


.png)
Overview
The landscape of real-time data streaming has evolved dramatically as we progress through 2025, with Apache Kafka remaining the cornerstone technology for organizations seeking robust event streaming capabilities. This comprehensive analysis examines the current state of Managed Apache Kafka as a Service offerings, critical features, architectural considerations, operational challenges, and cost optimization strategies essential for organizations navigating this dynamic ecosystem.
The Evolving Landscape of Managed Kafka Services in 2025
The data streaming landscape has undergone significant transformation from 2024 to 2025, particularly with the coming release of Apache Kafka 4.0. This milestone release completed the transition to KRaft (Kafka Raft) mode, eliminating the dependency on ZooKeeper that had been a cornerstone of Kafka's architecture for years[13]. This architectural shift has simplified cluster management, improved scalability, and enhanced the overall reliability of Kafka deployments.
The democratization of Kafka continues as its adoption extends beyond tech companies to industries such as healthcare, finance, retail, and manufacturing. Real-world implementations, like Virgin Australia's use of Kafka for flight operations and loyalty programs, demonstrate how organizations are leveraging this technology to drive innovation[1]. This widespread adoption is largely fueled by the growing availability of managed Kafka services, making the technology accessible to organizations without specialized expertise.
In 2025, several key trends are shaping the managed Kafka service landscape:
First, the Kafka protocol has become a de facto standard for data streaming, with multiple vendors adopting it to ensure compatibility with the broader ecosystem[18]. Second, Bring Your Own Cloud (BYOC) models are gaining popularity as organizations seek to maintain control over their cloud environments while benefiting from managed services[18]. Third, integration with AI is accelerating, with Kafka becoming a cornerstone for feeding data to predictive and generative AI applications. Fourth, edge computing deployments are increasing, with Kafka being deployed closer to data sources. Finally, there's an intensified focus on operational simplicity, with providers offering enhanced automation, monitoring, and observability tools.
Major Managed Kafka Service Providers in 2025
AutoMQ
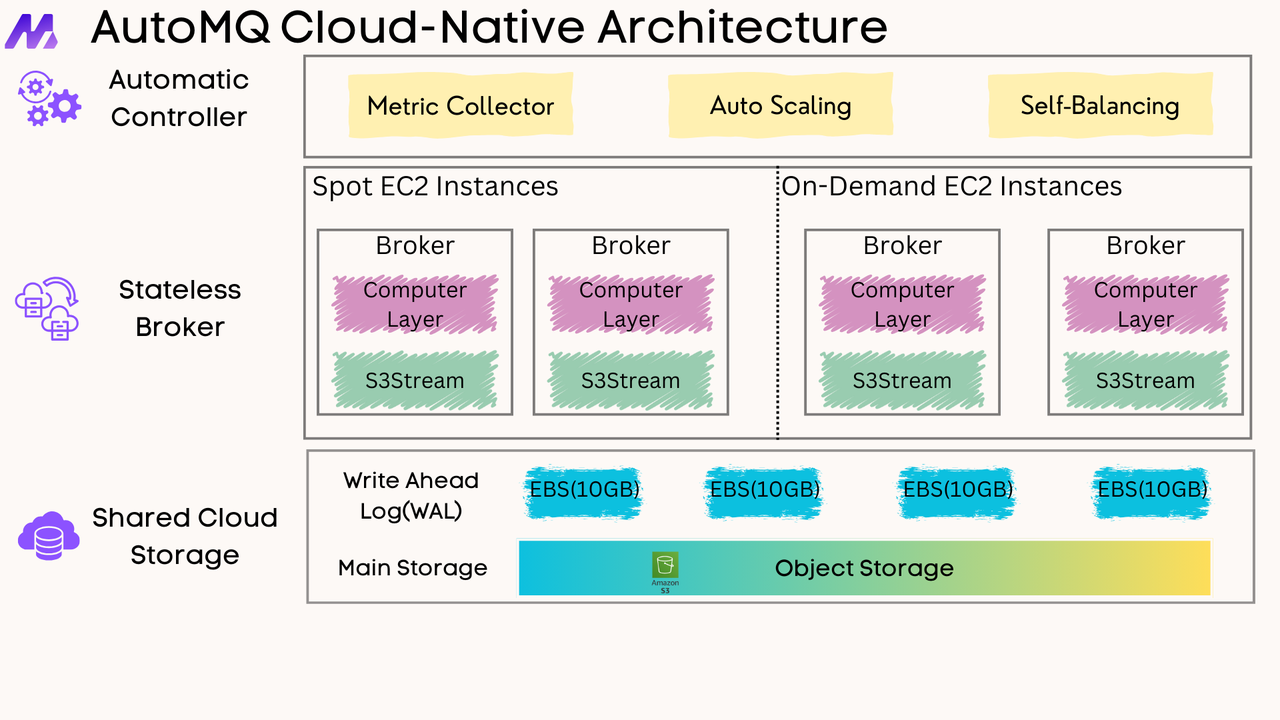
AutoMQ has emerged as a significant player in the Kafka-as-a-Service market with its cloud-native approach. AutoMQ adopts a Shared-Storage architecture, replacing the traditional storage layer of Apache Kafka with a shared streaming storage library called S3Stream[10]. This storage-compute separation makes brokers completely stateless, enabling partition reassignment in seconds and true auto-balancing[15].
Key features of AutoMQ include:
Cost optimization of over 50% compared to traditional Apache Kafka deployments[10]
Serverless capabilities with automatic scaling based on workload
Scaling in seconds due to the stateless nature of brokers
Infinite scalability through cloud object storage
100% compatibility with Apache Kafka APIs[15]
AutoMQ's cloud-native architecture offers advantages like capacity auto-scaling, self-balancing of network traffic, and the ability to move partitions in seconds, all contributing to a significantly lower Total Cost of Ownership (TCO)[2].
Confluent Cloud
As the company founded by the original creators of Apache Kafka, Confluent continues to lead the managed Kafka service market with Confluent Cloud.
Amazon MSK (Managed Streaming for Apache Kafka)
Amazon MSK remains a prominent player in 2025, offering two types of clusters:
MSK Provisioned clusters, where users can specify and scale cluster capacity
MSK Serverless clusters, where users don't need to specify or scale cluster capacity[8]
Amazon MSK Serverless makes it possible to run Apache Kafka without managing and scaling cluster capacity, automatically provisioning and scaling resources while managing partitions[8].
Google Cloud Managed Service for Apache Kafka
Google Cloud's Managed Service for Apache Kafka focuses on reducing the cost of manual broker management by handling cluster creation with automatic broker sizing and rebalancing[14]. In February 2025, Google Cloud announced the general availability of Committed Use Discounts (CUDs) for its Managed Kafka service, offering savings of up to 40% on compute costs.
Other Notable Providers
Other significant players in the managed Kafka space include Redpanda, Instaclust, Aiven etc.
Check more from this blog: Top 12 Kafka Alternative 2025 Pros & Cons

Key Features and Benefits of Managed Kafka Services
Operational Simplicity
Managed Kafka services significantly reduce the operational burden on organizations. These services typically provide automated cluster creation and configuration, built-in monitoring and alerting, automated backups and disaster recovery, and seamless scaling and broker management[6]. This automation frees up technical teams to focus on application development rather than infrastructure management.
High Availability and Reliability
Reliability is a critical factor for event streaming platforms. Managed Kafka services typically offer multi-zone or multi-region deployments for disaster resilience, uptime SLAs ranging from 99.9% to 99.99% depending on the provider and tier, automated failover mechanisms, and production-level support with rapid response times[6].
Security and Compliance
Security features in managed Kafka services have become increasingly robust in 2025. These typically include integrated authentication and authorization, encryption in transit and at rest, VPC connectivity and private networking options, and audit logging for compliance requirements[16].
Cost Optimization
Economic efficiency has become a more significant focus in 2025, with several managed Kafka providers emphasizing cost optimization. Features include pay-as-you-go pricing models, committed use discounts for predictable workloads, autoscaling to match resource consumption with actual needs, and storage-compute separation to optimize resource allocation[6].
Enhanced Developer Experience
Managed Kafka services enhance the developer experience through compatibility with existing Kafka clients and tools, managed schema registries and connectors, intuitive management consoles, and integration with cloud-native ecosystems.
Architecture and Technical Components
KRaft Mode: The New Standard
With Apache Kafka 4.0's coming release, KRaft mode has become the standard for Kafka deployments, replacing the previous ZooKeeper-based architecture[13]. KRaft (Kafka Raft) uses the Raft consensus protocol internally for metadata management, simplifying the overall architecture and improving scalability.
Cloud-Native Architectures
Newer managed Kafka services like AutoMQ implement cloud-native architectures that separate storage from compute[2]. This approach offers several advantages:
Stateless Brokers : Brokers become completely stateless, enabling rapid scaling and failover
Shared Storage : Using cloud object storage (like S3) for data persistence instead of local broker storage
Dynamic Scaling : The ability to scale the compute layer independently from the storage layer
Cost Efficiency : Optimizing resource allocation based on actual needs
AutoMQ's implementation, for example, first writes messages to an off-heap memory cache, batching data before writing it to object storage. To ensure data durability, it introduces a pluggable Write-Ahead Log (WAL) on disk[15].
Configuration and Operational Management
Cluster Configuration Best Practices
Partition Planning : Carefully plan the number of partitions based on throughput requirements and consumer parallelism. Increasing partitions improves parallelism but adds overhead[4].
Replication Factor : Use a replication factor of at least 3 for production workloads to ensure fault tolerance. This creates redundancy but increases storage requirements[4].
Broker Resources : Allocate sufficient CPU, memory, and disk resources to brokers. In managed services, select appropriate instance types based on workload characteristics.
Performance Optimization
Several performance optimization strategies have proven effective in 2025:
Dynamic Partition Rebalancing : Systems that automatically detect uneven partition loads and redistribute data across brokers without downtime[3].
Hybrid Storage Strategies : Integrating tiered storage models that separate hot and cold data, offloading older messages to cost-effective storage while ensuring fast access to current data[3].
Tune Replica Lag Time : Adjust based on latency tolerance to determine how long a follower can lag before being removed from the ISR list[4].
Thread Configuration : Tune network and I/O threads based on workload characteristics[4].
Configure Compression : Use appropriate compression algorithms (lz4, zstd, gzip) and compression levels to balance between throughput and CPU usage[4].
Common Issues and Troubleshooting
Despite the advantages of managed Kafka services, several operational challenges remain common in 2025:
Consumer Lag
Problem : Consumers falling behind producers, leading to delayed processing.
Solutions :
Adjust fetch settings (increase fetch.min.bytes, lower fetch.max.wait.ms)
Scale consumers by adding more to the consumer group
Monitor consumer lag in real-time and set up alerts[11]
Broker Availability Issues
Problem : "Broker Not Available" errors when producers or consumers try to connect.
Solutions :
Verify broker health and restart if necessary
Check network connectivity and firewall settings
Monitor broker metrics for early detection of issues[11]
Leadership Imbalance
Problem : Uneven distribution of partition leaders across brokers.
Solutions :
Use partition reassignment tools to redistribute leaders
Configure auto.leader.rebalance.enable=true
Implement regular leader balancing as part of maintenance[19]
Data Consistency Challenges
During migration or scaling operations, maintaining data consistency is critical. Organizations must ensure sequential message transfer without duplication or loss. This often requires implementing logging mechanisms, validation scripts, and checksum comparisons[12].
Monitoring and Management Complexity
Kafka's distributed nature demands robust monitoring tools. Organizations commonly use JMX metrics, Prometheus, or Grafana to track system health and performance. However, setting up these tools requires expertise and can be resource-intensive[20].
Cost Optimization Strategies
Several cost optimization strategies have gained prominence in 2025:
Right-sizing : Select appropriate cluster sizes based on actual throughput and storage needs.
Committed Use Discounts : Leverage long-term commitments for predictable workloads to save up to 40% on compute costs.
Storage-Compute Separation : Services like AutoMQ that separate storage from compute can reduce costs significantly, with AutoMQ claiming to be 10x more cost-efficient than traditional Kafka architecture[10].
Storage Tiering : Some providers offer tiered storage options, enabling cost-effective retention of historical data while keeping hot data on faster storage.
Eliminate Cross-AZ Traffic Costs : Solutions like AutoMQ specifically address cross-AZ traffic costs by leveraging object storage, which can be a significant expense in traditional Kafka deployments[10].
Future Trends and Innovations
As we progress through 2025, several trends continue to shape the future of managed Kafka services:
AI Integration : Kafka is increasingly used as the data backbone for AI pipelines, with managed services offering specialized integrations for ML workflows[18].
Edge Computing : Kafka deployments at the edge are growing, with managed services extending their reach to edge locations for scenarios like autonomous vehicles or IoT deployments[18].
Improved Observability : Advanced monitoring and observability tools are becoming standard features, providing deeper insights into Kafka operations[3].
Serverless Kafka : Truly serverless Kafka offerings continue to mature, with auto-scaling capabilities that adjust resources based on actual usage[8].
Protocol Enhancements : The Kafka protocol continues to evolve, with managed services quickly adopting new features and improvements from the open-source project.
Conclusion
As we navigate through 2025, Managed Apache Kafka as a Service has become the preferred approach for organizations looking to leverage the power of real-time data streaming without the operational complexity of self-managed Kafka clusters. From cloud-native offerings like AutoMQ that leverage modern architectural patterns to established players like Confluent Cloud and cloud provider solutions like Amazon MSK and Google Cloud Managed Service for Apache Kafka, organizations have a wide range of options to choose from.
The transition to KRaft mode, the adoption of cloud-native architectures, and the integration with AI and edge computing are all shaping how managed Kafka services are delivered and consumed. By understanding these trends, along with best practices for configuration, troubleshooting, and cost optimization, organizations can make informed decisions about their Kafka deployments and maximize the value they get from their real-time data streaming infrastructure.
References
Virgin Australia's Journey with Apache Kafka: Driving Innovation in the Airline Industry
AutoMQ vs Kafka: An Independent In-Depth Evaluation and Comparison by Xiaohongshu
Data Streaming Landscape Changes from 2024 to 2025: Implications for Apache Kafka
AutoMQ: Achieving Auto Partition Reassignment in Kafka Without Cruise Control
Top Trends for Data Streaming with Apache Kafka and Flink in 2025
Topic as a Service: Automate Governance Decisions for Apache Kafka
Introducing AutoMQ: A Cloud Native Replacement of Apache Kafka
How AutoMQ Reduces Nearly 100% of Kafka Cross-Zone Data Transfer Cost
Troubleshooting Kafka Clusters: Common Problems and Solutions
Confluent vs Redpanda: A Comparative Analysis for Kafka Infrastructure
Introducing AutoMQ: A Cloud Native Replacement of Apache Kafka





