
In cloud computing, resource pooling enables enterprises to optimize unit resource cost by outsourcing tasks like IDC construction, software development, and operations to cloud providers. This allows businesses to concentrate on innovation while leveraging a pool of talented engineers provided by cloud services. By entrusting specialized tasks to these professionals, enterprises can benefit from high-quality services tailored to their needs.
Elasticity is a critical capability in cloud computing, yet many customers struggle to fully leverage it, often treating it as a concept rather than implementing it effectively. This article delves into the reasons behind this gap between theory and practice and offers insights into cost-effective ways to enhance elasticity.
Cloud providers offering discounts through annual or monthly subscriptions contradict the concept of elasticity.
The table below compares the typical pricing of EC2 instances between reserved instances (annual pricing) and on-demand instances. Here are the key takeaways from this comparison:
- Opting for a reserved instance model can save costs by approximately 50% compared to pay-as-you-go pricing. This is why most enterprises choose to utilize EC2 resources through a reserved instance model. From the cloud provider's perspective, this design is highly rational. Cloud providers forecast the overall customer usage to determine how much spare capacity to reserve in a region. If on-demand and reserved instance prices were equal, it would be challenging for cloud providers to predict the capacity of a region accurately. This unpredictability could lead to significant differences between daytime and nighttime usage, directly impacting supply chain procurement decisions. Cloud providers operate on a retail-like business model, where the spare machine capacity in each region is analogous to inventory. Higher inventory levels in a region would result in lower profit margins.
- Spot instances are both cost-effective and billed on an hourly basis. Handling Spot instance interruptions is crucial, especially for stateless applications. Most cloud providers offer a notification window before Spot instance termination, allowing applications to gracefully shut down without impacting business operations. Startups[1] specializing in managing compute resources with Spot instances have developed robust features to assist users in maximizing Spot instance utilization. Companies like AutoMQ[2] have accumulated extensive experience in utilizing Spot instances. However, for stateful applications like Kafka, Redis, and MySQL, transitioning state before Spot instance termination can be challenging. It is generally not recommended to deploy data-centric infrastructure software directly on Spot instances.
The game rules have both reasonable aspects and areas for optimization. We believe there is room for improvement in the following aspects:
-
Spot Instance Termination Notification SLA: To encourage more users to utilize Spot instances, the notification mechanism for Spot instance termination should provide a defined SLA. This will allow critical businesses to confidently adopt Spot instances at scale.
-
Success Rate SLA for Reapplying Instances after Spot Termination : In the event of Spot instance termination, the fallback plan for applications is to provision new resources (such as new Spot instances or On-demand instances). The success rate of provisioning new resources should also have a defined SLA, as it directly impacts application availability.
-
SLA for Detaching Cloud Disks : Detaching EBS volumes should also have a defined SLA. In cases of Spot instance forced termination, users should be able to automatically manage application state detachment.
| EC2 Instance Type | Cost per month. | Relative On-Demand pricing ratio. |
|---|---|---|
| On Demand | $56.210 | 100% |
| Spot | $24.747 | 44% |
| Reserved 1YR | $35.259 | 63% |
| Reserved 3YR | $24.455 | 44% |
AWS US EAST m6g.large
It can be challenging for developers to effectively manage resource deallocation
C/C++ programmers spend a lot of effort battling with memory, yet still struggle to prevent memory leaks. The challenge lies in accurate resource reclamation - for instance, when a function returns a pointer, it's unclear who is responsible for deallocating the object, with no conventions in C/C++. This becomes even more daunting in multi-threaded scenarios. To address this, C++ introduced smart pointers, managing objects through a thread-safe reference count. Java, on the other hand, tackles object reclamation through a built-in GC mechanism, effectively eliminating the problem but incurring runtime overhead. Rust, a language gaining popularity, fundamentally operates like C++'s smart pointers but innovatively shifts memory reclamation checks to compile time. This greatly enhances memory reclamation efficiency, mitigating common memory issues faced by C/C++ programmers. The author believes Rust stands as a perfect replacement for C/C++.
In the realm of cloud operating systems, developers can easily create an ECS instance, a Kafka cluster, or an S3 object through a single API call, which directly impacts the billing. While creation is straightforward, resource reclamation becomes challenging. Typically, maximum specifications are set during creation; for instance, provisioning 20 Kafka nodes at the outset to avoid future scaling complexities.
Although cloud computing provides elasticity, developers struggle to effectively manage resources on demand, leading to difficulties in resource reclamation. This has prompted enterprises to establish cumbersome approval processes similar to traditional IDC resource management when creating resources in the cloud. As a result, developers end up using resources in a manner similar to IDC, requiring resource management through CMDB and relying on manual approval processes to prevent resource waste.
We have also seen some excellent best practices in elasticity. For example, a large enterprise sets the lifespan of each EC2 instance to be no more than 1 month. Once exceeded, it is labeled as a "legacy EC2" and put on the team's blacklist. This is a great immutable infrastructure practice that effectively prevents engineers from retaining state on servers, such as configurations and data, making it feasible for applications to move towards elastic architectures.
Currently, cloud computing is still in the C/C++ stage, lacking efficient resource recycling solutions. As a result, enterprises heavily rely on manual approval processes, hindering the full utilization of cloud elasticity. This contributes significantly to high cloud spending. We believe that for every problem, there is a superior solution. Expect to see innovative resource recycling solutions, akin to Java/Rust, emerge in the near future.
From foundational software to the application layer, we are not fully prepared for elasticity yet
In 2018, We began designing elastic solutions[3] for thousands of applications at Taobao and Tmall of Alibaba. While these applications achieved a mix of offline and online deployments to increase deployment density, online applications were still in a reserved mode, lacking on-demand elasticity. The fundamental issue lies in the potential for unexpected behavior during scaling of applications, even when running on Kubernetes. For example, applications may call various middleware SDKs (databases, caches, message queues, business caches, etc.), and the applications themselves take a long time to start up. Despite appearing stateless, these applications actually contain various states, such as unit tags, gray tags, etc., requiring significant manual intervention and observation for effective scaling.
In order to improve Java applications' cold start time from minutes to milliseconds, we developed Snapshot capability for Docker[3]. This capability was ahead of AWS by 4 years (AWS announced Lambda SnapStart[4][5] feature at the 2022 Re:Invent conference). By starting applications through Snapshot, a new compute node can be added in a matter of hundreds of milliseconds, allowing applications to scale resources based on traffic without needing to refactor into Lambda functions, thus providing a Pay as you go model similar to Lambda.
Adding elasticity at the application layer is already complex, and the challenge is even greater at the infrastructure layer with products like databases, caches, message queues,streaming process and big data solutions. The requirements for distributed high availability and reliability mean that these products need to store data in multiple replicas. When dealing with large data volumes, achieving elasticity becomes very difficult, and data migration can impact business availability. To address this issue in the cloud environment, a cloud-native approach is essential. When designing AutoMQ (A Cost-Effective Auto-Scaling Kafka distro), we prioritize elasticity as the highest priority. The core challenge is to offload storage to cloud services, such as pay-as-you-go S3, instead of maintaining a custom storage system. The graph below shows the traffic and node changes in AutoMQ online, demonstrating that AutoMQ automatically scales machines based on traffic. Using Spot instances for these machines can significantly reduce costs for enterprises, enabling true pay as you go functionality.
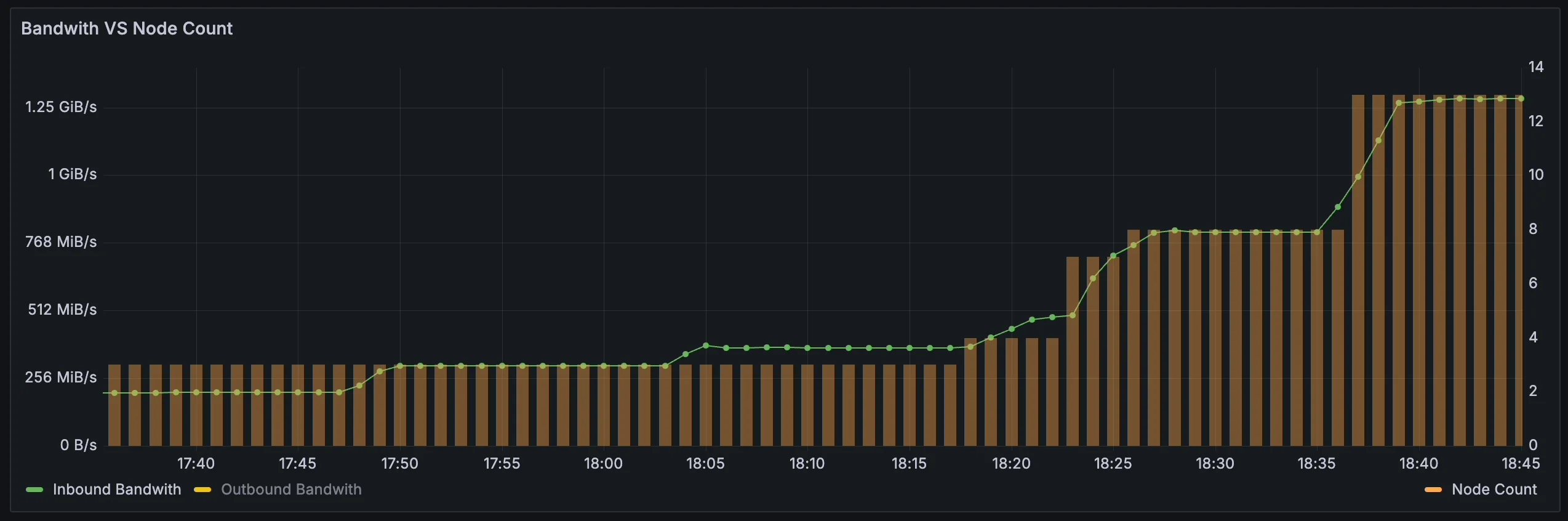
AutoMQ automatically scales nodes based on network traffic.
How can enterprises leverage elasticity to reduce costs and increase efficiency effectively?
In 2018, Google introduced Cloud Run[6], a fully managed computing platform that allows HTTP-based applications to simply provide a listening port and a container image to Cloud Run, which then handles all infrastructure management automatically. This approach, compared to AWS Lambda, offers the key advantage of not being tied to a single cloud provider, allowing for easier migration to other computing platforms in the future. Following suit, AWS and Azure quickly launched similar products, namely Azure Container Apps[7] and AWS App Runner[8].
Entrust professional tasks to experts. Scalability is a challenging task. It is recommended that cloud-based applications rely on serverless frameworks, such as Cloud Run, for on-demand and cost-effective compute resource consumption.
Foundational software like databases, caches, big data, and message queues are difficult to manage with a unified framework. The trend for such applications is towards elastic architectures, with each category evolving accordingly, such as Amazon Aurora Serverless and MongoDB Serverless[9]. Whether from cloud providers or third-party open-source software vendors, the consensus is to achieve full elasticity.
When selecting open-source foundational software, choose products with elasticity capabilities that can run on Spot instances and provide excellent cost-performance ratio. Also, consider whether these products can operate effectively across multiple clouds, which is crucial for future multi-cloud or hybrid cloud architectures and portability.
References
[1] https://spot.io/
[2] https://www.automq.com/blog/how-automq-achieves-10x-cost-efficiency-spot-instance
[3] https://mp.weixin.qq.com/s/Gj_qPPTn6KN065qUu6e-mw
[4] https://docs.aws.amazon.com/lambda/latest/dg/snapstart.html
[5] https://aws.amazon.com/cn/blogs/aws/new-accelerate-your-lambda-functions-with-lambda-snapstart/
[6] https://cloud.google.com/run?hl=zh_cn
[7] https://azure.microsoft.com/en-us/products/container-apps
[8] https://aws.amazon.com/cn/apprunner/
[9] https://www.mongodb.com/products/capabilities/serverless


