


.png)
Preface
With the growing demand for real-time data processing, enterprises require more efficient and flexible data integration solutions. AutoMQ, redesigned based on the cloud, stands out as an ideal choice with its significant cost benefits and elasticity. By integrating AutoMQ with Airbyte and data warehouses, the data integration process can be further simplified, enhancing data analysis capabilities. This enables efficient real-time data flow and analysis, helping enterprises make informed decisions quickly. This article will guide you through integrating these components.
Overview of AutoMQ
AutoMQ is a cloud-reimagined stream processing system that maintains 100% compatibility with Apache Kafka®. By decoupling storage into object storage, AutoMQ significantly enhances cost efficiency and elasticity. Specifically, AutoMQ leverages the S3Stream built on S3, offloading storage to shared cloud storage such as EBS and S3. This provides low-cost, low-latency, highly available, highly durable, and virtually unlimited capacity stream storage capabilities. Compared to the traditional Shared Nothing architecture, AutoMQ employs a Shared Storage architecture, significantly reducing storage and operational complexity while enhancing system elasticity and durability.
The design philosophy and technical advantages of AutoMQ make it an ideal choice for replacing existing Kafka clusters in enterprises. By adopting AutoMQ, companies can significantly reduce storage costs, simplify operations, and achieve automatic cluster scaling and balancing, thus more efficiently responding to changing business demands. Additionally, AutoMQ's robust support for high-throughput cold read operations and zero-downtime service ensures stable system operation under fluctuating loads. The storage architecture of AutoMQ is as follows:

Overview of Airbyte
Airbyte is a data integration platform focused on simplifying and automating the building and management of data pipelines. It supports a wide range of source and target systems, allowing users to easily configure data pipelines through an intuitive web interface or API. Airbyte features efficient ETL (Extract, Transform, Load) capabilities, with built-in scheduling and monitoring mechanisms to ensure the reliability and performance of data pipelines. Its modular design supports custom connectors, meeting diverse data integration needs.
