Overview
Apache Kafka has become a cornerstone technology for building scalable, high-throughput streaming data pipelines. At the heart of Kafka's architecture lies a fundamental concept: partitions. Partitions are the key to Kafka's scalability, fault tolerance, and performance capabilities. This comprehensive guide explores what Kafka partitions are, how they work, and best practices for implementing them effectively in your data streaming architecture.
What Are Kafka Partitions?
Partitions are the foundational unit of parallelism and scalability in Apache Kafka. In simple terms, a partition is an ordered, immutable sequence of messages that belongs to a specific topic. When you create a Kafka topic, it is divided into one or more partitions, each functioning as an independent, ordered log file that holds a subset of the topic's data.
Each message in a partition is assigned a sequential identifier called an offset, which uniquely identifies each message within the partition. Consumers read messages from the beginning to the end of a partition, with messages received earlier consumed first. This sequential nature of partitions is what enables Kafka to maintain order guarantees for message processing.
Partitions serve multiple critical functions within Kafka's architecture:
-
They enable horizontal scaling by distributing data across multiple brokers
-
They provide the foundation for parallel processing of messages
-
They facilitate fault tolerance through replication
-
They allow for independent consumption of data by different consumer groups
Partition Architecture and Message Flow
Within Kafka's distributed architecture, partitions play a central role in how data is organized and processed. A topic in Kafka is broken down into multiple partitions, and these partitions are distributed across the brokers in a Kafka cluster. This distribution enables Kafka to scale beyond the limits of a single server by parallelizing operations.
When a producer sends a message to a topic, the message is routed to a specific partition. This routing can be determined by several factors, including a partition key specified by the producer. Once a message arrives at a partition, it is appended to the end of the partition's log and assigned a sequential offset number.
Each partition has exactly one leader broker and can have multiple follower brokers. The leader handles all read and write requests for the partition, while followers passively replicate the data. This leader-follower model is central to Kafka's fault tolerance mechanism.
Consumers read messages from partitions by specifying the partition offset from which they want to start consuming. Since partitions are ordered logs, consumers can read messages in the exact order they were written. However, order guarantees only exist within a partition, not across different partitions of the same topic.
Producer Partition Strategies
When producing messages for a Kafka topic, several strategies determine how messages are distributed among partitions:
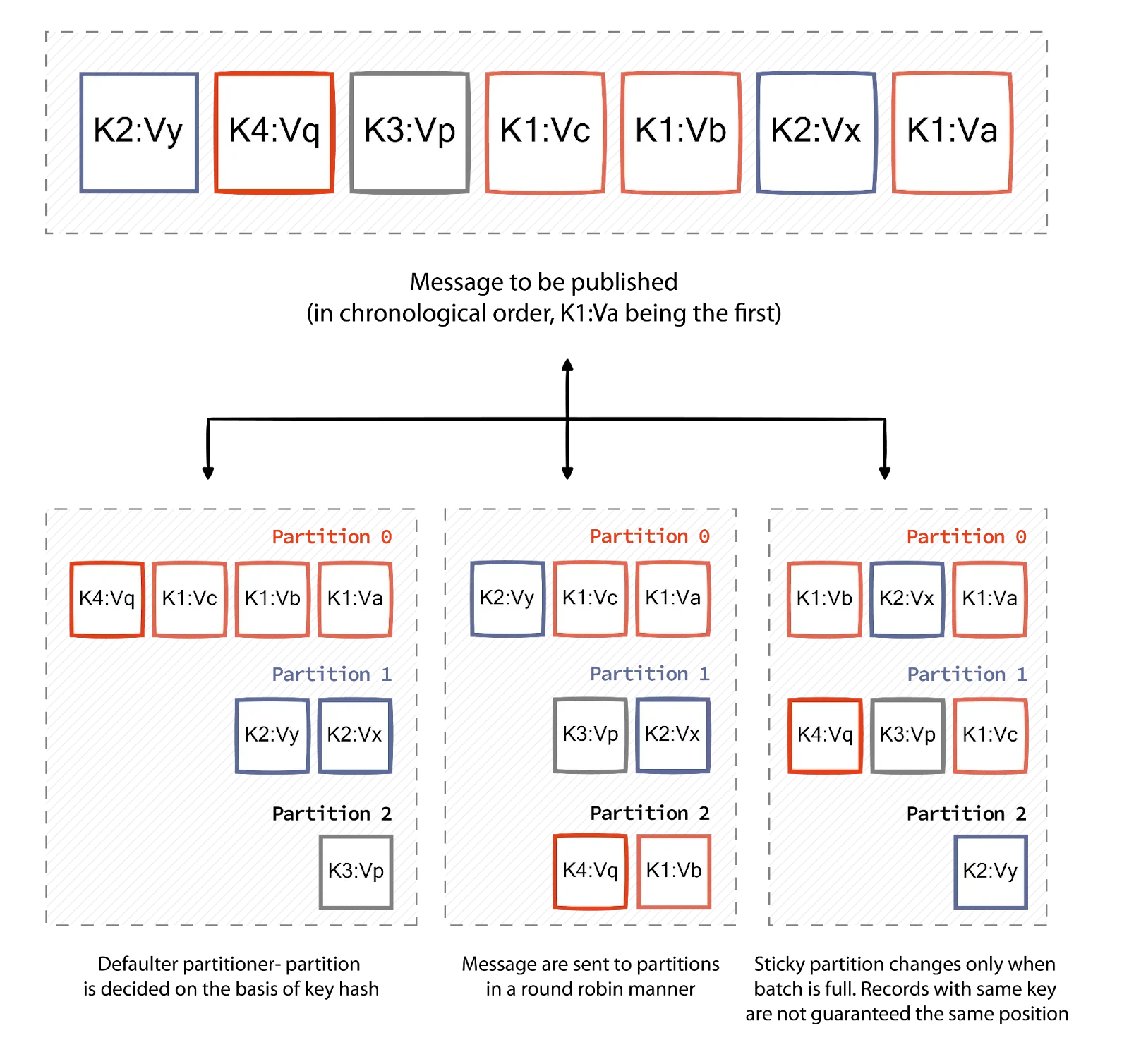
Default Partition Strategy
The default strategy uses a hash of the message key to determine which partition receives the message. This ensures that messages with the same key always go to the same partition, which maintains order for related messages. For messages with null keys, Kafka uses a round-robin approach to distribute them evenly across partitions.
Round-Robin Partition Strategy
This strategy assigns messages to partitions in a cyclic manner, regardless of message content. It ensures an even distribution of messages across all partitions but doesn't guarantee that related messages will be processed in order since they may end up in different partitions.
Uniform Sticky Partition Strategy
This approach sends messages to a "sticky" partition until either the batch size limit is reached or the linger time expires. This strategy reduces latency by minimizing the number of requests made to the cluster while still maintaining a relatively even distribution of messages.
Custom Partition Strategy
For specialized use cases, Kafka allows the implementation of custom partitioning logic by implementing the Partitioner interface. This provides complete control over how messages are mapped to partitions based on application-specific requirements.
Consumer Partition Strategies
How consumers read from partitions is equally important for system performance:
Range Assignment Strategy
This is the default strategy, which assigns contiguous ranges of partitions to consumers in the same consumer group. For example, if there are 10 partitions and 5 consumers, each consumer would be assigned 2 consecutive partitions.
Multiple Consumer Groups
Different applications can subscribe to the same topic using different consumer group IDs. This allows for independent consumption of messages, enabling diverse use cases from the same data stream. For instance, one consumer group might process messages for analytics while another handles real-time alerts.
Concurrency and Scaling
The number of partitions directly impacts how many consumers can process messages in parallel. Within a consumer group, Kafka assigns each partition to exactly one consumer. Therefore, the maximum number of consumers that can actively process messages concurrently is limited by the number of partitions.
Configuring Partitions
Proper configuration of partitions is essential for optimal Kafka performance:
Number of Partitions
The number of partitions is configured when creating a topic using the --partitions parameter. This decision should be based on expected throughput, number of consumers, and desired parallelism.
bin/kafka-topics.sh --bootstrap-server <BOOTSTRAP_SERVERS> --create --topic <TOPIC_NAME> --partitions <NUMBER_OF_PARTITIONS>Increasing Partitions
While Kafka allows increasing the number of partitions over time, this should be done cautiously, especially when messages use keys. Changing the number of partitions can affect how keyed messages are distributed, potentially breaking ordering guarantees for messages with the same key.
To increase partitions for an existing topic:
bin/kafka-topics.sh --bootstrap-server <BOOTSTRAP_SERVERS> --alter --topic <TOPIC_NAME> --partitions <NEW_NUMBER_OF_PARTITIONS>Partition Replicas
Replication factor determines how many copies of each partition will exist across the cluster. This is specified using the --replication-factor parameter when creating a topic:
bin/kafka-topics.sh --bootstrap-server <BOOTSTRAP_SERVERS> --create --topic <TOPIC_NAME> --partitions <NUMBER_OF_PARTITIONS> --replication-factor <REPLICATION_FACTOR>A replication factor of 3 is commonly recommended as it provides a good balance between fault tolerance and resource utilization.
Partition Replication and Fault Tolerance
Replication is how Kafka ensures data durability and availability:
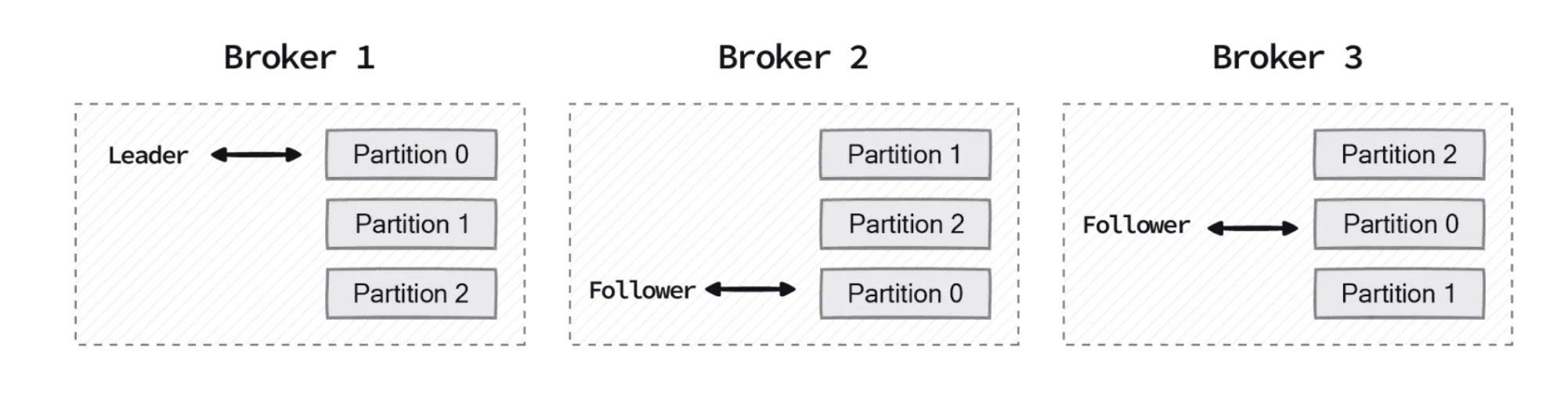
Leader and Follower Replicas
Each partition has one leader replica and zero or more follower replicas. The leader handles all read and write requests for the partition, while followers replicate the data. This model ensures that if the leader fails, one of the followers can be promoted to become the new leader without data loss.
In-Sync Replicas (ISRs)
An In-Sync Replica (ISR) is a broker that has the latest messages for a given partition. The leader is always an in-sync replica. Kafka tracks which replicas are in sync with the leader, and only in-sync replicas are eligible to become the new leader if the current leader fails.
Acknowledgment Modes
Producers can specify how many acknowledgments they require before considering a message successfully written:
-
acks=0: The producer doesn't wait for acknowledgment (higher throughput, lower durability) -
acks=1: The producer waits for acknowledgment from the leader only -
acks=all: The producer waits for acknowledgment from all in-sync replicas (highest durability)
Best Practices for Kafka Partitions
Implementing these best practices will help optimize your Kafka deployment:
Right-Size Your Partitions
As a general guideline, aim for approximately 100 partitions per broker for a balance of parallelism and resource efficiency. However, specific scenarios might require adjusting this number based on throughput requirements and available resources.
Choose Effective Partition Keys
Select partition keys that naturally distribute data evenly across partitions. Avoid keys that result in "hot partitions" where a small number of partitions receive a disproportionate amount of traffic.
Plan for Future Growth
It's better to over-partition slightly based on anticipated future throughput rather than under-partition and have to increase partitions later. This approach preserves message ordering for keyed messages as your system scales.
Balance Replication and Performance
A replication factor of 3 provides a good balance between fault tolerance and performance for most production environments. This allows you to lose up to 2 brokers without losing data.
Monitor Partition Health
Continuously monitor partition size, consumer lag, and throughput to identify potential issues proactively. Uneven partition sizes or high consumer lag can indicate problems with your partitioning strategy.
Avoid Too Many Partitions
While partitions enable parallelism, having too many partitions can increase memory usage and file handle count, as each partition requires its own resources. Each broker needs to maintain file handles for each partition segment it manages.
Conclusion
Kafka partitions are the cornerstone of what makes Apache Kafka a powerful distributed streaming platform. By properly understanding and configuring partitions, organizations can build highly scalable, resilient, and performant data streaming architectures that meet the demands of modern data-intensive applications.
The key to success with Kafka partitions lies in thoughtful planning: choosing the right number of partitions, implementing appropriate partitioning strategies, configuring replication for fault tolerance, and continuously monitoring system performance. With these foundations in place, Kafka can efficiently handle massive volumes of data while providing the reliability and scalability required for mission-critical applications.
Still struggling with skyrocketing Kafka bills and the "ops tax" of manual disk management? It's time to stop babysitting your clusters. Try AutoMQ Cloud for Free and experience how diskless architecture slashes costs and automates scaling—no credit card required. See how others made the switch in our case studies or explore the project on GitHub.


