Apache Kafka has become an essential component in modern data architectures, enabling real-time data streaming and processing at scale. At the heart of Kafka's publish-subscribe model lies the Kafka Producer, a critical client application responsible for publishing events to Kafka topics. This blog provides a thorough exploration of Kafka Producers, covering fundamental concepts, implementation examples, configuration options, advanced features, and best practices for optimal performance.
Fundamentals of Kafka Producers
A Kafka Producer is a client application that publishes (writes) events to a Kafka cluster. Unlike Kafka consumers that can be complex due to group coordination requirements, producers are conceptually simpler in their operation. The producer's primary responsibility is to take application data, serialize it into a byte format suitable for transmission, and deliver it to appropriate partitions within Kafka topics.
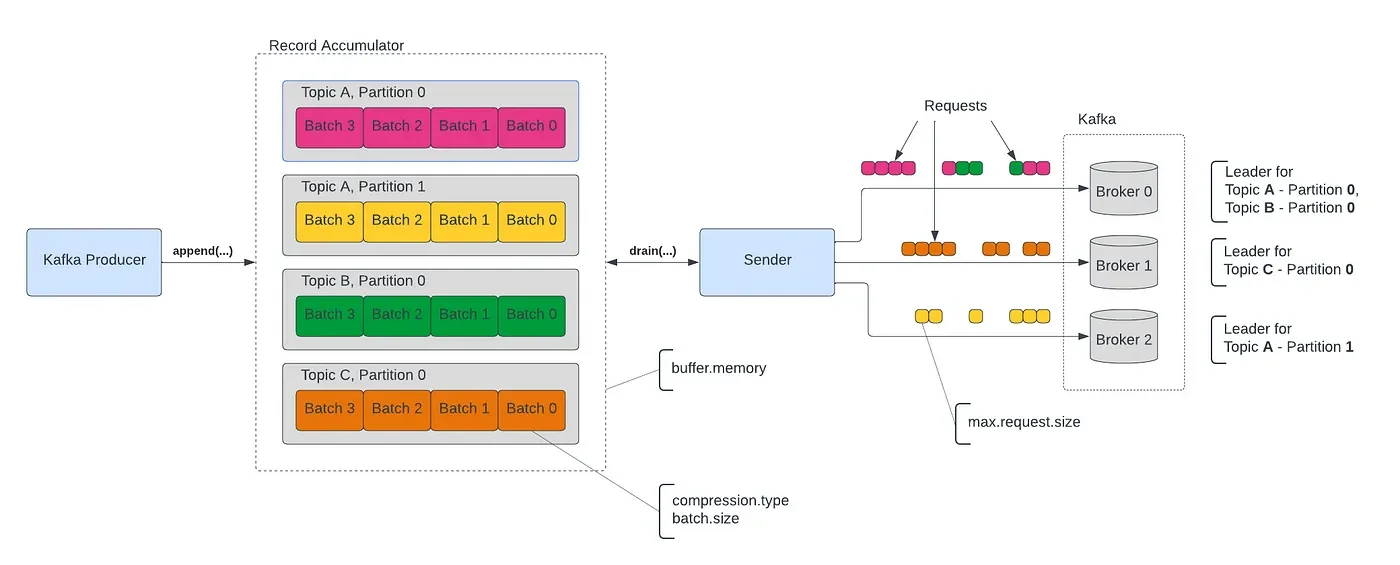
The Kafka producer architecture includes several key components working together to efficiently deliver messages. When an application sends a message using a producer, the message follows a specific path through these components before reaching the Kafka cluster. First, the producer needs to determine which partition should receive the message. This is handled by a partitioner component that maps each message to a specific topic partition. The default partitioning strategy ensures that all messages with the same non-empty key will be sent to the same partition, maintaining ordering for messages sharing a key. If a key is not provided, partition assignment happens with awareness of batching to optimize throughput.
Producers initially connect to bootstrap servers (a subset of Kafka brokers) to discover the complete list of broker addresses and the current leaders for each topic partition. This discovery process occurs through a MetadataRequest sent to the broker. After obtaining this metadata, producers send messages directly to the leader broker for the relevant topic partition using Kafka's proprietary protocol with TCP as the transport mechanism. This design enables message processing to scale efficiently while maintaining message order within each partition.
The Kafka client producer API is thread-safe, with a pool of buffers that hold messages waiting to be sent. Background I/O threads handle the conversion of records into request bytes and transmit these requests to the Kafka cluster. It's important to note that producers must be properly closed to prevent leaking resources such as connections, thread pools, and buffers.
Basic Producer Configuration and Implementation
Creating a Kafka producer requires configuring several key properties. At minimum, a producer needs bootstrap server addresses and serializers for both keys and values. Let's examine a basic Java implementation:
`javaimport org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties;
public class SimpleProducer { public static void main(String[] args) { Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
producer.send(new ProducerRecord<>("my-topic", "key", "Hello world!"));
producer.close();
}}`
In this example, three essential configurations are defined. First, the "bootstrap.servers" property tells the producer where to find the Kafka broker. Second, the key and value serializers convert the key and value objects to bytes so they can be transmitted over the network. The producer creates and sends a ProducerRecord containing the topic name, message key, and message value before properly closing the producer to release resources.