The main advantages of Airbyte include high scalability and flexibility, allowing users to quickly adapt to different data sources and target systems. The built-in data standardization processing and automated scheduling functions enhance the efficiency and consistency of data processing. Through containerized deployment, Airbyte simplifies the installation and expansion process, making it suitable for enterprise-level data integration and data warehousing. Additionally, the rich connector library and community support make it an ideal tool for data engineers and analysts to efficiently solve complex data integration challenges.
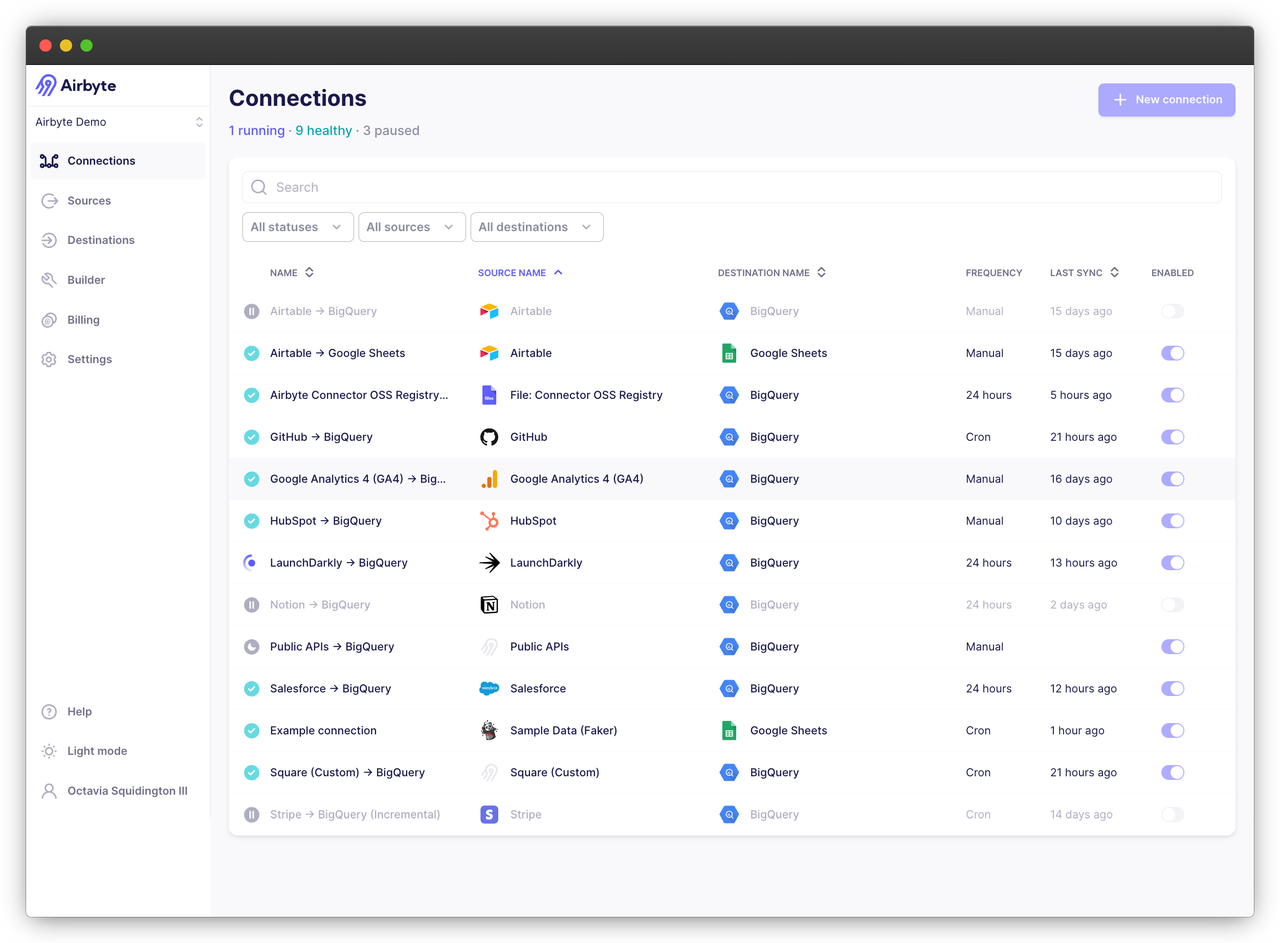
Prerequisites
Data Source: An available AutoMQ node.
Data Connector: An available Airbyte environment.
Data Destination (Data Warehouse): In this case, I've chosen a cloud-deployed Databricks [3] cluster.
Quick Deployment
Deploy AutoMQ
You can refer to the official AutoMQ documentation for deployment: [Quick Start | AutoMQ] [4]. Once the setup is complete, you can prepare data using the Kafka SDK or manually, followed by the data synchronization process. I have preloaded some data, and you can monitor the status of AutoMQ nodes using various visualization tools such as [Redpanda Console], [Kafdrop] [5], etc. Here, I choose Redpanda Console, where you can see that there are currently 50 Topics, and each Topic has 1000 initial messages.

Message Format:
[
{
"partitionID": 0,
"offset": 950,
"timestamp": 1721988652404,
"compression": "uncompressed",
"isTransactional": false,
"headers": [],
"key": {
"payload": "key-451",
"encoding": "text"
},
"value": {
"payload": {
"userId": 451,
"action": "visit",
"timestamp": 1721988652404
},
"encoding": "json"
}
}
]
Deploy Airbyte
Refer to the official Airbyte documentation: [Quickstart | Airbyte] [6].
Here, I will use the Linux system as an example to deploy Airbyte.
Environment Preparation
First, you need to install abctl, a tool provided by Airbyte that helps you quickly set up the necessary Airbyte environment. However, using this tool to set up the environment requires the installation of Docker. If you do not have a usable Docker environment, please refer to the Docker installation instructions: [Docker Install] [7]. You can output the version information with the command docker version:
Client:
Version: 20.10.5+dfsg1
API version: 1.41
Go version: go1.15.15
Git commit: 55c4c88
Built: Mon May 30 18:34:49 2022
OS/Arch: linux/amd64
Context: default
Experimental: true
Server:
Engine:
Version: 20.10.5+dfsg1
.........
