


.png)
History and Definitions
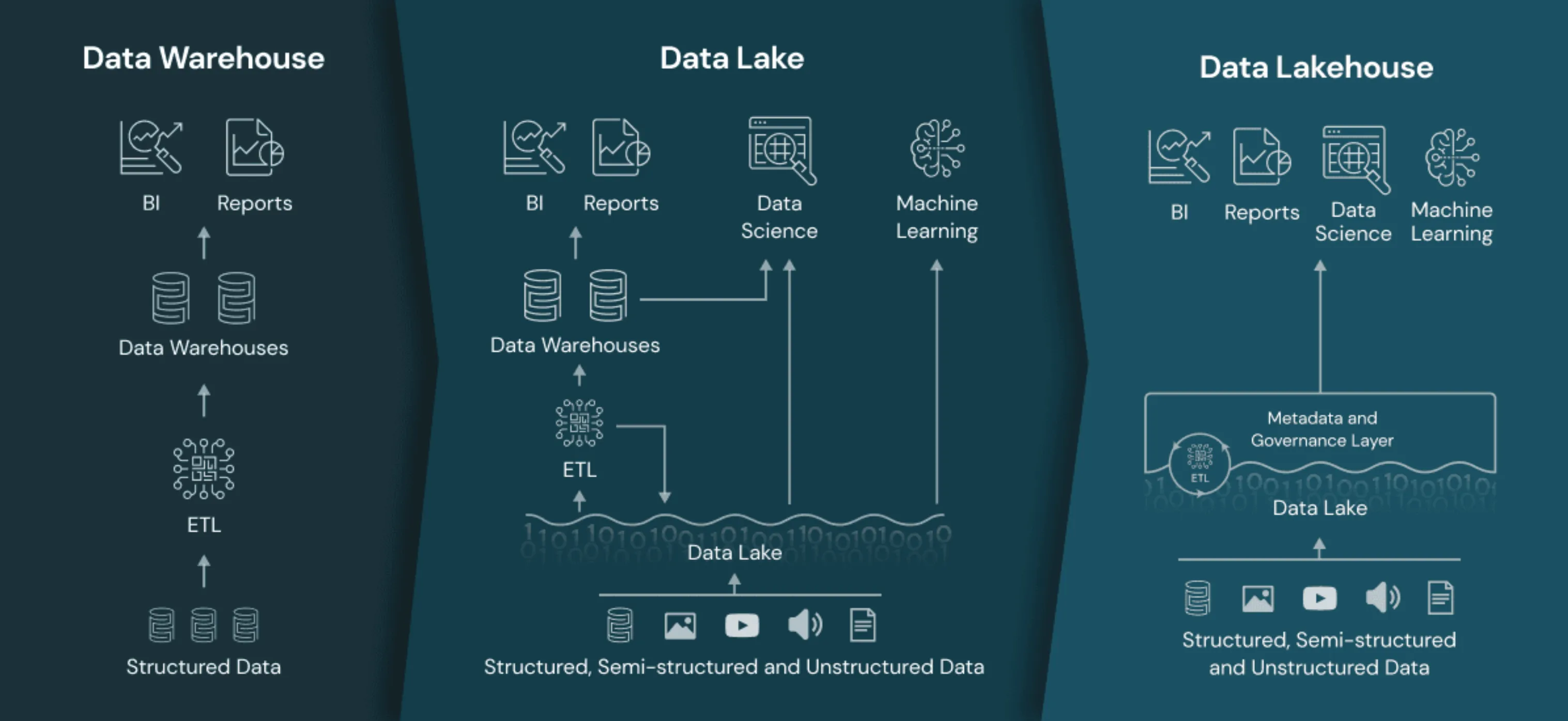
Data Warehouse : Originated in the 1980s, data warehouses are centralized repositories that store structured data from various sources, optimized for business intelligence and reporting. They are designed to provide historical insights and support decision-making by analyzing past data.
Data Lake : Coined in 2011, data lakes are repositories that store raw, unprocessed data in its native format, including structured, semi-structured, and unstructured data. They are ideal for big data analytics and machine learning.
Data Lakehouse : A more recent concept, data lakehouses combine the scalability of data lakes with the structured analytics capabilities of data warehouses. They offer a unified platform for managing diverse data types and support both real-time analytics and AI/ML workloads.
Usage Scenarios
Data Warehouse : Best suited for business intelligence, reporting, and historical analysis. They are ideal for structured data and support complex queries for business users.
Data Lake : Suitable for data science, big data analytics, and machine learning. Data lakes handle large volumes of diverse data types and are cost-effective for storing raw data.
Data Lakehouse : Offers comprehensive analytics capabilities, combining business intelligence with advanced analytics. It supports both structured and unstructured data, making it versatile for various use cases.
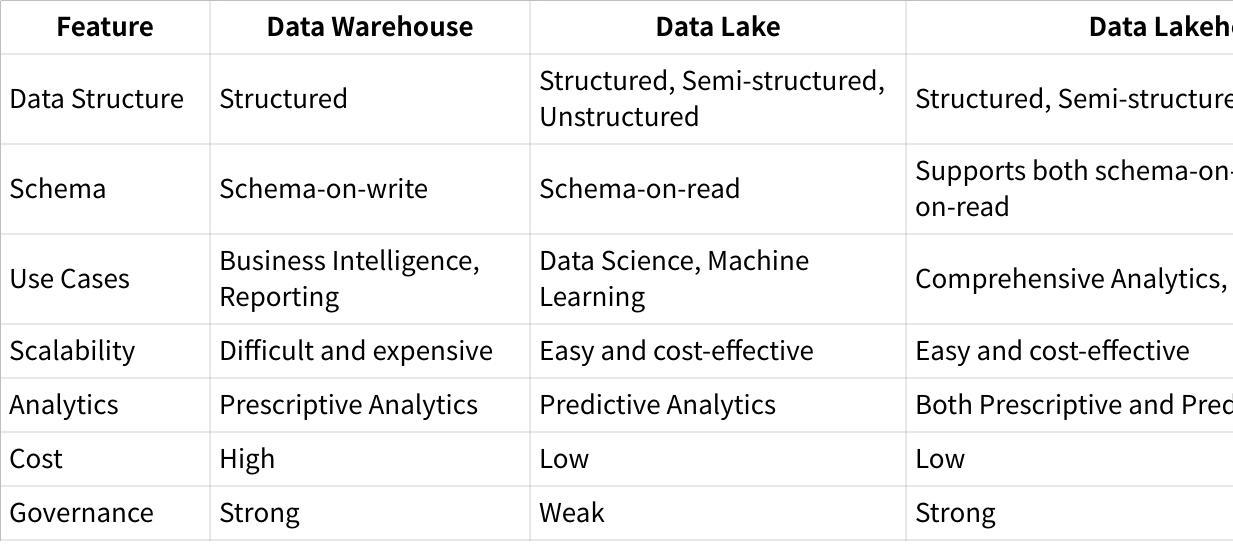
Differences
Emerging Trends for 2025
Integration and Convergence : There is a growing trend toward integrating data lakes and warehouses into lakehouse architectures to leverage the strengths of both systems.
AI and Real-Time Analytics : The integration of AI and real-time analytics is becoming more prevalent, with lakehouses leading the way in supporting these capabilities.
Data Governance and Security : As AI adoption increases, data governance and security are becoming critical to ensure compliance and protect sensitive data.
In summary, while data warehouses excel in structured data analysis, data lakes are ideal for handling diverse data types. Data Lakehouses, by combining the benefits of both, are poised to become a central component of modern data analytics architectures in 2025.
How to integrate AutoMQ with Data Lake Analysis
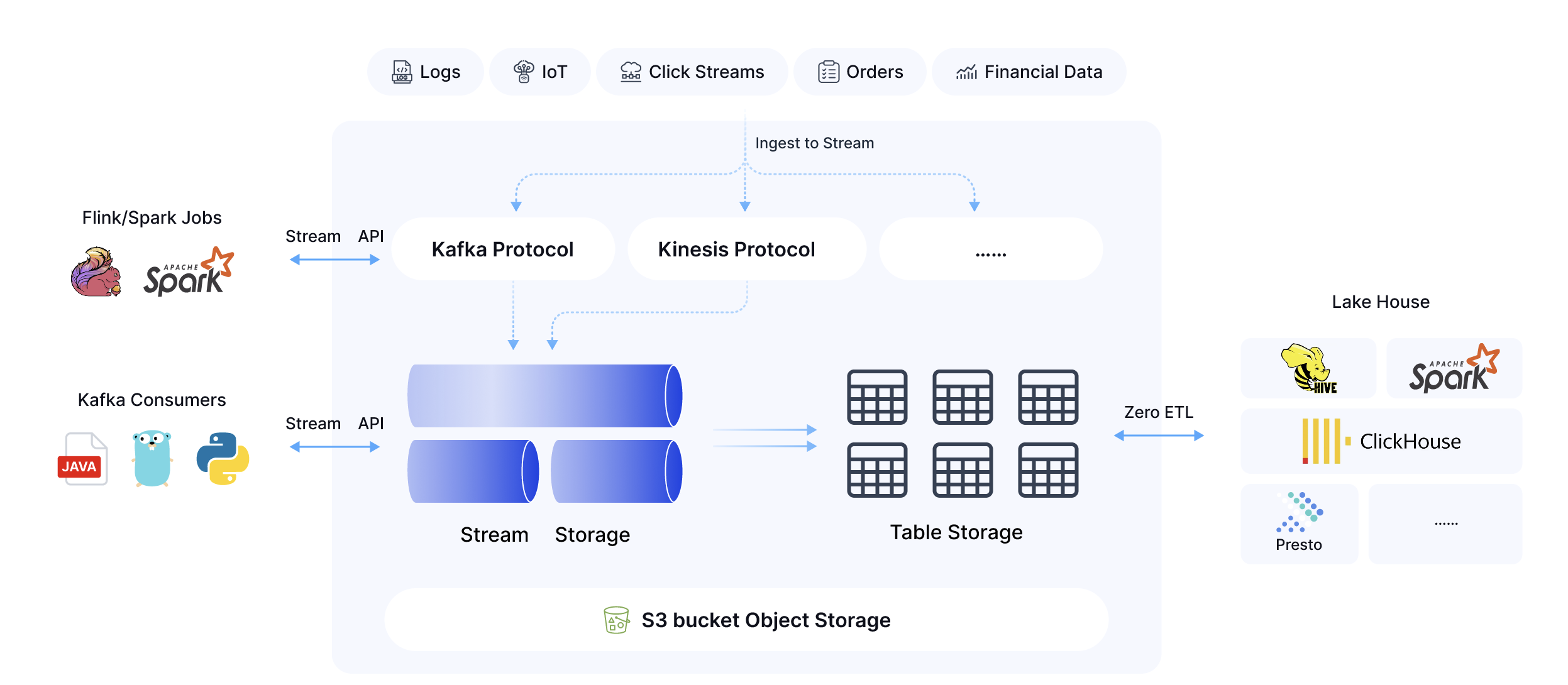
AutoMQ is a next-generation Kafka that is 100% fully compatible and built on top of S3. AutoMQ's Table Topic capability provides an efficient way to convert Kafka stream data directly into modern data lake table formats such as Apache Iceberg or Paimon. This feature simplifies transforming data from stream processing to data lakes. AutoMQ includes a fully functional schema registry that recognizes and manages data structures intelligently. This component automatically converts various stream data formats according to predefined schema rules, creating standardized data lake tables efficiently stored on S3 or other object storage systems. This automation eliminates the need to set up and maintain complex Flink jobs or ETL tasks for data format conversions, reducing both operational costs and technical complexity. By using the Table Topic feature, AutoMQ integrates naturally with today's mainstream data lake architectures, offering users an end-to-end data processing solution.
References
[1] Data Lakehouse: https://www.databricks.com/glossary/data-lakehouse





