.png)
Overview
This detailed analysis compares Apache Kafka and ZeroMQ, two powerful but fundamentally different messaging systems used in distributed computing. While both technologies enable communication between distributed components, they differ significantly in architecture, performance characteristics, and use cases.
Architecture and Core Concepts
Apache Kafka
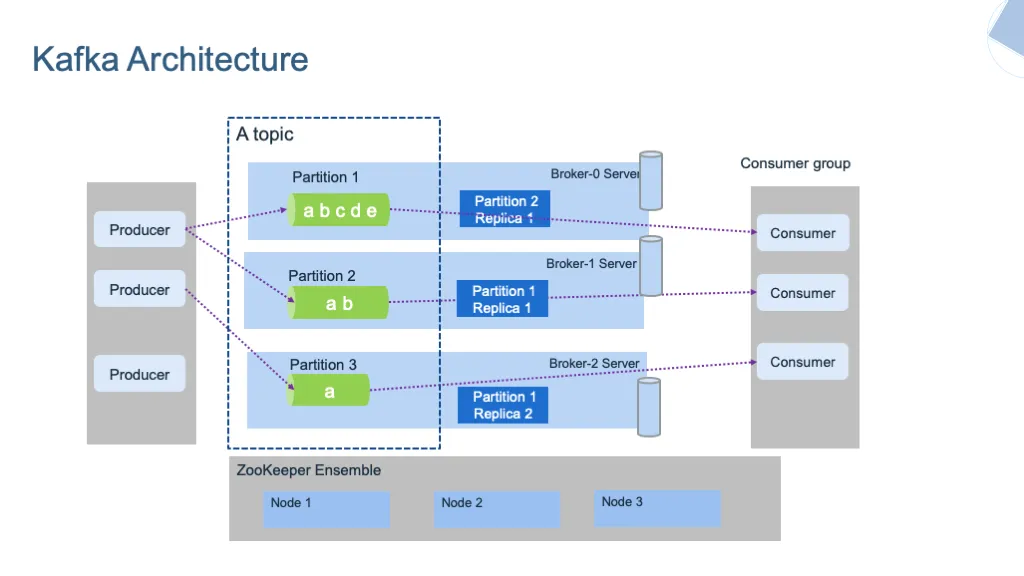
Kafka is a distributed event streaming platform built with a broker-based architecture. It maintains a cluster of servers (brokers) that store streams of records in categories called topics[1]. Kafka was initially developed by LinkedIn and later became an Apache open-source project.
Key architectural components include:
Brokers : Servers that store messages and serve client requests
Topics : Categories for message streams, divided into partitions
Partitions : Ordered, immutable sequence of records
ZooKeeper : Manages broker metadata (being phased out with KIP-500)[6]
Producers : Applications that publish data to topics
Consumers : Applications that subscribe to topics and process data
ZeroMQ
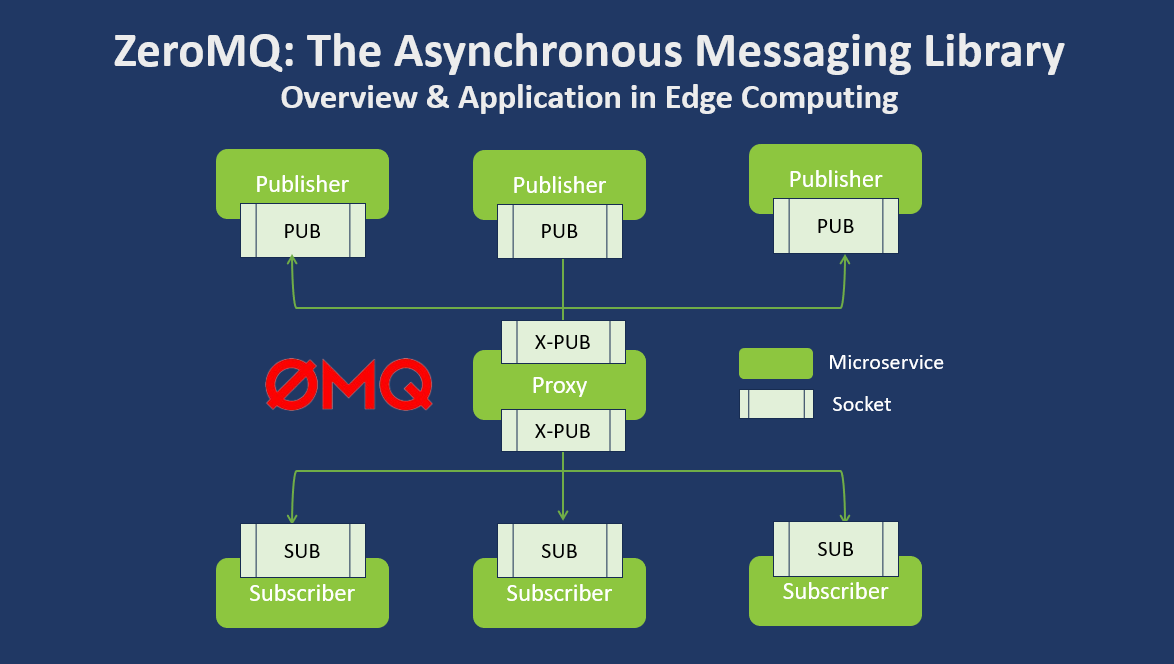
ZeroMQ (also written as ØMQ or 0MQ) is a high-performance asynchronous messaging library designed for use in distributed or concurrent applications[4]. Unlike Kafka, ZeroMQ operates without a central broker.
