
Introduction
Our project AutoMQ is based on S3 and EBS. We build a stream library called S3Stream to implement the storage layer. S3Stream uses cloud disks and object storage to achieve low latency, high throughput, "infinite" capacity, and low-cost stream storage.
As part of S3Stream, "Delta WAL" is one of the core components of it. Based on the cloud disk, it has the role of persistence, low latency, and high performance, and it is the write buffer layer on top of Main Storage (object storage). This article will focus on the implementation principle of Delta WAL.
What is Delta WAL?
The primary responsibility of Delta WAL is to serve as a persistent write buffer, working in conjunction with Log Cache to efficiently persist the written data in the form of WAL on cloud disk. Only after successful persistence on the cloud disk is success returned to the client. Meanwhile, the data reading process always occurs from memory and is returned to the client.
S3Stream has designed a cold-hot isolated cache system that consists of Log Cache (which caches newly written data) and Block Cache (which caches data pulled from object storage). The data in Log Cache will not become invalid in memory before the data in WAL has been uploaded to object storage. If data cannot be retrieved from Log Cache, it will be read from Block Cache instead. Block Cache ensures that even cold reads can hit the memory as much as possible through methods such as prefetching and batch reading, thereby ensuring the performance of cold read operations.
Delta WAL, as a component in S3Stream that supports high-performance persistent WAL, is primarily used to efficiently persist data from Log Cache to raw devices.
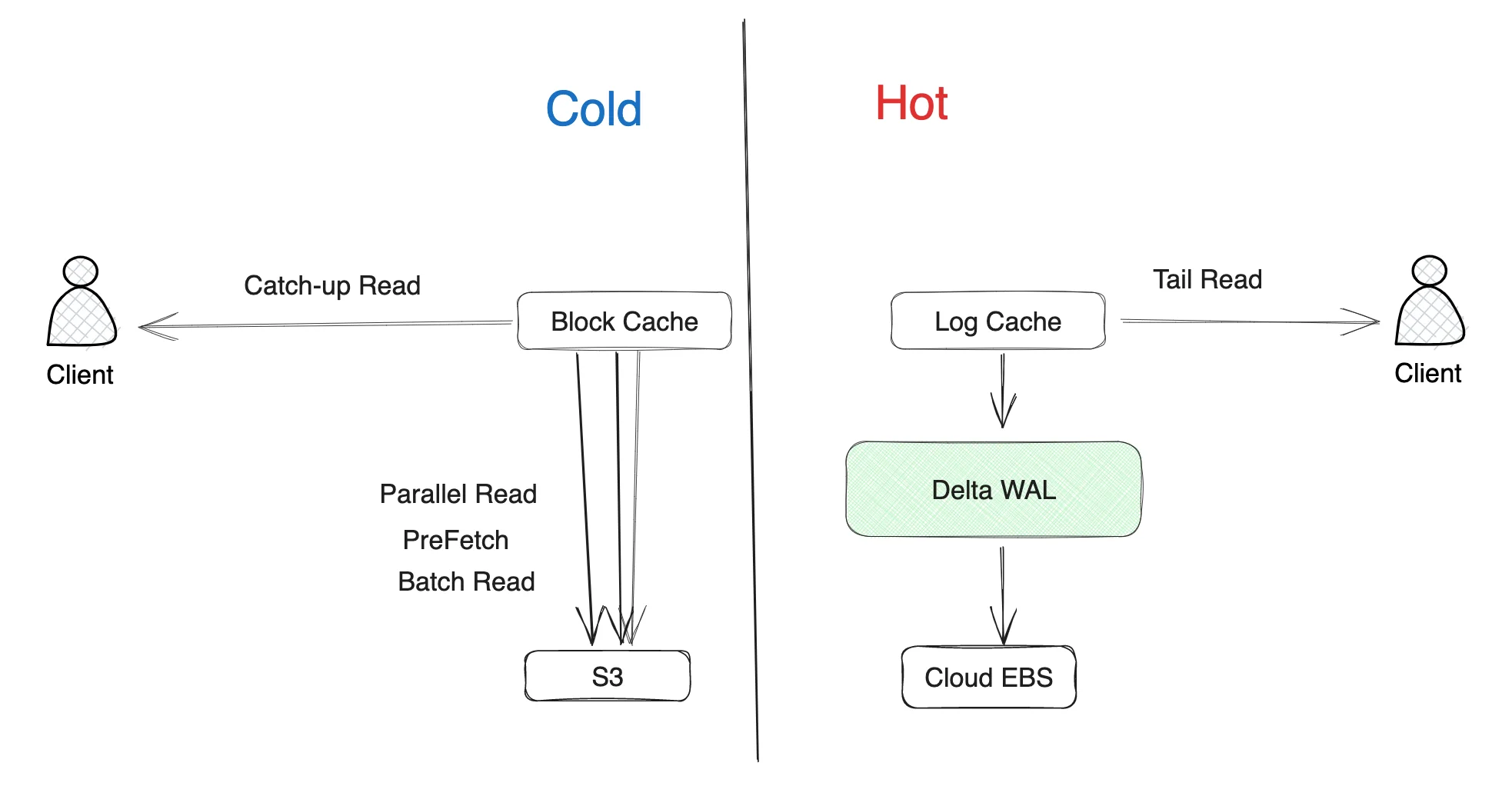
Why is S3Stream based on raw devices?
Delta WAL is built on top of cloud disks, bypassing the file system, and directly uses Direct I/O to read and write to raw devices. This design choice has the following three advantages:
-
Avoid Page Cache pollution
-
Enhancing write performance
-
Faster recovery after downtime
Prevent Page Cache pollution
When a Kafka broker handles a produce request, it writes data to the Page Cache and asynchronously writes data to the disk; similarly, when handling a consume request, if the data is not in the Page Cache, it reads the data from the disk into the Page Cache. This mechanism leads to pollution when consumers catch-up read, as data read from the disk is put into the Page Cache, affecting real-time reading and writing. When using Direct I/O for reading and writing, it bypasses the Page Cache, avoiding this problem and ensuring that real-time reading and writing do not interfere with catch-up reading.
