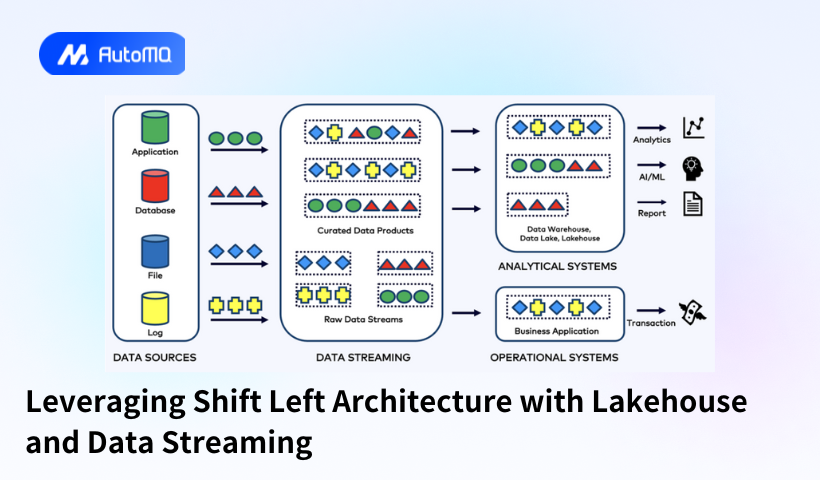
.png)
Editor's Note: This article is a reading guide for Kai Waehner's "The Shift Left Architecture – From Batch and Lakehouse to Real-Time Data Products with Data Streaming".
The article introduces the concept of data products and explores how to create reusable data products to enable organizations to derive value from current and future data. Based on the fundamental principle of building data products to harness data value, the author proposes using Apache Kafka and Flink to construct a shift-left architecture, where high-quality data products are created early in the data pipeline. Furthermore, real-time raw data streams are ingested into the lakehouse using the Iceberg format for subsequent analytical consumption. The article thoroughly explains the critical role of Apache Kafka in the modern shift-left data stack.
AutoMQ is the only next-generation Kafka that is 100% compatible with Apache Kafka globally, offering tenfold cost reductions and rapid elasticity, making the following methodologies fully applicable to AutoMQ. We invite you to use our open-source community version on GitHub or contact us for a commercial trial.
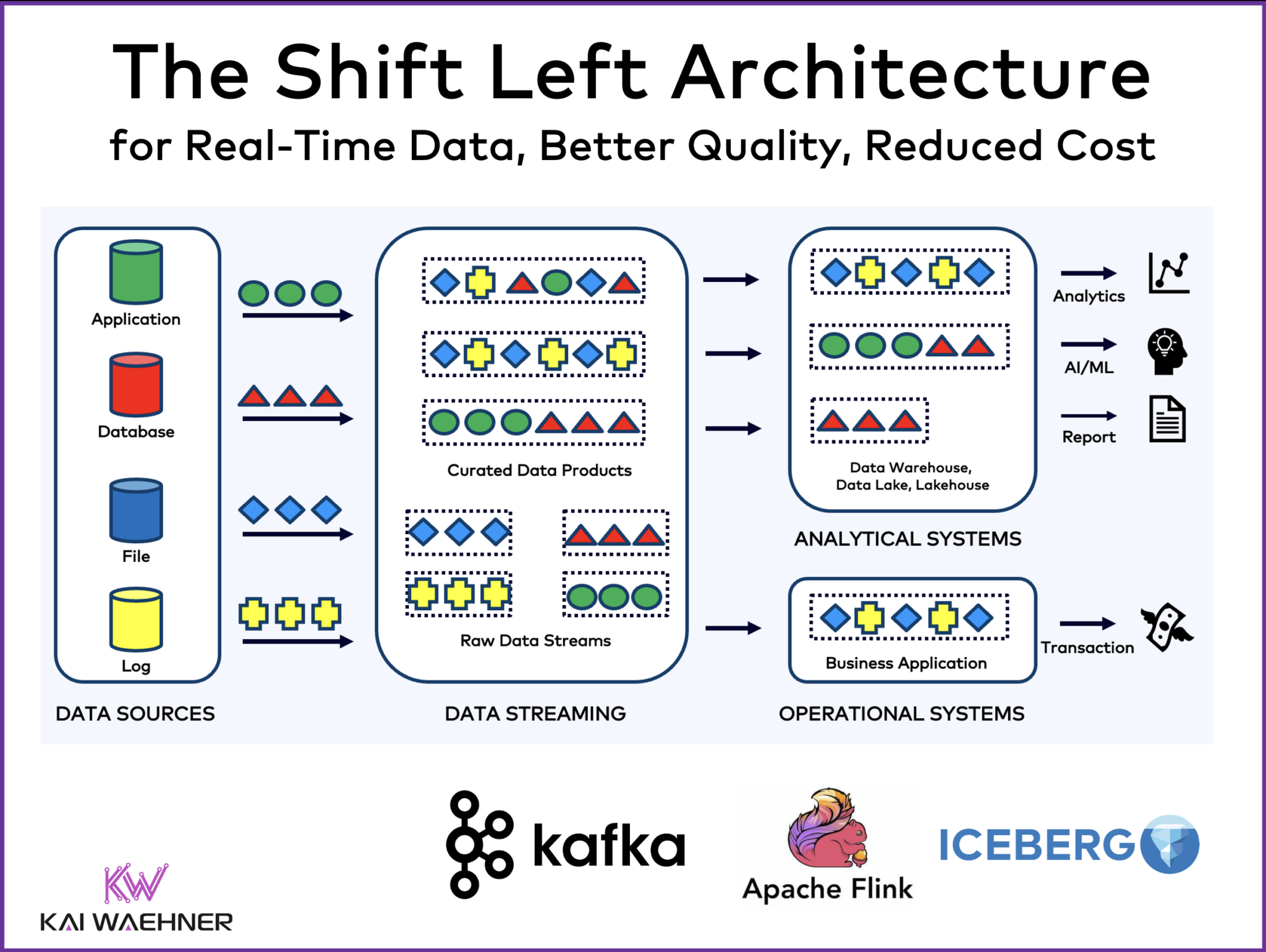
Data integration within enterprises is often riddled with complexity and inefficiencies. Traditional practices like batch processing and Reverse ETL, while common in data warehouses, lakes, or lakehouses, introduce significant issues such as data inconsistency, high computational costs, and outdated information. This article by Kai Waehner presents a novel approach—The Shift Left Architecture—to tackle these challenges. The architecture leverages real-time data products within a data mesh, enabling the unification of transactional and analytical workloads through technologies such as Apache Kafka, Flink, and Iceberg. The solution promises consistent data handling, reduced costs, and enhanced flexibility, ultimately fostering a data-driven company culture that accelerates the time-to-market for innovative software applications.
Main Takeaways
Challenges of Traditional Data Integration
Traditional methods like batch processing and Reverse ETL have been the go-to for data integration in legacy data warehouses, lakes, and lakehouses. However, these methods often lead to significant pitfalls, including data inconsistency where different systems hold different versions of the data, high computational costs due to redundant processing tasks, and outdated information because of the inherent delays in batch processing cycles. This outdated approach results in a spaghetti architecture that’s hard to manage and scale, leading to inefficiencies across the enterprise.
The Shift Left Architecture
The Shift Left Architecture is introduced as a revolutionary design pattern aimed at overcoming these traditional challenges. By deploying real-time data mesh architecture, it unifies both transactional and analytical workloads. Using cutting-edge data streaming technologies such as Apache Kafka, Flink, and Iceberg, the Shift Left Architecture processes data in real time as events are created, leading to more immediate and accurate data availability. This shift left means data processing is done earlier in the data lifecycle, enabling more agile and responsive data operations.
Real-Time Data Products
Central to the Shift Left Architecture is the concept of real-time data products. These products are inherently high-quality and consistent, designed to handle both real-time and batch processes seamlessly. By shifting data transformation to the point of data entry, these products ensure that data is processed once and made immediately available for various uses across the organization. This approach reduces redundancy, minimizes data latency, and enhances the reusability and reliability of the data, facilitating better decision-making and faster response times.
Data Mesh and Decentralized Management
A data mesh moves away from the conventional centralized data management to a decentralized approach, where data ownership is distributed across different domain teams. Each data product in this architecture is owned by a specific team, leading to truly decoupled applications. This decentralization allows for domain-specific expertise to be applied to data management, making it more effective. Data products include not just the raw data, but also associated metadata, documentation, and standardized APIs, ensuring that data is self-contained, discoverable, and easily accessible.
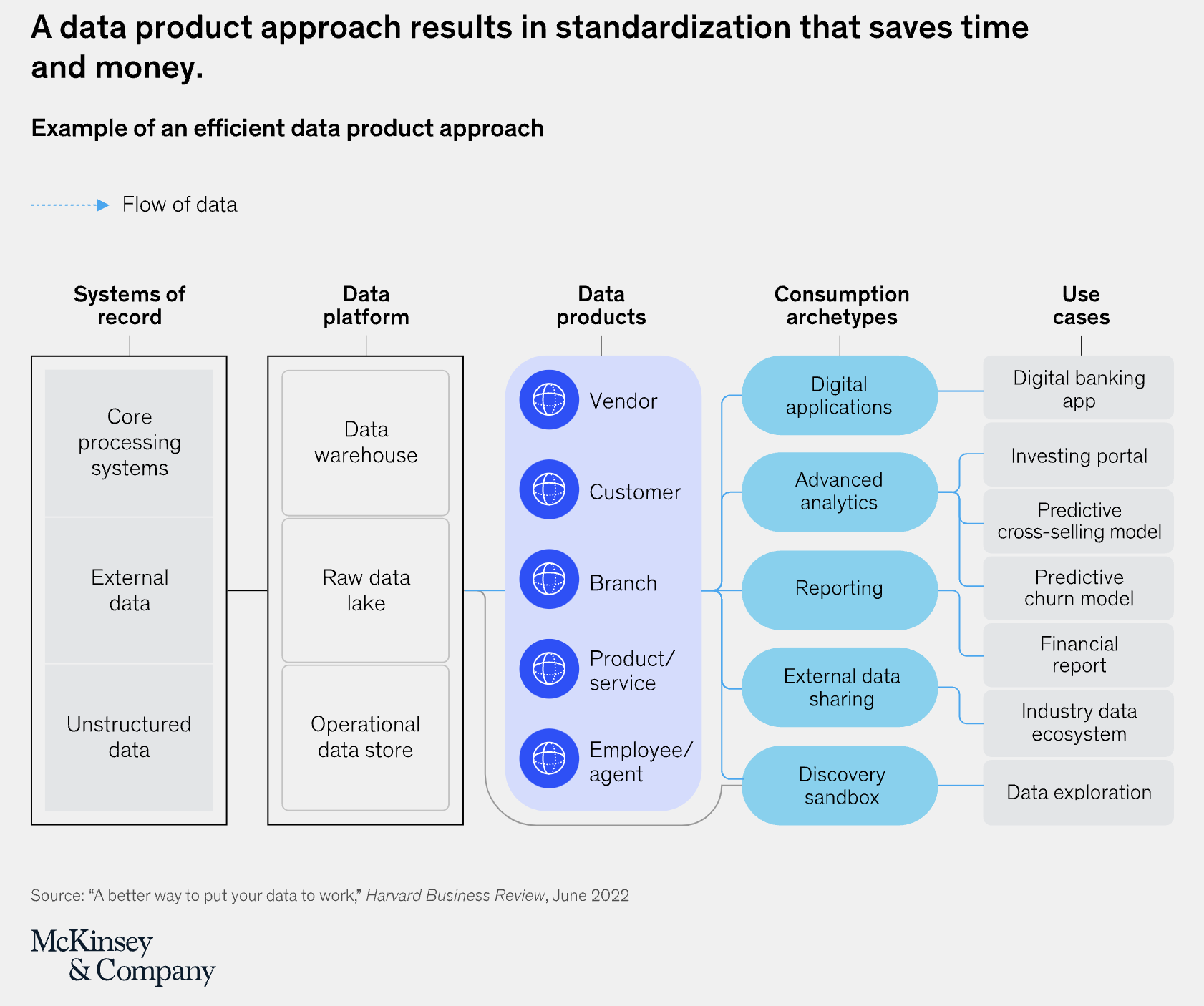
Drawbacks of Traditional ELT Processes
Traditional Extract, Load, Transform (ELT) processes are inefficient and often result in slower updates, as data must pass through several stages before becoming usable. Development times are lengthened since each business unit may need to perform similar data processing independently. This leads to increased costs, especially since many analytics platforms charge based on compute usage rather than storage. Repeated efforts across different units and platforms also lead to further inefficiency and higher operational overhead. Additionally, data inconsistency becomes a critical issue as multiple systems attempt to sync data through convoluted pipelines.
