Overview
The choice between stateful and stateless architecture fundamentally shapes how applications handle data, scale, and respond to failures. This comprehensive blog explores the key differences, implementation approaches, and best practices for each architectural pattern.
What is State?
State refers to a set of variables that can completely and uniquely represent the condition of a system at any given time. In computing, state encompasses information such as:
-
User authentication details
-
Session information
-
User preferences and settings
-
Transaction history
-
Application context
Stateful Architecture: Concepts and Mechanisms
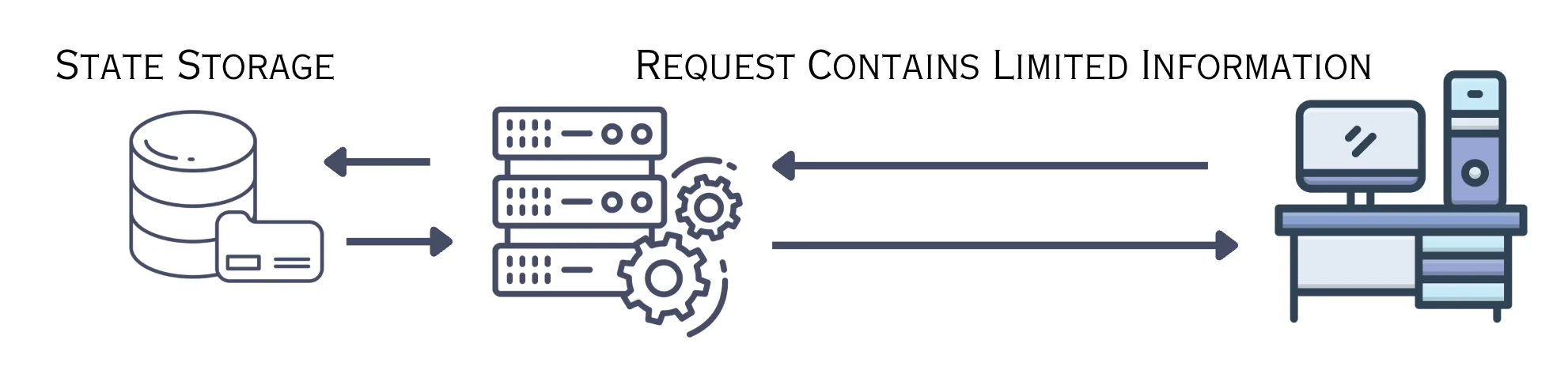
Stateful architecture maintains information about the client's session on the server side. The server "remembers" past interactions with clients and uses this information to inform future responses.
How Stateful Architecture Works
In a stateful system, the server retains client session information and expects subsequent requests from the same client to be processed by the same server. This creates a continuous conversational context between client and server.
Practical Analogy: A stateful architecture resembles a restaurant with waiters who take detailed notes on customer preferences, order history, and table numbers. Only the same waiter can efficiently serve a specific customer because they possess the customer's state information.
Real-World Examples
-
Traditional Web Applications: Applications requiring login sessions where servers maintain user state
-
Online Banking Systems: Track user authentication and transaction context
-
Email Platforms: Maintain user login state across browsing sessions
-
Database Management Systems: Store transaction state and data relationships
Implementations
-
Session Management: Server-side sessions using technologies like Redis, Memcached
-
Stream Processing: Stateful operations in Apache Kafka Streams (aggregations, reductions)
-
Container Orchestration: StatefulSets in Kubernetes for applications requiring persistent identity
Stateless Architecture: Concepts and Mechanisms
In stateless architecture, each request from client to server must contain all information needed to understand and process that request. The server doesn't rely on information from previous interactions.

How Stateless Architecture Works
Each request in a stateless system is treated as an independent transaction, carrying all necessary data with it. No user session information is stored on the server between requests. Instead, state data is typically stored in centralized databases or caches accessible by all servers.
Practical Analogy: A stateless restaurant operates with "forgetful" waiters who don't recognize returning customers or recall preferences. They record all orders in a central computer system that any waiter can access, allowing any server to help any customer efficiently.
Real-World Examples
-
RESTful APIs: Each HTTP request contains all needed information
-
Content Delivery Networks (CDNs): Deliver content based solely on the current request
-
Modern Streaming Services: Allow seamless continuation across multiple devices
-
Microservices Architectures: Independent services communicate through stateless interfaces
Implementations
-
Authentication: JWT (JSON Web Tokens) for stateless authorization
-
API Design: RESTful and GraphQL APIs
-
Caching Solutions: Redis, Hazelcast for external state management
-
Stream Processing: Stateless operations in Apache Flink or AutoMQ Data Transforms
Side-by-Side Comparison
| Characteristic | Stateful Architecture | Stateless Architecture |
|---|---|---|
| State Management | Maintains session data on servers | Stores state externally (database/cache) |
| Request Processing | Requires sticky sessions to route requests to same server | Any server can process any request |
| Fault Tolerance | Lower - server failure may lose session data | Higher - no critical session data lost if server fails |
| Scalability | Limited - adding servers requires session sharing mechanisms | High - servers can be added/removed easily |
| Resource Utilization | Higher server memory requirements to store state | More efficient server resource usage |
| Complexity | Simpler individual request handling | More complex request preparation (must include all context) |
| Data Redundancy | Lower - state stored once on server | Higher - state information sent with each request |
| Load Balancing | Requires sticky sessions configuration | Supports any load balancing strategy |
| Authentication | Server-maintained sessions | Token-based (JWT) or cookie-based approaches |
| Development Complexity | Can be simpler for developers initially | Requires more careful API design |
Best Practices
Stateful Architecture
-
Implement Session Replication: Ensure session data is replicated across servers to prevent data loss
-
Use Distributed Caching: Employ technologies like Redis or Hazelcast for shared state
-
Plan for Failover: Design systems to handle server failures without losing critical state
-
Optimize State Size: Minimize the amount of state data stored to reduce memory footprint
-
State Partitioning: Divide state data based on usage patterns to improve performance
Stateless Architecture
-
Externalize Application State: Store session data in stateful backing services like databases
-
Design for Horizontal Scaling: Build applications that can easily add/remove instances to match demand
-
Adopt Immutable Infrastructure: Replace components instead of updating them for consistency
-
Use Token-Based Authentication: Implement JWT or similar stateless authentication mechanisms
-
Implement Proper Caching Strategies: Optimize performance while maintaining statelessness
Use Cases: When to Choose Each Architecture
In practice, many modern applications blend these approaches, using stateless interfaces for scalability and resilience while managing necessary state in distributed databases or caching layers. The decision to use stateful or stateless architecture should be guided by the specific requirements of the application, including the complexity of user interactions, the need for personalization, expected traffic patterns, and the desired level of operational simplicity.
Ideal for Stateful Architecture
Stateful architecture is particularly well-suited for applications that require a persistent conversational context between the client and the server. For example, online banking platforms and e-commerce sites often need to maintain detailed user sessions, including authentication status, shopping cart contents, and transaction histories. In these scenarios, the application must remember the user's identity and activities across multiple interactions, making stateful design essential.
Real-time collaborative tools, such as document editors or chat applications, also benefit from stateful approaches, as they need to synchronize changes and user presence across sessions. Additionally, some legacy enterprise systems and applications with complex workflows may find stateful design more straightforward, as the overhead of passing complete state information with every request could become prohibitive or negatively impact performance.
Ideal for Stateless Architecture
On the other hand, stateless architecture excels in environments where scalability, reliability, and simplicity are paramount. Modern web services, especially those designed for cloud-native or microservices deployments, often favor statelessness because it allows any server instance to handle any request, facilitating effortless horizontal scaling and load balancing. Stateless design is also ideal for high-traffic APIs, content delivery networks, and serverless computing platforms, where rapid provisioning and fault tolerance are critical.
By externalizing state to centralized data stores or caches, these systems can recover quickly from failures and scale dynamically to meet fluctuating demand. Stateless architecture is also advantageous for services that need to be highly available and distributed across multiple geographic regions, as it minimizes dependencies on any single server or data center.
Decision Framework
When choosing between stateful and stateless architectures, consider these factors:
-
Scalability Requirements: If horizontal scaling is critical, prefer stateless
-
Complexity of State: More complex state management may benefit from stateful design
-
Fault Tolerance Needs: Higher reliability requirements favor stateless approaches
-
Development Resources: Assess team capability to handle complexity of each approach
-
User Experience Requirements: Consider if personalization needs stateful context
Conclusion
The choice between stateful and stateless architecture represents a fundamental design decision with far-reaching implications for application scalability, reliability, and complexity. While stateful architectures offer advantages in maintaining user context and providing personalized experiences, stateless architectures excel in scalability, fault tolerance, and alignment with modern cloud-native paradigms.
Most modern systems implement a hybrid approach-stateless service interfaces with externalized state management-to gain the benefits of both patterns. As distributed systems continue to evolve, understanding these architectural foundations remains essential for creating robust, scalable, and maintainable applications.
Still struggling with skyrocketing Kafka bills and the "ops tax" of manual disk management? It's time to stop babysitting your clusters. Try AutoMQ Cloud for Free and experience how diskless architecture slashes costs and automates scaling—no credit card required. See how others made the switch in our case studies or explore the project on GitHub.


