


.png)
Overview
As organizations seek more efficient and cost-effective alternatives to Apache Kafka, two prominent solutions have emerged: AutoMQ and Redpanda. Both platforms aim to address Kafka's challenges while offering improved performance, cost savings, and operational simplicity. This report provides a detailed comparison of these alternatives, analyzing their architectures, performance characteristics, compatibility, and cost-effectiveness.
Architectural Foundations
AutoMQ: Cloud-Native Storage Separation
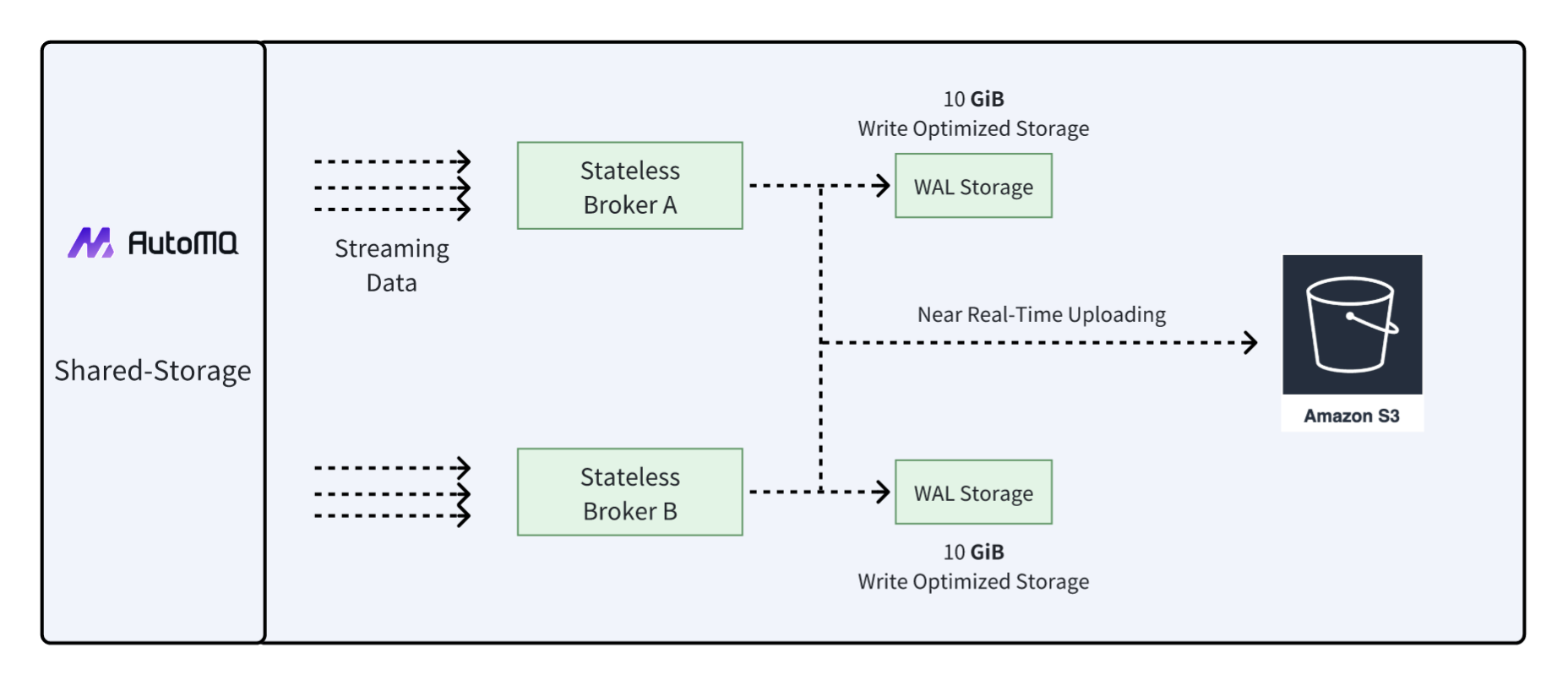
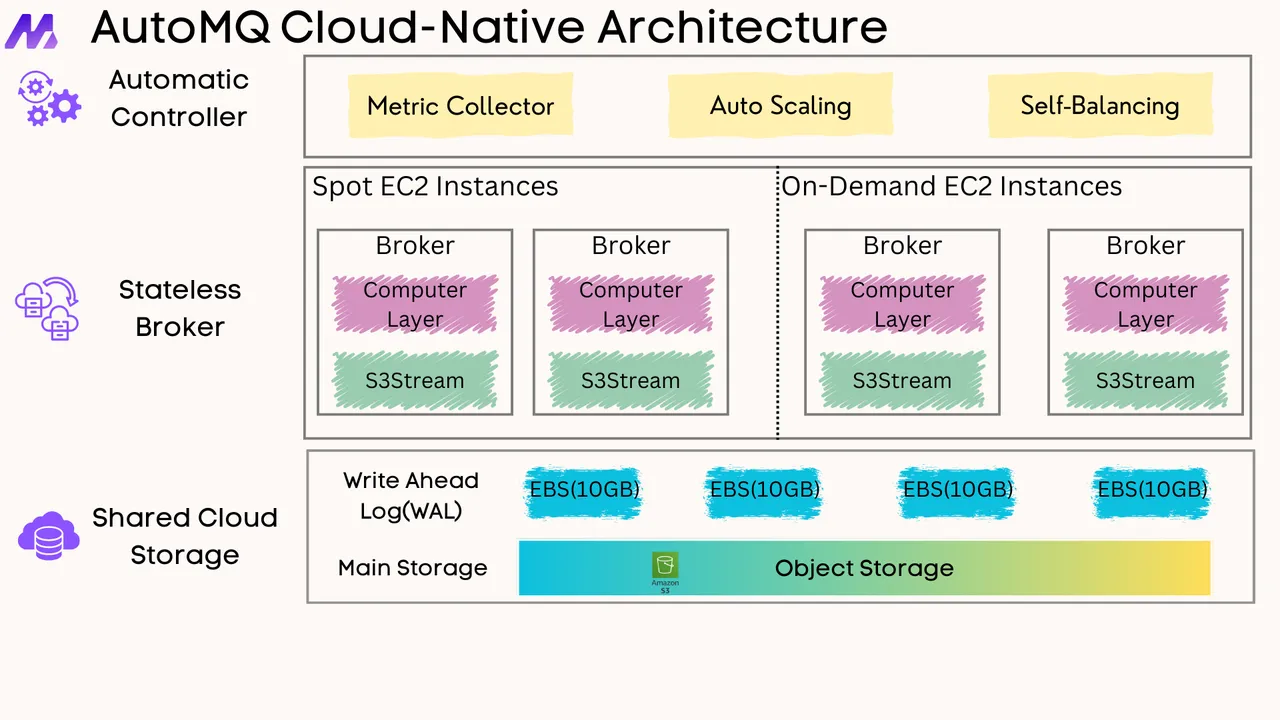
AutoMQ represents a fundamental reimagining of Kafka's architecture for cloud environments. Inspired by Snowflake, AutoMQ decouples compute from storage, leveraging shared cloud storage systems like Amazon S3 alongside stateless brokers[1][14].
This architectural approach allows AutoMQ to:
Offload data persistence entirely to cloud storage services
Maintain stateless brokers that can be quickly scaled
Eliminate expensive broker replication
Minimize cross-zone networking costs[3]
AutoMQ's architecture incorporates both Write-Ahead Logging (WAL) storage and object storage, storing all data in object storage in near real-time[13]. This shared storage architecture makes the entire broker node completely stateless, enabling operations like second-level partition reassignment and automatic scaling[13].
Redpanda: Modern C++ Implementation
Redpanda takes a different approach, completely rewriting Kafka in C++ while maintaining protocol compatibility[10][11]. This implementation eliminates dependencies on JVM and ZooKeeper, resulting in:
Thread-per-core parallelism with CPU core pinning
Elimination of lock contention and context switching
Removal of JVM garbage collection overhead
Replacement of ZooKeeper with Raft consensus
Single-binary deployment[8][17]
Redpanda retains a more traditional architecture compared to AutoMQ, still relying primarily on local storage for performance, though its Enterprise edition offers tiered storage capabilities[17][18].
Performance Characteristics
Latency and Throughput
Both systems claim significant performance improvements over Apache Kafka, but with different benchmarks:
| Metric | AutoMQ | Redpanda | Apache Kafka |
|---|---|---|---|
| Publisher Latency (P99) | Single-digit ms[13] | Claims 10x faster than Kafka[17] | >620ms (under high load)[13] |
| Throughput Capacity | High with fewer machines[14] | Claims to handle 1GB/s with 3 nodes vs Kafka's 9 nodes[17] | Requires more nodes for equivalent throughput[17] |
| Resource Efficiency | Optimizes cloud resources | Maximizes hardware usage | Requires significant overprovisioning[1][17] |
Redpanda's performance advantages stem primarily from its C++ implementation and thread-per-core architecture, while AutoMQ achieves its performance through cloud-optimized storage separation and reduced network overhead[8][13].
Scalability and Elasticity
The platforms differ significantly in their approach to scaling:
| Feature | AutoMQ | Redpanda | Apache Kafka |
|---|---|---|---|
| Scale in/out | In seconds[13] | In hours (Community), In seconds (Enterprise)[13][15] | In hours/days[13] |
| Partition Reassignment | In seconds[13] | In hours (Community), In seconds (Enterprise)[13][15] | In hours/days[13] |
| Continuous Self-Balancing | Yes[13] | Yes[17] | No (requires Cruise Control)[13] |
| Spot Instance Support | Yes[13] | Limited (claimed)[13][15] | No[13] |
AutoMQ's stateless broker architecture enables significantly faster scaling operations, while Redpanda's Enterprise edition provides more advanced scaling capabilities compared to its Community version[13][15].
Kafka Compatibility
Both solutions maintain compatibility with Kafka's API, but with important distinctions:
AutoMQ: "Native Kafka" Implementation
AutoMQ maintains what it calls "Native Kafka" compatibility, extensively reusing Kafka's original code while modifying only the underlying storage layer to be S3-based[6][14]. This approach ensures:
100% compatibility with Apache Kafka[14]
No need for business systems to upgrade during migration
Ability to leverage existing Kafka tooling and ecosystems[6]
Redpanda: "Kafka Protocol" Compatibility
Redpanda implements the Kafka protocol from scratch in C++, providing what it terms "Kafka Protocol" compatibility[15]. This means:
Clients can connect to Redpanda using standard Kafka clients
Existing Kafka applications can typically use Redpanda without modification
Redpanda speaks "only Kafka" in terms of protocols[7][15]
Both platforms strive to make migration from Kafka as seamless as possible, though AutoMQ's reuse of Kafka code potentially offers higher compatibility in edge cases.
Cost-Effectiveness
Infrastructure Costs
Both platforms claim significant cost savings compared to Apache Kafka, but through different mechanisms:
| Cost Factor | AutoMQ | Redpanda | Apache Kafka |
|---|---|---|---|
| Primary Storage Costs | Lower (uses cheaper S3 storage)[1][3] | Lower than Kafka (more efficient resource usage)[17] | Higher (requires local storage and replication)[1] |
| Compute Requirements | Lower (stateless brokers)[13] | Lower than Kafka (more efficient C++ implementation)[17] | Higher (requires more nodes)[17] |
| Cross-Zone Networking | No (with S3 replication)[13] | Yes[13] | Yes[13] |
| Storage Efficiency | High (separation of storage and compute)[1] | Medium (improved with tiered storage in Enterprise)[17] | Low (requires replication and over-provisioning)[1] |
AutoMQ claims up to a 10x cost advantage primarily through cloud storage efficiency and elimination of cross-zone networking costs[1][5]. Redpanda claims up to 6x cost efficiency through more efficient resource utilization and simplified infrastructure[17][18].
Operational Costs
Beyond direct infrastructure costs, operational overhead represents a significant expense:
| Operational Factor | AutoMQ | Redpanda | Apache Kafka |
|---|---|---|---|
| Deployment Complexity | Low (single service)[13] | Low (single binary)[17] | High (Kafka + ZooKeeper + tools)[17] |
| Monitoring Requirements | Reduced | Reduced | Extensive (JVM, ZooKeeper, etc.)[17] |
| Scaling Complexity | Low (automated)[13] | Medium (Community), Low (Enterprise)[17] | High (manual balancing)[17] |
| FTE Requirements | Lower | Lower | Higher (estimated 3-4x more)[17] |
According to Redpanda's analysis, administrative cost savings can be substantial, with a claimed reduction from $448,000 to $48,000 in FTE costs for a large workload[17].