Preparing the abctl tool
You can execute the following commands in sequence. Here, the version I am downloading is version: v0.9.2:
## Download:
wget https://github.com/airbytehq/abctl/releases/download/v0.9.2/abctl-v0.9.2-linux-amd64.tar.gz
## Extract:
tar -xvzf abctl-v0.9.2-linux-amd64.tar.gz
## Change into directory:
cd abctl-v0.9.2-linux-amd64
## Add execute permissions:
chmod +x abctl
## Global environment setup:
sudo mv abctl /usr/local/bin
## Verify version:
abctl version
## Output
version: v0.9.2
Deploying an Airbyte Environment
Execute the command `abctl local install` to pull the Airbyte images in Docker and deploy the environment using Helm. Part of the logs are as follows:
INFO Namespace 'airbyte-abctl' already exists
INFO Persistent volume 'airbyte-minio-pv' already exists
INFO Persistent volume 'airbyte-volume-db' already exists
INFO Persistent volume claim 'airbyte-minio-pv-claim-airbyte-minio-0' already exists
INFO Persistent volume claim 'airbyte-volume-db-airbyte-db-0' already exists
INFO Starting Helm Chart installation of 'airbyte/airbyte' (version: 0.350.0)
SUCCESS Installed Helm Chart airbyte/airbyte:
Name: airbyte-abctl
Namespace: airbyte-abctl
Version: 0.350.0
Release: 2
INFO Starting Helm Chart installation of 'nginx/ingress-nginx' (version: 4.11.1)
SUCCESS Installed Helm Chart nginx/ingress-nginx:
Name: ingress-nginx
Namespace: ingress-nginx
Version: 4.11.1
Release: 2
SUCCESS Basic-Auth secret created
SUCCESS Found existing Ingress
SUCCESS Updated existing Ingress
SUCCESS Launched web-browser successfully for http://localhost:8000
SUCCESS Airbyte installation complete
After a successful startup, you can log in via the browser at http://localhost:8000 with the default username and password:
Username: airbyte
Password: password
If you set your own username and password, use command line flags or variables. For example, to set the username and password to zhaoxi and ktpro123 respectively, you can run the following command:
abctl local install --username zhaoxi --password ktpro123
Or set these values from environment variables:
export ABCTL_LOCAL_INSTALL_PASSWORD=airbyte
export ABCTL_LOCAL_INSTALL_USERNAME=password
After entering the username and password, you will see the Airbyte workspace. Using this interface, you can easily set up and manage all connections and move data!

Deploying Databricks
If you do not have an available Databricks service, refer to the official documentation for setup: [Google Databricks][8].
Data Synchronization
Adding a New Data Source
To add AutoMQ as a data source, leverage AutoMQ's full compatibility with Kafka; hence, the Kafka data source template can be utilized for setting up the AutoMQ data source. Through the Airbyte interface, navigate to the left sidebar -> Sources -> search for Kafka, and fill in basic information such as Bootstrap Servers, Protocol, Topic Pattern, etc.

Next, we need to specify the target for data transfer. You can specify Topics that match a custom regular expression or directly specify the exact Topics for transfer. Here I choose to match all Topics that start with the prefix `Topic-` using the regular expression `Topic-.*`, which aligns with the format of my prepared data. Therefore, you need to ensure that your prepared data can also be matched accordingly. Once added successfully, we can see the following result proving that the data source connection is successful:
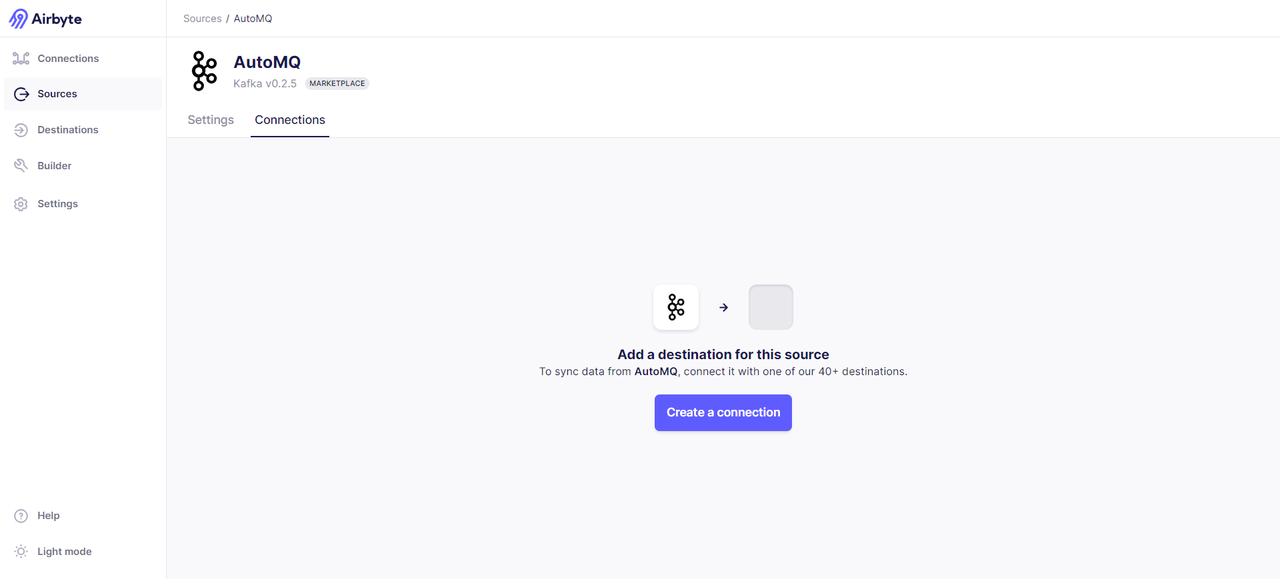
Adding a New Data Destination
For the data endpoint, we have chosen Databricks. Of course, you can also choose other data endpoints. For a specific list, refer to: [Destinations | Airbyte] [9]. Navigate via the sidebar on the left of the Airbyte interface -> Destinations -> search for Databricks.

The credential information that needs to be filled in can be obtained from the Databricks cluster. The specific steps are:
- Enter the created Databricks Cluster -> select Advanced Options -> JDBC/ODBC, where you can see the values for HTTP PATH and Server Hostname.

- Select the user in the upper right corner of the cluster -> Go to Settings -> Select User -> Developer -> AccessToken -> Generate new Token. You will get a Token similar to dapi8d336faXXXXXXXXXa6aa18a086c0e.
After obtaining the credential information, create the data endpoint. If successful, you will see the following interface:
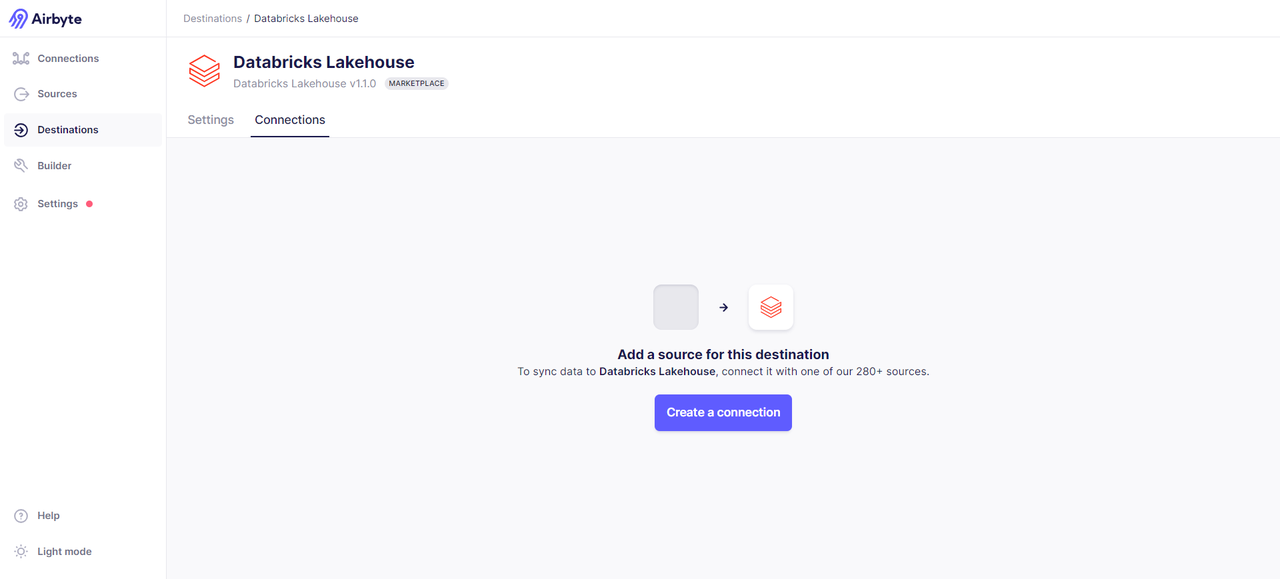
Initiate connection and transfer data
Both the data source and data endpoint are ready. Now we start to establish a connection. Select Airbyte from the left sidebar -> Connections -> Select data source and data endpoint -> Establish connection.
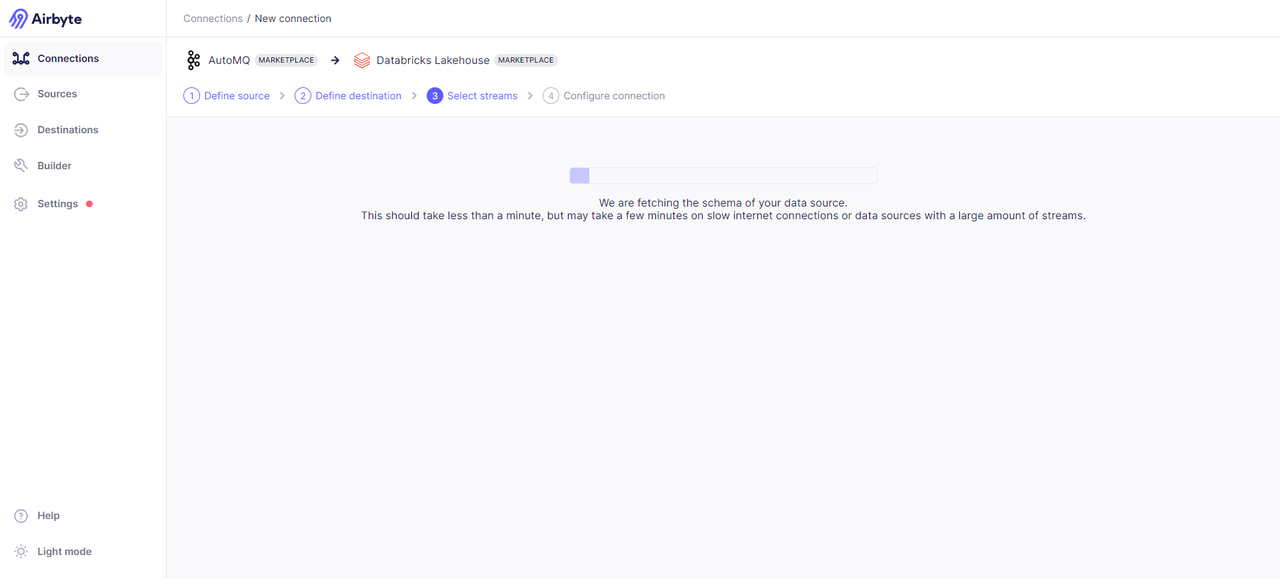
After the connection is successful, select the data transfer method. Incremental synchronization and full synchronization are provided here; I choose the full synchronization method.
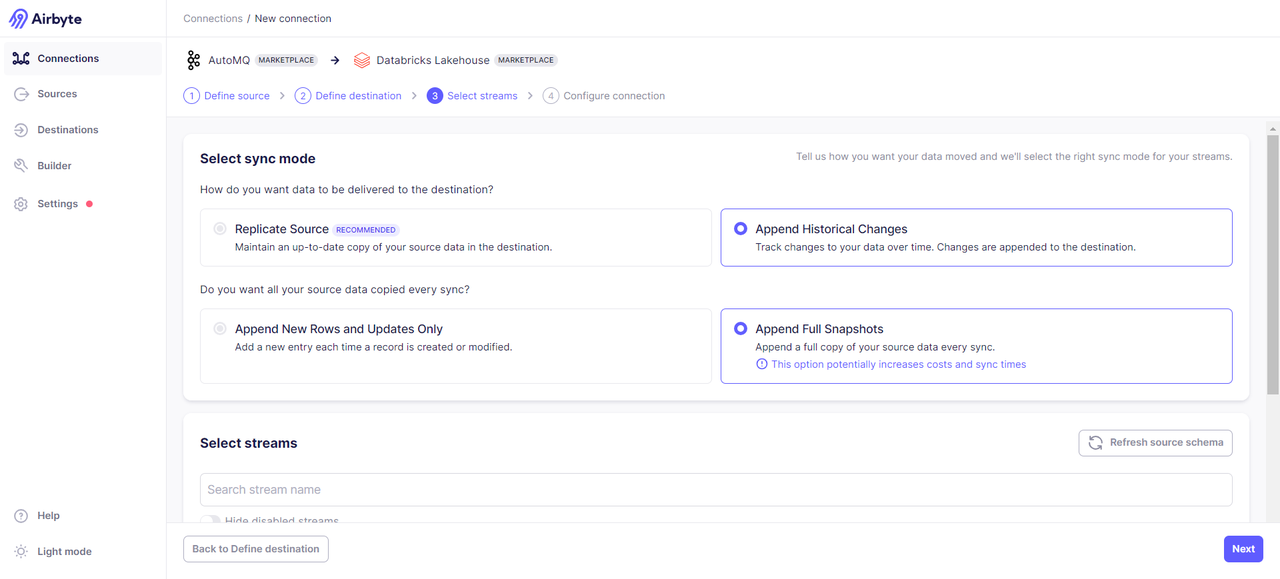
Select the specific Topics data that needs to be transmitted:

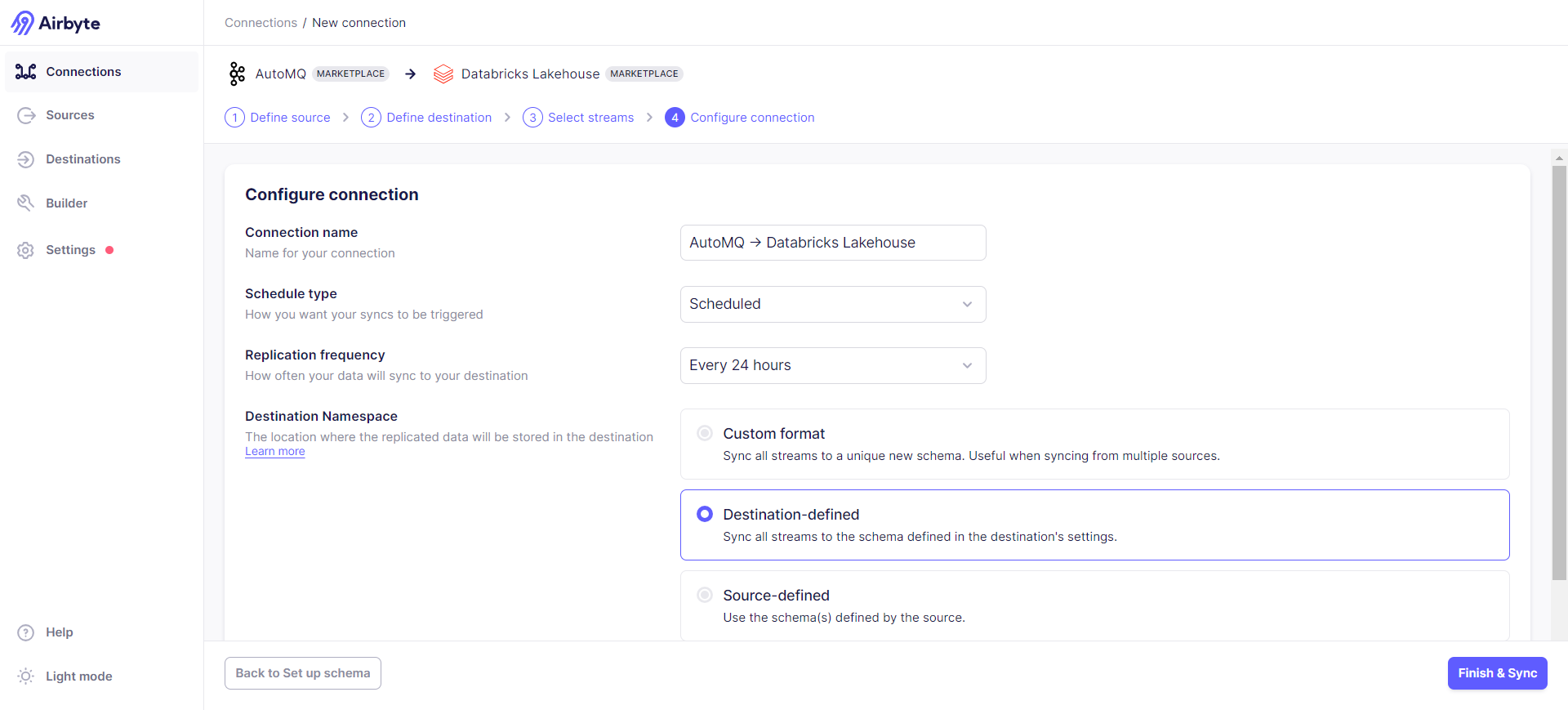
Determine the synchronization frequency and target data format configurations:
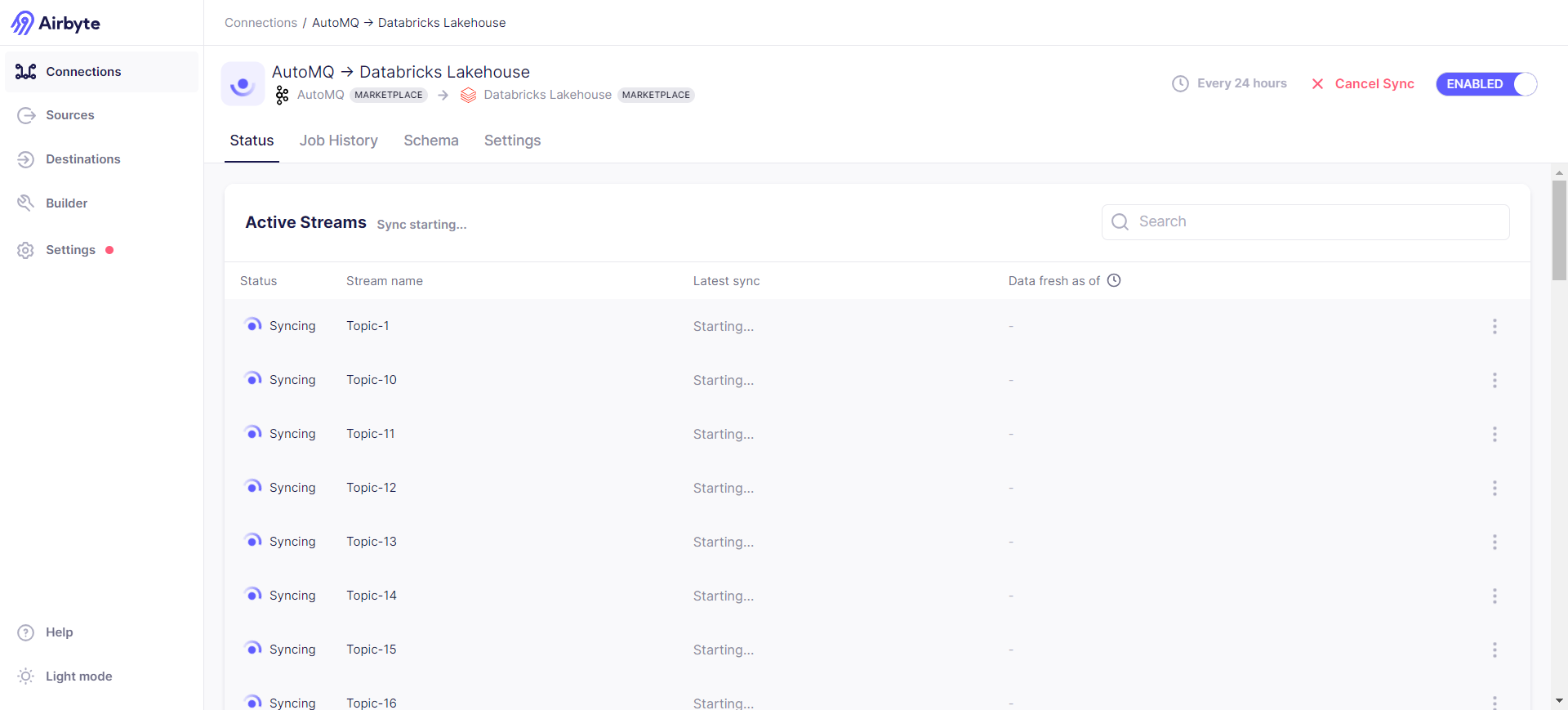
Start synchronization:
You can view the synchronization status through Job History -> Job -> Logs, where part of the log content includes:
2024-07-29 08:53:33 source > INFO o.a.k.c.c.i.AbstractCoordinator(resetStateAndGeneration):998 [Consumer clientId=consumer-airbyte-consumer-group-1, groupId=airbyte-consumer-group] Resetting generation and member id due to: consumer pro-actively leaving the group
2024-07-29 08:53:33 source > INFO o.a.k.c.c.i.AbstractCoordinator(requestRejoin):1045 [Consumer clientId=consumer-airbyte-consumer-group-1, groupId=airbyte-consumer-group] Request joining group due to: consumer pro-actively leaving the group
2024-07-29 08:53:33 source > INFO o.a.k.c.m.Metrics(close):659 Metrics scheduler closed
2024-07-29 08:53:33 source > INFO o.a.k.c.m.Metrics(close):663 Closing reporter org.apache.kafka.common.metrics.JmxReporter
2024-07-29 08:53:33 source > INFO o.a.k.c.m.Metrics(close):669 Metrics reporters closed
2024-07-29 08:53:33 source > INFO o.a.k.c.u.AppInfoParser(unregisterAppInfo):83 App info kafka.consumer for consumer-airbyte-consumer-group-1 unregistered
2024-07-29 08:53:33 source > INFO i.a.c.i.b.IntegrationRunner(runInternal):231 Completed integration: io.airbyte.integrations.source.kafka.KafkaSource
2024-07-29 08:53:33 source > INFO i.a.i.s.k.KafkaSource(main):62 Completed source: class io.airbyte.integrations.source.kafka.KafkaSource
2024-07-29 08:53:33 replication-orchestrator > (pod: airbyte-abctl / source-kafka-read-2-0-pbvbp) - Closed all resources for pod
2024-07-29 08:53:33 replication-orchestrator > Total records read: 0 (0 bytes)
2024-07-29 08:53:33 replication-orchestrator > Schema validation was performed to a max of 10 records with errors per stream.
2024-07-29 08:53:33 replication-orchestrator > readFromSource: done. (source.isFinished:true, fromSource.isClosed:false)
2024-07-29 08:53:33 replication-orchestrator > processMessage: done. (fromSource.isDone:true, forDest.isClosed:false)
2024-07-29 08:53:33 replication-orchestrator > thread status... heartbeat thread: false , replication thread: true
2024-07-29 08:53:33 replication-orchestrator > writeToDestination: done. (forDest.isDone:true, isDestRunning:true)
2024-07-29 08:53:33 replication-orchestrator > thread status... timeout thread: false , replication thread: true
2024-07-29 08:53:35 destination > INFO i.a.i.d.j.JdbcBufferedConsumerFactory(lambda$onStartFunction$1):147 Preparing raw table in destination started for stream Topic-27. schema: default, table name: _airbyte_raw_topic_27
2024-07-29 08:53:40 destination > INFO i.a.i.d.j.JdbcBufferedConsumerFactory(lambda$onStartFunction$1):147 Preparing raw table in destination started for stream Topic-24. schema: default, table name: _airbyte_raw_topic_24
2024-07-29 08:53:45 destination > INFO i.a.i.d.j.JdbcBufferedConsumerFactory(lambda$onStartFunction$1):147 Preparing raw table in destination started for stream Topic-25. schema: default, table name: _airbyte_raw_topic_25
2024-07-29 08:53:50 destination > INFO i.a.i.d.j.JdbcBufferedConsumerFactory(lambda$onStartFunction$1):147 Preparing raw table in destination started for stream Topic-28. schema: default, table name: _airbyte_raw_topic_28
2024-07-29 08:53:55 destination > INFO i.a.i.d.j.JdbcBufferedConsumerFactory(lambda$onStartFunction$1):147 Preparing raw table in destination started for stream Topic-29. schema: default, table name: _airbyte_raw_topic_29
2024-07-29 08:54:01 destination > INFO i.a.i.d.j.JdbcBufferedConsumerFactory(lambda$onStartFunction$1):147 Preparing raw table in destination started for stream Topic-30. schema: default, table name: _airbyte_raw_topic_30
2024-07-29 08:54:06 destination > INFO i.a.i.d.j.JdbcBufferedConsumerFactory(lambda$onStartFunction$1):147 Preparing raw table in destination started for stream Topic-33. schema: default, table name: _airbyte_raw_topic_33
2024-07-29 08:54:10 destination > INFO i.a.i.d.j.JdbcBufferedConsumerFactory(lambda$onStartFunction$1):147 Preparing raw table in destination started for stream Topic-34. schema: default, table name: _airbyte_raw_topic_34
2024-07-29 08:54:15 destination > INFO i.a.i.d.j.JdbcBufferedConsumerFactory(lambda$onStartFunction$1):147 Preparing raw table in destination started for stream Topic-31. schema: default, table name: _airbyte_raw_topic_31
2024-07-29 08:54:19 destination > INFO i.a.i.d.j.JdbcBufferedConsumerFactory(lambda$onStartFunction$1):147 Preparing raw table in destination started for stream Topic-32. schema: default, table name: _airbyte_raw_topic_32
Synchronization successful:

Verification Results
After successful data transfer, we can check the transfer results in the Databricks cluster:

We can see that the data from the selected Topics in the AutoMQ nodes has been successfully synchronized to Databricks. Next, data retrieval and processing can be performed using SQL. For specific syntax, please refer to the official documentation: [SQL language][10].
Summary
This article showcased how to integrate AutoMQ, Airbyte, and Databricks to achieve efficient real-time data flow and analysis. By combining the efficient stream processing of AutoMQ, the flexible data integration of Airbyte, and the powerful data analysis capabilities of Databricks, enterprises can build an efficient, flexible, and scalable data processing platform. This integration not only reduces storage and operational costs but also enhances data processing efficiency and the timeliness of business decisions. We hope this article provides valuable insights for enterprises in the realm of real-time data processing and analysis.
References
[1] AutoMQ: https://www.automq.com/zh
[2] Airbyte: httpsyte: https://airbyte.com/
[3] Databricks: https://www.databricks.com/
[4] Quick Start with AutoMQ: https://docs.automq.com/en/automq/getting-started
[5] Kafdrop: https://github.com/obsidiandynamics/kafdrop
[6] Quickstart Airbyte: https://docs.airbyte.com/using-airbyte/getting-started/oss-quickstart
[7] Docker Install: https://docs.docker.com/desktop/install/linux-install/
[8] Google databricks: https://cloud.google.com/databricks?hl=zh_cn
[9] Destinations : https://docs.airbyte.com/integrations/destinations/
[10] SQL language: https://docs.databricks.com/en/sql/language-manual/index.html





