


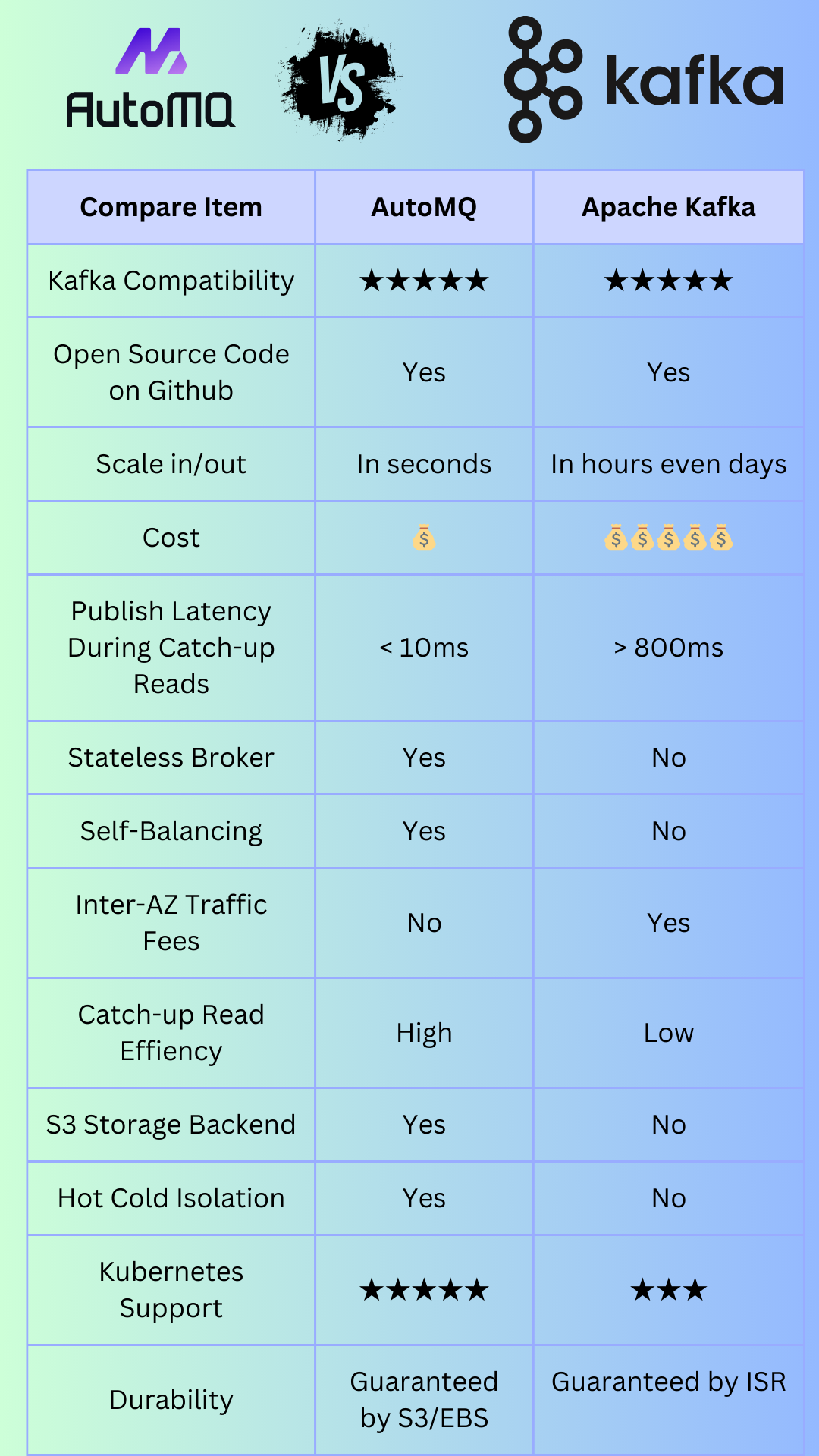
.png)
AutoMQ is 100% compatible with Apache Kafka. If you need a Kafka service with lower costs, greater elasticity, and better performance, you can choose AutoMQ without hesitation.
Background
What is AutoMQ
Inspired by Snowflake, AutoMQ [1] is a cloud-first designed alternative to Kafka. AutoMQ innovatively redesigned the storage layer of Apache Kafka based on the cloud. It achieved a 10x cost reduction and 100x elasticity improvement by offloading persistence to EBS and S3, while maintaining 100% compatibility with Kafka, and offering better performance compared to Apache Kafka.
What is Apache Kafka
Apache Kafka [2] is a popular open-source event streaming platform capable of handling trillions of events per day. Apache Kafka was created over a decade ago, leading the new era of streaming storage. It significantly improved data write efficiency and throughput through techniques like append-only logs and zero-copy technology. With its excellent scalability and performance, it quickly reshaped enterprise data infrastructure architectures and was widely adopted by organizations of all sizes. To this day, Apache Kafka has a very active community and continues to iterate and update. With Kafka's strong and rich ecosystem in the streaming systems field, the Kafka API has become the de facto standard in the streaming systems domain. Ensuring sufficient compatibility with Apache Kafka has become a crucial factor for many enterprises when choosing their data infrastructure.
Stream systems are crucial data infrastructures, and choosing the right stream system is vital for building a modern data stack. This article will provide a comprehensive comparison between AutoMQ and Apache Kafka from multiple dimensions, enabling readers to quickly understand their differences and select the stream system that best suits their needs.
TD;LR
All differences between AutoMQ and Apache Kafka can be summarized in the figure below. If you are interested in the details of the comparison, please continue reading the subsequent content.
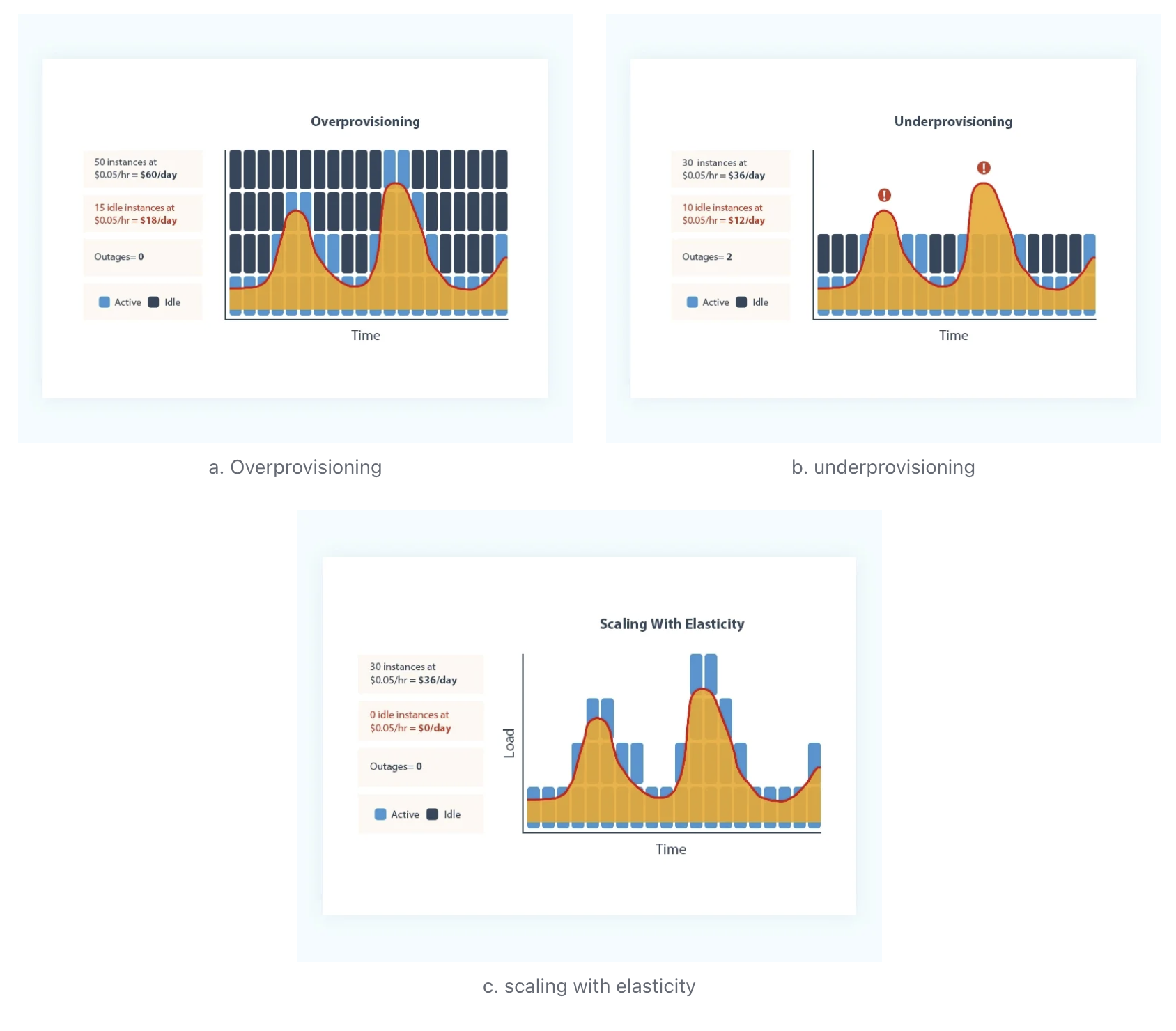
Elastic vs. Non-Elastic
The Foundation of Cloud-Native and Serverless: Elasticity
After years of development, cloud-native technologies and Public Cloud have become the foundation of modern data stacks across various industries. The concept of cloud-native primarily originates from the definitions provided by CNCF [3] and Cloud providers [4]. Regardless of the definition, they all emphasize that true cloud-native applications must have elastic capabilities. Elastic applications can quickly and efficiently adjust the resources they consume based on workload, whereas non-native applications require cumbersome capacity assessments based on peak load and over-provisioning of resources to handle peak workloads. The three figures below [5] effectively illustrate the differences in resource usage between cloud-native and non-cloud-native applications. Non-cloud-native applications often use the overprovisioning method shown in Figure a for capacity planning. For example, with Apache Kafka, to ensure the service can support peak throughput and maintain low latency, users must first assess the relationship between cluster machine specifications and the write throughput they can support. They then determine the cluster size needed to handle peak throughput and additionally reserve 30%-50% of the cluster capacity to handle unexpected "black swan" traffic. This overprovisioning method leads to significant wastage of computing and storage resources. Using the underprovisioning method shown in Figure b for capacity planning would fail to support high-load scenarios, impacting business operations. True cloud-native applications need to achieve the scale with elasticity shown in Figure c, where resource consumption is pay-as-you-go. One of the greatest values of the cloud is its virtually unlimited resources and rapid resource provisioning and decommissioning. When you no longer need these cloud resources, you must release them promptly; when you need them, you can quickly provision these resources through cloud APIs. Only by achieving this level of elasticity can the advantages of Public Cloud be fully realized.