Key Feature Comparison
The following table summarizes the key differences between AutoMQ, Redpanda, and Apache Kafka:
| Feature | AutoMQ | Redpanda | Apache Kafka |
|---|---|---|---|
| Core Architecture | Cloud storage separation | Modern C++ implementation | JVM-based with local storage |
| Kafka Compatibility | Native Kafka (modified storage layer)[13] | Kafka Protocol (from scratch)[15] | Original implementation |
| Broker State | Stateless[13] | Stateful[13] | Stateful |
| Primary Storage | Cloud storage (S3, EBS)[13] | Local disks (with tiered storage option)[8] | Local disks |
| Component Count | Broker[13] | Broker[13] | Broker + ZooKeeper |
| Durability | Guaranteed by cloud storage[13] | Guaranteed by Raft[13] | Guaranteed by ISR |
| Self-Balancing | Yes[13] | Yes (Enterprise)[17] | No (requires Cruise Control) |
| Source Availability | Open Source[13] | Open Source (Community)[13][17] | Open Source |
Best Practices and Use Cases
Ideal Use Cases
Ideal Scenarios for AutoMQ
AutoMQ is particularly well-suited for:
Cloud-native deployments seeking to minimize infrastructure costs
Workloads requiring frequent scaling or elastic capacity
Organizations looking to reduce cross-zone networking costs
Use cases where data persistence in S3 provides additional benefits
Organizations with existing Kafka infrastructure seeking cloud optimization[1][3][6]
Best practices for AutoMQ deployment include:
Leveraging cloud-native features like autoscaling groups
Using regional cloud storage options for optimal performance
Monitoring S3 costs and access patterns
Configuring appropriate WAL storage based on performance needs[5][13]
Ideal Scenarios for Redpanda
Redpanda is particularly well-suited for:
Performance-critical applications requiring minimal latency
Organizations seeking operational simplicity
Self-hosted environments where hardware efficiency is paramount
Use cases requiring strong consistency guarantees
Environments where JVM overhead causes issues[7][11][17]
Best practices for Redpanda deployment include:
Using Redpanda's Autotuner for hardware optimization
Implementing regular maintenance mode for upgrades
Leveraging tiered storage in Enterprise edition for cost optimization
Taking advantage of Redpanda's data safety features[17][18]
Implementation Considerations
Monitoring and Management
Both platforms require less monitoring than Apache Kafka but still benefit from proper observability:
AutoMQ: Monitor S3 access patterns and costs; ensure proper WAL configuration
Redpanda: Leverage built-in metrics; monitor hardware utilization
Security
Both platforms support security features including:
Authentication and authorization
Encryption in transit
Audit logging
Migration Strategy
When migrating from Kafka:
Test compatibility with existing producers and consumers
Plan data migration strategy (parallel processing or cutover)
Validate performance under expected load
Develop rollback procedures
Conclusion
AutoMQ and Redpanda represent two distinct approaches to improving upon Apache Kafka. AutoMQ embraces cloud-native principles through storage separation, achieving cost efficiency and elasticity. Redpanda focuses on performance and operational simplicity through modern C++ implementation and architectural improvements.
For cloud-native deployments prioritizing elasticity and cost optimization, AutoMQ offers compelling advantages. For performance-critical applications requiring minimal latency and operational simplicity, Redpanda presents an attractive option.
Organizations should evaluate these alternatives based on their specific requirements, weighing factors such as performance needs, existing cloud strategy, operational capabilities, and budget constraints. Both solutions significantly improve upon Apache Kafka's limitations while maintaining compatibility, making migration feasible for most organizations.
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
JD.comx AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging
References
What's an Open Source or More Affordable Alternative to Kafka?
Introducing AutoMQ: A Cloud-Native Replacement of Apache Kafka
Redpanda vs Kafka: Simplifying High-Performance Stream Processing
CodeDocs.nvim: My First Plugin - An Automatic Documentation Generator
Conduktor Now Available on AWS Marketplace to Complement MSK
Do You Think We Need an Automatic Code? - JavaScript Discussion