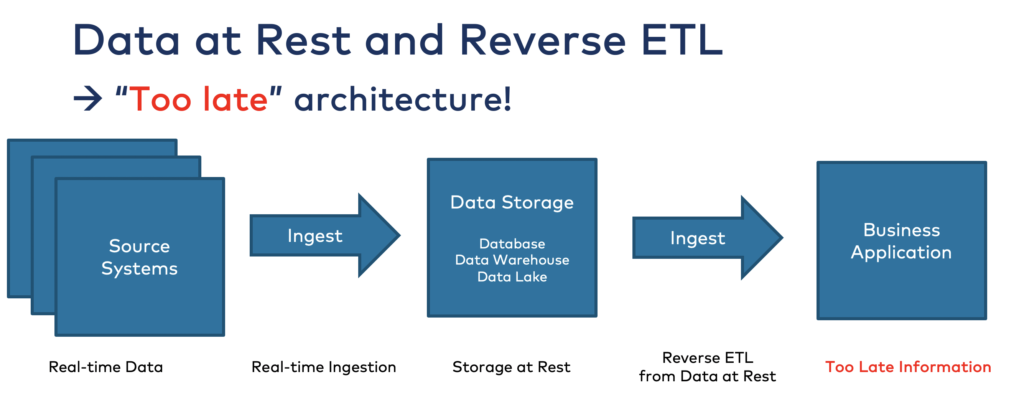
Benefits of Data Streaming
By adopting a data streaming platform like Apache Kafka, enterprises can capture and process data continuously in real time. This real-time data processing ensures immediate data availability and consistency. Data contracts and policy enforcement upstream ensure data quality and reliability right from the source. Streaming data platforms can handle large volumes of data efficiently, curating it into multiple contexts in real time to maximize reusability. This leads to a more streamlined, cost-efficient, and responsive data architecture, enabling better real-time analytics and operational efficiency.
Technological Integration
The Shift Left Architecture leverages key technologies: Apache Kafka for steady data streaming, Apache Flink for advanced stream processing, and Apache Iceberg for powerful data storage and query optimization. This combination allows seamless connectivity between data sources, efficient real-time processing, and versatile data consumption. Apache Iceberg, with its ACID transactions, performs schema evolution and partitioning, making it ideal for data lake and analytical workflows. This integration results in a highly performant data ecosystem that supports various operational and analytical needs without redundant data storage or processing.
Business Value
The Shift Left Architecture delivers substantial business value by significantly reducing computational costs across various data platforms such as data lakes, warehouses, and AI platforms. By performing data transformation immediately after event creation, development efforts are minimized, allowing teams to focus on critical business logic rather than repetitive ETL jobs. This accelerates time-to-market for new applications and innovations. The architecture also supports a best-of-breed approach, allowing the selection of the most suitable and cost-effective technologies per use case, thereby fostering organizational flexibility and rapid innovation.
Future Prospects and Standardization :
The Shift Left Architecture not only resolves current data integration problems but also sets the stage for future advancements in data management practices. Technologies like Apache Iceberg are becoming central to data processing efficiency and will likely continue to grow in importance. Major vendors across the cloud and data management sectors are supporting these technologies, indicating a move towards more standardized, interoperable, and cost-effective data solutions. This forward-thinking approach positions enterprises to better handle large-scale data operations and complex analytical needs, ensuring scalability and versatility in an evolving technological landscape.
By embracing The Shift Left Architecture, enterprises can transition away from fragmented and outdated data integration methods towards a more cohesive, efficient, and innovative data ecosystem driven by real-time streaming technologies. This strategic shift promises not only operational and cost benefits but also significantly enhances an organization's ability to swiftly develop and deploy cutting-edge applications.