
对比结论
- 相比 Apache Kafka 300 倍的分区迁移效率: AutoMQ 分区迁移速度相比 Apache Kafka 提升约 300 倍。AutoMQ 将 Kafka 高风险的常规运维动作,变成了可自动化,基本无感的低风险运维操作。
- 4min 从零到 1GiB/s 的极致弹性: AutoMQ 集群自动应急弹性从 0 MiB/s 到 1 GiB/s 仅需 4 分钟。它使得系统可以快速扩容响应突发流量。
- 相比 Apache Kafka 200 倍的冷读效率: AutoMQ 读写分离,相比 Apache Kafka 发送耗时降低 200 倍,追赶吞吐提高 5 倍。AutoMQ 可以轻松的应对在线消息削峰填谷和离线批处理的场景。
测试准备
配置参数
AutoMQ 默认数据强刷盘再响应,使用配置如下:机器规格
从成本效益来说,小规格机型 + EBS 比带 SSD 的大规格机器更优。 以小规格 r6in.large + EBS vs. 大规格 i3en.2xlarge + SSD 为例:- i3en.2xlarge,8 核,64 GB 内存,网络基准带宽 8.4 Gps,自带两块 2.5 TB 的 NVMe SSD,硬盘最大吞吐 600 MB/s;价格 $0.9040/h。
- r6in.large * 5 + 5 TB EBS,10 核,80GB 内存,网络基准带宽 15.625 Gbps,EBS 基准带宽 625 MB/s;价格 (计算)0.1743 * 5 + (存储)0.08 * 5 * 1024 / 24 / 60 = $1.156/h。
- r6in.large:2 核,16 GB 内存,网络基准带宽 3.125 Gbps,EBS 基准带宽 156.25 MB/s;价格 $0.1743/h。
- GP3 EBS:免费额度 3000 IOPS,125 MB/s 带宽;价格 存储 0.040 MB/s 每月,额外 IOPS $0.005 每月。
- AutoMQ 用 EBS 作为写入缓冲区,因此 EBS 只需配置 3 GB 存储空间,IOPS 和带宽使用免费额度即可。
- Apache Kafka 数据都存储在 EBS 上,EBS 空间由具体测试场景的流量和保存时间决定。额外购买 EBS 带宽 31 MB/s,进一步提高 Apache Kafka 的单位成本吞吐。
秒级分区迁移
在生产环境中,一个 Kafka 集群通常会服务多个业务,业务的流量波动和分区分布可能造成集群容量不足或者机器热点,Kafka 运维人员需要通过集群扩容,并且将热点分区迁移到空闲的节点,来保障集群的服务可用性。 分区迁移的时间决定了应急和运维效率:- 分区迁移的时间越短,集群从扩容到容量满足诉求的时间越短,服务受损的时间越短。
- 分区迁移越快,运维人员观测的时间更短,可以更快的得到运维反馈决策后续的动作。
300x 效率提升,AutoMQ 相比 Apache Kafka 30 GiB 分区迁移耗时从 12min 下降到 2.2s。
测试
本测试测量 AutoMQ 和 Apache Kafka 在带日常发送消费流量场景下,迁移一个具备 30 GiB 数据的分区到一个不存在该分区副本的节点的迁移耗时和影响。具体的测试场景为:-
2 台 r6in.large 作为 broker,在其上创建:
- 1 个单分区单副本的 Topic A,并以 40 MiB/s 吞吐持续读写。
- 1 个 4 分区单副本的 Topic B,并以 10 MiB/s 吞吐持续读写,作为背景流量。
- 13 分钟后,将 Topic A 的唯一一个分区迁移到另一个节点,迁移吞吐限制 100 MiB/s。
Apache Kafka 每台 broker 额外分别挂载一块 320GB 156MiB/s gp3 EBS 用于存储数据。
| 对比项 | AutoMQ | Apache Kafka |
|---|---|---|
| 迁移耗时 | 2.2s | 12min |
| 迁移影响 | 最大发送延时 2.2s | 12min 内持续发送耗时 1ms ~ 90ms 抖动 |
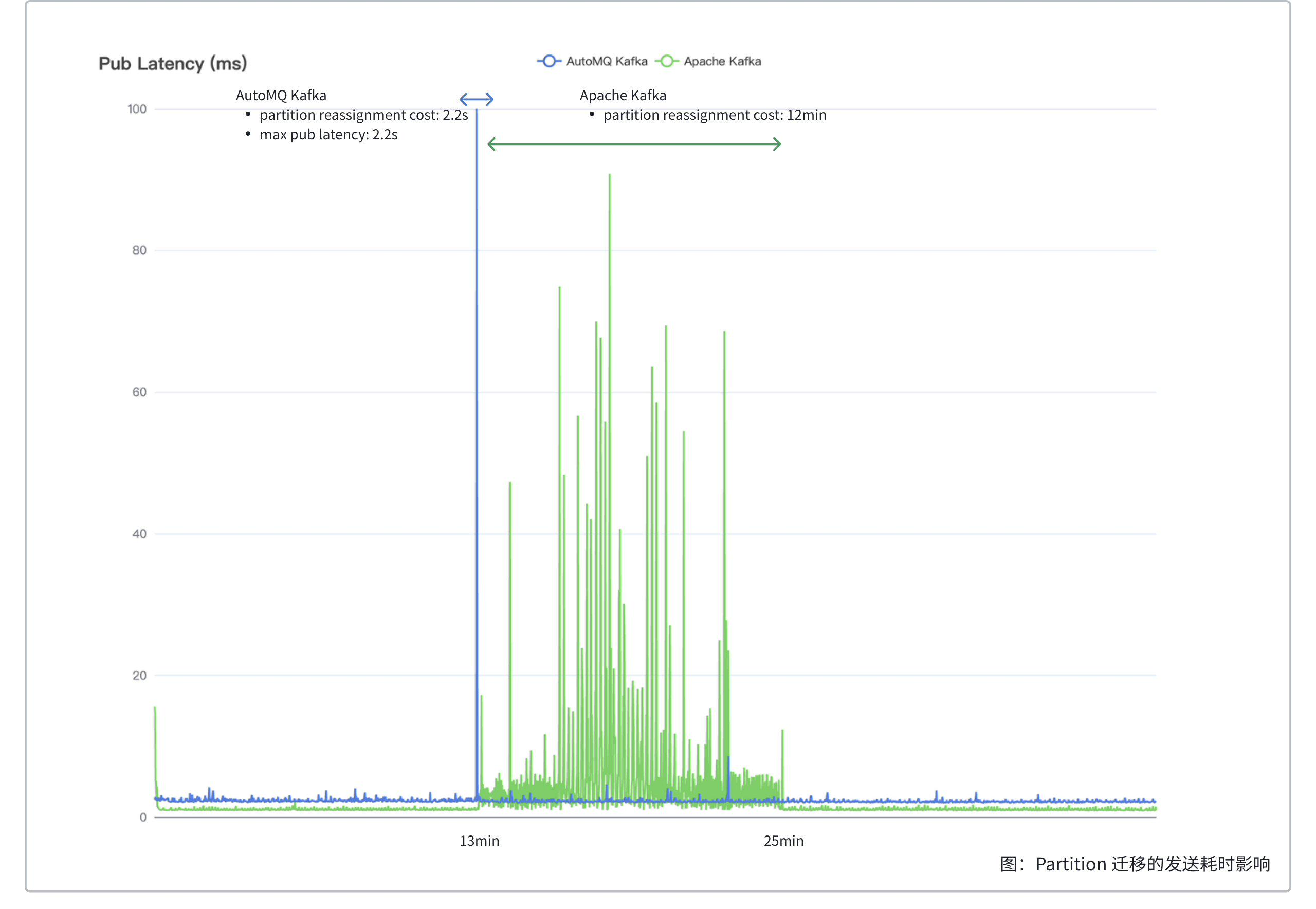
分析
AutoMQ 分区迁移只需要将 EBS 中缓冲的数据上传到 S3 即可在新的节点安全打开,500 MiB 的数据通常在 2 秒内即可完成上传。AutoMQ 分区的迁移耗时和分区的数据量无关,分区迁移时间平均下来在 1.5 秒左右。AutoMQ 分区在迁移过程中向客户端返回 NOT_LEADER_OR_FOLLOWER 错误码,在迁移完成后客户端更新到新的 Topic 路由表,客户端内部重试发送到新的节点,因此该分区的此刻的发送延迟会上涨,迁移完成后恢复到日常水位。 Apache Kafka 分区迁移需要将分区的副本拷贝到新的节点,拷贝历史数据的同时还要追赶新写入的数据,迁移的耗时 = 分区数据量 / (迁移吞吐限制 - 分区写入吞吐),在实际生产环境中,分区迁移往往是小时级的,本测试中的 30 GiB 的分区迁移耗时就到了 12 分钟。除了迁移耗时长以外,Apache Kafka 迁移需要从硬盘读取冷数据,即使在设置了 throttle 的情况下,仍旧会因为抢占 page cache 导致发送延迟的抖动,影响服务质量,体现在图中为绿色曲线抖动的部分。0 -> 1 GiB/s 极致弹性
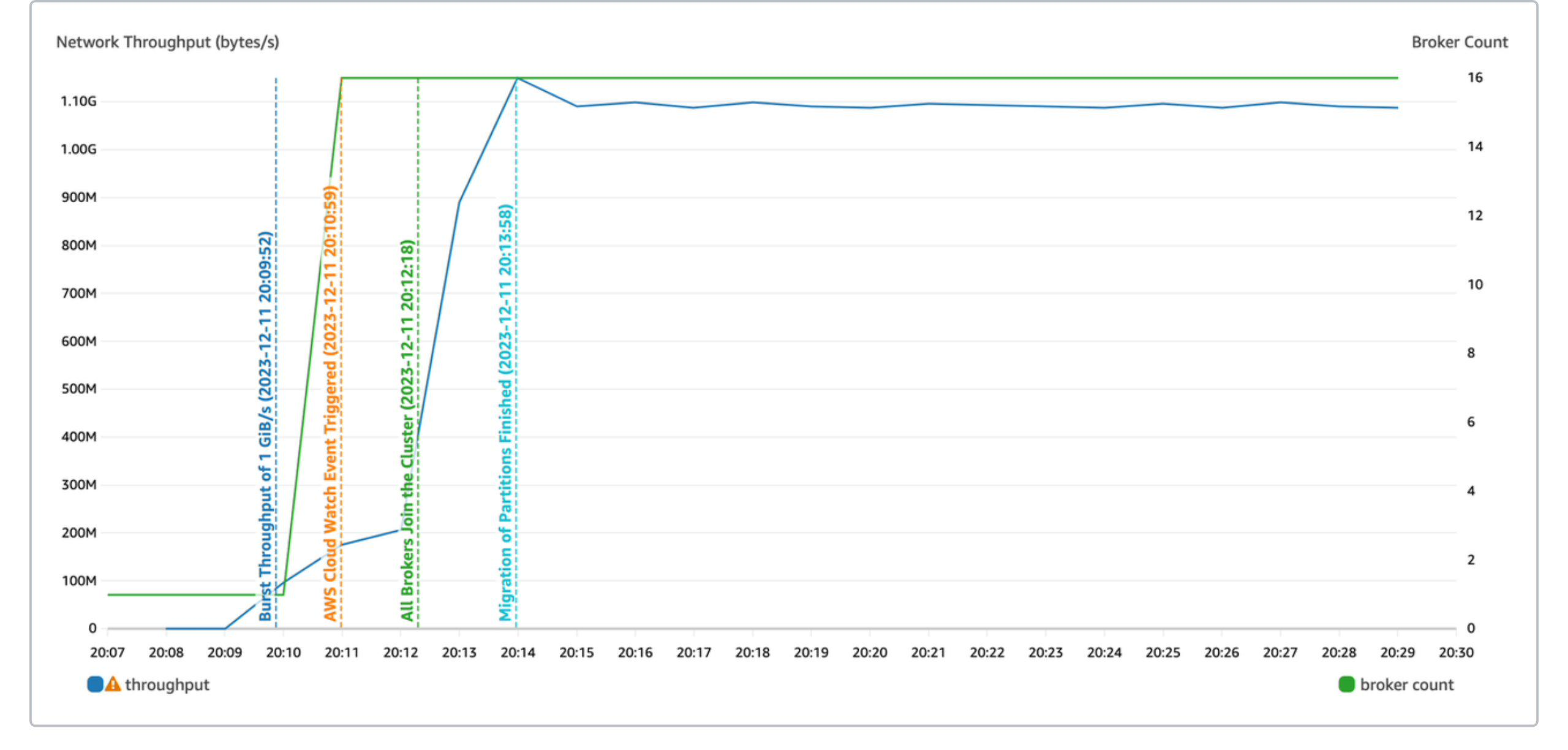
Kafka 运维人员通常会根据历史经验准备 Kafka 集群容量,然而总会有一些非预期中的热门事件和活动导致集群流量陡增。这时候就需要快速的将集群扩容并重平衡分区,来应对突发流量。极致弹性,AutoMQ 集群应急弹性从 0 MiB/s 扩展到 1 GiB/s 仅需 4 分钟。
测试
本测试的目的是测量 AutoMQ 的应急弹性功能从 0 MiB/s 到 1 GiB/s 的弹性速度。具体的测试场景为:- 集群初始只有 1 个 Broker,设置应急弹性容量为 1 GiB/s,创建一个 1000 分区的 Topic。
- 启动 OpenMessaging 直接将发送流量设置为 1 GiB/s。
| 分析项 | 监控报警 | 批量扩容 | Auto Balancing | 总计 |
|---|---|---|---|---|
| 0 -> 1 GiB/s 弹性耗时 | 70s | 80s | 90s | 4min |
追赶读(Catch-up Read)
追赶读是消息和流系统常见的场景:- 对于消息来说,消息通常用作业务间的解耦和削峰填谷。削峰填谷要求消息队列能将上游发送的数据堆积住,让下游慢慢的消费,这时候下游追赶读的数据都是不在内存中的冷数据。
- 对于流来说,周期性的批处理任务需要从几个小时甚至一天前的数据开始扫描计算。
- 额外还有故障场景:消费者宕机故障若干小时后恢复重新上线;消费者逻辑问题,修复后,回溯消费历史数据。
- 追赶读的速度:追赶读速度越快,消费者就能更快从故障中恢复,批处理任务就能更快产出分析结果。
- 读写的隔离性:追赶读需要尽量不影响生产的速率和延时。
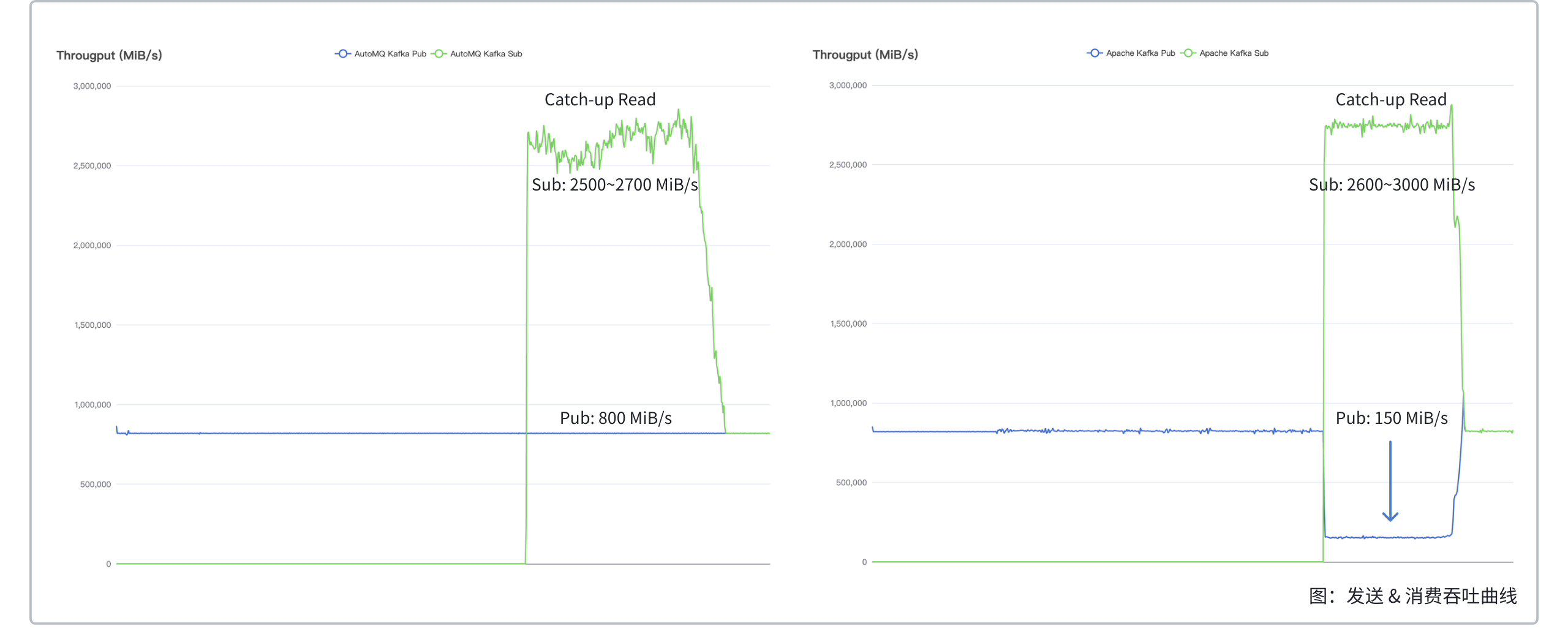
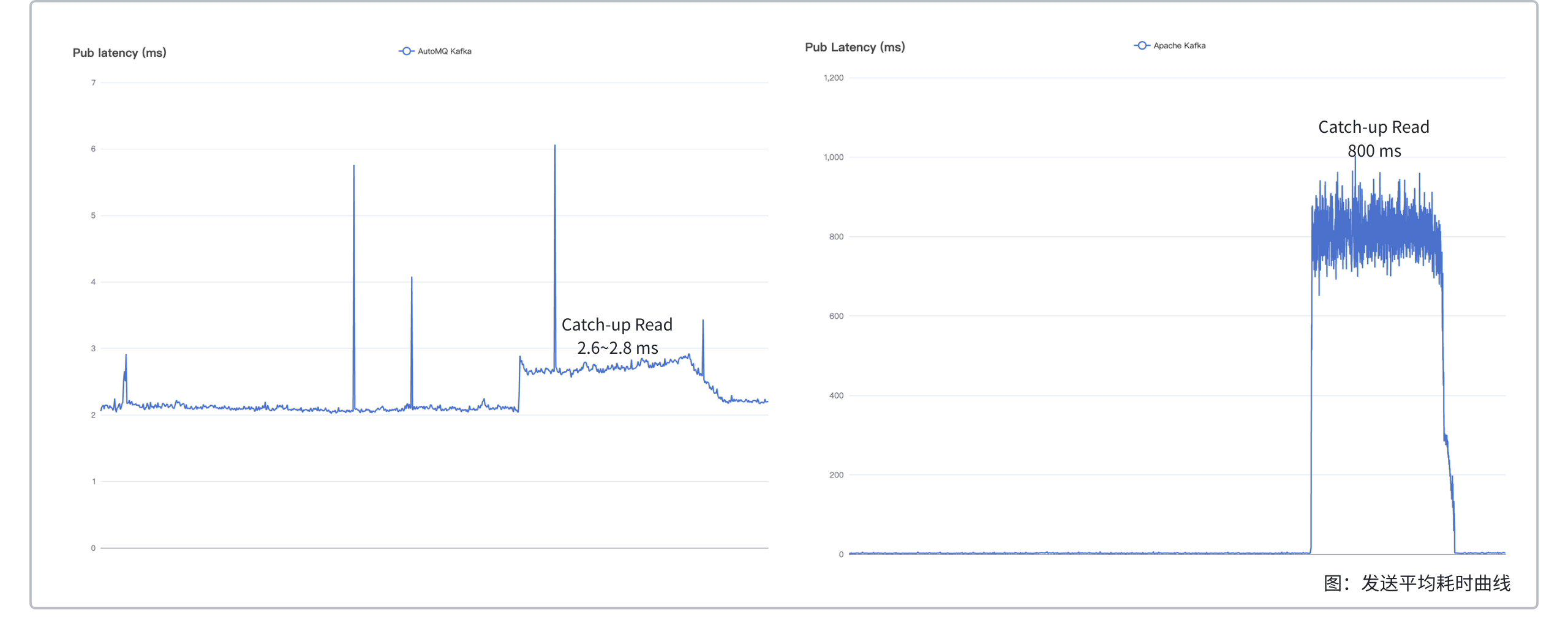
200x 效率提升,AutoMQ 读写分离相比 Apache Kafka 在追尾读场景,发送耗时从 800ms 下降到 3ms,追赶时间从 215 min 缩短到 42 min。
测试
本测试测量 AutoMQ 和 Apache Kafka 在相同集群规模下的追赶读性能,测试场景如下:- 集群部署 20 台 Broker,创建 1 个 1000 分区的 Topic。
- 以 800 MiB/s 的吞吐持续发送。
- 在发送 4 TiB 数据后,拉起消费者,从最早的位点开始消费。
Apache Kafka 每台 broker 额外分别挂载一块 1000GB 156MiB/s gp3 EBS 用于存储数据。
| 对比项 | 追赶读过程中发送耗时 | 追赶读过程中对发送流量影响 | 追赶读峰值吞吐 |
|---|---|---|---|
| AutoMQ | 小于 3ms | 读写隔离,维持 800 MiB/s | 2500 ~ 2700 MiB/s |
| Apache Kafka | 大约 800ms | 相互影响,下跌到 150 MiB/s | 2600 ~ 3000 MiB/s (牺牲写入) |
分析
- 相同集群规模下,在追赶读时,AutoMQ 的发送流量没有受到任何影响,而 Apache Kafka 的发送流量下降了 80%。这是由于,Apache Kafka 在追赶读时会读取硬盘,且没有做 IO 隔离,这占用了 AWS EBS 的读写带宽,导致写硬盘带宽减少,发送流量下降;作为对比,AutoMQ 读写分离,在追赶读时不会读硬盘,而是读对象存储,不会占用硬盘读写带宽,也就不会影响发送流量。
- 相同集群规模下,在追赶读时,相较于仅发送,AutoMQ 的平均发送延迟上升了约 0.4 ms,而 Apache Kafka 则飙升了约 800 ms。Apache Kafka 发送延迟升高有两方面原因:其一是前文提到的,追赶读会占用 AWS EBS 读写带宽,这会导致写入流量下降、延迟升高;其二是追赶读时,读硬盘中的冷数据会污染 page cache,同样会导致写入延迟升高。
-
值得说明的是,在追赶读 4 TiB 数据时,AutoMQ 花费了 42 min,Apache Kafka 花费了 29 min。Apache Kafka 耗时更短的原因有两个:
- 追赶读时,Apache Kafka 的发送流量下降了 80%,使得它需要追赶的数据变少。
- Apache Kafka 并没有 IO 隔离,牺牲了发送速率来提升读取速率。
- 假设追赶读时 Apache Kafka 发送速率为 700 MiB/s,考虑三副本写入占用 EBS 带宽为 700 MiB/s * 3 = 2100 MiB/s。
- 而集群中的 EBS 总带宽为 156.25 MiB/s * 20 = 3125 MiB/s。
- 可用于读取的带宽为 3125 MiB/s - 2100 MiB/s = 1025 MiB/s。
- 在一边发送一边读取的追赶读场景下,读取 4TiB 数据需耗时 4 TiB * 1024 GiB/TiB * 1024 MiB/GiB / (1025 MiB/s - 700 MiB/s) / 60 s/min = 215 min。
总结
本次基准测试展现出 AutoMQ 在基于云重塑 Kafka 后相比 Apache Kafka 在效率提升和成本节约上均有不错的优化:- 在分区迁移场景,AutoMQ 30GB 分区迁移时间从 Apache Kafka 12 分钟 下降到 2.2 秒,达到了 300x 效率提升。
- 极致弹性,AutoMQ 0 -> 1 GiB/s 仅需 4 分钟就能 Scale-out 满足目标容量。
- 在历史数据追赶读场景,AutoMQ 读写分离不仅平均发送延时有 200 倍的优化从 800ms 下降到 3ms,而且追赶读吞吐是 Apache Kafka 的 5 倍。
其他补充说明
- AutoMQ 支持使用 AWS Graviton 的机型,该性能对比结果针对支持 Graviton 的机型同样适用。
- 云资源成本对比时 AWS 环境 Apache Kafka 存在跨可用区传输流量费用,AutoMQ 可以通过跨可用区路由组件消除跨可用区传输流量。具体参考使用 AutoMQ 节省跨 AZ 流量费用▸