The integration of Apache Kafka with Kubernetes has revolutionized how organizations deploy and manage scalable, resilient streaming platforms. This comprehensive blog explores the various Kafka operators available for Kubernetes, their deployment methodologies, and best practices for maintaining high-performance Kafka clusters. Understanding these elements is crucial for architecting robust streaming solutions that can handle the demands of modern data-intensive applications.
Understanding Kafka Operators in Kubernetes
Kubernetes operators extend the platform's capabilities by encoding domain-specific knowledge about applications into custom controllers. For stateful applications like Kafka, operators are particularly valuable as they automate complex operational tasks that would otherwise require manual intervention. Operators follow the Kubernetes control loop pattern, continuously reconciling the desired state with the actual state of the system.
The operator pattern emerged as a solution to the challenges of running stateful applications on Kubernetes. According to the Confluent blog, "The Operator pattern is used to encode automations that mimic 'human operator' tasks, like backing up data or handling upgrades". This paradigm allows organizations to manage Kafka deployments declaratively, treating infrastructure as code and employing GitOps methodologies for consistent, repeatable deployments.
Kafka operators typically handle several key responsibilities. They automate the provisioning of Kafka clusters with the correct configurations, manage broker scaling operations while ensuring proper data distribution, coordinate rolling upgrades without service disruption, and implement security mechanisms. As noted in the CNCF documentation, "Strimzi itself has three core components. A Cluster Operator deploys an Apache Kafka cluster by starting the brokers with the desired configuration and manages rolling upgrades". This level of automation significantly reduces the operational burden on platform teams.
Major Kafka Operators Comparison
Several Kafka operators have emerged in the ecosystem, each with distinct features and capabilities. Understanding their differences is essential for selecting the right solution for your specific requirements.
Strimzi Kafka Operator
Strimzi has gained significant adoption as an open-source operator for Kafka on Kubernetes. It has graduated to CNCF incubation status, with over 1,600 contributors from more than 180 organizations. Strimzi provides comprehensive capabilities for managing Kafka clusters, including:
Strimzi deploys Kafka using a custom resource approach, making it highly customizable for different environments. It includes a Cluster Operator for managing the Kafka cluster, a Topic Operator for managing Kafka topics via KafkaTopic custom resources, and a User Operator for managing access permissions through KafkaUser resources. This modular design provides flexibility in deployment options.
A notable advantage of Strimzi is its support for the OAuth 2.0 protocol, HTTP-based endpoints for Kafka interaction, and the ability to configure Kafka using ConfigMaps or environment variables. As the CNCF documentation notes, "The goal is to work with the CNCF to eventually create enough momentum around an effort to streamline the deployment of an Apache Kafka platform that IT teams employ for everything from sharing log data to building complex event-driven applications".
Confluent Operator
Confluent Operator represents the enterprise option in the Kafka operator ecosystem. It's designed specifically for deploying and managing Confluent Platform, which extends beyond Apache Kafka to include additional components like Schema Registry, Kafka Connect, and ksqlDB.
According to Confluent's documentation, "Confluent Operator allows you to deploy and manage Confluent Platform as a cloud-native, stateful container application on Kubernetes and OpenShift". The operator provides automated provisioning, rolling updates for configuration changes, and rolling upgrades without impacting Kafka availability. It also supports metrics aggregation using JMX/Jolokia and metrics export to Prometheus.
The Confluent Operator is compatible with various Kubernetes distributions, including Pivotal Cloud Foundry, Heptio Kubernetes, Mesosphere DC/OS, and OpenShift, as well as managed Kubernetes services like Amazon EKS, Google Kubernetes Engine, and Microsoft AKS.
Deployment Strategies
Using Helm Charts for Kafka Deployment
Helm charts provide a package manager approach for deploying Kafka on Kubernetes. They offer a simpler entry point compared to operators but with less operational automation for day-2 operations. The deployment process typically involves:
-
Setting up a Kubernetes cluster with adequate resources
-
Installing Helm and adding required repositories
-
Configuring deployment values
-
Deploying Kafka using the helm chart
For example, to deploy Kafka using Confluent's Helm repository:
helm repo add confluentinc <https://packages.confluent.io/helm> helm repo update helm install my-kafka confluentinc/kafkaUsing Kafka Operators
Operators provide more sophisticated management capabilities compared to Helm charts. They handle the entire application lifecycle, not just installation. For example, to deploy the Strimzi operator using Helm:
helm repo add strimzi <https://strimzi.io/charts/> helm install my-strimzi-operator strimzi/strimzi-kafka-operatorAfter installing the operator, you would create a Kafka custom resource (CR) that defines your desired Kafka cluster configuration. The operator then continuously reconciles the actual state with this desired state, handling scenarios like node failures, scaling operations, and configuration changes.
Manual Deployment with Kubernetes Resources
For those who need complete control, manual deployment using native Kubernetes resources is possible but significantly more complex. This approach involves:
-
Creating network policies for Kafka communication
-
Deploying ZooKeeper as a StatefulSet (if using traditional Kafka)
-
Creating ZooKeeper services
-
Deploying Kafka brokers as StatefulSets
-
Creating Kafka headless services
This method requires deeper understanding of both Kafka and Kubernetes but offers maximum flexibility for customization.
Best Practices for Kafka on Kubernetes
Using Separated Storage and Compute in Kafka for Better Operations and Scaling
Kubernetes is primarily designed for cloud-native stateless applications. The main challenge of running Kafka on Kubernetes lies in its architecture that couples compute and storage, with strong dependency on local disks. This makes Kafka difficult to manage and scale on Kubernetes. With the continuous evolution of the Kafka ecosystem, you can now choose next-generation storage-compute separated Kafka solutions like AutoMQ. AutoMQ is built entirely on S3, with complete separation of compute and storage. The stateless Broker significantly reduces the management complexity of Kafka on Kubernetes.
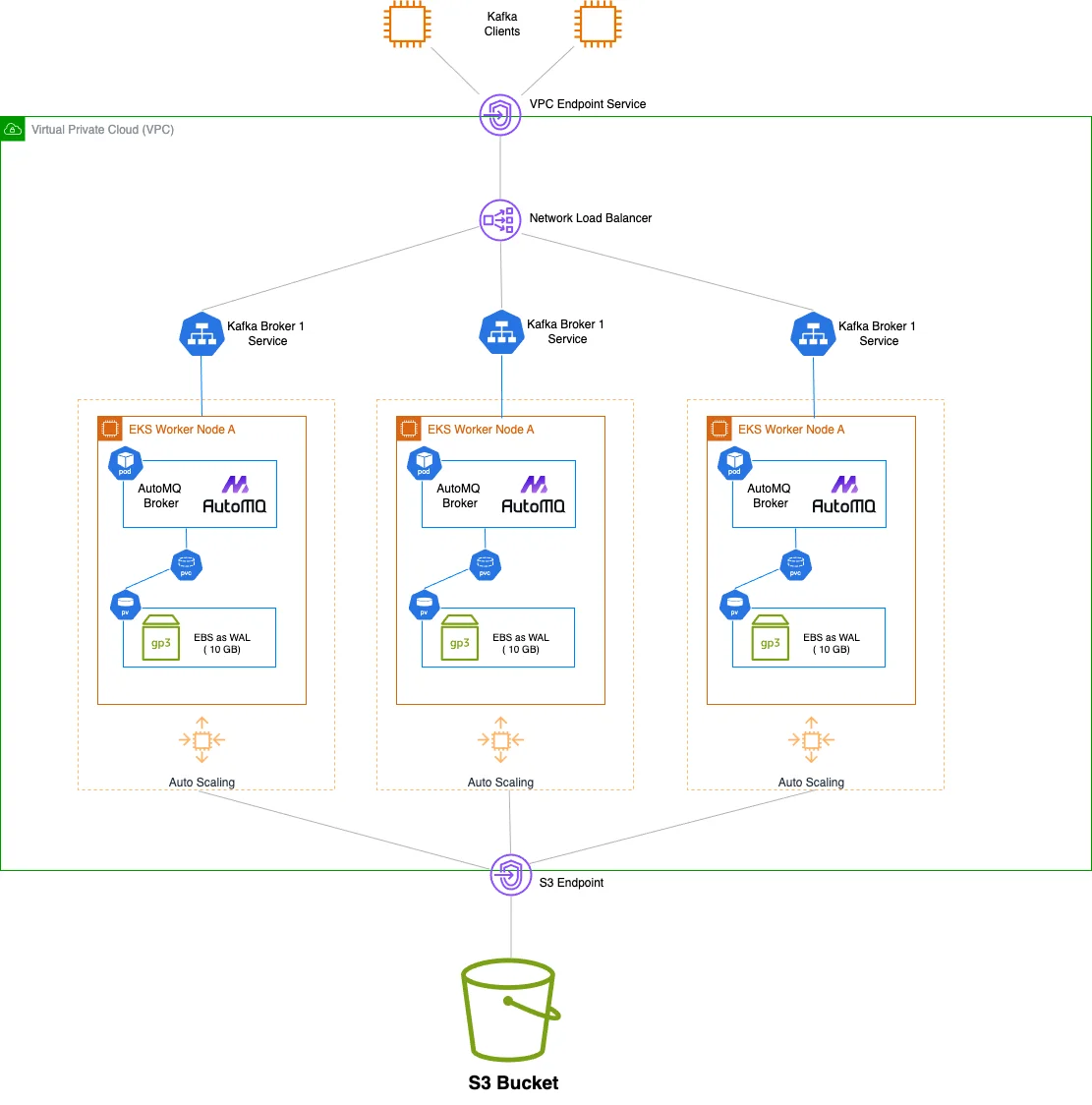
High Availability Configuration
For robust fault tolerance and high availability, implement these strategies:
-
Deploy Kafka brokers across multiple availability zones to protect against zone failures
-
Configure a replication factor of at least 2 for each partition to ensure data durability
-
Use pod anti-affinity rules to distribute Kafka brokers across different nodes
-
Implement proper leader election to minimize downtime during failures
Resource Management and Performance Tuning
Proper resource allocation is critical for Kafka performance on Kubernetes:
-
Set appropriate CPU and memory requests and limits in Kubernetes manifests
-
Configure JVM heap size according to available container memory (typically 50-70%)
-
Adjust producer settings like batch size, linger time, and compression to optimize throughput
-
Optimize consumer configurations including fetch size and max poll records
As noted in the expert guide, "There is a trade-off between different batch sizes for producers. Too small off a batch size can decrease throughput, whereas a very large size may result in the wasteful use of memory and higher latency". Finding the right balance for your specific workload is essential.
Storage Configuration
Kafka's performance and reliability depend significantly on storage configuration:
-
Use persistent volumes for data retention to maintain data across pod rescheduling
-
Select appropriate storage class based on performance requirements
-
Consider volume replication for faster recovery after node failures
-
Implement proper storage monitoring to detect and address issues proactively
Network Configuration
Networking is one of the most challenging aspects of running Kafka on Kubernetes:
-
Use headless services for broker discovery within the cluster
-
Configure advertised listeners correctly for both internal and external communication
-
Address the "bootstrap server" challenge for external clients
-
Consider using NodePort or LoadBalancer services for external access
Topic Configuration Best Practices
Proper topic configuration enhances Kafka's performance and reliability:
-
For fault tolerance, configure two or more replicas for each partition
-
Control message size to improve performance - "Messages should not exceed 1GB, which is the default segment size"
-
Calculate partition data rate to properly size your infrastructure
-
For high-throughput systems, consider isolating mission-critical topics to dedicated brokers
-
Establish a policy for cleaning up unused topics to manage cluster resources effectively
Security Implementation
Security for Kafka on Kubernetes should be implemented at multiple levels:
-
Encrypt data in transit using TLS/SSL
-
Implement authentication using SASL or mutual TLS
-
Configure authorization with Access Control Lists (ACLs)
-
Use Kubernetes secrets for credential management
-
Implement network policies to control traffic flow
As noted in Red Hat's documentation, "To enhance security, configure TLS encryption to secure communication between Kafka brokers and clients. You can further secure TLS-based communication by specifying the supported TLS versions and cipher suites in the Kafka broker configuration".
Common Challenges and Solutions
Managing Stateful Workloads on Kubernetes
Running stateful applications like Kafka on Kubernetes presents unique challenges:
-
Ensuring persistent identity and storage for Kafka brokers
-
Handling pod rescheduling without data loss
-
Managing upgrades without service disruption
To address these challenges, use StatefulSets and Headless services. StatefulSets provide stable identities for pods, ensuring consistent addressing even after rescheduling.
Handling Scaling Operations
Scaling Kafka on Kubernetes requires careful planning:
-
Properly configure partition reassignment during scaling to redistribute load
-
Manage leader rebalancing to prevent performance degradation
-
Plan for increased network traffic and disk I/O during scaling operations
When scaling a Kafka cluster, use the operator's provided mechanisms rather than manually modifying the StatefulSets. As noted in a Stack Overflow response regarding Strimzi, "You should not touch the StatefulSet resources created by Strimzi... If you want to scale the Kafka cluster, you should edit the Kafka custom resource and change the number of replicas in .spec.kafka.replicas".
Monitoring and Troubleshooting
Effective monitoring is essential for maintaining healthy Kafka clusters on Kubernetes:
-
Implement comprehensive metrics collection using Prometheus and Grafana
-
Monitor key metrics including broker health, consumer lag, and partition status
-
Set up alerts for critical conditions
-
Collect and analyze logs for troubleshooting
For troubleshooting, Koperator documentation suggests first verifying that the operator pod is running, checking that Kafka broker pods are running, examining logs of affected pods, and checking the status of resources.
Choosing the Right Kafka Operator
When selecting a Kafka operator, consider these factors:
-
Maturity and community support
-
Feature completeness for your requirements
-
Integration with your existing ecosystem
-
Enterprise support options
-
Ease of deployment and management
Strimzi is an excellent choice for organizations seeking an open-source, community-supported option with CNCF backing. It provides a comprehensive feature set and has a large community of contributors.
Confluent Operator is ideal for organizations already using Confluent Platform or requiring enterprise support. It provides the most integrated experience for the complete Confluent ecosystem but comes with licensing costs.
KUDO Kafka offers a balance of features and simplicity, particularly for those already using the KUDO framework for other applications.
Redpanda Operator is worth considering for those open to an alternative to traditional Kafka that offers performance improvements and architectural simplifications.
Conclusion
Deploying Kafka on Kubernetes using operators offers significant benefits in terms of automation, scalability, and operational efficiency. Each operator provides different capabilities and integration points, allowing organizations to select the option that best aligns with their requirements and ecosystem.
By following the best practices outlined in this report and considering the unique challenges of running stateful workloads like Kafka on Kubernetes, organizations can build robust, scalable streaming platforms that meet the demands of modern data-intensive applications. Whether you choose Strimzi, Confluent Operator, KUDO Kafka, or Redpanda Operator, the key is to leverage the declarative, automated approach that Kubernetes operators provide to reduce operational complexity and focus on delivering business value through your streaming applications.
Still struggling with skyrocketing Kafka bills and the "ops tax" of manual disk management? It's time to stop babysitting your clusters. Try AutoMQ Cloud for Free and experience how diskless architecture slashes costs and automates scaling—no credit card required. See how others made the switch in our case studies or explore the project on GitHub.


