.png)
What is Tiered Storage

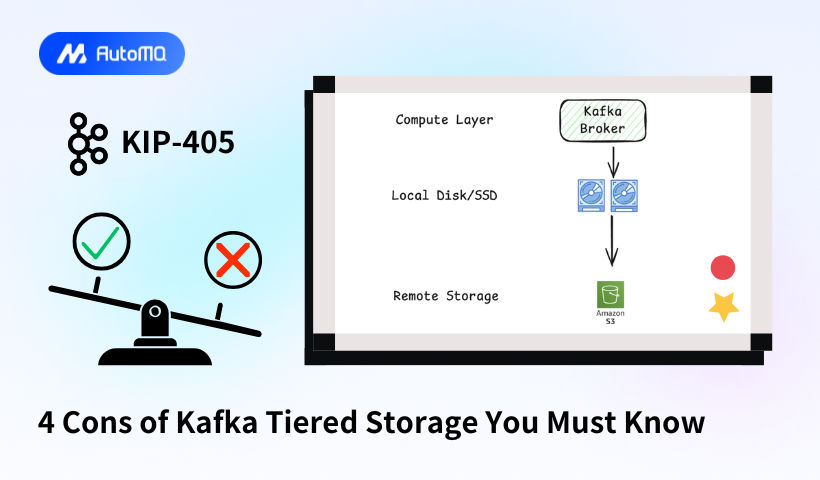
Apache Kafka KIP-405 [1] introduced the tiered storage concept, released in Kafka 3.9. The core principle is to persist only recent data on local disks while asynchronously moving historical data to cost-efficient object storage.
Kafka's legacy architecture stores all data locally on disks. This design was optimized for on-premises data centers over a decade ago, now misaligned with cloud-native demands. KIP-405 highlights three key drivers for tiered storage:
Long-Term Data Management : Many users treat Kafka as long-term storage. While Kafka clusters scale by adding brokers, this introduces redundant memory/CPU resources, making storage costs less efficient compared to offloading older data to external storage. Larger clusters with more nodes also increase deployment complexity and operational overhead.
Operational Burden
Cluster scaling/recovery required full data replication between brokers
Node failures in large clusters (100+ nodes) caused prolonged recovery times
Local disk reduction became impractical due to retention policies
Cloud Economics
High-capacity disk configurations from on-premises environments lack cloud-equivalent options
Cloud-optimized instance types prioritize compute over storage capacity
Tiered Storage is undoubtedly a major advancement in Kafka’s recent updates, but it’s not without limitations. Let’s unpack its shortcomings.
Evolution of Kafka Storage

Shared Nothing Architecture
Apache Kafka originally implemented a classic Shared Nothing architecture. In this design, each node operates independently with dedicated local storage and compute resources. While delivering high performance and low latency, this approach introduces several critical limitations:
Tight Compute-Storage Coupling: The architecture binds compute and storage resources together. Each Kafka broker handles both data storage and processing tasks. This interdependence forces simultaneous scaling of compute and storage resources, reducing operational flexibility.
Expensive Local Storage : Local storage costs escalate quickly in cloud environments, particularly with high-performance SSDs. Large-scale Kafka clusters storing massive datasets face significant infrastructure expenses.
Operational Complexity at Scale : Cluster expansion becomes increasingly cumbersome as data volumes grow. Adding brokers and rebalancing partitions requires manual intervention, introducing operational overhead and potential errors. Larger clusters also amplify maintenance challenges.
Cloud-Native Limitations : On-premises Kafka deployments typically use high-capacity disks to optimize I/O throughput and meet data retention needs. Cloud environments lack cost-effective equivalents for these storage-heavy configurations. Instead, cloud-optimized SKUs with reduced local storage prove more practical for Kafka broker nodes in distributed systems.
Tiered Storage Architectures
Cloud Kafka providers like Confluent and Aiven employ tiered storage to mitigate some limitations of Kafka's shared-nothing architecture. However, this solution only partially addresses the core challenges.
The "partial" designation stems from tiered storage preserving Kafka's original architecture, which was optimized for on-premises data centers rather than cloud environments. Key unresolved issues include:
Persistent ISR Replication Costs : The architecture still depends on Kafka's ISR (In-Sync Replica) replication for data durability. This approach generates substantial cross-availability-zone network traffic in cloud deployments, increasing operational costs.
Local Storage Dependency : While tiered storage reduces local disk consumption, brokers still require local storage for active data processing. This keeps local disks in the critical I/O path, maintaining performance dependencies.
Operational Overhead : Scaling operations remain complex. Partition replication workflows and synchronization between local storage and remote storage continue to introduce management overhead.
Shared Storage Architectures

WarpStream and AutoMQ both implement shared-storage architectures but take fundamentally different approaches. WarpStream adopts a minimalist architecture by storing all data directly on object storage. While this simplifies the system design, it comes at the cost of higher latency.
AutoMQ presents a more sophisticated implementation within the same architectural paradigm. Rather than rebuilding system components from scratch, it maintains full compatibility with the Apache Kafka ecosystem by preserving the original compute layer while completely re-architecting the storage layer. This strategic alignment ensures 100% Kafka API compatibility - a critical advantage over WarpStream's Go-based implementation that introduces compatibility gaps.
The system achieves its architectural breakthrough through innovative storage engine design. AutoMQ implements Elastic Block Store (EBS) as its write-ahead log (WAL), leveraging three key EBS characteristics:
Ultra-low latency data writes
High-throughput processing capabilities
Native cloud infrastructure integration
This approach enables AutoMQ's shared-storage implementation to maintain strict latency SLAs comparable to traditional local storage architectures[4].
4 Tiered Storage Cons You Must Know
Tiered Storage represents a significant leap forward compared to Kafka’s traditional shared-nothing architecture. However, as a solution still reliant on local disks, it is viewed as a transitional phase toward true shared storage architectures. If you plan to adopt Tiered Storage, be aware of its limitations:
No Out-of-the-Box Support in Apache Kafka: Apache Kafka provides only a Tiered Storage framework—you must implement the
RemoteStorageinterface yourself. Efficiently accessing object storage and managing data across local and remote tiers remains untenable for most organizations. The feature is locked behind paid offerings like Aiven, Confluent, and MSK. In contrast, AutoMQ’s shared storage implementation is open-source and production-ready. You can download and explore it directly on GitHub[5].High Operational Complexity Persists: Tiered Storage mitigates—but doesn’t resolve—inherent pain points of shared-nothing architectures. Issues like partition migration during scaling, data replication, and hotspots remain unresolved. Additionally, managing remote storage introduces new complexities: configuring local/remote data retention policies, monitoring hybrid storage health, and handling edge cases amplify operational overhead.
Slow Scaling Workflows: Compared to shared storage-based systems like WarpStream and AutoMQ, Kafka’s scaling efficiency with Tiered Storage still depends on local data volume. Large local datasets prolong scaling cycles. AutoMQ’s stateless brokers, powered by shared storage, enable instant scaling and seamless integration with Kubernetes autoscaling, spot instances, and cloud-native infrastructure.
Unavoidable Network Costs: As highlighted in WarpStream’s blog[3], shared storage systems like AutoMQ and WarpStream eliminate cross-AZ network costs entirely by leveraging S3. With Tiered Storage, ISR replication and producer traffic across availability zones incur significant network expenses—a critical cost factor for cloud deployments.
Summary
Tiered Storage undoubtedly marks a landmark advancement for the Kafka community, offering significant improvements over the traditional Shared Nothing architecture. However, from an architectural evolution perspective, it’s clear this isn’t the definitive future of Kafka’s storage design. Kafka's future lies in the cloud. The next-generation architecture must be cloud-built, leveraging cloud infrastructure as its foundation. Only a truly cloud-native elastic architecture can unlock the full cost efficiencies of cloud-scale operations.
References
[1] KIP-405: Kafka Tiered Storage
[2] 16 Ways Tiered Storage Makes Apache Kafka(®) Simpler, Better, and Cheaper: https://aiven.io/blog/16-ways-tiered-storage-makes-kafka-better
[3] Tiered Storage Won’t Fix Kafka: https://www.warpstream.com/blog/tiered-storage-wont-fix-kafka
[4] AutoMQ vs. WarpStream https://www.automq.com/blog/automq-vs-warpstream
[5] AutoMQ Github: https://github.com/AutoMQ/automq
[6] Zero-Disk Architecture: The Future of Cloud Storage Systems: https://www.pracdata.io/p/zero-disk-architecture-the-future