In the world of data processing and distributed systems, messaging queues and streaming platforms represent two fundamental approaches to handling real-time data. While they may appear similar at first glance, they serve distinct purposes and offer different advantages for various use cases. This comprehensive guide explores the key differences, benefits, and limitations of each approach.
Understanding the Fundamentals
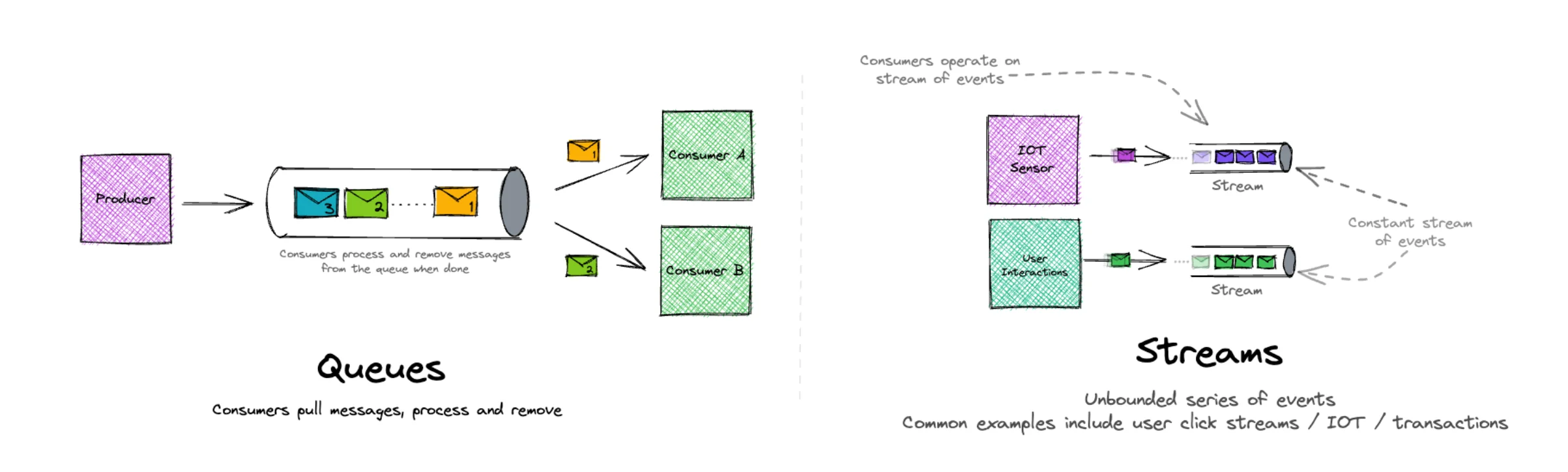
What Are Message Queues?
Message queues function as middleware that facilitate asynchronous communication between applications by temporarily storing messages until they are processed. In a queue-based system, producers send messages to a queue, and consumers retrieve these messages for processing.
A helpful analogy comes from the coffee shop scenario: when customers place orders (producers), the barista (consumer) processes them one at a time, removing each order from the queue after completion. Each message represents a discrete task to be processed independently, and once consumed, it's typically removed from the queue.
What Is Data Streaming?
Streaming platforms handle continuous flows of data, enabling real-time processing as information arrives. Unlike queues, streaming systems maintain a record of events over time, allowing multiple consumers to access the same data, even retrospectively.
Streaming platforms excel at handling large volumes of continuous data from sources like IoT devices, user activity logs, or transaction systems. They focus on the chronological sequence of events and enable various applications to consume these events based on their specific needs.
Key Architectural Differences
Communication Model
Message Queues : Implement a point-to-point communication model where each message is delivered to exactly one consumer. This ensures that work is distributed evenly across consumers without duplication.
Streaming : Follows a publish-subscribe model where messages are broadcast to all interested subscribers. Multiple consumer groups can read the same data independently without affecting each other.
Message Consumption
Message Queues : Practice destructive reading – once a message is processed and acknowledged by a consumer, it's removed from the queue. This prevents duplicate processing and ensures each task is completed exactly once.
Streaming : Uses non-destructive reading where events remain in the stream even after being consumed. This allows multiple consumers to process the same events and enables replay of historical data.
Data Retention
Message Queues : Focus on transient storage until successful processing. Messages exist primarily to facilitate task execution and are typically not retained long-term.
Streaming : Emphasizes persistence with configurable retention periods. Events are stored for a specified duration regardless of consumption, enabling historical analysis and replay capabilities.
Ordering Guarantees
Message Queues : Often provide FIFO (First In, First Out) processing within a queue, though some implementations may offer priority-based variations.
Streaming : Guarantee order within each partition but not across partitions. Messages with the same key are typically delivered to the same partition, ensuring ordered processing for related events.
Advantages and Disadvantages
Advantages of Message Queues
Workload Distribution and Load Leveling
Message queues excel at distributing tasks among multiple workers, preventing any single component from becoming overwhelmed. They effectively manage fluctuations in workload by buffering messages during peak times and processing them when resources are available.
Reliable Task Execution
By persisting messages until they're successfully processed, queues ensure that no task is lost, even if consumers temporarily fail. Most queue implementations support acknowledgment mechanisms to confirm successful processing before removing messages.
Simple Implementation and Operation
Message queues typically offer straightforward interfaces with clear semantics. Their point-to-point delivery model simplifies reasoning about message flow and system behavior, making them easier to implement and debug.
Temporal Decoupling
Producers and consumers don't need to operate simultaneously, allowing asynchronous communication between components that may have different operational schedules or processing capacities.
Guaranteed Once-Only Processing
The destructive consumption model ensures each message is processed by exactly one consumer, eliminating concerns about duplicate processing that could affect data integrity.
Disadvantages of Message Queues
Limited Data Access Patterns
Once a message is consumed, it's no longer available to other consumers or for historical analysis. This limits the types of processing that can be performed on the data.
No Historical Replay
Without additional storage mechanisms, message queues don't support replaying past messages, making them less suitable for analytical use cases that might require historical data processing.
Scaling Complexity
While queues can scale horizontally by adding more consumers, coordinating these consumers and ensuring proper message distribution can become complex, especially when maintaining strict ordering requirements.
Potential Message Loss
If not properly configured with persistence and acknowledgment mechanisms, message queues may risk losing data during system failures or restarts.
Advantages of Streaming Platforms
Real-Time Analytics and Processing
Streaming platforms excel at continuous, real-time data processing, enabling immediate insights from incoming data. This is crucial for use cases like fraud detection, monitoring, and real-time dashboards.
Multi-Consumer Access
The same data stream can be consumed by multiple independent applications, each processing the data according to their specific requirements without affecting others. This enables diverse use cases from a single data source.
Historical Data Access
By retaining data for configurable periods, streaming platforms support both real-time and historical analysis. New consumers can process past events, enabling retroactive analysis and facilitating system recovery.
High Throughput and Scalability
Modern streaming platforms like Kafka and AutoMQ are designed to handle extremely high data throughput rates. They achieve this through partitioning, which allows data processing to be divided into manageable chunks that can be distributed across servers.
Event-Driven Architecture Support
Streaming platforms naturally align with event-driven architectures, where systems react to events as they occur. This enables more responsive, loosely coupled system designs.
Disadvantages of Streaming Platforms
Increased Operational Complexity
Streaming platforms typically require more complex setup and maintenance than message queues. Managing topics, partitions, and consumer groups adds operational overhead.
Higher Resource Requirements
The retention of data for extended periods demands more storage resources compared to queues. High-throughput streaming systems may also require more processing power and memory.
Exactly-Once Processing Challenges
Ensuring exactly-once processing semantics is more complex in streaming systems where the same data can be read multiple times. Applications must implement idempotence or other strategies to handle potential duplicates.
Learning Curve
The concepts and patterns associated with stream processing often have a steeper learning curve than the simpler queue-based models, potentially increasing development time and complexity.
Representative Systems
-
Messaging Queues: RabbitMQ, Apache ActiveMQ, NATS, etc.
-
Streaming: Apache Kafka,AutoMQ,Confluent, Amazon Kinesis, Redpanda, etc.
Learn more from: Top 12 Kafka Alternative 2025 Pros & Cons
Use Cases and Applications
When to Use Message Queues
Message queues are ideal for:
-
Task Distribution : Distributing work across multiple workers for parallel processing, such as order processing in e-commerce systems.
-
Job Scheduling : Managing scheduled tasks and ensuring they're executed reliably, like batch processing jobs.
-
Decoupling Services : Reducing dependencies between system components, allowing them to evolve independently.
-
Guaranteed Delivery : Ensuring critical operations (like financial transactions) are processed exactly once, even in the face of system failures.
Load Leveling : Handling traffic spikes by buffering requests during peak times.
When to Use Streaming Platforms
Streaming platforms shine in:
-
Real-Time Analytics : Processing data as it's generated to provide immediate insights and visualizations.
-
Event-Driven Architectures : Building systems that react to events as they occur, enabling more responsive applications.
-
IoT Data Processing : Handling continuous data flows from sensors and connected devices that generate high volumes of time-series data.
-
Change Data Capture : Tracking changes in databases to keep systems synchronized or to maintain audit trails.
-
Media Streaming : Delivering continuous audio and video content to multiple consumers.
Implementation Guidelines
Real-World Examples
Message Queue Examples
-
E-commerce Order Processing : When a customer places an order, a message is sent to a queue. Payment processing, inventory updates, and shipping initiation are handled as separate steps by different consumers.
-
Healthcare Systems : Managing patient flow and appointment scheduling, ensuring each patient is processed by the appropriate department without duplication.
-
Restaurant Operations : Handling customer orders and ensuring they're fulfilled in sequence by the kitchen staff.
Streaming Examples
-
Financial Fraud Detection : Analyzing transaction patterns in real-time to identify potentially fraudulent activities before they're completed.
-
Real-Time Dashboards : Providing up-to-the-second visualizations of business metrics, system performance, or user activity.
-
IoT Sensor Networks : Processing continuous data from thousands or millions of sensors to monitor environmental conditions, equipment health, or infrastructure status.
Best Practices and Considerations
For Message Queues
-
Implement Proper Error Handling : Design consumers to handle failed message processing through retry mechanisms or dead-letter queues.
-
Configure Appropriate Timeouts : Balance between responsive failure detection and avoiding unnecessary reprocessing.
-
Monitor Queue Depth : Track the number of pending messages to detect processing bottlenecks or capacity issues.
-
Consider Message Persistence : For critical operations, ensure messages are persisted to disk to survive system restarts.
For Streaming Platforms
-
Optimize Partitioning Strategy : Design topic partitions based on throughput requirements and key distribution to ensure even workload.
-
Configure Retention Policies : Balance between data availability and resource usage by setting appropriate retention periods.
-
Implement Consumer Group Strategies : Organize consumers into logical groups based on their processing requirements.
-
Monitor Consumer Lag : Track how far behind consumers are from producers to detect processing bottlenecks.
Conclusion
While both messaging queues and streaming platforms enable asynchronous communication between distributed systems, they serve distinct purposes with different trade-offs. Message queues excel at reliable task distribution and guaranteed one-time processing, making them ideal for workload distribution and decoupled service architectures. Streaming platforms shine in scenarios requiring real-time analytics, multiple consumers, and historical data access, supporting event-driven architectures and continuous data processing.
The choice between these technologies depends on your specific requirements regarding data access patterns, processing semantics, and operational characteristics. Many modern systems even combine both approaches, using message queues for reliable task execution and streaming platforms for real-time analytics and event distribution.
Understanding these differences allows architects and developers to select the right tool for each specific use case, building more efficient, scalable, and robust distributed systems.
Still struggling with skyrocketing Kafka bills and the "ops tax" of manual disk management? It's time to stop babysitting your clusters. Try AutoMQ Cloud for Free and experience how diskless architecture slashes costs and automates scaling—no credit card required. See how others made the switch in our case studies or explore the project on GitHub.