When creating a producer, it's also good practice to add a "client.id" property, which enables easier correlation of requests on the broker with the client instance that made them. This correlation aids in debugging and can be used to enforce client quotas.
The producer's send method is asynchronous by default, returning immediately after adding the record to an output buffer and before the actual transmission occurs. The buffer is used for batching records to improve I/O efficiency and compression. For synchronous behavior, applications can call the get() method on the Future returned by the send method, which will block until the message is sent and acknowledged by the broker.
Message Durability and Reliability
Kafka producers offer configurable guarantees for message durability through the "acks" setting. This setting controls how many brokers must acknowledge receipt of a message before the producer considers it sent. There are three possible values:
The "acks=all" setting provides the strongest durability guarantee, requiring all in-sync replicas to acknowledge receipt of the message. This ensures the message won't be lost as long as at least one replica remains available, but it also results in higher latency.
With "acks=1" (the default in versions prior to Kafka 3.0), only the partition leader must acknowledge receipt of the message. This offers a balance between durability and performance.
Setting "acks=0" maximizes throughput as the producer doesn't wait for any acknowledgment. However, this provides no guarantee that the message was successfully written to the broker's log and means the producer won't be able to determine the offset of the message.
Producer reliability can be further enhanced through the "enable.idempotence" configuration. An idempotent producer ensures records are delivered exactly once and in order per partition for the lifetime of the producer instance. When enabled, each producer is assigned a unique Producer ID (PID), and each message receives a monotonically increasing sequence number. The broker tracks the PID and sequence number combination for each partition, rejecting any duplicate write requests it receives.
As of Kafka 3.0, idempotence is enabled by default with "acks=all". For earlier versions, it's generally recommended to enable this feature explicitly to prevent duplicate messages in case of producer retries. The idempotent producer solves a real problem of message reordering or duplication in the log, which previously required limiting the number of in-flight requests to one per connection, thereby severely limiting throughput.
Advanced Producer Features and Optimization
Beyond basic configuration, Kafka producers offer several advanced features that can significantly improve performance and reliability.
Batch Processing for Improved Throughput
Batching multiple messages together before sending them to Kafka brokers is a key optimization technique. By default, the "batch.size" is 16KB, and the "linger.ms" is 0, meaning the producer sends each message individually as soon as it's ready. By increasing these values, you can significantly improve throughput at the cost of slightly increased latency.
The batch size setting determines the maximum number of messages the producer sends in a single request. A larger batch size reduces the number of network round trips required, enhancing overall throughput. The "linger.ms" setting controls how long the producer waits before sending a batch, even if it's not full. Setting a small non-zero value (e.g., 5-10ms) allows more messages to accumulate, reducing network overhead without introducing substantial latency.
For example, the following configuration would instruct the producer to gather messages for up to 10ms before sending, with a maximum batch size of 64KB:
javaprops.put\("batch.size", 65536); props.put\("linger.ms", 10);
This configuration can dramatically improve throughput for applications that produce many small messages, especially when the producer and broker are separated by higher network latency3.
Message Compression
Compressing messages before sending them can significantly reduce network bandwidth consumption and disk storage requirements. Kafka supports several compression algorithms, including "gzip," "snappy," and "lz4". Compression is activated by setting the "compression.type" configuration property.
Each compression algorithm offers different tradeoffs between compression ratio, CPU usage, and speed. Generally, "lz4" provides the best balance of compression speed and efficiency, while "gzip" offers better compression ratios at the cost of higher CPU utilization. In many cases, enabling compression can improve overall throughput even with the additional CPU overhead, especially for larger messages or when network bandwidth is limited.
The following configuration enables lz4 compression:
javaprops.put\("compression.type", "lz4");
Compression is particularly effective when combined with batching, as compressing multiple messages together typically achieves better compression ratios than compressing individual messages3.
Buffer Management
The Kafka producer uses a buffer to store unsent messages. The "buffer.memory" configuration (default 33MB) determines the total bytes of memory the producer can use to buffer messages. If the producer sends messages faster than they can be transmitted to the server, this buffer will eventually fill up. When this happens, the send() method will either block or throw an exception, depending on the "max.block.ms" setting.
For high-throughput applications, you might need to increase the buffer size, but be aware that this increases the memory footprint of the producer application. Additionally, if you increase the buffer size, you may need to adjust the "max.block.ms" setting to prevent messages from staying in the buffer too long and potentially expiring.
Error Handling Strategies
Handling errors effectively is critical for building reliable Kafka producer applications. The Kafka producer API provides several mechanisms for error handling.
