Overview
Kafka topics represent the fundamental organizational unit within Apache Kafka's architecture, serving as the backbone for event streaming applications across industries. As the structured channel between producers and consumers, topics enable the high-throughput, fault-tolerant data streaming that powers companies like LinkedIn, Netflix, and Uber. This comprehensive guide explains everything you need to know about Kafka topics, from basic concepts to advanced configurations and best practices.
Understanding Kafka Topics
Kafka topics function as named logical channels that facilitate communication between producers and consumers of messages. At their core, topics are simply ordered logs of events where data is appended and stored in a time-sequential manner. Unlike traditional message queues, Kafka topics are durable, persistent logs that retain messages for a configurable period regardless of whether they've been consumed. This fundamental characteristic makes topics suitable for a wide range of use cases, from event streaming to log aggregation and message queueing. When external systems write events to Kafka, these events are appended to the end of a topic, creating an immutable record of what happened and when.
Topics provide a means of categorizing and organizing the potentially vast number of events flowing through a Kafka cluster. For instance, a topic might contain readings from temperature sensors named 'temperature_readings' or GPS locations from vehicles called 'vehicle_location'. Each topic has a unique name across the entire Kafka cluster, which typically describes the type of data it contains. The naming conventions often reflect the business domain, making topics intuitive organizational units that map to specific business objectives or data sources.
Topic Architecture
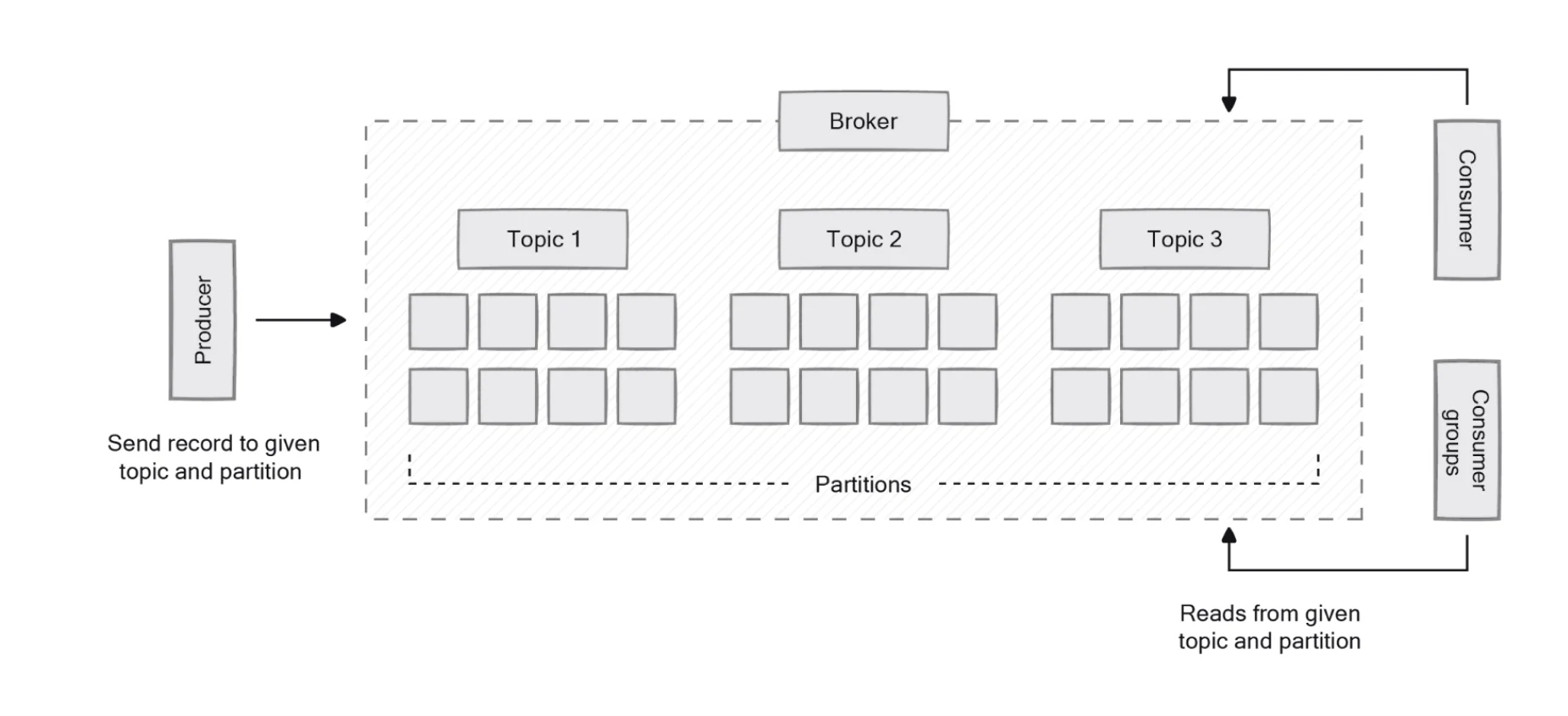
The internal architecture of Kafka topics is designed for scalability and performance. Topics are divided into partitions, which serve as the fundamental storage element of Kafka. Each partition is an ordered, immutable sequence of messages that is continually appended to. The partitioning mechanism allows Kafka to scale horizontally by distributing data across multiple servers, enhancing throughput and providing fault tolerance. Messages within a partition are assigned a sequential identifier called an offset, which uniquely identifies each message within that partition.
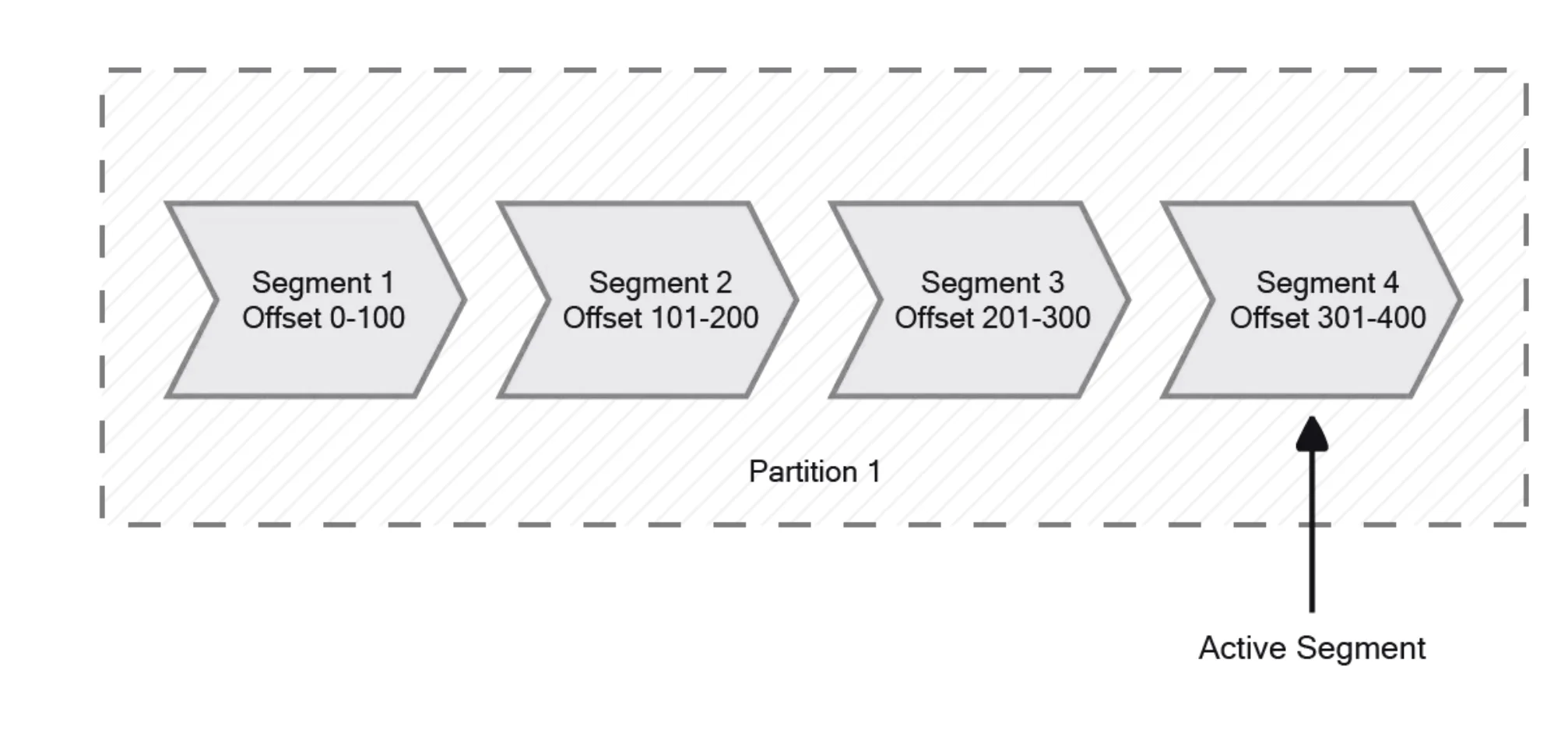
Partitions enable parallelism by allowing multiple consumers to read from different partitions of the same topic simultaneously. This parallel processing capability is a significant factor in Kafka's ability to handle high-volume data streams efficiently. Additionally, partitioning allows topics to scale beyond the storage limits of a single server, as partitions can be distributed across multiple brokers in a Kafka cluster. Inside each partition, Kafka further organizes data into segments, which represent files in Kafka's directory structure. Only one segment is active at any time, with new data being written to this active segment.
Topic Replication
To ensure fault tolerance and data durability, Kafka implements a replication mechanism at the topic level. When creating a topic, administrators specify a replication factor, which determines how many copies of each partition should be maintained across different brokers. This replication strategy ensures that if a broker fails, data remains accessible through replicas on other brokers. For a topic with a replication factor of N, Kafka can tolerate up to N-1 server failures without losing any committed records.
For each partition, one broker serves as the leader, handling all read and write requests for that partition. The remaining replicas, known as followers, synchronize with the leader to maintain identical copies of the data. If the leader fails, one of the in-sync followers automatically takes over as the new leader, ensuring continuous availability of the partition. This leader-follower model balances the workload across the cluster while maintaining data consistency. Kafka ensures that the same partitions never end up on the same broker, which is crucial for maintaining fault tolerance in case of server failures.
How Kafka Topics Work
Kafka topics function as commit logs, essentially serving as temporary storage for messages as they move from producers to consumers. The log-based architecture provides simple semantics that make it feasible for Kafka to deliver high throughput while simplifying replication and recovery processes. Logs are append-only data structures with well-defined semantics: new messages are always appended to the end, they can only be read by seeking an arbitrary offset and then scanning sequentially, and events in the log are immutable once written.
Producer-Consumer Interaction
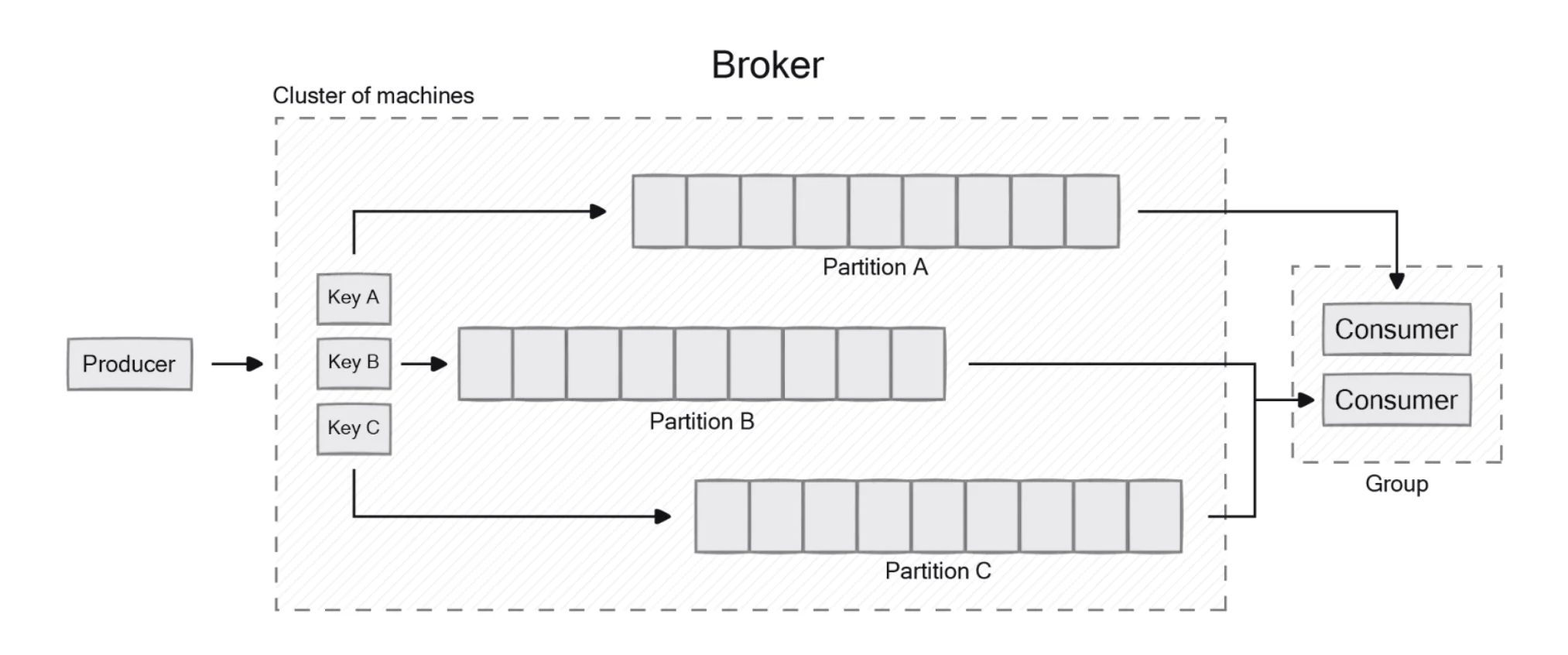
Producers create messages and write them to topics. When a producer sends a message to a topic, Kafka's partition mapper determines which partition within the topic should receive the message. This decision can be based on a message key (all messages with the same key go to the same partition) or through a round-robin distribution if no key is specified. Based on configuration settings, producers can adopt a fire-and-forget approach or wait for an acknowledgment from the Kafka broker confirming successful message receipt.
On the consumer side, applications subscribe to one or more topics and process the messages in the order they were produced. Unlike traditional pub/sub systems, Kafka doesn't push messages to consumers. Instead, consumers pull messages from topic partitions, allowing them to consume at their own pace. This pull-based model provides consumers with control over their consumption rate, contributing to system stability under varying loads. A consumer connects to a subscribed topic partition in a broker and reads messages in the order they were written. Kafka supports both single and multiple-topic subscriptions, enabling consumers to process messages from different topics concurrently.
Topic Offsets and Storage
Within partitions, Kafka uses offsets to track message positions. Offsets represent the sequential ordering of messages from the beginning of a partition and help Kafka ensure message ordering and establish delivery guarantees. Consumers maintain their position in each partition by recording the offset of the last consumed message, allowing them to resume consumption from where they left off if they disconnect and reconnect later. This offset management is a crucial aspect of Kafka's durability and reliability.
Inside partitions, Kafka divides data into segments, which are files in Kafka's directory structure. Only one segment is active at a time, and new data is written to this active segment. When a segment reaches a certain size or age threshold, it is closed, and a new active segment is created. This segmentation allows for efficient storage management and cleanup of older data. Administrators can control segment management through configuration parameters like 'log.segment.bytes' (maximum segment size) and 'log.segment.ms' (maximum time a segment remains open).
Configuring Kafka Topics
Kafka provides extensive configuration options for topics, allowing administrators to fine-tune performance, durability, and resource utilization based on specific use cases. These configurations can be set when creating a topic or modified later as requirements evolve. Understanding these configuration options is essential for optimizing Kafka's behavior in various deployment scenarios.
Topic Creation and Management
Topics can be created either automatically or manually. Automatic creation occurs when an application produces, consumes, or fetches metadata from a non-existent topic, assuming the 'auto.create.topics.enable' property is set to true. However, best practice recommends manually creating all input/output topics before starting an application. Manual creation gives administrators more control over topic configurations like partition count and replication factor.
To create a topic manually, administrators use the 'kafka-topics.sh' script, specifying parameters such as topic name, replication factor, and partition count. For example:
bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic test-topic --partitions 3 --replication-factor 2This command creates a topic named 'test-topic' with three partitions and a replication factor of two. Once created, topic configurations can be altered using the 'kafka-configs.sh' command, allowing for adjustments to parameters like segment size, retention period, and cleanup policies.
Essential Topic Configurations
Kafka topics support various configuration options that affect their behavior and performance. Retention settings determine how long data should be kept in a topic before deletion, with options for time-based retention (keeping data for a specific duration) or size-based retention (keeping data until the topic reaches a certain size). These settings are crucial for managing storage resources and ensuring compliance with data retention policies.
Segment size configuration impacts how data is stored on disk and affects write performance and cleanup operations. Smaller segments allow for more granular data management, while larger segments can improve write performance at the cost of more complex cleanup. Compression settings reduce storage requirements and improve data transfer efficiency by compressing the data stored in topics. Cleanup policies determine how data is removed from topics, with options like 'delete' (removing messages based on retention settings) or 'compact' (retaining only the latest message for each key), each serving different use cases.
Best Practices for Kafka Topics
Implementing best practices for Kafka topic design and management ensures optimal performance, scalability, and reliability. These practices encompass naming conventions, partition strategies, and data retention policies. Well-defined practices help maintain topic organization, efficient data processing, and smooth operation of the Kafka ecosystem.
Partitioning Strategy
Choosing an appropriate partitioning strategy is critical for Kafka's performance. The number of partitions should match the desired level of parallelism and expected workload, considering factors like the number of consumers, data volume, and cluster capacity. Too few partitions can limit throughput and parallelism, while too many can increase overhead and resource consumption. A common rule of thumb is to align the partition count with the expected concurrent consumer count to maximize parallelism without overloading the system.
Understanding data access patterns is essential for designing an effective partitioning strategy. Analyze how your data is produced and consumed, considering read-and-write patterns to create a strategy aligned with your specific use case. For scenarios requiring strict message ordering for related events, key-based partitioning ensures that messages with the same key are routed to the same partition, preserving their order. However, this approach may lead to uneven partition distribution if keys are not well-distributed. Regularly monitor partition balance and adjust the strategy as needed to maintain optimal performance.
Operational Recommendations
Avoid frequent partition changes, as modifying the number of partitions for a topic can be disruptive. Adding partitions is relatively straightforward but doesn't redistribute existing data, while reducing partitions is more complex and can cause data loss. Plan partitioning strategies during initial topic creation and adjust only when necessary. For routine tasks like topic creation, configuration updates, and scaling, implement automation using tools like Ansible or Kafka Manager to reduce manual effort and minimize errors.
Data retention requires careful consideration based on use cases, compliance requirements, and storage capacity. Implement appropriate retention policies to ensure data is neither lost prematurely nor retained excessively. For topics containing change data or key-value pairs, consider using compaction to retain only the latest value for each key, reducing storage requirements and simplifying downstream processing. Finally, implement robust security measures for Kafka topics, including authentication and authorization mechanisms to protect data integrity and prevent unauthorized access.
Conclusion
Kafka topics form the cornerstone of Apache Kafka's architecture, providing a scalable, durable, and high-performance foundation for event streaming applications. Their log-based design enables the separation of producers and consumers, allowing for asynchronous communication patterns that are essential in distributed systems. By understanding the concepts, architecture, and configuration options of Kafka topics, organizations can effectively leverage this technology to handle real-time data streams at scale.
The best practices outlined in this guide help ensure optimal performance and reliability when working with Kafka topics. From thoughtful partitioning strategies to careful configuration of retention policies, these recommendations provide a framework for designing and managing topics effectively. As event streaming continues to gain importance across industries, mastering Kafka topics becomes increasingly valuable for architects, developers, and administrators building modern data platforms. With proper implementation and management, Kafka topics enable organizations to process and analyze data streams in real-time, unlocking insights and driving innovation.
Still struggling with skyrocketing Kafka bills and the "ops tax" of manual disk management? It's time to stop babysitting your clusters. Try AutoMQ Cloud for Free and experience how diskless architecture slashes costs and automates scaling—no credit card required. See how others made the switch in our case studies or explore the project on GitHub.