In our performance white paper[3], we detail the performance comparison between Kafka and AutoMQ during catch-up reading. The results are shown in the following table:
| - | Time spent on sending during catch-up reading | Impact on sending traffic during catch-up reading | Catch up with peak read throughput |
|---|---|---|---|
| AutoMQ | Less than 3ms | Isolation of read and write, maintaining 800 MiB/s | 2500 ~ 2700 MiB/s |
| Kafka | Approximately 800ms | Interactions, dropping to 150 MiB/s | 2600 ~ 3000 MiB/s (sacrificing write) |
As can be seen, by avoiding page cache pollution, we achieve excellent read/write isolation when reading historical data . When catching up with reads, the real-time read and write performance is almost unaffected; whereas Kafka, when catching up with reads, results in a significant increase in message delivery latency and a serious drop in traffic.
Enhancing write performance
The vast majority of file systems will have certain additional overhead during read and write: such as file system metadata operations, journaling, etc. These operations will occupy a part of the disk bandwidth and IOPS, and the write path will also become longer. Using raw devices for read and write can avoid these overheads, resulting in lower write latency. The following table compares the performance of writing on a file system and on a raw device. It can be seen that compared to a file system, the write latency of a raw device is significantly lower and the performance is better.
| - | Average Write Latency (ms) | P99 Write Latency (ms) | Maximum Write Latency (ms) |
|---|---|---|---|
| Raw Device | 1.250 | 3.95 | 13.1 |
| Ext4, journal | 5.074 | 19.00 | 377.4 |
| Ext4, ordered | 1.573 | 5.01 | 266.9 |
| Ext4, writeback | 1.317 | 4.18 | 79.8 |
Note: The tests are based on fio, with the command as sudo fio -direct=1 -iodepth=4 -thread -rw=randwrite -ioengine=libaio -bs=4k -group_reporting -name=test -size=1G -numjobs=1 -filename={path}
Faster recovery after downtime
When using a file system, if the OS crashes, a check and recovery of the file system is needed after restart. This process could be time-consuming and is directly proportional to the size of the data and metadata on the file system.
When using raw devices, no file system check and recovery is needed, hence the recovery is faster after downtime.
Design Goals
Delta WAL, as a component in S3 Stream, has the following design goals:
-
Rotating write, not much storage space needed. As a buffer before data is written into object storage, Delta WAL doesn't store much data (by default, every time it accumulates 512 MiB, it uploads to object storage). Therefore, it can use the rotating write mode (similar to Ring Buffer), and doesn't require much storage space (by default 2 GiB).
-
Fully leverage the performance of cloud disks. Currently, most cloud providers offer some free IOPS and bandwidth for their cloud disks. For example, AWS EBS GP3 provides 3000 free IOPS and 125 MiB/s bandwidth. This requires Delta WAL to fully utilize the capacity of the cloud disk, and use the free IOPS and bandwidth to improve performance as much as possible.
-
Support recovery from non-graceful shutdown as quickly as possible. When unexpected problems such as crashes occur and brokers are shut down in an inelegant manner, Delta WAL needs to recover to normal as quickly as possible after restarting, without data loss.
Implementation details
The source code of Delta WAL can be found in the S3stream[2] repository. We will introduce the specific implementation of Delta WAL from top to bottom.
Interface
The interface of Delta WAL is defined in WriteAheadLog.java. There are several main methods:
public interface WriteAheadLog {
AppendResult append(ByteBuf data) throws OverCapacityException;
interface AppendResult {
long recordOffset();
CompletableFuture<CallbackResult> future();
interface CallbackResult {
long flushedOffset();
}
}
CompletableFuture<Void> trim(long offset);
Iterator<RecoverResult> recover();
interface RecoverResult {
ByteBuf record();
long recordOffset();
}
}-
append : asynchronously write a record to Delta WAL. Return the offset of the record and the future of the write result, which will be completed after the record is flushed to disk.
-
trim : Delete the record whose offset is less than or equal to the specified offset. It is worth mentioning that this is just logical deletion, and the data on the disk will not actually be deleted. When a segment of data is uploaded to object storage, this method will be used to update the offset.
-
recover : From the latest trim offset, recover all records. Return an iterator, each element in the iterator is a record and its offset. This method will be called after restarting recovering the data in Delta WAL that has not been uploaded to object storage.
It is worth noting that the offset returned in Delta WAL is a logical position, not an actual position on the disk (physical position). This is due to the previously mentioned fact that Delta WAL adopts a round-robin writing mode, where the physical position cycles on the disk, while the logical position is monotonically increasing.
Data Structure
The main data structures in Delta WAL include WALHeader, RecordHeader, and SlidingWindow. They will be introduced separately.
WALHeader
WALHeader is the header information of Delta WAL, defined in WALHeader.java. It contains some metadata of Delta WAL, including:
-
magicCode : used to identify the header of Delta WAL to prevent misreading.
-
capacity : the capacity of the bare device. It is configured at initialization and will not change. It is used to convert logical positions and physical positions.
-
trimOffset : the trim position of Delta WAL. Records before the trim position have been uploaded to object storage and can be overwritten; during recovery, recovery will start from the trim position.
-
lastWriteTimestamp : the timestamp of the last refresh of WALHeader.
-
slidingWindowMaxLength : The maximum length of the sliding window. Its specific function will be introduced later.
-
shutdownType : Shutdown type. It is used to identify whether the last shutdown of Delta WAL was graceful.
-
crc : The CRC check code of WALHeader. It is used to check whether the WALHeader is damaged.
RecordHeader
RecordHeader is the header information of each record in Delta WAL, defined in SlidingWindowService.java. It contains some meta-information of each record in Delta WAL, including:
-
magicCode : Used to identify the header of the Delta WAL record to prevent misreading.
-
length : The length of the record.
-
offset : The logical position of the record.
-
crc : The CRC check code of the record. It is used to check whether the record is damaged.
SlidingWindow
SlidingWindow is the sliding window for writing in DeltaWAL, defined in SlidingWindowService.java. It is used to allocate the writing position for each record and control the writing of the record. It consists of several positions, as shown below:

-
Start Offset : The starting point of the sliding window. Records before this have been landed.
-
Next Offset : The next logical point that has not yet been allocated. New records will start writing from here. The data between the Next Offset and the Start Offset has not yet been fully landed.
-
Max Offset : The maximum logical point of the sliding window. When the Next Offset reaches the Max Offset, it will try to expand the sliding window. When the window reaches its maximum length (the slidingWindowMaxLength mentioned in WALHeader earlier), it will pause writing until a record lands and the window slides forward.
Writing and Recovery
Next, let's focus on the writing and recovery process of Delta WAL.
Writing
AutoMQ has fully considered the billing items of the cloud disk and the characteristics of the underlying implementation in the design of writing implementation, in order to maximize performance and cost-effectiveness. Taking AWS EBS GP3 as an example, it provides 3000 IOPS for free, so the time threshold of Delta WAL is set to 1/3000 seconds by default, to match the free IOPS quota and avoid extra costs. In addition, AutoMQ has introduced a batch size threshold (default is 256 KiB) to avoid sending too large Records to the cloud disk. The underlying implementation of the cloud disk will split records larger than 256 KiB into multiple 256 KiB small data blocks and write them to the persistent medium in sequence. AutoMQ's split operation ensures parallel writing at the bottom of the cloud disk, improving write performance. The following figure shows the specific writing process of Delta WAL:
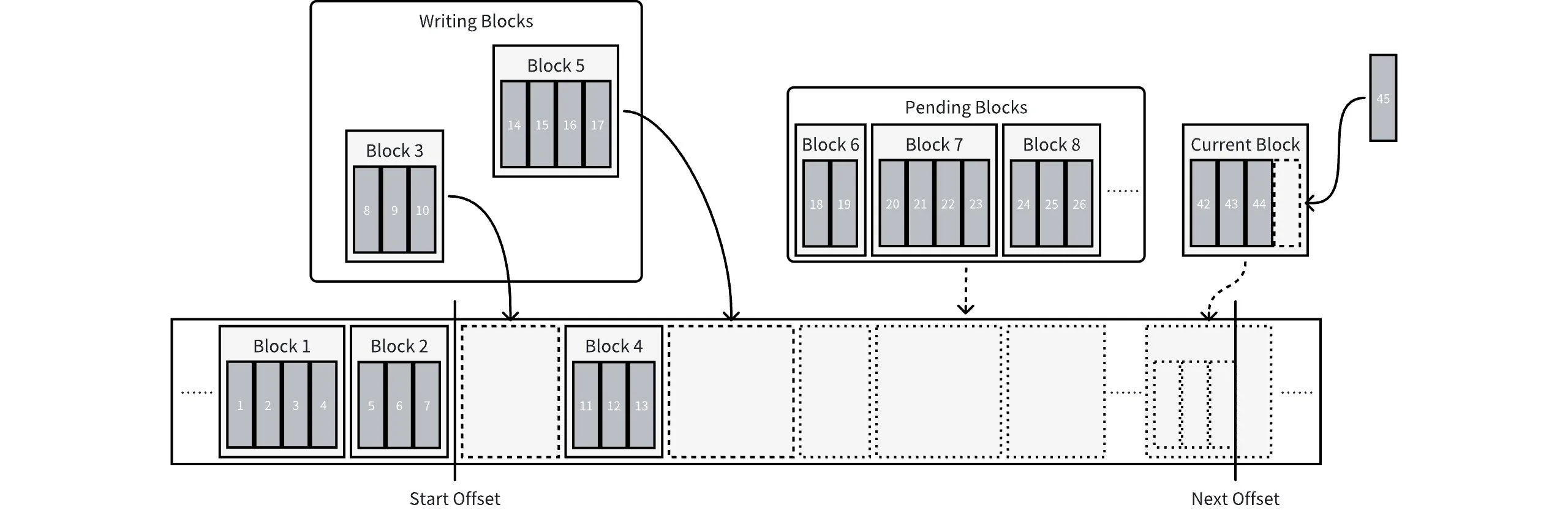
The Start Offset and Next Offset mentioned in the figure have been explained earlier, and are not elaborated on here. The meanings of several new data structures introduced are as follows:
-
Block : The smallest unit of an IO operation, containing one or more records. When written to disk, each Block aligns to 4 KiB.
-
writingBlocks : A collection of blocks being written. When a block is written to the disk, it is removed from the collection.
-
pendingBlocks : A collection of blocks waiting to be written. When the IO thread pool is full, new blocks are placed into this collection, waiting for the previous IO to complete before being moved into writingBlocks for writing.
-
currentBlock : The latest Block. Records that need to be written are placed in this block, which is also responsible for allocating logical offsets for new records. When currentBlock is full, it is placed into pendingBlocks, and a new Block is created and becomes currentBlock.
The process of writing is as follows:
-
The caller initiates an append request, passing in a record.
-
The record is added to the end of the currentBlock, and an offset is assigned. The offset is synchronously returned to the caller.
-
If the currentBlock has accumulated a certain size or time, it will be put into pendingBlocks, and a new currentBlock will be created at the same time.
-
If the number of writingBlocks is less than the size of the IO thread pool, a block is taken from the pendingBlocks and placed in the writingBlocks for writing.
-
Once the block is written to the disk, it is removed from the writingBlocks. At the same time, calculate and update the Start Offset of the sliding window, and complete the future of the append request.
Recovery
When Delta WAL restarts, the external will call the recover method to recover all records from the latest trim point. The recovery process is as follows:
-
Read the trim offset from the WAL header and set it as the recover offset.
-
Read the record header under the recover offset and check whether it is legal.
-
If so, update the recover offset to the end of this record.
-
If not, set the recover offset to the next 4K aligned position.
-
-
Repeat step 2 until, after the first encounter with an illegal record, you continue to attempt to read for a length of window max length.
It's worth noting that in step 3, the reason for continuing to attempt to read after encountering an illegal record is because there may be gaps in the data between the Start Offset and the Next Offset in the sliding window, i.e., some records have already been written to disk, while others have not yet been written. During recovery, it is necessary to recover as many records that have already been written to disk as possible, rather than skipping them directly.
Read and Write Raw Devices
As mentioned earlier, Delta WAL does not rely on the file system at the bottom, but directly uses Direct I/O to read and write raw devices. In implementation, we relied on a third-party library kdio and made a slight modification to it to adapt to the Modules feature introduced in Java 9. It encapsulates system calls such as pread and pwrite, providing some convenient methods to help us read and write raw devices directly.
Below are some experiences we have accumulated when using Direct I/O to read and write raw devices.
Alignment
When using Direct I/O for reading and writing, it is required that the memory address, the offset and size of IO be aligned with the following values, otherwise the write will fail:
-
The sector size of the disk (usually 512 Bytes or 4 KiB)
-
The page size of the operating system (usually 4 KiB)
-
(If the kernel version is lower than 2.6.33) the logical block size of the file system (512 Bytes)
In order to ensure that the offset and size of the IO are aligned, we have aligned the Block mentioned above, making its size a multiple of 4 KiB, and also aligning its offset when written to the disk to 4 KiB. The advantage of this is that each time you write, the IO offset is aligned and there is no need to deal with the situation of writing in the middle of a sector. At the same time, because the Block has a batching logic, and Delta WAL only serves as a buffer and does not need to store data for a long time, the space waste caused by the holes created after alignment is small and acceptable.
In the implementation process, the following methods were used to handle the alignment of memory addresses:
public static native int posix_memalign(PointerByReference memptr, NativeLong alignment, NativeLong size);
// following methods are from io.netty.util.internal.PlatformDependent
public static ByteBuffer directBuffer(long memoryAddress, int size);
public static long directBufferAddress(ByteBuffer buffer);
public static void freeDirectBuffer(ByteBuffer buffer);-
posix_memalign is a method in the POSIX standard used to allocate a block of memory and ensure that its address is aligned to a specified size.
-
The remaining three methods are utility methods in Netty:
-
directBuffer is used to wrap a memory address and size into ByteBuffer
-
directBufferAddress is used to get the memory address of ByteBuffer, which is used as the argument of pread and pwrite
-
freeDirectBuffer is used to release ByteBuffer
-
By combining the above methods, we can allocate, use, and release aligned memory in Java.
Maintaining Raw Device Size
Unlike file systems, the size of a raw device cannot be obtained through the metadata of the file, which requires us to maintain the size of the raw device ourselves. During initialization, the upper layer will specify the size of the WAL, and Delta WAL will obtain the size of the raw device at initialization and compare it with the specified size: if the size of the raw device is smaller than the specified size, an exception will be thrown; if the size of the raw device is larger than the specified size, the capacity in WALHeader will be set to the specified size, and it cannot be changed thereafter. The advantage of this is that it can ensure that the size of Delta WAL is not bound to the size of the raw device, avoiding problems caused by changes in the size of the raw device.
In the future, we will also support dynamic changes to the size of Delta WAL to meet more scenarios.
Benchmark Test
In order to verify the performance of Delta WAL, we conducted some benchmark tests. The test environment is as follows:
-
AWS EC2 m6i.xlarge, 4 vCPU, 16 GiB RAM
-
AWS EBS GP3 (2 GiB, 3000 IOPS, 125 MiB/s)
-
Ubuntu 22.04 LTS linux 5.15.0-91-generic
The test code can be found in the repository. The size of the IO thread pool is configured to be 4 during the test, and the target write throughput is 120 MiB/s. The test results are as follows:
| Record size** | Avg Latency (ms) | IOPS* | Throughput* (MiB/s) | Request SIze* (KiB) | Queue size* |
|---|---|---|---|---|---|
| 1 KiB | 0.990 | 2800 | 122.1 | 44.7 | 2.0 |
| 4 KiB | 0.910 | 2790 | 119.9 | 43.6 | 2.0 |
| 64 KiB | 1.120 | 1580 | 119.3 | 77.3 | 1.3 |
| 128 KiB | 1.330 | 963 | 119.2 | 126.7 | 1.0 |
| 256 KiB | 1.950 | 486 | 119.0 | 251.0 | 0.8 |
| 1 MiB | 3.80 | 486 | 119.0 | 251.0 | 1.2 |
*: Reading in iostat
**: Each record in Stream WAL has a 24 Bytes header, which was subtracted during the test.
We can see that
-
Delta WAL can fully utilize the performance of the cloud disk
-
The write throughput is close to 125 MiB/s (a small part of the bandwidth is used to write headers, 4K alignment, and other overheads).
-
When the record is not too large, it can basically run at full 3000 IOPS.
-
-
The write latency of Delta WAL is low, with an average latency of less than 1 ms for small packets and less than 2 ms for large packets. In the AutoMQ performance white paper, it can be seen that the long-tail latency of AutoMQ sending messages is significantly better than Kafka.
Conclusion
DeltaWAL, as a part of S3Stream, is one of the core components of AutoMQ. It is based on raw devices, avoiding Page Cache pollution, improving write performance, and faster recovery after crashes. In its implementation, we fully utilize the IOPS and bandwidth of the cloud disk to ensure the performance of DeltaWAL, thereby ensuring the low latency and high throughput of AutoMQ. In the future, we will support more features, such as dynamically changing the size of DeltaWAL, to meet more scenarios.


