


.png)
Overview
Apache Kafka stands out in the data streaming world for its exceptionally high throughput capabilities. This distributed streaming platform can process millions of messages per second while maintaining low latency, making it the backbone of modern data architectures. This blog explores the architectural design decisions, optimization techniques, and configuration parameters that enable Kafka's impressive performance.
Core Architectural Elements Driving Kafka's Throughput
Kafka's architecture is fundamentally designed for high throughput through several key structural elements that work together to create an efficient data pipeline.
Distributed Architecture
Kafka operates as a distributed system that horizontally scales by adding more brokers to a cluster. This design allows Kafka to handle increasing volumes of data by distributing the processing load across multiple nodes. Each broker contributes its resources to the overall system capacity, enabling linear scalability that directly translates to higher throughput potential.
Partitioned Log Model
At the heart of Kafka's architecture is the partitioned log model. Topics are divided into partitions that can be distributed across different brokers in the cluster. This partitioning enables parallel processing of data, as producers can write to different partitions concurrently while consumers read from them simultaneously. Each partition represents a unit of parallelism, meaning more partitions typically result in higher throughput capability.

Zero-Copy Data Transfer
Perhaps one of the most significant technical innovations in Kafka is its implementation of zero-copy data transfer. Traditional data transfer methods involve multiple data copies between the disk, kernel buffer, application buffer, and socket buffer, requiring four copies and four context switches. Kafka's zero-copy approach eliminates unnecessary copying by allowing data to flow directly from disk to network interface, reducing this to just two copies and two context switches.
This optimization significantly reduces CPU utilization and eliminates system call overhead, allowing Kafka to achieve much higher throughput with the same hardware resources. The direct data flow from page cache to network interface card (NIC) buffer enables Kafka to handle massive volumes of data efficiently.

Zero-Copy Implementation in Kafka
Zero-copy in Kafka is implemented through Java NIO's memory mapping (mmap) and the sendfile system call. These mechanisms optimize data transfer between disk and network by minimizing intermediate copies.
Memory Mapping (mmap)
Memory mapping allows direct access to kernel space memory from user space, eliminating the need for explicit data copying between these spaces. This approach is particularly effective for transferring smaller files and supports random access patterns.

Sendfile System Call
For larger file transfers, Kafka leverages the sendfile system call (introduced in Linux 2.1), which directly transfers data between file descriptors. In Java, this is implemented through the FileChannel's transferTo method.
The combination of these approaches means Kafka can move data from disk to network with minimal CPU involvement, allowing it to maintain high throughput even under heavy loads.
Producer Optimizations for Maximizing Throughput
Proper configuration of Kafka producers plays a crucial role in achieving high throughput. The following parameters are particularly important:
Batching Strategy
Kafka producers can batch multiple messages together before sending them to brokers, which dramatically reduces network overhead. Two key configuration parameters control this behavior:

Increasing the batch size allows producers to accumulate more messages in a single request, significantly improving throughput by reducing the number of network round trips. The linger time parameter gives producers more time to fill these batches, optimizing network usage even further.
Compression Configuration
Message compression reduces both network bandwidth usage and storage requirements:

Enabling compression (particularly lz4 or zstd) can significantly increase effective throughput by reducing the amount of data that needs to be transferred over the network. The choice of compression algorithm should balance compression ratio with CPU overhead.
Acknowledgment Settings
The acknowledgment level (acks) determines how producers confirm message delivery:

Setting acks=1 provides a good balance between throughput and data durability for most use cases.
Broker Configurations That Enhance Throughput
Broker-side optimizations are equally important for maintaining high throughput:
Threading and Request Processing
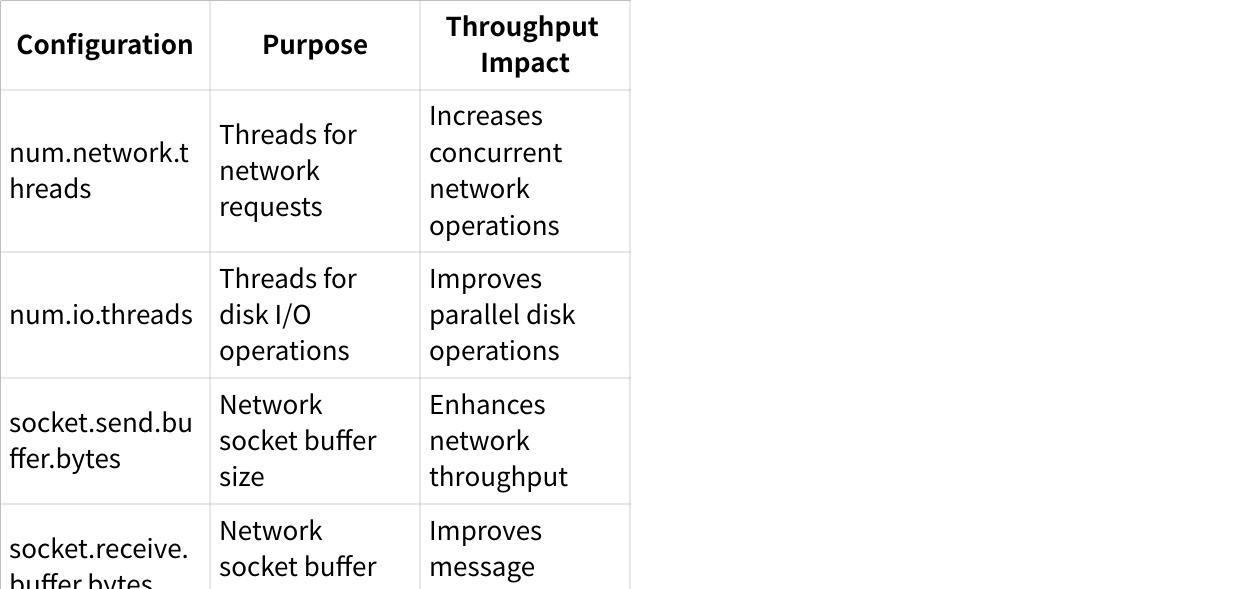
Increasing the number of network and I/O threads allows brokers to handle more requests concurrently, directly improving throughput potential.
Log Management

Proper log segment configuration helps optimize disk I/O operations, which can significantly impact overall throughput.
Consumer Configuration for Optimal Throughput
Consumer settings also play an important role in throughput optimization:
Fetch Configuration

Increasing fetch.min.bytes reduces the number of fetch requests, improving overall throughput by making better use of network resources.
Consumer Parallelism
Kafka allows one consumer per partition within a consumer group. To maximize throughput, it's important to configure enough partitions to allow for sufficient consumer parallelism. This enables horizontal scaling of consumption by adding more consumer instances.
Hardware and Network Considerations
Physical infrastructure significantly impacts Kafka's throughput capabilities:
Storage Optimization
Using solid-state drives (SSDs) rather than traditional hard disk drives provides faster I/O operations, reducing latency and improving throughput. For extremely high-throughput scenarios, NVMe drives offer even better performance.
Network Infrastructure
Network capacity often becomes the bottleneck in high-throughput Kafka deployments. High-speed network interfaces (10 GbE or higher) are recommended for production environments. The impact of network latency is substantial—even small increases in network latency can significantly reduce throughput.
Network Latency Effects on Throughput
Network latency directly affects how many batches can be processed per second. For example, with a round-trip latency of 10ms, throughput is limited to approximately 100 batches per second per thread just from network constraints alone. Reducing network latency through proper infrastructure and configuration is therefore critical for high-throughput applications.
Common Throughput Issues and Solutions
Several common issues can limit Kafka's throughput potential:
Consumer Lag
When consumers cannot keep up with the rate of production, consumer lag occurs. Solutions include:
Increasing the number of partitions to allow more parallel consumption
Adding more consumer instances to process data more quickly
Optimizing consumer processing logic to reduce processing time per message
Broker Overload
When brokers become overloaded, throughput suffers across the entire system. Remedies include:
Adding more brokers to the cluster to distribute load
Ensuring adequate CPU, memory, and disk resources for existing brokers
Better distributing partitions across brokers to avoid hotspots
Conclusion: Why Kafka Achieves High Throughput
Kafka's exceptional throughput is the result of multiple deliberate design decisions working in concert:
The distributed, partitioned architecture enables parallel processing and horizontal scaling
Zero-copy data transfer minimizes CPU overhead and maximizes data movement efficiency
Batching and compression optimize network utilization
Configurable producer, broker, and consumer settings allow fine-tuning for specific use cases
Log-based storage provides sequential I/O patterns that are highly efficient
By understanding and optimizing these aspects, organizations can leverage Kafka's full throughput potential to build high-performance data streaming applications that process millions of messages per second with minimal latency.
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
JD.comx AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging






