Rebalancing is a critical process in Apache Kafka that ensures efficient and balanced processing of data across consumer instances. Understanding this mechanism is essential for optimizing performance and maintaining system stability in Kafka deployments. This comprehensive examination explores the intricacies of Kafka rebalancing, from fundamental concepts to advanced configurations and best practices, providing insights for both newcomers and experienced practitioners alike.
Understanding Kafka Rebalancing
Kafka rebalancing is the process by which Kafka redistributes partitions across consumers to ensure that each consumer is processing an approximately equal number of partitions. This fundamental mechanism allows for even data processing distribution, preventing any single consumer from becoming overloaded while others remain underutilized. The rebalancing process is central to Kafka's ability to scale efficiently and handle changes in consumer group topology without manual intervention.
Rebalancing occurs within the context of consumer groups, which are logical groupings of consumers that collaborate to process data from Kafka topics. Each partition within a topic can only be assigned to exactly one consumer within a specific consumer group at any given time. This constraint ensures that message ordering is maintained within partitions while allowing parallel processing across multiple consumers.
The group coordinator, a role assigned to one of the Kafka brokers, orchestrates the rebalancing process. When a rebalance is triggered, the coordinator manages the redistribution of partitions, notifying consumers of their new assignments and ensuring a smooth transition from the old assignment to the new one. This coordination is crucial for maintaining data processing continuity and preventing duplicates or gaps in consumption.