When sending messages asynchronously, you can provide a callback that will be invoked when the send completes, allowing you to handle success or failure conditions. For example:
javaproducer.send(record, (metadata, exception) -> {
if (exception != null) {
// Handle the error
log.error("Failed to send message", exception);
} else {
// Message successfully sent
log.info("Message sent to partition {} at offset {}",
metadata.partition(), metadata.offset());
}
});For synchronous sends, exceptions will be thrown directly, which can be caught using standard try-catch blocks. Common errors include network issues, broker unavailability, and message size violations.
In applications that need to ensure message delivery even when the Kafka cluster is temporarily unavailable, implementing a store-and-forward pattern can be helpful. This involves storing messages locally when Kafka is unavailable and retrying the send later. However, designing such a system requires careful consideration of ordering guarantees and potential duplicates.
In Spring applications, the KafkaListenerErrorHandler interface provides a mechanism for handling errors that occur during message consumption. This can be particularly useful in request-reply scenarios where you might want to send a failure result to the sender after some number of retries.
Best Practices for Kafka Producers
Based on the search results and industry knowledge, here are key best practices for working with Kafka producers:
Optimize for Your Use Case
Configure your producer based on your specific requirements for latency, throughput, and reliability. If you need maximum throughput, consider using compression, larger batch sizes, and non-zero linger times. If minimum latency is crucial, you might use smaller batches and zero linger time, sacrificing some throughput.
For critical data where losing messages is unacceptable, configure "acks=all" and enable idempotence. For less critical data where maximum throughput is the priority, consider "acks=1" or even "acks=0".
Message Size Considerations
While Kafka can handle large messages, performance is typically better with smaller messages (ideally under 1MB). For larger objects, consider storing the data externally (such as in a database or object store) and sending only a reference in the Kafka message.
If large messages are unavoidable, ensure that the "max.request.size" on the producer and "message.max.bytes" on the broker are configured appropriately. Keep in mind that very large messages can impact partitioning, replication, and consumer performance.
Proper Error Handling
Implement comprehensive error handling in your producer code. For critical applications, consider implementing retry logic with exponential backoff for transient failures. Monitor and log producer metrics to identify issues before they become critical.
For applications where message delivery must be guaranteed, consider implementing a two-phase commit pattern or using Kafka's transactional API, which provides exactly-once semantics across multiple partitions.
Production Deployment Considerations
In production environments, carefully monitor your Kafka producers using available metrics. Key metrics to track include message send rate, average batch size, and error rates. These metrics can help identify configuration issues or performance bottlenecks.
When deploying in Docker or Kubernetes environments, ensure that resource limits are set appropriately to avoid memory pressure or CPU starvation, which can impact producer performance.
Implement circuit breakers for your producers to handle scenarios where Kafka brokers become unavailable. This prevents cascading failures and allows your application to degrade gracefully during outages.
Learning Resources for Kafka Producers
For those looking to deepen their understanding of Kafka producers, several excellent resources are available:
The Apache Kafka Fundamentals playlist on YouTube provides a digestible way to understand basic Kafka concepts, including producers. Of particular interest is module three, which covers Kafka fundamentals, and module four, which explains how Kafka works with code overviews for basic producers and consumers.
The Apache Kafka 101 course includes a module titled "Your First Kafka Application in 10 Minutes or Less," demonstrating how to create a basic Kafka application quickly. This course is available on Confluent Developer and covers important concepts including topics, partitioning, brokers, producers, and consumers.
For those who prefer hands-on learning, several GitHub repositories provide comprehensive examples of Kafka producers in various languages. These include kafka-producer-example, spring-boot-kafka-producer-example, and the official Kafka examples repository.
Does AutoMQ support Kafka Producers?
AutoMQ is a next-generation Kafka that is 100% fully compatible and built on top of S3. Thanks to AutoMQ's complete Kafka compatibility, when you need to write data to AutoMQ, you can directly use Kafka Clients in various programming languages to write Kafka Producer code.
Check out the article: How AutoMQ makes Apache Kafka 100% protocol compatible? to understand how AutoMQ achieves 100% complete compatibility with Kafka.
Conclusion
Kafka producers form a critical component in the Apache Kafka ecosystem, enabling applications to publish data to Kafka topics reliably and efficiently. By understanding producer architecture, configuration options, and best practices, developers can build robust and high-performance data streaming solutions.
The configuration and optimization of Kafka producers should be approached thoughtfully, balancing requirements for throughput, latency, and reliability. Key considerations include batching strategy, compression, acknowledgment levels, and error handling approaches. By leveraging the advanced features of Kafka producers and following established best practices, organizations can build data streaming applications that scale effectively and operate reliably even under challenging conditions.
As Kafka continues to evolve, producer capabilities and best practices will also advance. The shift toward default idempotent producers in recent versions reflects the community's emphasis on reliability and exactly-once semantics. Staying informed about these developments through the learning resources mentioned in this report will help ensure your Kafka implementations remain current and effective.


