.png)
About Qianxun SI
Qianxun SI is a space-time intelligence infrastructure company founded in August 2015. The company leverages foundational positioning data from the BeiDou Satellite System (compatible with GPS, GLONASS, and Galileo), over 5000 globally distributed GNSS satellite/ground-based enhancement stations, self-developed positioning algorithms, and a large-scale internet service platform to provide centimeter-level positioning, millimeter-level sensing, and nanosecond-level timing services. In October 2019, the company completed a Series A financing round of 1 billion RMB, with a valuation exceeding 13 billion RMB.
Business Background
Since its establishment in 2015, Qianxun SI has been using the BeiDou Satellite System and its positioning algorithms to provide industry solutions in various fields such as water conservancy, mining, smart cities, and smart transportation, empowering multiple industries. The large volumes of data and corresponding monitoring, trace, and log information from internal positioning base stations and hardware terminal devices need to be distributed via Apache Kafka to downstream consumers for further analysis and processing. With rapid business growth, daily data processing has reached tens of billions.
Initially, Qianxun SI utilized Kafka; however, as hardware terminals proliferated and business rapidly expanded, data traffic surged, leading to increasingly severe challenges with Kafka. AutoMQ's architecture, which offloads durability to shared storage like object and block storage, not only significantly reduces costs compared to Kafka but also provides rapid elasticity and ease of maintenance. This positions AutoMQ as the optimal choice for cost optimization and architectural enhancement. Given AutoMQ’s 100% compatibility with Apache Kafka, Qianxun SI can seamlessly migrate without needing to adjust its existing architecture or surrounding Apache Kafka facilities, thereby resolving a series of past pain points. The following diagram illustrates the data platform architecture of Qianxun SI after applying AutoMQ:
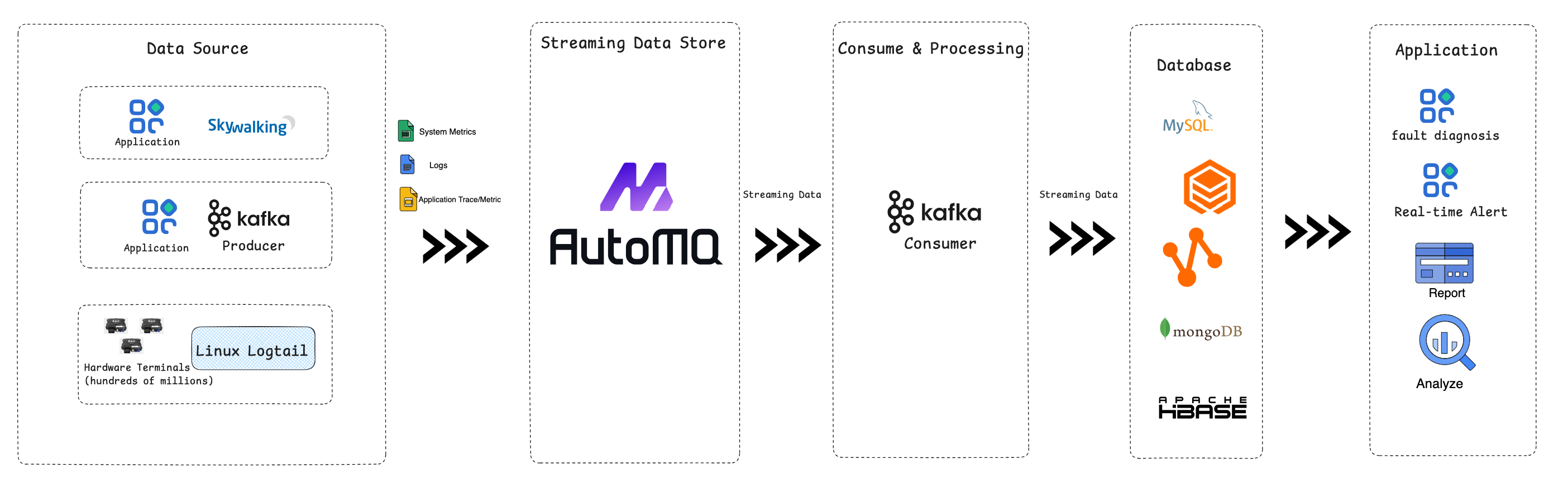
Qianxun Position writes data to AutoMQ in several main categories:
System Monitoring Data : A component similar to falcon_agent directly sends machine monitoring data to AutoMQ. This primarily includes virtual machine system monitoring data such as disk, CPU, and network metrics. Utilizing this data, Qianxun Position's downstream monitoring and alerting systems can promptly identify anomalies in virtual machines.
User Data : User data is mainly sent to AutoMQ via Kafka Producer or Logtail. The data from Logtail originates from hundreds of millions of terminals on Qianxun SI. These include industry drones, surveying equipment, and vehicle-mounted positioning terminals. The write throughput is 600MB/s , with over 10 billion messages written daily. In addition to general user data, there are two critical data pipelines with a write throughput of 150MB/s , which must ensure low latency and no data loss to avoid impacting the accuracy of critical reports. Once ingested, user data is analyzed by other applications to produce important reports such as user behavior analysis, daily active user trends, key customer analysis, and base station data analysis. These reports aid in enterprise decision-making and optimize the service levels of Qianxun Position's various products.
Application Trace/Metric Data : Trace and metric information from applications is sent to AutoMQ through skywalking agent, used for real-time monitoring, alerting, and issue diagnosis of applications.
Why Choose AutoMQ
For Qianxun Technology, the primary goal is to quickly reduce costs and address Kafka's elasticity issues. Kafka's cost-related challenges primarily manifest in the following areas:
High Storage Costs : Kafka, based on Apache Kafka's ISR multi-replica mechanism, ensures data durability. With three replicas and the cost of SSD cloud disks, the storage unit price can reach up to 3.x RMB (approximately 0.5 USD) per GB per month. While EBS in the cloud already provides high durability through multiple replicas, Apache Kafka's ISR mechanism leads to additional storage space inefficiency. Furthermore, EBS, as a high-performance and highly durable block storage, incurs relatively high unit storage costs.
Lack of Separation Between Storage and Compute Leading to Extra Costs : Kafka fundamentally employs a coupled storage and compute architecture. To support higher write throughput, both compute and storage must scale simultaneously, which is not ideal for Qianxun Position's application scenarios. All Qianxun Position data is initially stored in various databases, with Kafka retaining data for only 2 hours. When Kafka's capacity is insufficient to handle write traffic and requires scaling, both compute and storage layers must be expanded simultaneously, leading to considerable storage space waste. Clients still bear the cost for these underutilized resources, causing expenses to escalate substantially with increased write traffic.
Lack of Elasticity : Kafka's integrated architecture for both storage and computation necessitates partition data replication during scaling. This process consumes significant disk and network I/O resources and is time-consuming, hindering rapid cluster scaling. As business expands, the Qianxun Position Kafka cluster inevitably encounters capacity constraints, necessitating expansion to manage increased traffic. During Kafka scaling, partition data must be reassigned to new nodes—a time-intensive process requiring manual intervention and incurring high operational costs.
After extensive research into AutoMQ, we discovered that its innovative storage architecture can significantly reduce our Kafka cloud expenses while offering robust elasticity, effectively addressing Qianxun Position's current challenges:
Significantly Reduced Compute and Storage Costs : AutoMQ stores all data in object storage, priced at 0.12 CNY (approximately 0.017 USD) per GB per month, offering a significant cost advantage over Kafka's SSD-based multi-replica storage. Furthermore, AutoMQ's innovative shared storage architecture ensures that compute layer Brokers are stateless. Combined with AutoMQ's built-in self-balancing capability, we can quickly, safely, and automatically scale the compute layer independently. This enables us to downsize the cluster during off-peak periods or for clusters with reduced traffic, thereby saving costs.
More Economical Separation of Compute and Storage : Unlike Kafka, AutoMQ completely decouples the compute and storage layers. The storage layer operates on-demand, while the compute layer can be independently scaled quickly and safely based on traffic demands. This flexible architecture ultimately leads to cost savings. Qianxun Position's traffic model primarily features high write traffic with short storage retention times. Consequently, AutoMQ enables us to scale the compute layer independently without incurring increased storage costs, providing substantial savings compared to Kafka.
Extreme Elasticity Frees Up Operations : The cost of Qianxun Position's data infrastructure encompasses not only cloud resources and services but also human resources. AutoMQ comprehensively addresses Kafka's elasticity challenges. By offloading data durability to cloud storage, AutoMQ eliminates the need for partition data reassignment during scaling. Only metadata modifications are required, allowing partition reassignment in seconds. Its built-in automatic self-balancing component also aids in balancing traffic during scaling, preventing data skew issues. Previously, Kafka cluster scaling demanded tens of minutes and manual traffic redirection for partition reassignment. To ensure seamless scaling, we had to prepare contingency plans and keep the entire team on standby during off-peak hours. With AutoMQ, cluster scaling transforms into a low-risk, automated, routine operation, significantly reducing the manpower required for Kafka cluster scaling and making the entire process safer, faster, and more reliable.
Another crucial reason for selecting AutoMQ is its 100% compatibility with Apache Kafka. Qianxun Position has developed numerous applications and data infrastructure components around Apache Kafka. Thanks to AutoMQ's full compatibility with Apache Kafka, our entire data platform architecture and various upstream and downstream data infrastructure can migrate seamlessly without any modifications, significantly reducing migration complexity and eliminating potential migration risks.
Implementation of AutoMQ at Qianxun Position
Thanks to AutoMQ's 100% compatibility with Apache Kafka, the entire migration process was very smooth. Components like Skywalking and Logtail proved fully compatible with AutoMQ after testing, requiring no modifications. Upon completing the PoC, we successfully migrated from Kafka to AutoMQ using a traffic-cutting approach.
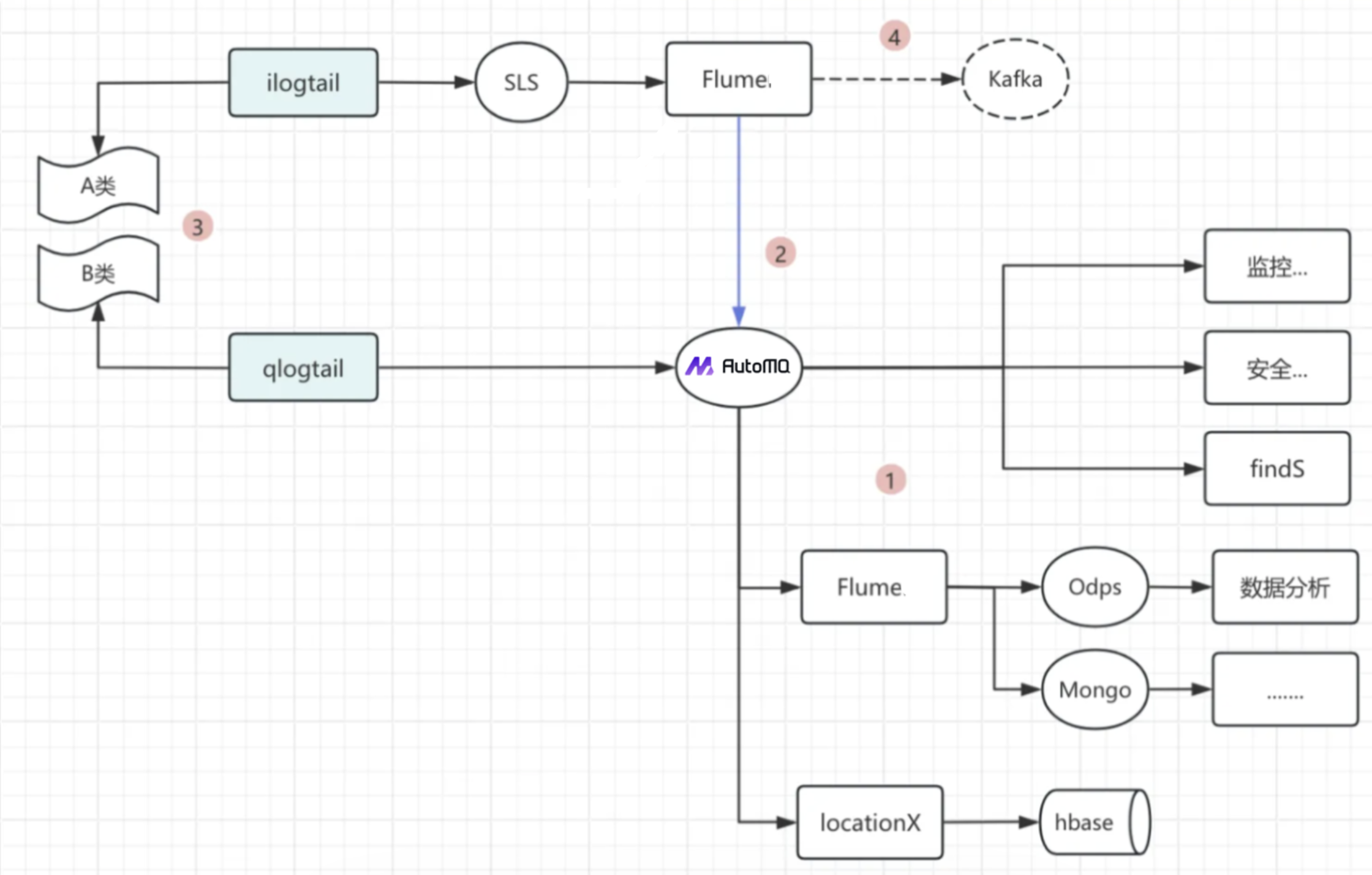
Flume implements dual-write, writing to both the old Kafka and the new AutoMQ
All consumption and delivery systems switch to the new AutoMQ
Gradually replace the old logtail client on the servers with the new client, which points to AutoMQ
After the gradual switch, decommission the old Flume and Kafka
Benefits and Outlook
Overall, AutoMQ is a next-generation Kafka with significant advantages in cost, performance, and elasticity. After deploying AutoMQ, costs are expected to decrease by over 50% .