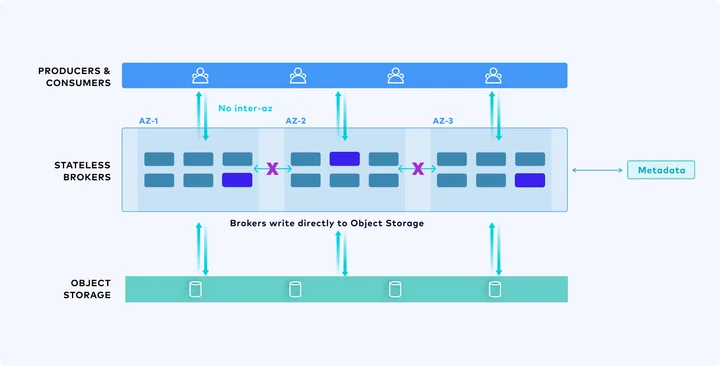
Writing directly to Object storage has resolved a series of issues caused by the stateful Broker in Kafka, such as scalability and cross-AZ network costs, but this is clearly not the optimal storage solution on a Shared Storage architecture. Generally, writing directly to S3 can lead to latency over 600ms[9], which is unacceptable in many real-time scenarios. When designing systems, it is crucial to ensure that frequently used paths have the lowest latency and optimal performance. In Kafka's use cases, reading hot data is a frequent path, and it is essential to ensure it has minimal latency and optimal performance. Currently, many customers still use Kafka to replace traditional message queuing systems like RabbitMQ. These application scenarios are highly sensitive to latency, where milliseconds-level delays can cause unacceptable message processing delays, thereby impacting business processes and user experience.
Although writing directly to S3 may provide a cost-effective storage solution in some scenarios, it does not address the need for low latency in high-frequency data processing paths of Kafka. To maintain Kafka's competitiveness as a streaming platform, it is essential to balance cost and performance in the design, especially on high-frequency data paths, to ensure that user experience and system performance are not compromised. Therefore, finding a storage solution that reduces costs, enhances Kafka's scalability, and maintains low latency has become a critical goal in our innovations for Kafka.
Innovation in Shared Storage
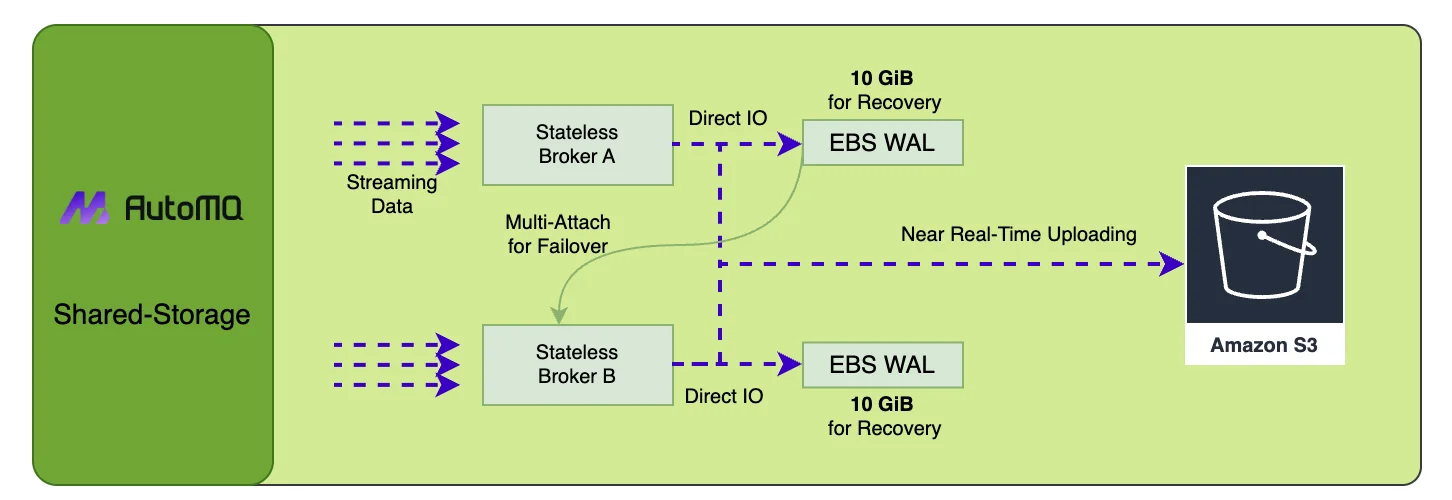
Our project AutoMQ[10] has introduced a pluggable Write-Ahead Log (WAL) in conjunction with S3 to provide an innovative shared storage architecture that delivers both low latency and cost efficiency. AutoMQ supports multiple WAL backends—S3 WAL (the default for AutoMQ Open Source), EBS WAL, Regional EBS WAL, and NFS WAL—so users can choose the right trade-off between latency and cost. This storage architecture enjoys all the benefits of writing directly to S3—excellent scalability, no cross-AZ data replication, low cost—while not sacrificing latency. The diagram reveals the implementation details of this storage architecture using EBS WAL as an example. Once WAL data is persisted successfully through Direct IO, consumers can immediately read the persisted stream data from the memory cache. Since only recent WAL data is stored on EBS, with historical data still being read from S3, this storage architecture requires only a very small EBS volume (typically 10GB), where the storage cost of EBS is minuscule in the overall storage costs. When a Broker node crashes, EBS volumes can be quickly remounted to another healthy node in milliseconds using multi-attach technology to recover WAL data, ensuring high availability.
EBS + S3 ≠ Tiered Storage
If one does not understand the advantages of our storage architecture, it's easy to confuse this innovative shared storage architecture with Tiered Storage. In tiered storage, the Broker is essentially a stateful Broker, tightly coupled with local disks. In our Shared Storage architecture, Brokers are decoupled from EBS. When a compute node crashes, using EBS multi-attach capabilities[[11]] and NVME reservations[[12]], failover and recovery can be completed in milliseconds. AutoMQ's Shared Storage architecture treats EBS as shared storage. EBS volumes can be quickly mounted to other nodes in the event of an EC2 failure, continuing to provide read and write services seamlessly. From this perspective, EBS is considered shared storage, similar to S3, rather than a stateful local disk. For EBS, being completely decoupled from Brokers, the Brokers in AutoMQ are stateless. EBS and S3 are both cloud-provided storage services, and by fully leveraging the features of cloud storage, we can seamlessly share EBS volumes among Brokers, forming our innovative Shared Storage architecture.
EBS is a cloud service, not just a physical volume
We have been continuously striving to build the next generation of truly cloud-native streaming systems, which can fully exploit the potential of public cloud services. A critical characteristic of a truly cloud-native system is to fully utilize the scalable and technologically advanced cloud services available on the public cloud. The key here is the shift from the traditional hardware-centric software mindset to a design oriented towards cloud services. The EBS cloud service is fundamentally a distributed storage, implementing multi-replica technology similar to systems like HDFS, Bookekeeper, and due to its large-scale application in the cloud, it has a lower marginal cost. Therefore, cloud providers like Alibaba Cloud have invested over a decade in optimizing storage technology with over 15 million lines of C++ code supporting these advancements; AWS also uses integrated hardware and software technologies like Nitro Card[13] to even rewrite network protocols suitable for LANs embedded in the hardware, thereby providing highly durable, reliable, and low-latency cloud storage services. Believing that cloud storage is less reliable than local disks or has latency issues is now an outdated notion. The current mainstream cloud providers offer mature enough cloud disk services, and standing on the shoulders of giants rather than reinventing the wheel can better empower the innovation of cloud-native software.
How to solve the issue of expensive EBS
Article[1] compares the storage cost per GB for a three-replica Kafka cluster on S3 versus EBS, highlighting a difference of up to 24 times. For users with larger clusters requiring long-term data retention, EBS storage costs can significantly impact the overall Total Cost of Ownership (TCO) of a Kafka cluster. Improper use of cloud storage media can lead to a dramatic increase in storage costs. EBS and S3 are cloud storage services designed for different read/write scenarios: EBS is intended for low-latency, high IOPS scenarios, while S3 targets low-cost storage for cold data, prioritizing throughput and tolerant of higher latencies. Optimizing the use of these cloud storage services based on their characteristics can achieve the best cost-effectiveness while ensuring performance and availability.
