Apache Kafka has emerged as a powerful distributed streaming platform enabling real-time data pipelines and streaming applications. At the heart of Kafka's architecture lies the broker, a fundamental component responsible for data storage and delivery. This comprehensive blog explores Kafka brokers in detail, covering their definition, core functionality, usage patterns, and recommended best practices for optimal deployment.
Understanding Kafka Brokers
A Kafka broker is a core server component within the Kafka architecture that manages the storage and distribution of data records between producers and consumers. Often referred to as a Kafka server or Kafka node, the broker functions as the central mediator handling the storage of messages in topics and making them available for consumption. Each Kafka broker is assigned a unique integer ID that distinguishes it within the cluster environment.
Brokers are intentionally designed with simplicity in mind, maintaining minimal state to ensure reliability and performance. Their primary responsibilities include writing new events to partitions, serving reads from partitions, and replicating data across the cluster to ensure fault tolerance and high availability. This lightweight design allows each broker to efficiently handle thousands of requests for reads and writes per second, with properly configured brokers capable of managing terabytes of messages without performance degradation.
From an architectural standpoint, brokers form the storage layer of Kafka, writing event data directly to the file system. Each topic-partition combination creates a new subdirectory on the broker's storage, providing organized data management. The straightforward storage mechanism contributes to Kafka's remarkable throughput capabilities, as data can be efficiently written to and read from sequential files on disk.
How Kafka Brokers Work
Kafka brokers operate within a cluster architecture, where multiple broker instances work together to provide a scalable and fault-tolerant streaming platform. When a producer sends data to Kafka, it connects to a broker, which receives the data records, assigns them unique offsets, and stores them on disk in the appropriate topic partition. Consumers then connect to brokers to read these stored events based on their needs.
One of the key architectural aspects of Kafka brokers is the bootstrap server concept. Every Kafka broker functions as a bootstrap server, meaning that clients only need to connect to a single broker to discover the entire cluster topology. Upon connection, the client receives metadata about all brokers, topics, and partitions, enabling direct communication with the appropriate brokers for subsequent operations.
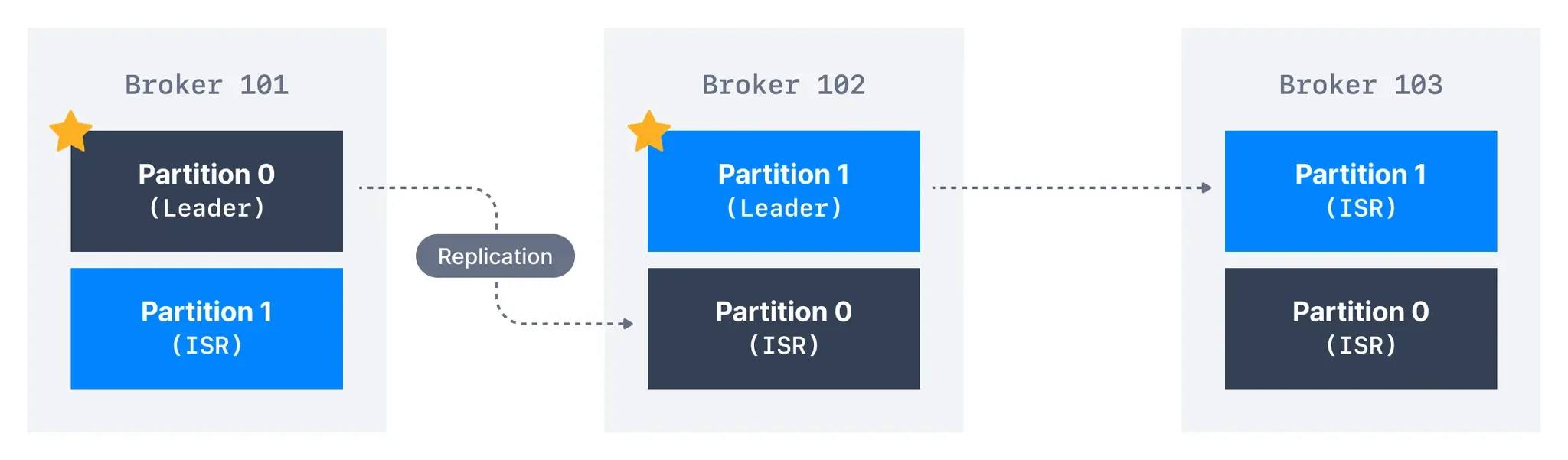
The distribution of data across brokers follows a partition-based approach. Topics in Kafka are divided into partitions, which are distributed across all available brokers in the cluster. This partitioning enables horizontal scaling and load balancing, as no single broker needs to handle all the data for any given topic. For example, if Topic-A has three partitions, these partitions might be distributed across Brokers 101, 102, and 103, with each broker holding a subset of the total partitions.
Within the broker cluster, one broker is designated as the controller. This controller broker assumes additional responsibilities, including maintaining the state of other brokers, managing broker failures, and coordinating the reassignment of work when cluster membership changes. The controller role is crucial for the smooth operation of the entire Kafka ecosystem.
Broker Replication and Failover Mechanisms
Kafka achieves its renowned fault tolerance through sophisticated replication mechanisms implemented at the broker level. Each topic partition is replicated across multiple brokers based on a configurable replication factor. Within this replication scheme, one broker hosts the leader replica for a given partition, while others maintain follower replicas.
The leader replica handles all read and write requests for its assigned partitions, while follower replicas continuously mirror the leader's data to stay in sync. This leader-follower architecture ensures that if the leader broker fails, one of the followers can be quickly promoted to the leader role, maintaining service availability without data loss.
When a broker failure occurs, Kafka's failover process automatically elects new leaders for all the partitions previously led by the failed broker. For example, in a three-broker cluster with a replication factor of three, if one broker fails, Kafka redistributes leadership among the remaining brokers. While the replication factor configuration remains unchanged, the In-Sync Replicas (ISR) list adjusts to reflect only the available brokers.
The recovery process depends on how new brokers are introduced to the cluster. If a replacement broker uses the same broker.id as the failed one, it will automatically start replicating data for its assigned partitions and eventually join the ISR list. However, if a new broker with a different broker.id is introduced, Kafka does not automatically reassign existing partitions without manual intervention.
Best Practices for Kafka Broker Management
Implementing Kafka brokers effectively requires careful attention to configuration, deployment, and ongoing management. The following best practices will help ensure optimal performance and reliability:
Broker Configuration Optimization
Fine-tuning broker configuration is essential for achieving the right balance of performance, durability, and resource utilization. For high availability environments, increase the replication factor to at least three for topics and set the minimum number of in-sync replicas to one less than the replication factor. This configuration ensures that data remains available even if multiple brokers experience failures.
Memory and disk optimization significantly impact broker performance. Utilize high-performance SSDs for storing logs and configure appropriate retention settings through parameters like log.retention.bytes and log.retention.hours. To prevent single points of failure at the storage level, spread logs across multiple disks using separate directories, which improves throughput while reducing the risk of disk-related bottlenecks.
Network configuration requires careful consideration, as both inter-broker and client communication typically use the same network interface and port. Keep inter-broker network traffic on private subnets while allowing client connectivity to brokers. This approach enhances security while maintaining necessary accessibility.
Infrastructure and Deployment Considerations
Physical infrastructure decisions profoundly impact Kafka broker reliability. The best practice is to deploy each broker in a different rack to avoid shared failure points for critical infrastructure services like power and networking. Implement dual power connections to separate circuits and deploy dual network switches with bonded interfaces on servers to enable seamless failover.
Cluster sizing should align with anticipated workload requirements. While three brokers provide a good starting point for many applications, larger deployments might require dozens or even hundreds of brokers. When planning capacity, consider the recommended number of partitions per broker based on broker size. For example, kafka.m5.large or kafka.m5.xlarge instances can typically handle 1000 partitions per broker under normal conditions.
Monitor CPU utilization carefully, as it directly impacts broker performance. Maintain total CPU utilization (CPU User + CPU System) under 60% to ensure adequate headroom for processing spikes. Exceeding this threshold can lead to degraded performance, increased latency, and potential stability issues.
Monitoring and Health Management
Implementing comprehensive monitoring is critical for maintaining healthy Kafka brokers. Set up real-time alerts for key metrics including CPU usage, memory consumption, and disk I/O. These indicators provide early warning of potential issues before they impact service availability.
The ActiveControllerCount metric warrants special attention, as it indicates the number of active controllers in the Kafka cluster. In a healthy environment, this value should always be 1, indicating that exactly one broker is serving as the controller. Deviations from this value suggest controller election problems that require immediate investigation.
Broker logs provide valuable insight into system health. Monitor them for telltale signs of problems such as high garbage collection pauses or increasing disk latency. Addressing these warnings proactively can prevent more severe issues from developing.
Client-Side Considerations
Client configuration significantly impacts overall system reliability and performance. Configure all clients for high availability to ensure they can handle broker failures gracefully. Remember that while Kafka clusters are designed to tolerate broker failures, client applications must be equally resilient.
Ensure that client connection strings include at least one broker from each availability zone to facilitate failover when specific brokers are unavailable. This diversity in connection points prevents clients from losing connectivity during planned or unplanned broker outages.
Before deploying to production, conduct thorough performance testing with your specific client configurations to verify that they meet your performance objectives. Different client libraries and configuration settings can yield dramatically different results, making empirical testing essential.
Differences between AutoMQ and Kafka Brokers
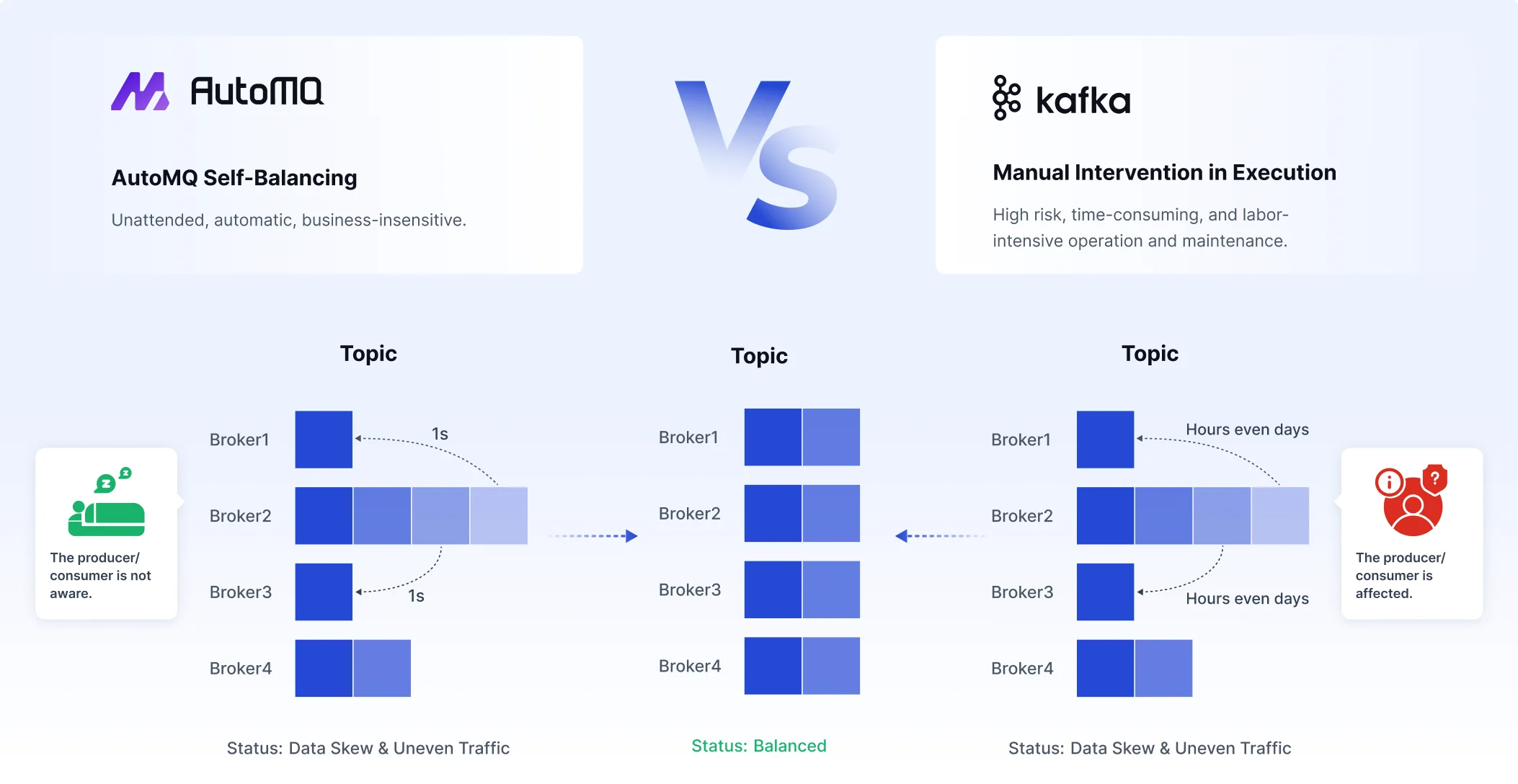
AutoMQ is a next-generation Kafka that is 100% fully compatible and built on top of S3. AutoMQ also uses the concept of brokers. The key difference from Kafka is that AutoMQ doesn't rely on ISR multiple replicas for data durability—instead, it uses cloud storage to ensure data persistence. This means AutoMQ brokers don't need to maintain multiple replicas internally like Apache Kafka does. Based on this cloud-first design philosophy, AutoMQ introduces innovative features such as second-level partition migration, rapid auto-elasticity, and continuous rebalancing. If you're interested in learning more, please check out this article:
Conclusion
Kafka brokers form the backbone of the Apache Kafka ecosystem, enabling reliable, scalable, and high-performance data streaming across a wide range of applications. By storing and distributing messages between producers and consumers, brokers facilitate the decoupling of data generation from consumption, creating flexible and resilient data pipelines.
Understanding the fundamentals of broker architecture, including topics, partitions, and replication, is essential for effectively implementing Kafka in production environments. By following the best practices outlined in this report—including optimizing broker configuration, implementing appropriate infrastructure, establishing comprehensive monitoring, and properly configuring clients—organizations can ensure their Kafka deployments deliver the performance, reliability, and scalability required for modern data streaming applications.
As data volumes continue to grow and real-time processing becomes increasingly critical, the role of properly managed Kafka brokers will only become more significant. With careful attention to design, configuration, and operational practices, Kafka brokers provide a solid foundation for building the next generation of data-intensive applications.