Comparison of Elastic Capabilities
Conclusion: AutoMQ >> Apache Kafka

Apache Kafka : Apache Kafka is an outstanding open-source product. At the time of its inception, it featured numerous technical innovations and leadership. However, in recent years, with the widespread adoption of Public Cloud technologies and Kubernetes, new demands have been placed on the elasticity of such data infrastructure. If a product itself does not possess excellent cloud elasticity [5], it will not be able to fully leverage the capabilities of Public Cloud and Kubernetes. Apache Kafka, born over a decade ago, is fundamentally still software, not a service. Many users simply rehost Kafka to the cloud, only to find that the costs actually increase, and the operational complexity of Kafka itself does not decrease. The key reason behind this is the monolithic storage and compute architecture of Apache Kafka, where stateful Brokers lead to a lack of elasticity in the compute layer, making it difficult to scale quickly and securely. The lack of an elastic architecture not only prevents full utilization of cloud advantages but also triggers issues such as disk network I/O contention and cold read inefficiency. Below are some elasticity-related issues with Apache Kafka:
Significantly Increased TCO Due to Capacity Evaluation : The costs of deploying Apache Kafka primarily come from the compute, storage, and network costs of its Broker machines. Many users overlook the complexity and challenges brought by capacity evaluation. To ensure the stability of the production system, developers need to spend a significant amount of time selecting the appropriate machine specifications and testing performance on different machine types to accurately evaluate the cluster capacity needed to handle peak throughput. Factors such as replica count, read/write ratio, network bandwidth, SSD I/O bandwidth, and retention time must all be considered in terms of their impact on the write throughput capacity, greatly increasing production costs. Furthermore, any future need to scale up or down will require a reevaluation of capacity. Capacity evaluation is a labor-intensive and high-cost task that greatly increases the TCO of using Apache Kafka. However, if using a system like AutoMQ that supports automatic elasticity, users would not need to spend a significant amount of effort planning cluster capacity based on their workloads.
Resource Waste Due to Reserved Capacity : Accurately evaluating and predicting read/write throughput is extremely challenging. To avoid efficiency issues during Apache Kafka scaling, users have to reserve capacity in advance based on peak throughput. Additionally, to avoid unexpected spikes in traffic—which are common in e-commerce scenarios—an extra 30%-50% capacity needs to be reserved. Imagine if a user’s average write throughput is 100MB/s, and they need to handle peak throughput of 1GB/s, they would need a cluster capable of handling 1.3GB/s to 1.5GB/s, resulting in up to 92% of the cluster capacity being wasted.
Scaling Impacts on Business Read/Write Operations, Unable to Adapt to Future Business Changes : Businesses are constantly evolving. Even with reserved capacity, inevitable future adjustments to cluster capacity will be required. Real-world cases from AutoMQ’s clients, including new energy car manufacturers and e-commerce companies, highlight this issue. These businesses often experience marketing peaks, such as new model launches or promotional sales events, during which the Kafka cluster must handle traffic several times greater than usual. This necessitates cluster scaling, which must be reduced after the event. This is a high-risk and business-disruptive operation. For Apache Kafka, scaling involves significant data replication between Brokers, which can take hours to days. Worse still, during partition reassignment, the read/write operations of these moving partitions are also impacted. Each scaling operation forces the developers responsible for Kafka’s operations to worry about capacity adjustments and coordinate with business teams to mitigate potential business disruptions caused by the reassignment.
Facing Sudden Traffic Surges Without Timely Intervention : If peak traffic is not accurately assessed from the start, sudden traffic surges during critical business moments can cause performance degradation due to insufficient capacity in the Kafka cluster. At this point, the Kafka cluster can only endure these traffic surges with performance loss, leading to business damage and company losses.
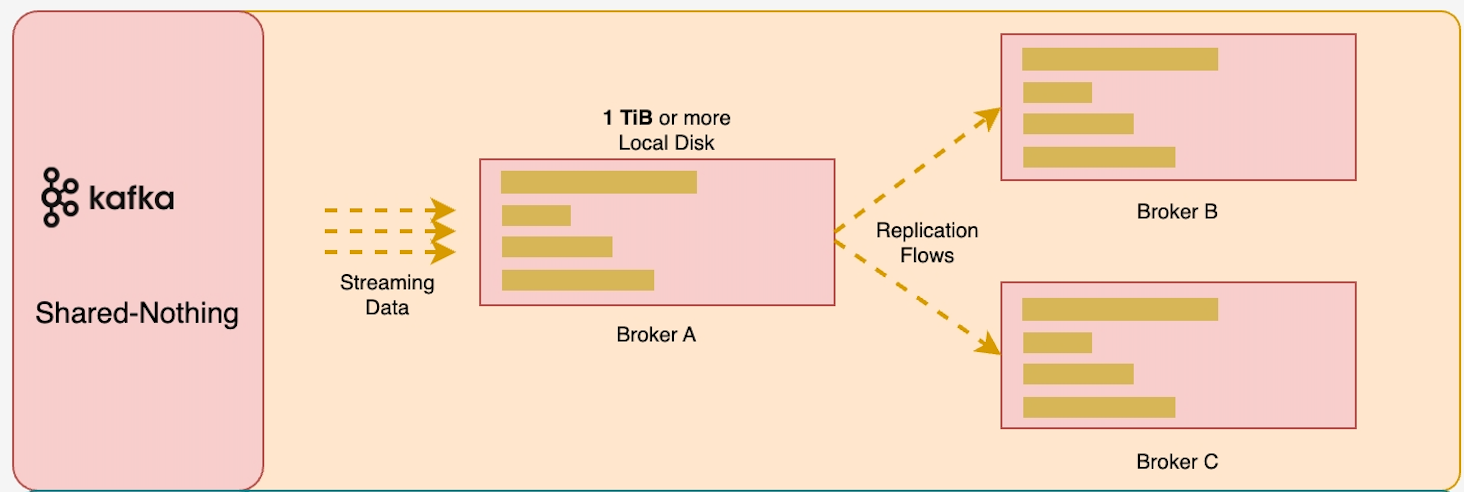
AutoMQ : AutoMQ has completely redesigned Apache Kafka's storage layer with a cloud-native approach. Based on a cloud-first philosophy, it offloads persistence to mature cloud storage services like EBS and S3. The main difference from Apache Kafka is that the entire compute layer becomes stateless. Because the compute layer is stateless, the entire architecture becomes highly elastic. Under this elastic architecture, AutoMQ can significantly reduce costs by leveraging cloud technologies such as Spot instances and auto-scaling, and it also works better on Kubernetes. AutoMQ eliminates all the costs, operational complexity, and other issues associated with Kafka due to its lack of elasticity. The figure below reveals the differences between AutoMQ's elastic architecture based on EBS WAL and object storage (S3) shared storage and Apache Kafka's integrated storage and compute architecture. In this elastic storage architecture, AutoMQ brings many benefits:
Using Spot Instances to Reduce Costs : AutoMQ's elastic storage architecture makes Brokers stateless, allowing the use of Spot instances, which can be several times more cost-effective than on-demand instances, to reduce costs.
Better Integration with Kubernetes : Although Apache Kafka can also be deployed on Kubernetes, it cannot fully leverage the containerization advantages of Kubernetes. Compared to using virtual machines, Kubernetes can create and destroy pods much faster using container technology. AutoMQ's elastic architecture allows it to be more elastic on Kubernetes. Apache Kafka, due to the extensive data replication required among Brokers during scale-in/scale-out, cannot benefit from the elasticity brought by Kubernetes containerization.
Support for Auto-Scaling : Fast and secure scaling capabilities are the foundation of auto-scaling. AutoMQ's elastic storage architecture further fosters critical features such as second-level partition reassignment and automatic traffic self-balancing, enabling AutoMQ to achieve true auto-scaling.
AutoMQ offers better support for Kubernetes.

Kubernetes is a significant innovation in the cloud-native technology field and a culmination of cloud-native technologies. It fully leverages container technology, elasticity, IaC, and declarative APIs to provide enterprises with a standardized, general-purpose, and efficient cloud-native technology foundation. By adhering to cloud-native best practices, enterprises can migrate applications that align with cloud-native principles to Kubernetes, benefiting from its efficient automated operations, resource management, and rich ecosystem. For instance, core services on Alibaba Cloud mostly run on K8s. Using Kubernetes in enterprises of a certain scale will yield greater benefits. Many large customers of AutoMQ are either extensively using K8s or are in the process of migrating their core data infrastructure to K8s.
AutoMQ has excellent support for K8s. In the Apache Kafka ecosystem, there are outstanding products like Bitnami and Strimzi. In their communities, developers have called for support for AutoScaling [10] [11]. However, due to Apache Kafka's integrated compute and storage architecture, it is challenging to achieve horizontal scaling on K8s. Deploying Apache Kafka on K8s essentially just rehosts Kafka from an IDC to K8s, making it difficult to fully utilize the advantages of K8s. Conversely, AutoMQ supports a stateless Kafka Broker through cloud-native modifications to the Kafka storage layer. You can deploy AutoMQ on AWS EKS [12] and use Karpenter [13], Cluster AutoScaler [14], and other K8s ecosystem products to support AutoMQ's automatic elasticity.
Cost Comparison
The official AutoMQ documentation, "Cost-Effective: AutoMQ vs. Apache Kafka" [6], compares the actual cloud bill differences when running AutoMQ and Apache Kafka on AWS. Overall, under typical scenarios with similar performance metrics, AutoMQ can save up to 90% of the cost compared to Apache Kafka. The figure below details where these cost differences primarily come from when self-hosting Apache Kafka and using AutoMQ on AWS Cloud.
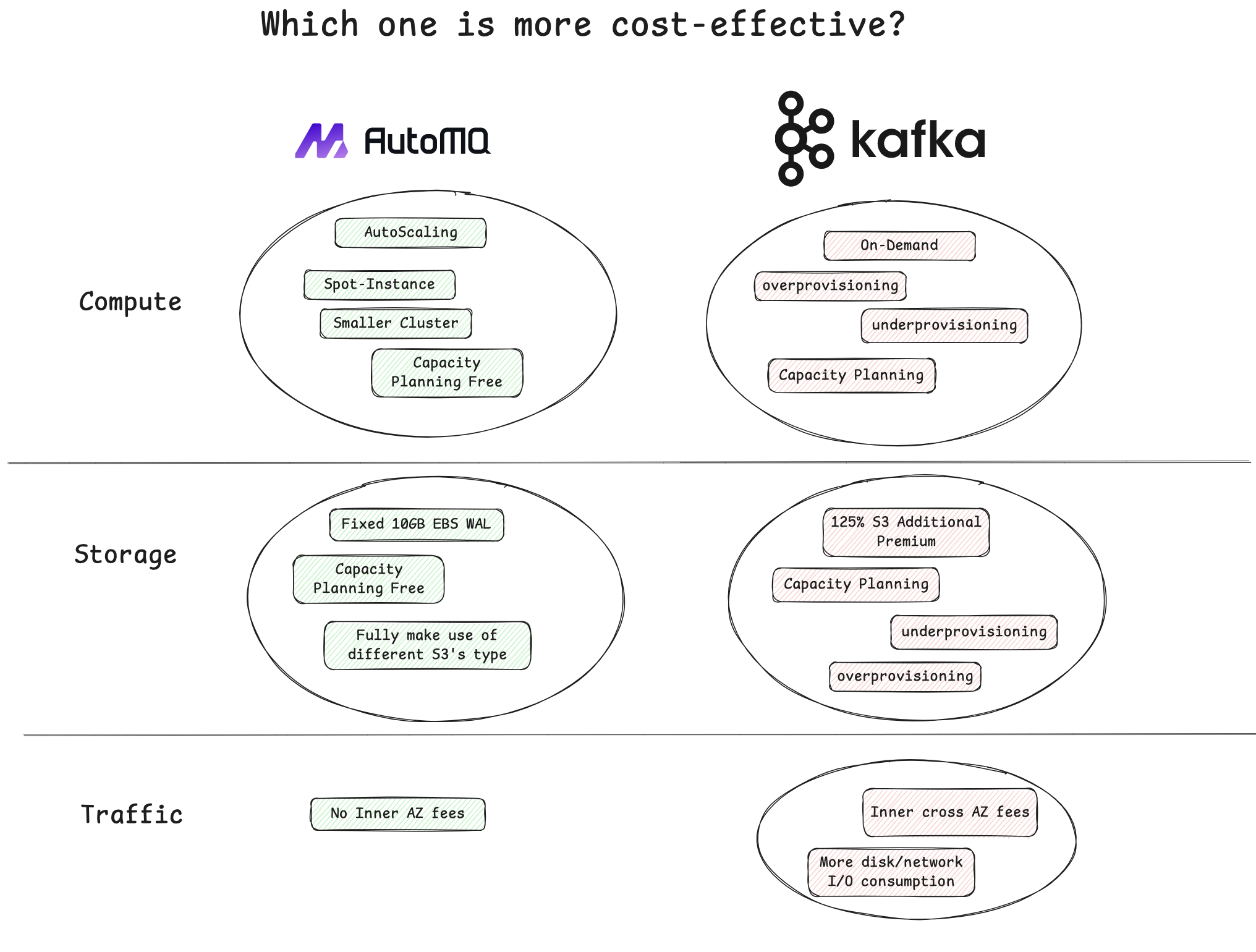
Compute Layer:
Spot Instances : For example, the on-demand price for an r6i.large instance in aws cn-northwest-1 is ¥0.88313/hour, while the price for a Spot instance is ¥0.2067/hour. In this case, using Spot instances can save 76% of the cost compared to on-demand instances.