Rebalancing Triggers
Several events can trigger a rebalance in Kafka consumer groups. Understanding these triggers is essential for anticipating and managing rebalances effectively:
- Membership changes occur when a consumer joins or leaves the consumer group. This can happen during normal operations (such as scaling up or down), or unexpectedly (such as consumer failures or network issues).
-
Topic changes, including adding new partitions to existing topics or creating new topics that match subscription patterns, can initiate rebalancing to incorporate these new resources into the assignment.
-
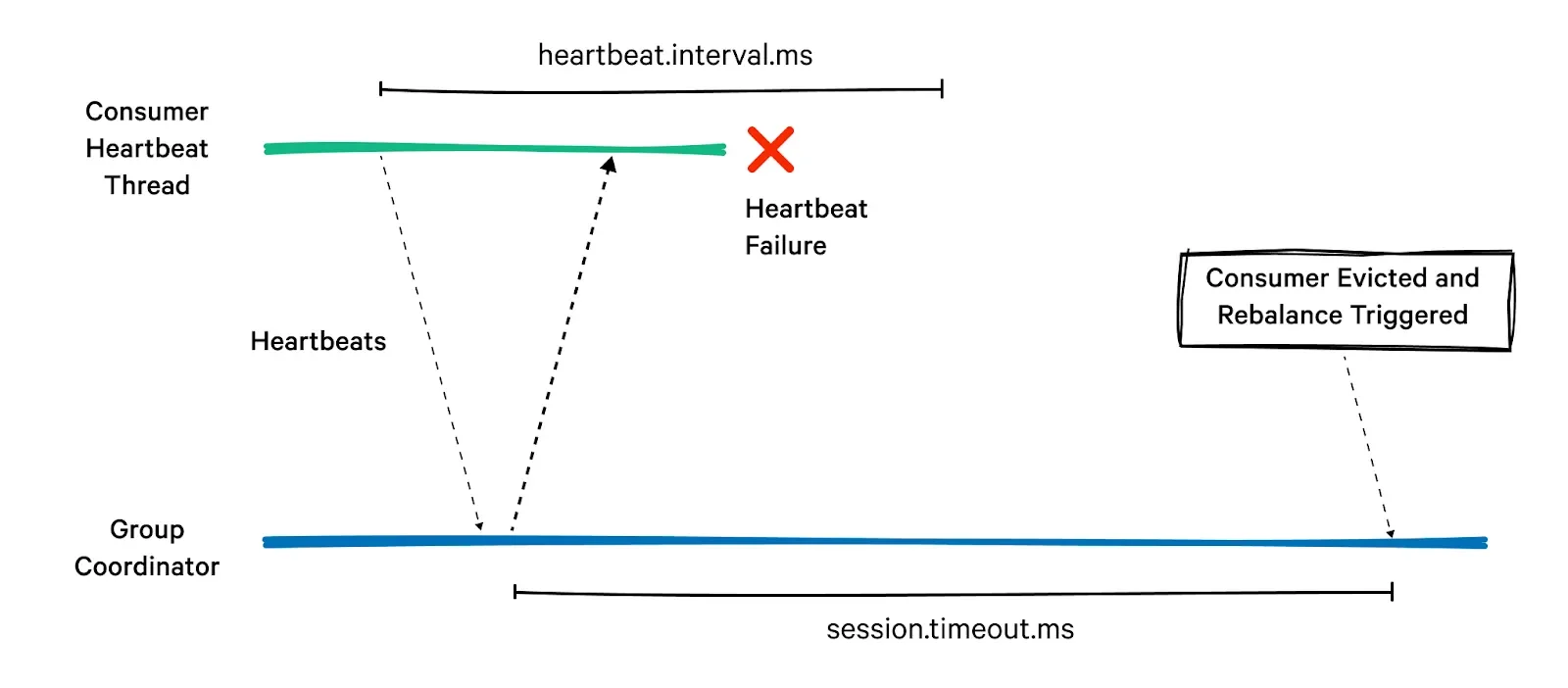
Session timeouts happen when a consumer fails to send heartbeats to the coordinator within the configured timeout period. The coordinator marks the consumer as dead and triggers a rebalance to reassign its partitions.
-
Max poll exceedance occurs when a consumer takes too long to process records between poll calls, exceeding the
max.poll.interval.mssetting. This is interpreted as a consumer failure, triggering a rebalance. -
Coordinator failover can trigger rebalances if the broker serving as the group coordinator fails and another broker takes over this responsibility.
Each of these triggers represents a change in the consumer group's state that necessitates a redistribution of partitions to maintain balanced processing across all active consumers.
Rebalancing Mechanisms and Protocols
The rebalancing process has evolved significantly over Kafka's development, with newer protocols designed to address limitations in earlier implementations. Understanding these protocols helps in selecting the most appropriate approach for specific use cases.
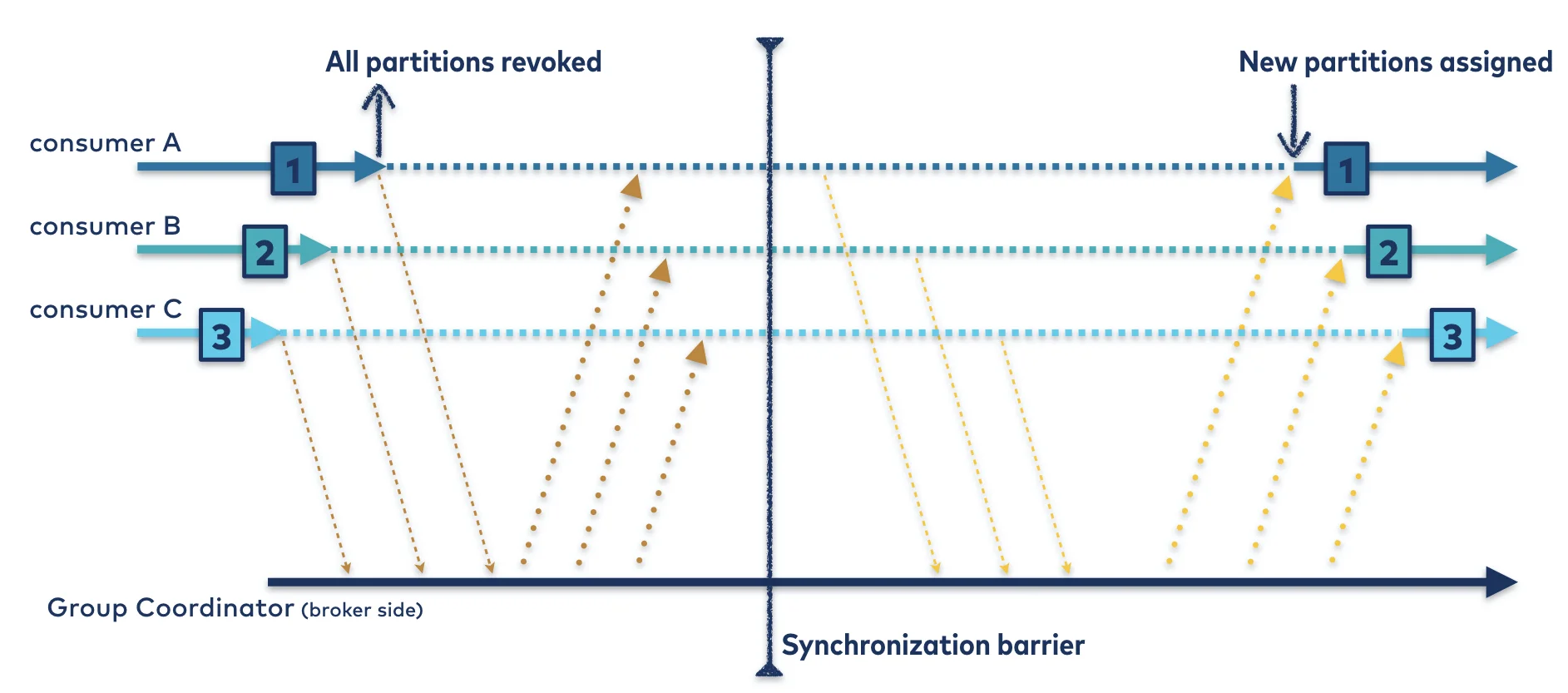
Eager (Traditional) Rebalancing
In the traditional eager rebalancing protocol, all consumers in a group stop consuming data during a rebalance, commonly referred to as the "stop the world" effect. The process follows these steps:
-
The coordinator sends a rebalance notification to all group members.
-
All consumers respond with a JoinGroup request, temporarily stopping consumption.
-
The group leader (selected by the coordinator) computes a new partition assignment.
-
The coordinator distributes the new assignment to all members.
-
Consumers resume consumption with their new partition assignments.
This approach ensures consistency but causes significant disruption to data processing, especially in large consumer groups or during frequent rebalances.
Incremental Cooperative Rebalancing
Introduced in Kafka 2.4, the incremental cooperative rebalancing protocol significantly reduces the disruption caused by rebalances:
-
Instead of revoking all partitions, consumers only surrender specific partitions required for rebalancing.
-
Consumers continue processing data from unaffected partitions during the rebalance.
-
Rebalancing occurs in multiple rounds, with each round affecting only a subset of partitions.
-
The protocol allows consumers to negotiate partition assignments based on their current state and capacity.
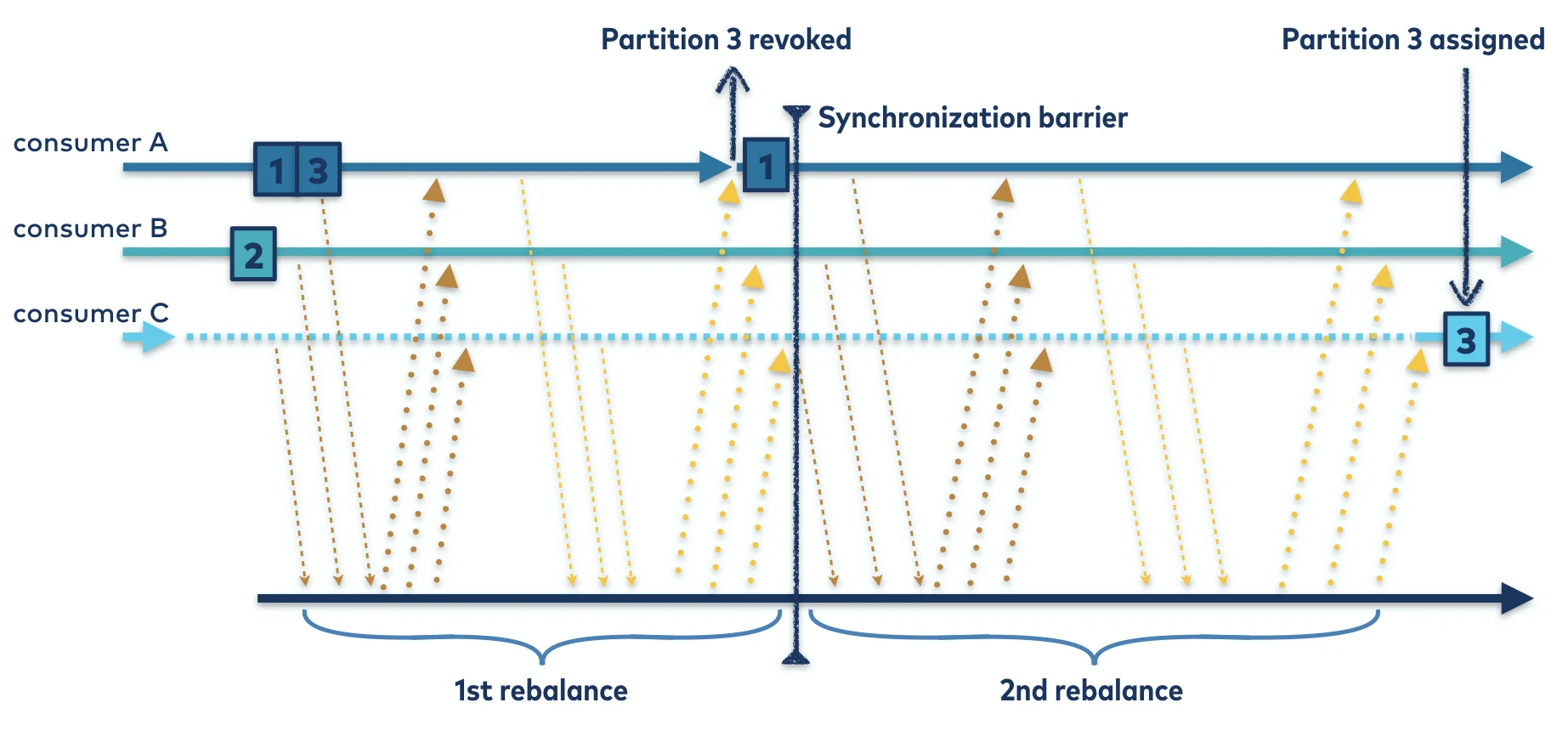
This approach minimizes processing interruptions and provides more fine-grained control over the rebalancing process. In testing with large clusters, cooperative rebalancing has shown significant improvements in throughput and reduced lag during rebalancing events compared to eager rebalancing.
Partition Assignment Strategies
Kafka provides several partition assignment strategies that determine how partitions are distributed among consumers during a rebalance:
RangeAssignor (Default in older versions)
The RangeAssignor strategy assigns partitions to consumers on a per-topic basis. For each topic, it divides the partitions numerically and assigns each range to a consumer. This can lead to uneven distribution when consumers subscribe to multiple topics.
RoundRobinAssignor
This strategy assigns partitions to consumers in a round-robin fashion, attempting to achieve a more balanced distribution than the range-based approach. It's particularly useful when consumers subscribe to multiple topics with varying partition counts.
StickyAssignor
Introduced to improve upon the RoundRobinAssignor, the StickyAssignor attempts to maintain existing assignments as much as possible during rebalances. It aims to minimize partition movement while ensuring balanced assignments, reducing the impact of rebalances.
CooperativeStickyAssignor
This strategy combines the benefits of sticky assignment with the cooperative rebalancing protocol. It maintains existing assignments where possible while supporting incremental rebalancing, providing the least disruptive approach to partition reassignment.
Configuration Parameters for Effective Rebalancing
Properly configuring Kafka clients is crucial for optimizing the rebalancing process. The following parameters significantly impact rebalancing behavior:
Session and Heartbeat Configuration
The session.timeout.ms parameter defines the maximum time a consumer can be inactive before being considered failed. Larger values reduce sensitivity to temporary issues but increase detection time for actual failures. This parameter is typically set between 10-30 seconds, depending on network reliability and processing characteristics.
The heartbeat.interval.ms controls how frequently consumers send heartbeats to the coordinator. It should be set to approximately one-third of the session timeout to ensure timely detection of consumer failures while avoiding excessive heartbeat traffic. Typical values range from 1-3 seconds.
Poll and Processing Configuration
The max.poll.interval.ms parameter sets the maximum time between consecutive poll calls before a consumer is considered failed. This is particularly important for applications with variable processing times. Setting this value too low can cause unnecessary rebalances, while setting it too high delays detection of stuck consumers.
The max.poll.records configuration limits the number of records returned in a single poll call, helping to ensure that processing completes within the maximum poll interval. This is crucial for preventing rebalances due to processing delays.
Partition Assignment Strategy Configuration
The partition.assignment.strategy parameter specifies which assignment algorithm to use during rebalances. Setting this to org.apache.kafka.clients.consumer.CooperativeStickyAssignor enables cooperative rebalancing with sticky assignments, minimizing disruption during rebalances:
textprops.put\(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, Collections.singletonList\(CooperativeStickyAssignor.class));
Static Membership Configuration
The group.instance.id parameter enables static membership, allowing consumers to rejoin a group with the same identity after restarts. This prevents unnecessary rebalances during planned restarts or brief network issues:
textprops.put\(ConsumerConfig.GROUP_INSTANCE_ID_CONFIG, "consumer-instance-1");
Static membership is particularly valuable in containerized environments where consumers may be frequently restarted.
Common Rebalancing Issues and Solutions
Despite careful configuration, Kafka users often encounter rebalancing challenges. Understanding these issues and their solutions is essential for maintaining healthy Kafka deployments.
Rebalance Storms
Rebalance storms occur when consecutive rebalances are triggered before previous rebalances complete, creating a cycle of continuous rebalancing. This often happens in large consumer groups or when consumers are unstable.
Solution : Implement backoff mechanisms for consumer restarts, ensure stable consumer deployments, use static membership IDs, and employ cooperative rebalancing to reduce the impact of individual rebalances.
Long Rebalance Times
Long rebalance times, sometimes extending to 20-50 minutes, can severely impact system performance, especially in environments with many topics and partitions.
Solution : Reduce the number of partitions per consumer group, ensure brokers have adequate resources, optimize consumer configurations, and use cooperative rebalancing to reduce the scope of each rebalance.
Timeout Errors During Rebalancing
Network latency or misconfigured timeout parameters often cause timeout errors during rebalancing, preventing successful completion of the process.
Solution : Adjust timeout parameters to accommodate network conditions, ensure sufficient bandwidth between consumers and brokers, and monitor network performance regularly.
Uneven Partition Distribution
After rebalancing, partitions may be unevenly distributed among consumers, leading to processing bottlenecks and reduced parallelism.
Solution : Use appropriate assignment strategies (StickyAssignor or CooperativeStickyAssignor), ensure consistent topic subscription across consumers, and monitor partition assignments after rebalances.
Best Practices for Managing Rebalancing
Implementing these best practices can significantly improve rebalancing performance and reduce its impact on system operations:
Upgrade to Modern Kafka Versions
Newer Kafka versions (2.4+) include significant improvements to rebalancing protocols. Upgrading to these versions enables cooperative rebalancing and other optimizations that reduce rebalancing disruption.
Optimize Consumer Configurations
Fine-tune consumer configurations to balance rapid failure detection with rebalance stability:
-
Set
session.timeout.mshigh enough to tolerate normal processing variations -
Configure
heartbeat.interval.msto approximately one-third of the session timeout -
Adjust
max.poll.interval.msbased on actual record processing times -
Use
max.poll.recordsto limit batch sizes for predictable processing times
Implement Strategic Scaling
When scaling consumer groups, implement strategies that minimize rebalancing disruption:
-
Scale gradually rather than adding many consumers simultaneously
-
Schedule scaling during periods of lower traffic when possible
-
Use lag-based autoscaling rather than CPU/memory-based scaling to prevent unnecessary rebalances
-
In Kubernetes environments, consider using KEDA with the incremental cooperative rebalance protocol for smoother scaling
Monitor Rebalancing Events
Implement comprehensive monitoring of rebalancing events to detect and address issues promptly:
-
Set up alerts for frequent or long-duration rebalances
-
Monitor consumer lag before and after rebalances
-
Track partition assignments to identify uneven distributions
-
Use Kafka's built-in metrics to monitor coordinator and consumer health
Partition Planning
Thoughtful partition planning can significantly reduce rebalancing challenges:
-
Size partitions appropriately based on expected throughput
-
Avoid creating excessive numbers of partitions per topic
-
Consider future scaling needs when determining partition counts
-
Remember that increasing partitions later causes rebalancing and may affect message ordering
Advanced Rebalancing Techniques
For organizations with complex Kafka deployments, these advanced techniques can provide additional benefits:
Enforced Rebalancing
Introduced in recent Kafka versions, enforced rebalancing allows administrators to trigger a rebalance programmatically. This can be useful for pre-emptively rebalancing during maintenance windows or resolving known partition assignment issues:
javaKafkaMessageListenerContainer container = ... container.enforceRebalance();The rebalance occurs during the next poll operation, allowing for controlled timing of the process.
Static Group Membership
Static group membership assigns permanent identities to consumers, allowing them to rejoin a group with the same partition assignments after temporary failures. This reduces unnecessary rebalances and partition movement, particularly in containerized environments with frequent restarts.
Custom Partition Assignment Strategies
For specialized use cases, Kafka allows implementation of custom partition assignment strategies by extending the AbstractPartitionAssignor class. Custom strategies can incorporate application-specific knowledge, such as consumer capacity differences or data locality considerations.
Conclusion
Kafka rebalancing is a fundamental process that ensures balanced data processing across consumer instances. While it introduces potential disruptions, proper understanding and configuration can minimize these impacts significantly. By implementing the appropriate rebalancing protocols, optimizing configuration parameters, following best practices, and utilizing advanced techniques when necessary, organizations can achieve reliable and efficient Kafka deployments even at substantial scale.
The evolution of Kafka's rebalancing mechanisms, from eager to cooperative approaches, demonstrates the community's focus on improving this critical aspect of distributed data processing. As Kafka continues to evolve, we can expect further refinements to these mechanisms, making rebalancing less disruptive and more efficient.
For organizations building mission-critical systems with Kafka, investing time in understanding and optimizing rebalancing behavior will yield significant returns in system reliability, performance, and operational simplicity.
Still struggling with skyrocketing Kafka bills and the "ops tax" of manual disk management? It's time to stop babysitting your clusters. Try AutoMQ Cloud for Free and experience how diskless architecture slashes costs and automates scaling—no credit card required. See how others made the switch in our case studies or explore the project on GitHub.