Our Shared Storage architecture is designed under the principle that "high-frequency usage paths need the lowest latency and optimal performance." It thoughtfully leverages the differing storage characteristics of EBS and S3, combining the advantages of both to offer low-latency, high-throughput, cost-effective, and virtually unlimited streaming storage capabilities. Kafka writes hot data which is immediately read by consumers, a high-frequency read/write path. When using EBS WAL, by utilizing the persistence, low-latency, and block storage capabilities of EBS, coupled with engineering solutions like Direct I/O, data is persisted with minimal latency. Once persisted, consumers can read the data from the memory cache, completing the read/write process with single-digit millisecond latency. Using EBS as a Write-Ahead Log (WAL) for Recovery, we require only about 5-10GB of EBS storage space. For instance, a 10GB AWS GP3 storage volume costs only $0.8 per month. This approach not only utilizes the persistence and low-latency characteristics of EBS but also addresses the latency issues inherent in direct S3 writes. For deployments where latency requirements are less strict, S3 WAL (the default for AutoMQ Open Source) writes directly to object storage, eliminating any dependency on block storage.
How to address the lack of multi-AZ disaster recovery capabilities with AWS EBS
In public clouds, AWS EBS is unique as it does not offer Regional EBS like other cloud providers. Azure[17], GCP[16], and Alibaba Cloud (set to release in June 2024) all offer Regional EBS solutions that seamlessly integrate with our Shared Storage, providing AZ-level disaster recovery and fully leveraging the technical advantages of cloud storage services. On AWS EBS, we support AZ-level disaster recovery by dual-writing to EBS in different AZs and to S3 Express One Zone.
Conclusion
As cloud computing and cloud-native concepts evolve, Kafka faces significant challenges, but it is not going to disappear[15]. It will continue to grow and develop. We believe that the shared storage architecture will inject new vitality into the Kafka ecosystem, leading it truly into the era of cloud-native.
References
[1] Cloud Disks are (Really!) Expensive: https://www.warpstream.com/blog/cloud-disks-are-expensive
[2] Making Apache Kafka Serverless: Lessons From Confluent Cloud**: https://www.confluent.io/blog/designing-an-elastic-apache-kafka-for-the-cloud/#self-balancing-clusters**
[3] How AutoMQ addresses the disk read side effects in Apache Kafka: https://www.automq.com/blog/how-automq-addresses-the-disk-read-side-effects-in-apache-Kafka
[4] Broker performance degradation caused by call of sendfile reading disk in network thread:https://issues.apache.org/jira/browse/Kafka-7504
[5] Is there anyway to activate auto scaling or some form of auto scaling with Strimzi? : https://github.com/orgs/strimzi/discussions/6635
[6] Introducing Confluent Cloud Freight Clusters**: https://www.confluent.io/blog/freight-clusters-are-generally-available/**
[7] Resize a Dedicated Kafka Cluster in Confluent Cloud**: ** https://docs.confluent.io/cloud/current/clusters/resize.html
[8] Why is low latency important?:https://www.redpanda.com/guides/kafka-performance/kafka-latency
[9] Public Benchmarks and TCO Analysis**: https://www.warpstream.com/blog/warpstream-benchmarks-and-tco**
[10] AutoMQ: https://github.com/AutoMQ/automq
[11] AWS EBS Multi-Attach: https://docs.aws.amazon.com/ebs/latest/userguide/ebs-volumes-multi.html
[12] NVME reservations: https://docs.aws.amazon.com/ebs/latest/userguide/nvme-reservations.html
[13] Nitro card for Amazon EBS: https://d1.awsstatic.com/events/Summits/reinvent2023/STG210_Behind-the-scenes-of-Amazon-EBS-innovation-and-operational-excellence.pdf
[14] How AutoMQ addresses the disk read side effects in Apache Kafka: https://www.automq.com/blog/how-automq-addresses-the-disk-read-side-effects-in-apache-Kafka
[15] Kafka is dead, long live Kafka**: ** https://www.warpstream.com/blog/kafka-is-dead-long-live-kafka
[16] GCP Regional Persistent Disk: https://cloud.google.com/compute/docs/disks/high-availability-regional-persistent-disk
[17] Azure ZRS Disk: https://learn.microsoft.com/en-us/azure/virtual-machines/disks-deploy-zrs?tabs=portal