AutoScaling : AutoMQ's stateless computing layer provides the foundation for implementing AutoScaling. For Apache Kafka, due to its lack of elasticity, scaling operations are extremely high-risk and time-consuming, making ordinary scaling operations difficult to implement, let alone achieving AutoScaling capabilities. AutoMQ can rapidly AutoScale to provide resources that match actual load changes, reducing resource waste and lowering costs. The greater the fluctuation in user traffic, the more savings achieved through AutoScaling. In Cost-Effective: AutoMQ vs. Apache Kafka[6], we simulated a scenario with periodic load fluctuations similar to real-world scenarios. Utilizing AutoMQ's auto-scaling capabilities to automatically scale compute instances, in this fluctuating load scenario, an average of 90% of instance costs can be saved daily.
Compared to Apache Kafka, AutoMQ can handle larger read and write throughput with fewer machines and smaller specifications : Machines on AWS have network bandwidth tied to their specifications. Only larger instance types can enjoy higher network bandwidth. Assuming a 1:1 write model, for each write traffic, AutoMQ's outbound traffic includes one portion consumed by consumers and another portion written to S3. In contrast, using Apache Kafka with three replicas, the outbound traffic includes one portion for consumer consumption and an additional two portions for partition replication. Therefore, for a single broker, AutoMQ only needs an EC2 instance capable of handling the network bandwidth for two portions of outbound traffic, while Apache Kafka requires an EC2 instance capable of handling the network bandwidth for three portions of outbound traffic. This allows AutoMQ to use significantly smaller instance types to achieve the same read and write throughput as Apache Kafka.
No capacity assessment required, reducing labor costs : AutoMQ Business Edition provides throughput-based billing. Users do not need to worry about the relationship between the traffic that a cluster can handle and the underlying computation, storage, and network. AutoMQ's technical experts have spent considerable time helping users select the optimal instance types and configurations. Whether creating new clusters or scaling up or down, users do not need to spend significant time and effort re-evaluating the relationship between resource consumption and actual throughput capacity. With auto-scaling enabled, users can use AutoMQ in a manner completely similar to using a Serverless service.
Storage Layer :
Apache Kafka Relies on Expensive Local Storage : To ensure Kafka's latency requirements are met, users need to use SSDs to store Kafka data. For scenarios requiring backtrack consumption, this data needs to be retained on the Kafka cluster for some time. Given that Kafka is a data-intensive infrastructure, it involves a significant amount of data write-in and storage. Considering us-east-1, GP3's EBS unit price at 0.08 USD/GB per month, and assuming an average daily write-in traffic of 100MB/s with data retention time of 24h, the monthly storage cost would amount to 691.20 USD. However, with AutoMQ, the storage cost would only be 188.42 USD per month, saving 73% of storage costs . For users with larger throughput and retention time, the absolute storage costs will be more apparent. For large-scale enterprises, just in terms of storage costs, AutoMQ can save tens of thousands of dollars per month compared to Kafka.
No need for capacity assessment, reducing labor costs : When using Apache Kafka, you need to test, verify, and assess how much local disk to configure for each Broker yourself. Similar to the compute layer, AutoMQ eliminates the need for users to carry out cluster capacity assessments on their own.
Network:
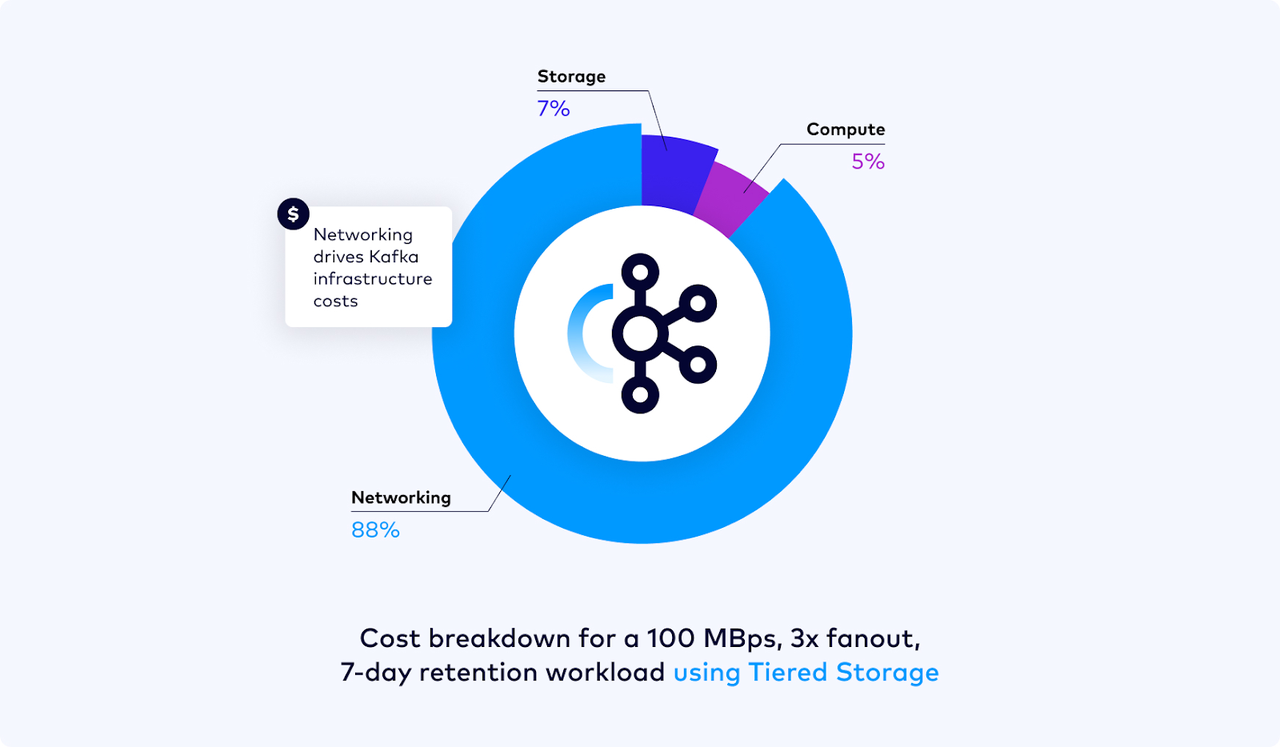
- Intra-AZ costs within the cluster : Apache Kafka, in order to ensure data persistence, requires 3 replicas. Kafka uses ISR to guarantee the persistence of data. Overseas cloud providers like AWS and GCP charge for network traffic across availability zones. Not only Apache Kafka, but also models like Confluent, Redpanda that rely on multi-replica replication to ensure data persistence will incur significant network costs on clouds like AWS that charge for cross-AZ traffic [8] . AutoMQ, on the other hand, involves no data replication within the cluster. AutoMQ offloads data persistence to cloud storage services like EBS, S3, which inherently have a multi-replica mechanism. At the AutoMQ cluster level, a single data replica is sufficient to ensure data persistence.
Performance Comparison
Unlike WarpStream [9], which sacrifices latency, AutoMQ's innovation in the stream storage engine maintains Kafka's high throughput and low latency advantages. In Catch-up Read scenarios, AutoMQ even offers better performance due to the isolation of hot and cold data. AutoMQ employed the OpenMessaging Benchmark to conduct a comprehensive performance comparison between AutoMQ and Apache Kafka. For detailed benchmark information, refer to Benchmark: AutoMQ vs. Apache Kafka [7]. This article highlights several key points from the benchmark.
Fixed Scale Latency and Throughput Performance Comparison
The main advantages of AutoMQ over Apache Kafka® at a fixed scale are:
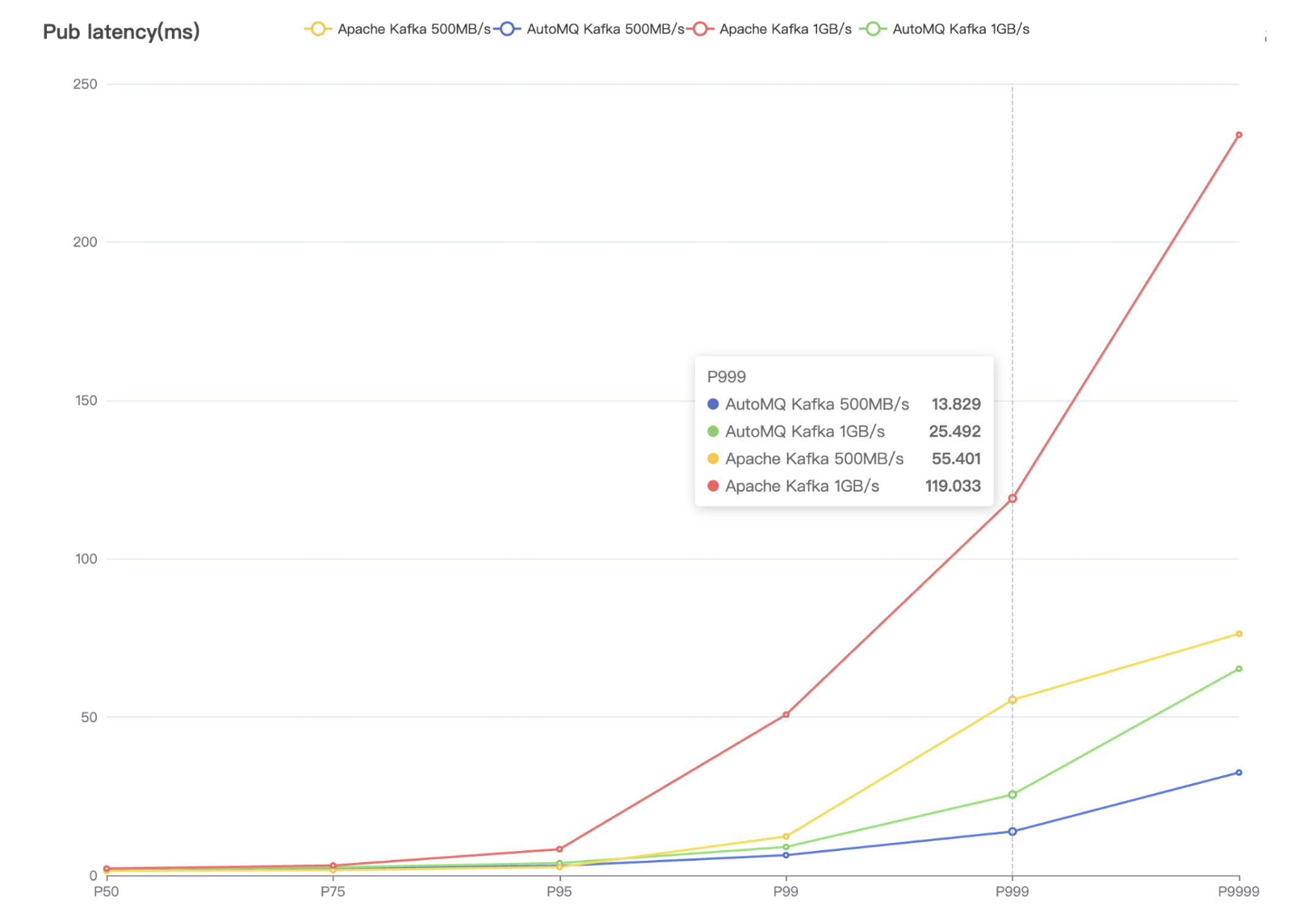
At the same machine scale, the extreme throughput of AutoMQ is 2X that of Apache Kafka : AutoMQ ensures high data durability through multiple replicas based on EBS at the lower level, without additional replication at the upper layer. In contrast, Apache Kafka requires ISR three replicas to ensure high data durability. When disregarding CPU and network bottlenecks, both AutoMQ and Apache Kafka max out the disk bandwidth, with AutoMQ's theoretical throughput limit being three times that of Apache Kafka.
With the same cluster scale and traffic (500 MiB/s), AutoMQ's send latency P999 is 1/4 that of Apache Kafka's. Even when AutoMQ handles twice the traffic (500 MiB/s : 1024 MiB/s), its send latency P999 remains 1/2 of Apache Kafka's.
AutoMQ uses Direct IO to bypass the file system and write directly to the EBS raw device, avoiding file system overhead and thus achieving more stable send latency.
Apache Kafka, by using Buffered IO, writes data to the page cache, returning success once the data is in the page cache, and the operating system asynchronously flushes dirty pages to the disk in the background. File system overhead, cold reads from consumers, and page cache miss uncertainties can all cause fluctuations in send latency.

Performance Comparison During Catch-up Reads
Catch-up reads, often referred to as "cold reads", refer to the consumption of data with offsets prior to the current moment. This scenario typically occurs when the consumer's consumption rate cannot keep up with the production rate or when it needs to backtrack consumption due to its own reasons. Cold reads are common and critical scenarios in Kafka consumption, playing an essential role in assessing Kafka's performance. Common scenarios of cold reads include:
Consumer Rate Can't Keep Up with Producers : For messages, they are often used for business decoupling and peak shaving. Peak shaving requires the message queue to accumulate data sent by the upstream, allowing the downstream to consume it slowly. At this time, the data that the downstream catches up to read is cold data not in memory.
Backtracking Consumption for Periodic Batch Processing Tasks : For streams, periodic batch processing tasks require scanning and computation from data dating back several hours or even a day.
Failure Recovery Scenarios: Consumer goes offline due to a failure and recovers after several hours; logical issues with the consumer, which, once fixed, require the consumption of historical data.
Summary of Results

AutoMQ maintains write throughput during cold reads : With the same cluster size, AutoMQ's send throughput remains unaffected during catch-up reads, while Apache Kafka's send throughput drops by 80%. This is because Apache Kafka reads from the disk during catch-up reads without IO isolation, occupying the read-write bandwidth of AWS EBS, which leads to a reduction in disk write bandwidth and a drop in send throughput. In contrast, AutoMQ separates reads and writes. During catch-up reads, it does not read from the disk but from object storage, thus it does not occupy the disk read-write bandwidth and will not affect send throughput.
AutoMQ does not degrade latency performance during cold reads : with the same cluster size, the average send delay of AutoMQ increases by approximately 0.4 ms during catch-up reads, compared to just sending, while Apache Kafka skyrockets by about 800 ms. The increase in Apache Kafka's sending delay is due to two reasons: Firstly, as mentioned earlier, catch-up reads will occupy AWS EBS read-write bandwidth, leading to a decrease in write traffic and an increase in delay. Secondly, during catch-up reads, the cold data read from the disk will contaminate the page cache, also resulting in an increase in write delay.
AutoMQ and Apache Kafka
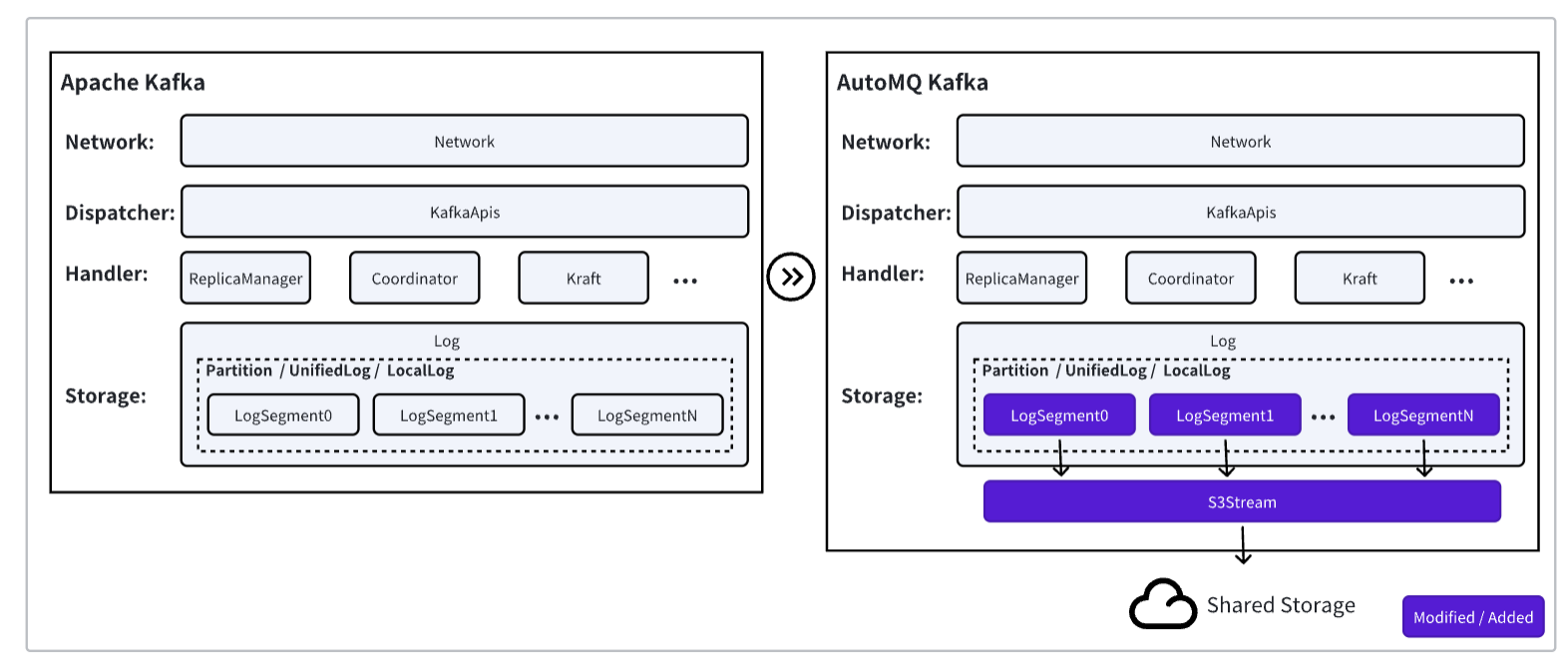
In summary, AutoMQ is a fork project from the Apache Kafka community. While retaining all the code from Apache Kafka's computational layer, AutoMQ has identified a suitable cut point (LogSegment) to thoroughly replace Kafka's storage layer. It redesigned and implemented a new shared storage stream engine called S3Stream based on EBS WAL and S3 [16]. This ensures 100% compatibility with Apache Kafka. AutoMQ is a dedicated supporter of the Apache Kafka ecosystem and continuously follows the latest fixes and changes in the Apache Kafka community, maintaining complete compatibility with the upstream Kafka community. Therefore, if you are already using AutoMQ, you can seamlessly transition to AutoMQ without making any modifications to your upper-layer applications or the data infrastructure built around Apache Kafka.
References
[1] AutoMQ: https://github.com/AutoMQ/automq
[2] Apache Kafka: https://kafka.apache.org/
[3] CNCF Cloud-Native: https://github.com/cncf/toc/blob/main/DEFINITION.md
[4] AWS What is Cloud-Native: https://aws.amazon.com/what-is/cloud-native/
[5] What Is Cloud Elasticity?: https://www.cloudzero.com/blog/cloud-elasticity/
[6]Cost-Effective: AutoMQ vs. Apache Kafka: https://docs.automq.com/automq/benchmarks/cost-effective-automq-vs-apache-kafka
[7] Benchmark: AutoMQ vs. Apache Kafka: https://docs.automq.com/automq/benchmarks/benchmark-automq-vs-apache-kafka
[8] Introducing Confluent Cloud Freight Clusters: https://www.confluent.io/blog/freight-clusters-are-generally-available/
[9] WarpStream: https://www.warpstream.com/
[10] [bitnami/kafka ] Auto Scaling: https://github.com/bitnami/charts/issues/22733
[11] How to scaling up Kafka Broker: https://github.com/strimzi/strimzi-kafka-operator/issues/1781
[12] Using AutoMQ to Optimize Kafka Costs and Efficiency at Scale: https://aws.amazon.com/cn/blogs/china/using-automq-to-optimize-kafka-costs-and-efficiency-at-scale/
[13] Karpenter:https://karpenter.sh/
[14] autoscaler: https://github.com/kubernetes/autoscaler
[15] How does AutoMQ achieve 100% protocol compatibility with Apache Kafka? https://www.automq.com/blog/how-automq-makes-apache-kafka-100-protocol-compatible
[16] S3Stream Overview: https://docs.automq.com/automq/architecture/s3stream-shared-streaming-storage/overview





