Kafka retention policies dictate how long data remains stored within topics before being eligible for deletion. Properly configured retention is crucial for balancing storage efficiency, system performance, and data availability. This comprehensive exploration of Kafka retention policies covers core concepts, implementation mechanics, configuration parameters, and industry best practices to help optimize your Kafka deployment.

Understanding Kafka's Storage Architecture
At its core, Apache Kafka functions as an append-only distributed commit log system, with data organized hierarchically through topics, partitions, and segments. This architecture forms the foundation for Kafka's retention implementation.
Log Structure Fundamentals
Kafka organizes data in a tiered structure, starting with topics that contain one or more partitions. Each partition represents an ordered, immutable sequence of records that is continuously appended to, creating what's known as a commit log. For storage efficiency and performance optimization, partitions are further divided into segments, which are the actual files stored on disk.
Each segment consists of several components:
-
Log file (.log) : Contains the actual message records
-
Index file (.index) : Maps message offsets to physical positions within the log file
-
Timeindex file (.timeindex) : Maps timestamps to message offsets for time-based lookups
This segmentation approach significantly enhances Kafka's performance by enabling efficient access to specific data points without reading entire partitions. It also facilitates more granular data retention management, as Kafka can remove entire segments rather than individual messages.
Retention Policies in Kafka
Kafka implements retention through three primary mechanisms: time-based retention, size-based retention and key-based retention. These can be used independently or in combination to create customized data lifecycle management strategies.
Time-based Retention
Time-based retention is the most commonly used approach, where messages are retained for a specified period before becoming eligible for deletion. By default, Kafka retains messages for 7 days (168 hours), though this can be modified based on business requirements.
When a message's age exceeds the configured retention period, the entire segment containing that message becomes eligible for deletion—but only if all messages within that segment have also exceeded the retention threshold. This segment-level deletion mechanism is more efficient than removing individual messages.
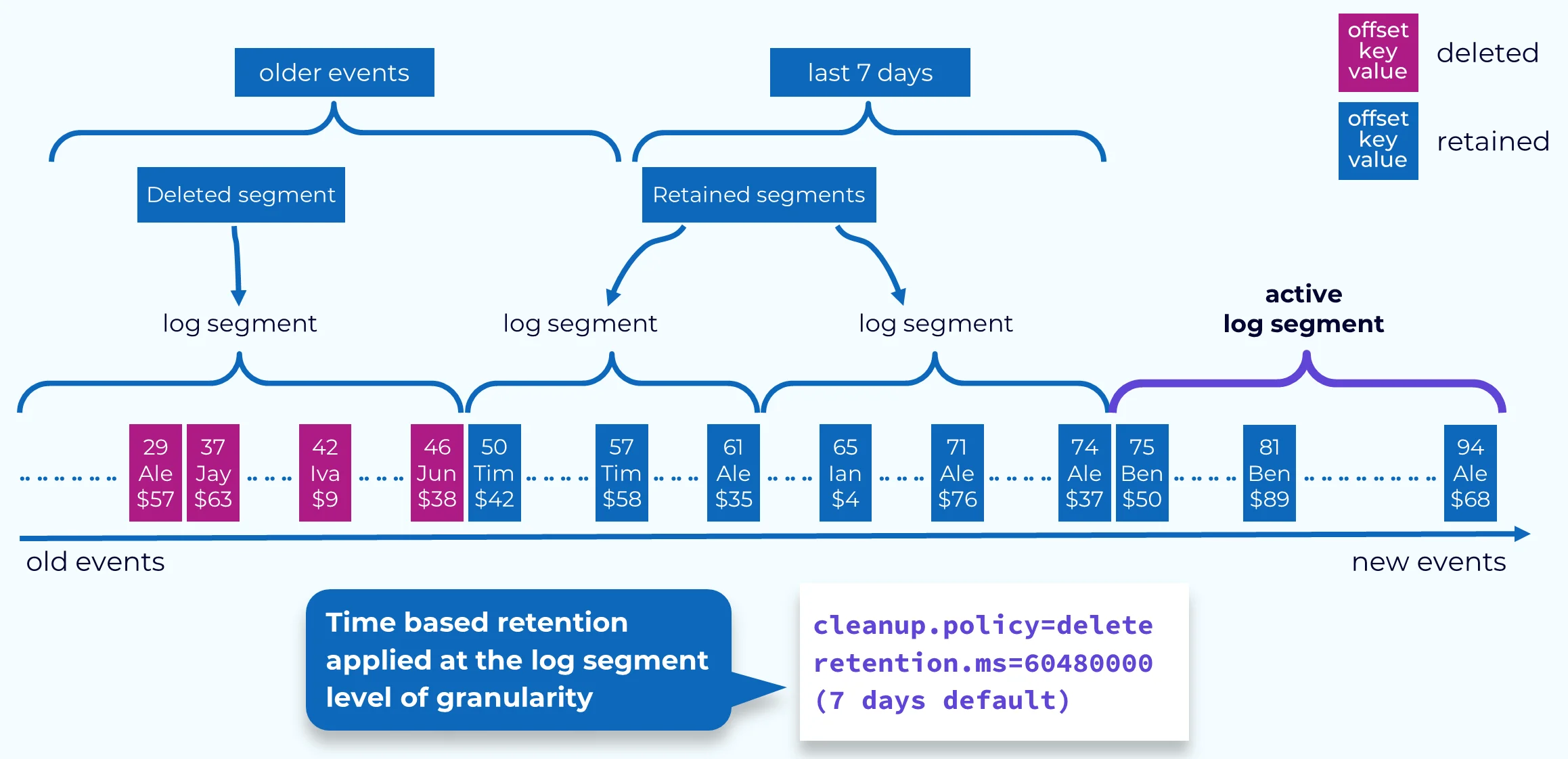
Size-based Retention
Size-based retention limits the amount of data stored per partition, ensuring that storage usage remains within defined bounds. When a partition reaches its configured size limit, Kafka begins removing the oldest segments to maintain compliance with the size threshold.
This approach is particularly valuable in environments with limited storage capacity or in scenarios where the volume of incoming data is highly variable.
Key-based Retention (Log Compaction)
Key-based retention, commonly referred to as log compaction, provides a finer-grained approach to data management by retaining only the most recent value for each message key. Unlike time-based or size-based retention that removes data based on age or volume, log compaction selectively preserves the latest state of each unique key while discarding outdated values for the same key.
When log compaction runs, Kafka scans the partition and creates a map of keys with their highest offset values. It then purges older messages with the same keys, ensuring that only the latest state for each key remains in the log. This process occurs at the partition level, maintaining data integrity while optimizing storage usage.
This retention mechanism is particularly beneficial for stateful applications, change data capture scenarios, and systems where the current state of data is more valuable than its complete history.
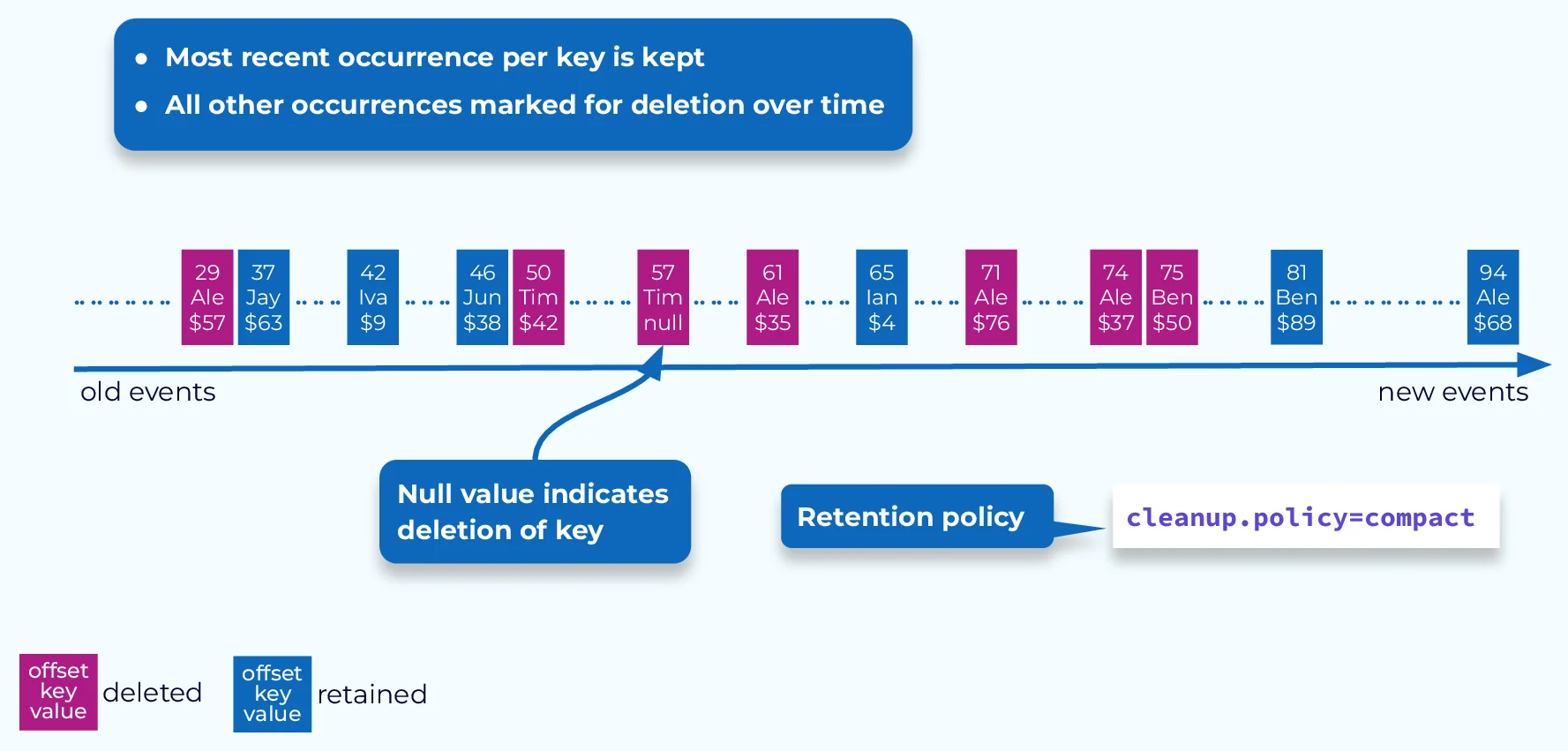
Cleanup Policies
Kafka offers two cleanup policies that define how data is managed once it exceeds retention thresholds:
-
Delete Policy (default): Removes entire segments when they exceed the configured retention limits, either by time or size.
-
Compact Policy : Retains only the most recent value for each unique message key, discarding older values with the same key. This approach is ideal for maintaining the latest state of key-value pairs without storing their complete history.
-
Combined Policy : Both delete and compact can be implemented simultaneously by specifying "delete,compact" as the cleanup policy. In this configuration, segments are first compacted to retain the latest values for each key, then the delete policy is applied based on retention settings.
Segment Management
Segment management plays a vital role in Kafka's retention implementation. Kafka designates one segment per partition as the "active segment," where all new messages are written. Once a segment reaches a certain size or age, it is closed, and a new active segment is created.
The segmentation process directly impacts retention behavior, as Kafka can only delete closed (inactive) segments. The active segment remains untouched by cleanup processes, regardless of retention settings.
Configuration Parameters
Kafka provides numerous configuration parameters to customize retention behavior at both the broker and topic levels.
Core Retention Parameters
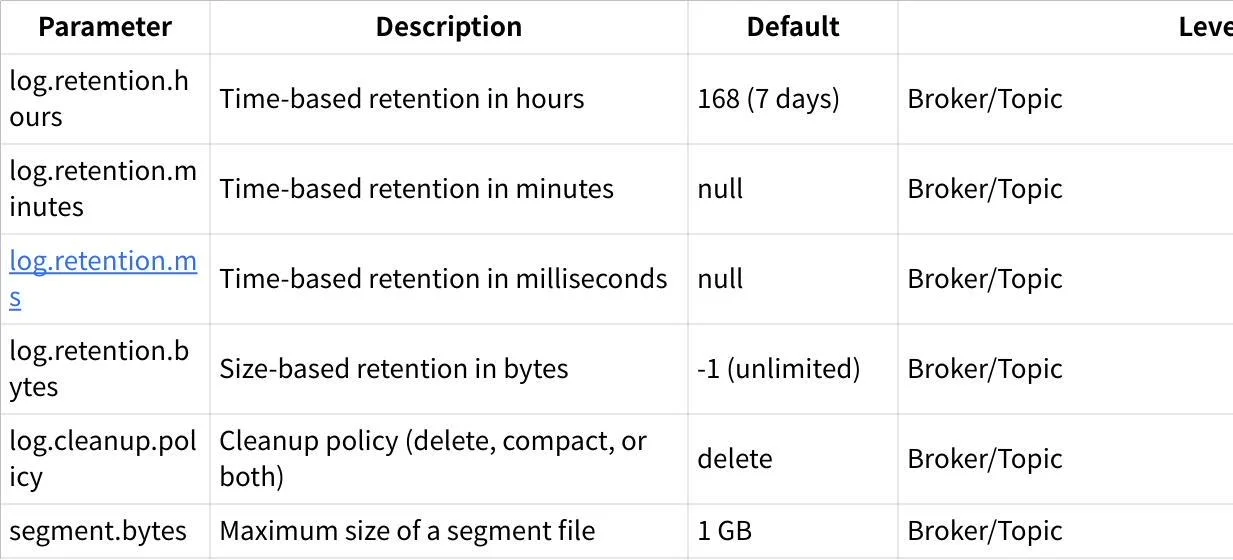
When multiple time-based parameters are specified, Kafka prioritizes the most granular unit (ms > minutes > hours). For example, if both log.retention.hours and log.retention.ms are set, the log.retention.ms value takes precedence.
Advanced Configuration Parameters

These parameters provide finer control over retention behavior, especially for advanced scenarios like tiered storage or log compaction.
Implementing Retention Policies
Retention policies can be implemented at both the broker level (affecting all topics by default) and at the individual topic level (overriding broker defaults).
Broker-level Configuration
Broker-level configurations are specified in the server.properties file and serve as default values for all topics:
`text# Time-based retention (7 days) log.retention.hours=168
log.retention.bytes=-1
log.cleanup.policy=delete`
Topic-level Configuration
Topic-level configurations override broker defaults and can be specified during topic creation or modified later:
`text# Create a topic with 1-hour retention kafka-topics.sh --bootstrap-server localhost:9092 \ --create --topic fast-data-topic \ --partitions 3 --replication-factor 2 \ --config retention.ms=3600000
kafka-configs.sh --bootstrap-server localhost:9092 \ --entity-type topics --entity-name existing-topic \ --alter --add-config retention.ms=259200000`
This flexibility allows administrators to implement different retention strategies for different data types within the same Kafka cluster.
Best Practices for Kafka Retention
Implementing effective retention policies requires careful consideration of several factors, including storage capacity, data value over time, consumer patterns, and compliance requirements.
Storage Optimization
-
Match retention to data lifecycle : Analyze how long data remains valuable to your consumers and align retention policies accordingly.
-
Implement tiered retention : Consider using different retention periods for different topics based on their importance and usage patterns.
-
Monitor disk usage : Regularly monitor broker disk usage and adjust retention settings proactively to prevent storage-related failures.
-
Consider compression : Implement message compression to reduce storage requirements while maintaining longer retention periods.
Performance Considerations
-
Segment sizing : Optimize segment.bytes configuration based on message size and access patterns. Smaller segments enable more granular cleanup but increase the number of files.
-
Balanced cleanup scheduling : Configure log.retention.check.interval.ms appropriately to balance cleanup frequency against broker load.
-
Resource allocation : Ensure sufficient CPU and I/O capacity for log cleanup operations, especially on clusters with high throughput or aggressive retention policies.
-
Consumer offset retention : Configure offsets.retention.minutes carefully (default: 7 days) to ensure consumer groups can resume from their last position after reasonable downtime periods.
Use Case-Specific Recommendations
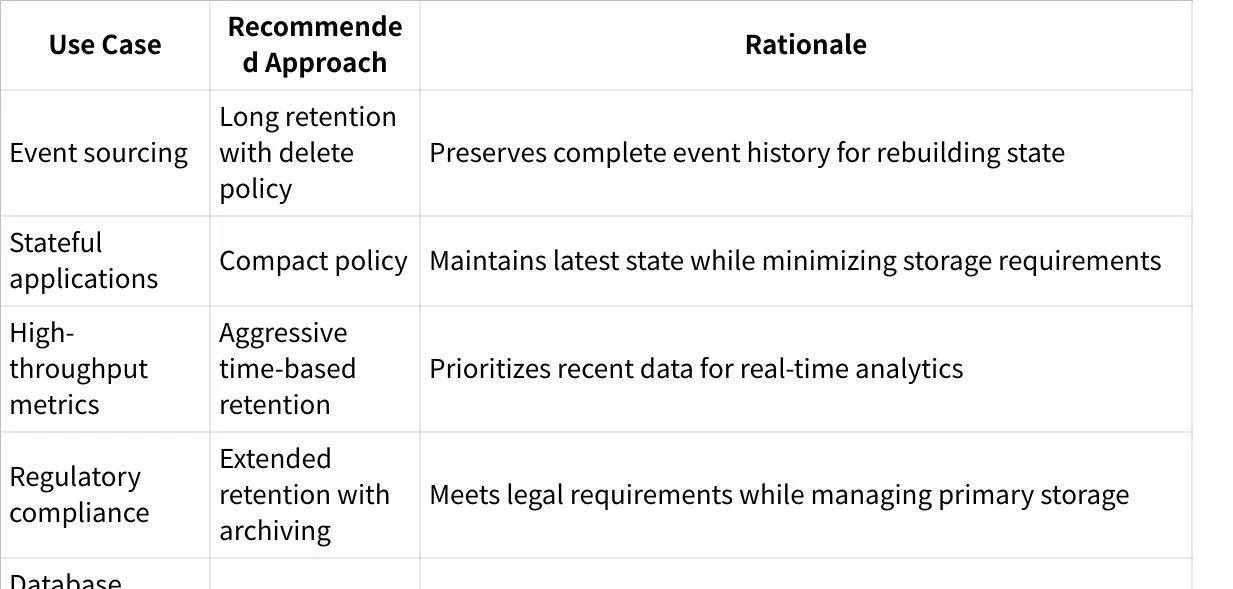
Common Challenges and Solutions
Challenge: Consumer Offset Loss
Problem : Consumer groups that remain inactive beyond the offsets.retention.minutes period (default: 7 days) lose their committed offsets, causing them to restart from the latest or earliest offsets when reactivated.
Solution : Increase offsets.retention.minutes for critical consumer groups or implement custom offset management for long-running but intermittent consumers.
Challenge: Storage Growth
Problem : Rapid storage growth in high-throughput environments can exhaust disk space before retention policies take effect.
Solution : Implement both time and size-based retention limits, monitor storage usage proactively, and consider scaling storage horizontally across additional brokers.
Challenge: Retention vs. Availability
Problem : Aggressive retention policies may delete data before all consumers have processed it.
Solution : Align retention policies with consumer SLAs, implement monitoring for consumer lag, and consider buffering critical data in secondary storage for slower consumers.
Challenge: Segment Cleanup Timing
Problem : Even when messages exceed retention thresholds, they aren't deleted until their entire segment is eligible for deletion, potentially leading to longer-than-expected retention.
Solution : Tune segment size and monitor actual versus configured retention to ensure alignment with business requirements.
Kafka's retention mechanisms provide powerful tools for managing data lifecycle within streaming platforms. By understanding the interplay between segments, retention policies, and cleanup strategies, organizations can implement efficient and effective data management approaches that balance storage costs against data availability requirements.
When implementing retention policies, consider starting with conservative settings and gradually adjusting based on observed usage patterns and business needs. Regular monitoring and periodic review of retention configurations will ensure your Kafka deployment continues to meet evolving requirements while maintaining optimal performance.
Still struggling with skyrocketing Kafka bills and the "ops tax" of manual disk management? It's time to stop babysitting your clusters. Try AutoMQ Cloud for Free and experience how diskless architecture slashes costs and automates scaling—no credit card required. See how others made the switch in our case studies or explore the project on GitHub.