Core components include:
Sockets : Communication endpoints with various patterns
Patterns : Communication models like request-reply, publish-subscribe, push-pull
Transport Protocols : TCP, IPC, PGM, TIPC, and others[13]
No Central Broker : Direct peer-to-peer communication
Fundamental Differences
| Feature | Apache Kafka | ZeroMQ |
|---|---|---|
| Architecture | Distributed, broker-based | Brokerless library |
| Persistence | Built-in, durable storage | No built-in persistence |
| Message Ordering | Strict ordering within partitions | Limited ordering guarantees |
| Data Distribution | Publish-subscribe with replication | One-to-one or one-to-many patterns |
| Complexity | More complex with multiple components | Lightweight, simple deployment |
| Community Support | Large, enterprise-backed | Active but smaller community |
System Characteristics
Persistence and Durability
Kafka is designed with data persistence as a core feature. It stores all messages on disk, enabling reliable message replay and fault tolerance[1]. This persistent storage is what makes Kafka particularly well-suited for event streaming applications where data loss is unacceptable.
ZeroMQ, by contrast, prioritizes low-latency message delivery without built-in persistence. Messages are typically lost if not immediately consumed, requiring developers to implement their own persistence mechanisms if needed[1][4].
Scalability Model
Kafka achieves high scalability through its partition-based design. Each topic can be divided into multiple partitions distributed across different brokers, allowing multiple consumers to read messages simultaneously[1].
ZeroMQ offers a different scaling model based on distributed patterns. It's designed for smaller-scale deployments or scenarios requiring extremely low latency[1]. As a socket library rather than a complete messaging system, ZeroMQ requires developers to implement their own reliability and scaling mechanisms.
Performance Characteristics
Throughput
Kafka is known for its exceptional throughput capabilities. According to benchmarks from Confluent, Kafka can achieve throughput rates of up to 605 MB/s, significantly outperforming other messaging systems like RabbitMQ (38 MB/s) and Pulsar (305 MB/s)[6].
ZeroMQ, designed for minimal overhead, can achieve extremely high message rates, often hundreds of thousands per second[7]. In certain configurations, ZeroMQ has been shown to process 10,000 messages in approximately 15 milliseconds, compared to RabbitMQ's 1 second for the same workload[9].
Latency
Kafka provides consistent latency even at high throughput. At 200 MB/s throughput, Kafka demonstrates a p99 latency of approximately 5 ms[6].
ZeroMQ offers exceptionally low latency, often in microseconds, due to its minimal overhead and direct communication model. However, this comes at the cost of durability guarantees[7][9].
When to Use Kafka
Kafka excels in the following scenarios:
High-Volume Event Streams
Kafka is ideal for applications generating continuous streams of events such as user activity, website clicks, sensor data, logging events, or stock market updates[15].
Real-Time Analytics
Particularly valuable for building real-time data processing pipelines where data needs to be processed immediately upon arrival[15].
Durable Message Storage
When message persistence and replay capability are essential requirements, Kafka's log-based storage provides these guarantees[1][4].
Large-Scale Data Distribution
For scenarios requiring one-to-many distribution with high throughput and strong ordering guarantees[1].
When to Use ZeroMQ
ZeroMQ is better suited for:
Low-Latency Inter-Process Communication
Ideal for high-speed communication between processes or components within a distributed application[4][7].
Lightweight Messaging Requirements
When you need a simple messaging library without the overhead of a full messaging system[1].
Custom Messaging Patterns
ZeroMQ supports various messaging patterns (request-reply, publish-subscribe, push-pull) that can be combined to create custom topologies[4].
Resource-Constrained Environments
ZeroMQ's minimal resource footprint makes it suitable for environments where memory and processing power are limited[1][4].
Configuration Best Practices
Kafka Producer Configuration
For optimal Kafka producer performance, consider these best practices[5]:
Throughput Optimization
Balance batch size and linger time based on latency requirements
Implement compression to reduce data size and improve throughput
Use appropriate partitioning strategies for even data distribution
Error Handling
Implement robust retry mechanisms with exponential backoff
Enable idempotence for exactly-once processing semantics
Use synchronous commits for critical data and asynchronous for higher throughput
Key configuration parameters include:
## Batch optimization
batch.size=16384
linger.ms=5
## Reliability settings
acks=all
enable.idempotence=true
retries=10
retry.backoff.ms=100
delivery.timeout.ms=120000
Kafka Consumer Configuration
For reliable and efficient Kafka consumers[5]:
Partition Management
Choose the right number of partitions based on throughput requirements
Maintain consumer count consistency relative to partitions
Use a replication factor greater than 2 for fault tolerance
Offset Commit Strategy
Disable auto-commit (
enable.auto.commit=false) for critical applicationsImplement manual commit strategies after successful processing
Balance commit frequency to minimize reprocessing risk while maintaining performance
Key configuration parameters include:
## Group management
group.id=my-consumer-group
heartbeat.interval.ms=3000
max.poll.interval.ms=300000
## Offset management
enable.auto.commit=false
auto.offset.reset=earliest
max.poll.records=500
ZeroMQ Configuration
When working with ZeroMQ, consider these configuration approaches[7][13]:
Buffer Management
ZeroMQ uses high water marks (HWM) to control message buffering. When the HWM is reached, ZeroMQ will either block the sender or drop messages, depending on the socket type[7].
Socket Types
Choose the appropriate socket type based on your communication pattern:
REQ/REP : Request-reply pattern
PUB/SUB : Publish-subscribe pattern
PUSH/PULL : Pipeline pattern for distributing work
Error Handling
ZeroMQ does not provide built-in error recovery. Design your application to handle disconnections and reconnections gracefully[7][13].
Market Adoption
Apache Kafka has a significantly larger market share compared to ZeroMQ. According to 6Sense data, Kafka holds approximately 34.76% market share in the Queueing, Messaging, and Background Processing category, while ZeroMQ has about 1.61% market share[10].
Kafka is used by 16,684 customers compared to ZeroMQ's 774 customers, placing them at 1st and 9th place in their category, respectively[10].
Common Challenges and Solutions
Kafka Challenges
Complex Setup and Management
Kafka's distributed nature and dependency on ZooKeeper (though being phased out) increase operational complexity[1][6].
Solution : Consider using managed Kafka services like Confluent Cloud, or adopt Kafka distributions that simplify management.
Resource Requirements
Kafka clusters can be resource-intensive, requiring substantial memory and disk space[12].
Solution : Properly size your cluster based on expected throughput and retention requirements.
ZeroMQ Challenges
Message Loss
ZeroMQ doesn't guarantee message delivery by default, which can lead to data loss[1][7].
Solution : Implement your own reliability layer on top of ZeroMQ, using patterns described in the ZeroMQ guide.
Scalability Limitations
While ZeroMQ is fast, building large-scale, reliable systems requires significant custom development[1][7].
Solution : Consider using ZeroMQ for specific high-performance components within a larger system that may use other messaging technologies for different requirements.
Conclusion
The choice between Apache Kafka and ZeroMQ depends largely on your specific requirements:
Choose Kafka when you need high-throughput, durable, scalable message processing with strong ordering guarantees. Kafka excels at large-scale event streaming applications where reliability and fault tolerance are critical.
Choose ZeroMQ when you need extremely low-latency messaging with minimal overhead for inter-process communication. ZeroMQ is ideal for building lightweight, custom messaging patterns within applications.
Many organizations use both technologies for different components of their systems, leveraging each for its strengths. For instance, you might use ZeroMQ for internal component communication within a service while using Kafka for communication between services in a microservice architecture[1][8].
In some cases, as mentioned in Fred George's microservice architecture approach, these technologies can even be combined, with Kafka serving as a "high-speed bus" and ZeroMQ instances connected to it as "rivers," enabling a hybrid approach that leverages the strengths of both systems[8].
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
JD.comx AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging