.png)
Introduction
In the landscape of modern data architecture, Apache Kafka has established itself as the de facto standard for real-time event streaming. Its ability to handle massive volumes of data with high throughput and low latency has made it the backbone of countless data-driven applications, from microservices communication to real-time analytics and IoT data ingestion. As organizations grow and their data strategies mature, the platforms they built yesterday may no longer meet the demands of tomorrow. This brings us to a critical and often complex undertaking: Kafka migration.
But what exactly is Kafka migration? Is it just a simple version upgrade? And more importantly, why do engineering teams invest significant time and resources into such a process?
This blog post provides a comprehensive explanation for software engineers and architects. We will define the various forms of Kafka migration and explore the fundamental technical and business drivers that make it not just a beneficial project, but often a necessary one for long-term success.

Defining Kafka Migration: More Than an Upgrade
At a high level, Kafka migration is the process of moving a Kafka cluster, its underlying data, its configurations, and its connected client applications from a source environment to a different target environment. While a version upgrade is a type of migration, the term encompasses a much broader set of scenarios, each with unique challenges and motivations.
The scope of a migration project typically involves several key components:
Cluster & Broker Migration: Moving the Kafka brokers themselves to new infrastructure.
Data Replication: Ensuring that all topic data, including historical logs and recent messages, is present in the target cluster without loss.
Metadata Migration: Transferring critical cluster information, such as topic configurations, Access Control Lists (ACLs), and consumer group offsets.
Ecosystem Migration: Moving adjacent components like Schema Registry, Kafka Connect clusters, and other tools that depend on Kafka.
Client Application Cutover: Re-configuring and redirecting all producers and consumers to communicate with the new cluster, ideally with minimal to zero downtime.
We can categorize most Kafka migrations into one of the following types:
On-Premise to On-Premise: This often involves moving from an older data center to a new one or refreshing underlying hardware. The core architecture remains self-managed, but the physical infrastructure changes.
On-Premise to Cloud: This is arguably the most common and transformative type of migration. It involves moving a self-hosted Kafka cluster from an organization's own data center to a public or private cloud environment, either as a self-managed deployment on virtual machines or, more commonly, to a managed streaming service.
Cloud to Cloud (or Region to Region): This involves moving a cluster from one cloud provider to another or between different geographic regions within the same cloud. This is often driven by cost, performance, or data sovereignty requirements.
Version-to-Version: This is the classic upgrade path, moving from an older version of Apache Kafka to a newer one to leverage new features, performance improvements, and security patches. Migrations between major versions can be complex enough to warrant a full migration strategy rather than an in-place upgrade.
The Core Drivers: Why is Kafka Migration Necessary?
Undertaking a migration is a significant technical decision. The motivations behind it are rarely singular and usually represent a confluence of technical debt, strategic goals, and evolving operational realities. Let's explore the primary drivers.
Reducing Operational Overhead and Total Cost of Ownership (TCO)
Self-managing an Apache Kafka cluster is a notoriously complex and resource-intensive endeavor. An engineering team is responsible for the entire stack, which includes:
ZooKeeper Management: Kafka has historically depended on Apache ZooKeeper for metadata management, leader election, and configuration storage. Managing a separate, mission-critical distributed system just to support Kafka adds significant operational overhead.
Manual Scaling and Rebalancing: When the cluster needs to be scaled up, engineers must provision new servers, install software, and then manually trigger the partition rebalancing process. This process involves physically copying massive amounts of data across the network, which is slow and can impact cluster performance if not managed carefully [1].
Patching and Upgrades: The team is responsible for applying security patches and performing version upgrades for the operating system, the JVM, ZooKeeper, and Kafka itself.
Monitoring and Troubleshooting: Setting up comprehensive monitoring and alerting requires deep expertise. When issues arise, troubleshooting performance bottlenecks or broker failures is a specialized skill.
Each of these tasks translates directly into engineering hours, which often represents the largest portion of a system's Total Cost of Ownership (TCO). Many organizations migrate from a self-hosted model to a managed service specifically to offload this operational burden. By doing so, they free up their highly skilled engineers to focus on building value-added applications rather than performing routine infrastructure maintenance.
The Pursuit of Scalability and Elasticity
For many businesses, data workloads are not static; they are bursty and unpredictable. An e-commerce platform experiences massive traffic spikes during holiday seasons, while a financial services application might see a surge in trading data during market volatility.
Scaling a self-managed, on-premise Kafka cluster to meet this demand is challenging. The process involves hardware procurement, which can have lead times of weeks or months. Consequently, teams are often forced to overprovision their clusters, paying for peak capacity 24/7 even if it is only needed 5% of the time. This is economically inefficient.
Cloud environments, by contrast, offer elasticity—the ability to dynamically scale resources up or down based on real-time demand. Migrating Kafka to the cloud allows organizations to:
Scale on Demand: Add or remove broker capacity in minutes, not months.
Handle Traffic Bursts: Automatically scale the cluster to handle sudden increases in message volume and then scale back down to save costs once traffic subsides.
Decouple Storage from Compute: Modern cloud-native storage solutions allow storage to scale independently of the compute resources, providing another lever for cost-effective scaling [2].
This elasticity ensures that the data platform can grow with the business without requiring massive upfront capital investment or suffering from performance degradation during peak loads.
Modernization and Access to Advanced Features
The Apache Kafka project is continuously evolving, with new features and architectural improvements introduced in each major release. Older, self-managed clusters often lag behind, missing out on crucial capabilities that can enhance performance, reduce costs, and simplify operations.
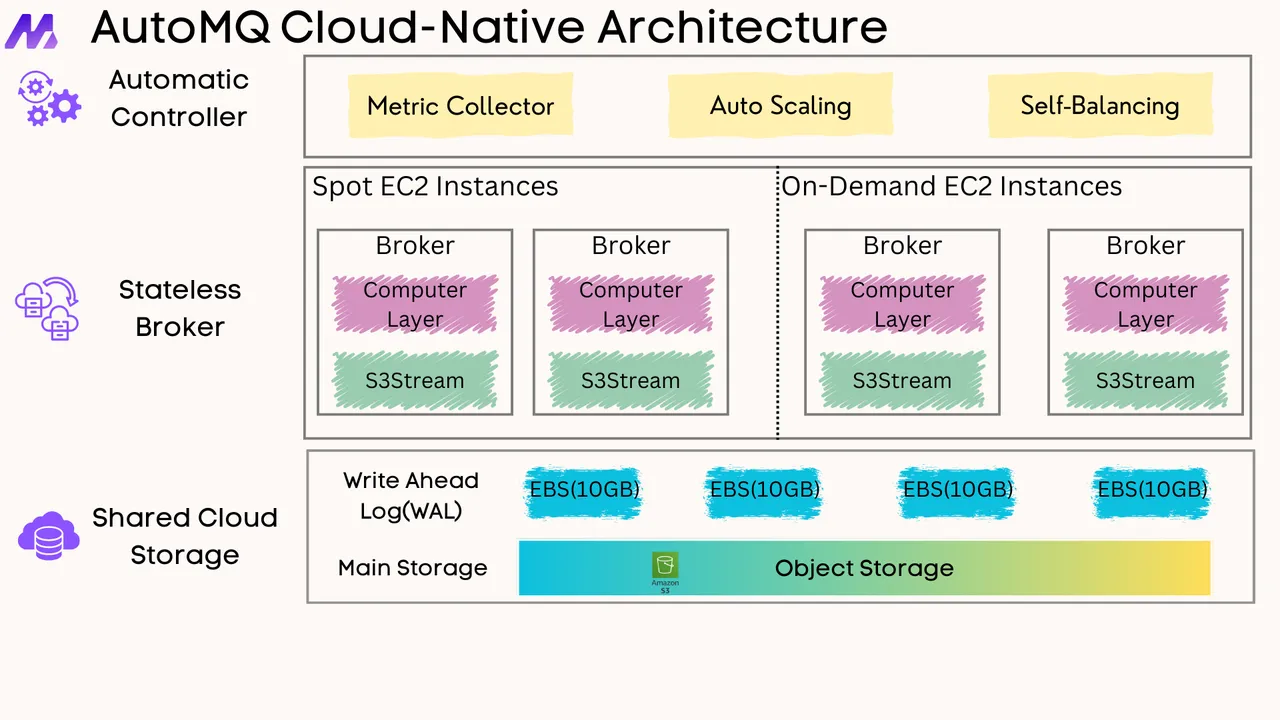
A primary driver for migration is to gain access to these modern features. One of the most significant architectural advancements in recent years is Tiered Storage. In traditional Kafka, all data—whether it is from five minutes ago or five months ago—resides on the expensive, high-performance disks attached to the brokers. This makes retaining data for long periods prohibitively expensive. Tiered Storage solves this by automatically moving older, less-frequently-accessed data segments to a cheaper, scalable object store (like Amazon S3 or Google Cloud Storage) while keeping recent data on the brokers for fast access. This architecture dramatically reduces storage costs and enables "infinite" data retention in Kafka, transforming it from a short-term message buffer into a true streaming data record system.
Other modernization drivers include:
Simplified Management: Newer versions of Kafka have made strides in reducing the dependency on ZooKeeper, simplifying the overall architecture.
Enhanced Security: Modern platforms offer more granular security controls, better integration with identity management systems, and simpler encryption configuration.
Richer Ecosystem: Managed platforms often come with pre-built connectors, robust management APIs, and user interfaces that accelerate development and simplify operations.
Enhancing Reliability and Availability
For a system that serves as the central nervous system for a company's data, reliability is non-negotiable. While Kafka is designed for fault tolerance, achieving high availability with a self-hosted deployment requires meticulous planning and execution. The cluster is vulnerable to data center power outages, network partitions, and correlated hardware failures.
Cloud providers, on the other hand, build their infrastructure around the concept of Availability Zones (AZs)—distinct physical data centers within a single geographic region. By migrating to a cloud-based solution, organizations can easily deploy a Kafka cluster that spans multiple AZs. If one entire data center fails, the cluster can continue operating without data loss or significant downtime by failing over to the brokers in the other AZs [3]. This multi-AZ architecture provides a level of resilience that is often too complex and expensive for most organizations to achieve on their own premises.
Data Gravity and Ecosystem Integration
"Data gravity" is the idea that data exerts a force, pulling applications and services towards it. As an organization's digital footprint grows, it becomes increasingly inefficient to have different parts of the data ecosystem separated by high-latency networks.
If a company has migrated its primary databases, data warehouse, and analytics platforms to the cloud, keeping its Kafka cluster on-premise creates a major architectural bottleneck. Every message produced or consumed by a cloud-based application must traverse the network link between the data center and the cloud, incurring latency and data egress costs.
To eliminate this friction, organizations migrate their Kafka clusters to be "close" to the rest of their data ecosystem. Placing the event streaming platform in the same cloud and region as the applications and services that depend on it minimizes latency, reduces data transfer costs, and simplifies the overall architecture.
End-of-Life (EOL) and Security
Finally, one of the most practical and urgent drivers for migration is the end-of-life (EOL) of supporting software. Running outdated versions of Apache Kafka, ZooKeeper, or the underlying operating systems exposes an organization to known security vulnerabilities that are no longer being patched by the community or vendors. This is not just a technical risk but also a significant business and compliance risk. A migration is often the required path to move to a fully supported and secure software stack, ensuring the platform remains compliant with industry standards and protected against emerging threats.
Conclusion
Kafka migration is far more than a simple maintenance task; it is a strategic engineering initiative that reflects the evolution of an organization's data needs. Whether driven by the desire to reduce operational costs, the need for elastic scale, the pursuit of modern features, or the mandate for higher reliability and security, a well-executed migration can fundamentally transform a company's ability to leverage real-time data. While the process is complex and requires careful planning, the outcome is often a more resilient, efficient, and future-proof data backbone poised to support the next generation of applications and insights.
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
JD.comx AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging