


.png)
Real-time data streaming powers everything from financial transactions to logistics and IoT systems. Platforms like Google Cloud Pub/Sub, AWS SNS, and Kafka make this possible, but as data volumes surge, Pub/Sub costs can spiral out of control. Factors like cross-zone traffic, storage retention, and over-provisioning often turn efficient systems into budget drains.
Controlling these costs isn’t just about sending fewer messages; it’s about designing smarter, cloud-efficient pipelines.
This guide explores 10 proven ways to cut your Pub/Sub costs, from batching and compression to cloud-native architecture, and shows how modern solutions like AutoMQ help achieve sustainable, scalable savings.
Key Takeaways
Message volume isn’t the only factor; network egress, storage, idle capacity, and operations all impact your Pub/Sub bill.
Use batching, compression, and efficient message formats to lower overhead and data transfer costs.
Co-locate producers and consumers or adopt architectures that eliminate interzone replication.
Dynamic scaling, cleanup jobs, and optimized retention prevent waste and reduce operational load.
Decouple compute from storage to scale elastically, eliminate replication traffic, and reduce costs.
Understand Your Cost Drivers
Before reducing your Pub/Sub cost, it’s essential to understand where the money goes. Most teams focus on message volume, but the real cost comes from multiple sources: throughput, data transfer, storage, idle capacity, and operational time.
Throughput costs depend on the total data published and delivered. Sending many small messages increases per-request overhead. Batching messages and compressing payloads can significantly lower the cost per byte.
Network transfer is a hidden expense. When data crosses availability zones or regions, cloud providers charge egress fees. In many Kafka or Pub/Sub workloads, cross-AZ traffic accounts for over 80% of total cost. Keeping producers and consumers in the same zone can instantly reduce this.
Storage and retention also add up. Extending message retention beyond what’s necessary multiplies storage costs. Set different retention periods for real-time, operational, and archival data.
Idle capacity is another culprit. Over-provisioned brokers or nodes reserved for “peak load” often stay underutilized. Elastic scaling or automation ensures you pay only for what you use.
Finally, consider operational overhead, the time engineers spend rebalancing partitions, scaling clusters, or troubleshooting. Automating these processes saves both labor and infrastructure costs.
10 Ways to Cut Your Pub/Sub Costs
After understanding your main cost drivers, it’s time to take action. The following ten strategies will help you identify and eliminate inefficiencies, from message-level optimizations to architectural transformations. Let’s dive in.
Batch Your Messages to Reduce Overhead
Batching messages before publishing is one of the easiest ways to lower Pub/Sub costs. Sending thousands of small messages separately wastes CPU and network resources, as each request triggers its own acknowledgment and metadata exchange.
By grouping messages for a short interval (a few hundred milliseconds) and sending them together, you reduce API calls and handling overhead, cutting your bill significantly.
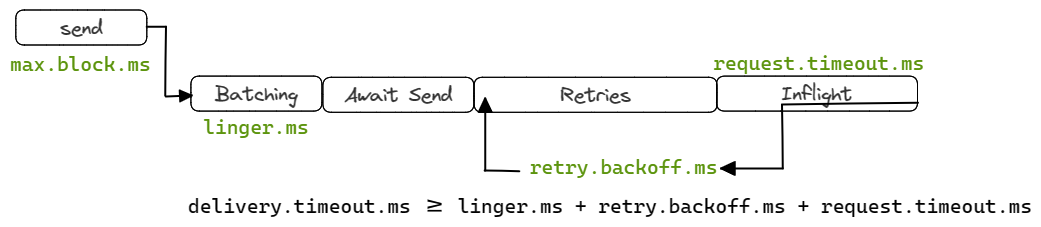
The key is balance. Larger batches lower cost but add latency, while smaller ones improve responsiveness. Most SDKs already support configurable batching, making this an effortless optimization.
Compress and Optimize Message Payloads
Once batching is in place, look at what you’re sending. Every unnecessary byte adds to your bill, especially when you process billions of messages a month.
Verbose formats like JSON or XML often waste bandwidth with repeated field names and whitespace. Switching to more compact schemas like Avro or Protobuf, or enabling compression with algorithms such as GZIP, Snappy, or Zstd, can shrink your payloads by 60–90%.
This directly translates to savings in:
Publish and delivery costs (less data transferred)
Network usage (smaller packets move faster)
Storage charges (less retained data)
Beyond compression, optimize message structure:
Remove redundant metadata or timestamps already present in headers.
Send identifiers instead of large embedded files.
Flatten nested structures where possible.
Even modest reductions of 20% per message can compound into major savings when your pipeline runs 24/7.
Co-Locate Producers and Consumers to Minimize Network Charges
Cross-zone traffic is a major hidden expense, often making up over half of Pub/Sub bills. Each inter-zone hop adds egress fees
For example, when a producer in us-east-1a writes to a broker in us-east-1b, and a consumer reads from us-east-1c, you’re paying for at least two cross-AZ transfers per message. Over time, that’s thousands of dollars in avoidable egress charges.
To fix this:
Pin workloads to the same availability zone by default.
Use zone-aware routing so producers and consumers prefer local brokers.
Local fan-out, global fan-in: keep most replication within a zone, aggregate across zones only when necessary.
Audit egress usage monthly to catch unexpected traffic.
Optimizing placement alone can reduce network costs by double digits.
Right-Size Message Retention and Storage Policies
Overly long retention periods quickly inflate Pub/Sub costs. Each stored message consumes space, replication bandwidth, and metadata resources; keeping even a few extra days of data can cost thousands monthly.
To right-size your storage:
Set retention based on purpose: keep real-time data for minutes, operational data for hours, and move historical data to cheaper storage like S3 or BigQuery.
Reduce default windows when quick acknowledgments make long retention unnecessary, and regularly clear temporary extensions.
Optimized retention not only cuts storage costs but also improves broker performance and recovery speed.
Automate Idle Resource Management
Cloud infrastructure is elastic, but only if you use it that way. Many teams pay for idle capacity because they size for peak load and leave clusters running full-time. This can waste 20–40% of your total streaming cost.
Avoid this by automating scaling and cleanup:
Enable autoscaling based on CPU, lag, or throughput. Scale down during quiet hours.
Adopt serverless or usage-based tiers for bursty workloads.
Schedule predictable downscaling for off-hours traffic dips.
Monitor utilization via dashboards to spot underused brokers or subscriptions.
Decommission unused topics regularly through automated cleanup jobs.
Treat capacity as dynamic, not static. Automation ensures you pay for performance only when you need it, not for idle brokers waiting for a spike that may never come.
Streamline Operational and Maintenance Costs
Beyond infrastructure, the human cost of operations adds up. Managing Kafka clusters or Pub/Sub systems can consume entire DevOps teams, time spent on scaling, partition reassignments, and manual failovers.
Automation and standardization are the keys:
Centralize monitoring and alerting for message lag, throughput, and health.
Use Infrastructure-as-Code (e.g., Terraform or Helm charts) for consistent deployments.
Automate rebalancing and failover wherever possible.
Consolidate observability with unified logging and metrics to cut troubleshooting time.
Reducing manual intervention reduces errors, improves uptime, and lowers the risk of costly outages. In many organizations, streamlining operations yields as much savings as any technical optimization.
So far, we’ve optimized what you send and where. Now, let’s fix how the system is built.
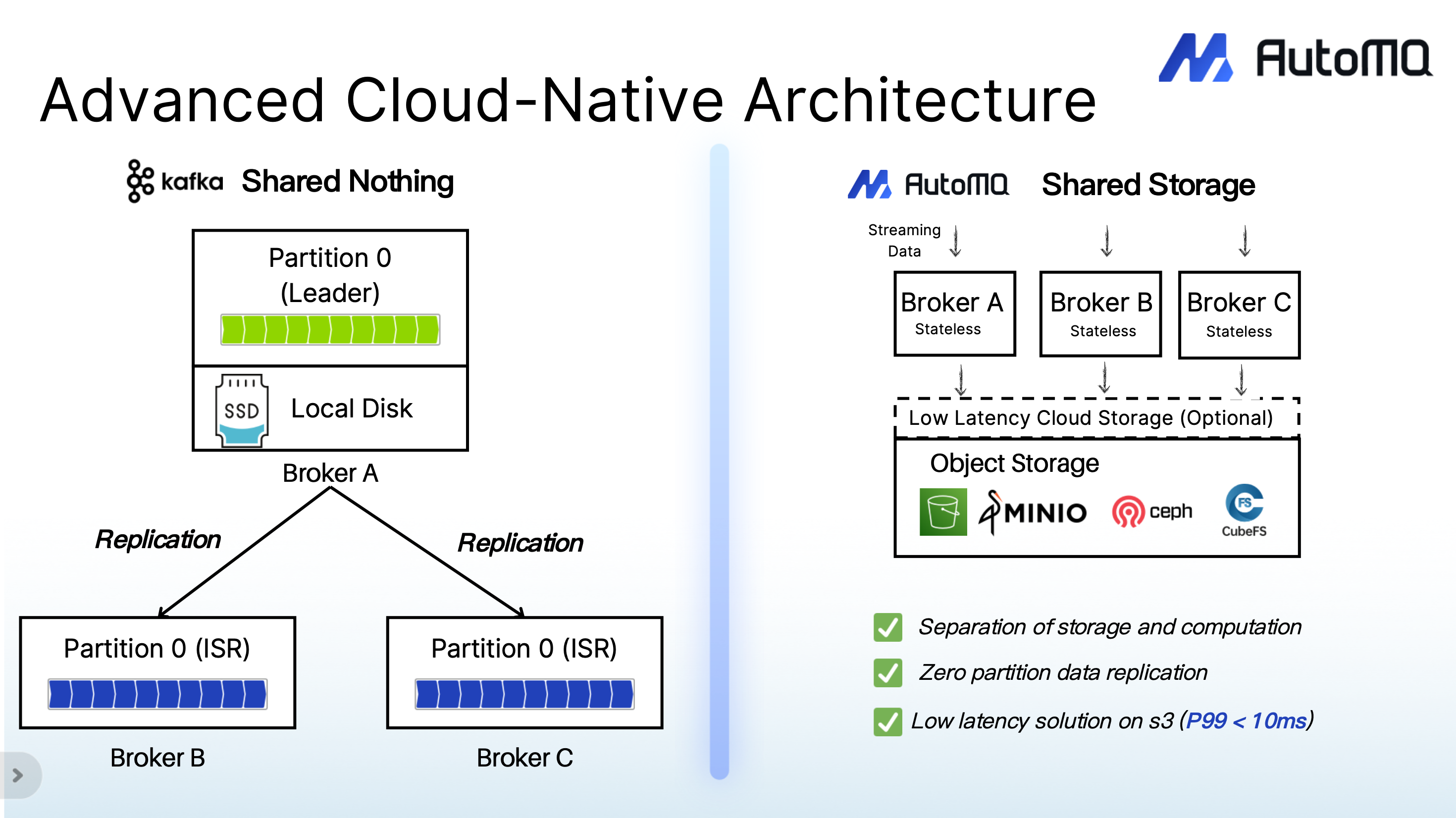
Separate Compute from Storage for True Elasticity
The biggest cost inefficiencies often come from architecture itself. In traditional Kafka-style systems, compute and storage are tightly coupled, meaning you must scale both together. That design forces you to over-provision, migrate data during scale-ups, and maintain redundant replicas across disks.
Separating compute from storage solves this. By decoupling the two layers:
You can scale compute independently of data.
Brokers become stateless, making scaling nearly instant.
Cloud storage handles durability, removing the need for redundant replicas.
You pay only for active compute, not idle capacity.
This is exactly the value of AutoMQ’s shared storage architecture; it stores message data directly on cloud storage like S3 while brokers simply handle compute. The result is a truly elastic Kafka experience: brokers scale in seconds, not hours, without rebalancing or downtime.
Eliminate Cross-AZ Replication and Traffic Costs
Cross–availability zone traffic is another major cost sink. Kafka’s default replication model requires writing multiple copies of each message across AZs to ensure fault tolerance, but this doubles or triples your data transfer fees.
AutoMQ eliminates this problem. Its architecture offloads durability to the cloud storage layer (e.g., S3 or FSx), which already provides multi-zone replication. Brokers no longer need to send data to peers in other zones, resulting in:
Zero interzone replication traffic
Local writes only, avoiding costly egress
Consistent durability backed by cloud-native storage
A typical Kafka workload writing at 0.1 GB/s with three replicas can generate over $14,000 per month in cross-AZ network fees. AutoMQ removes that category of cost while maintaining reliability, a clear win for both performance and budget.
Prevent Resource Waste with Self-Balancing and Fast Scaling
Uneven traffic distribution, or “hotspots”, is another hidden inefficiency. When a few brokers handle most of the load, others sit idle, forcing teams to over-scale clusters to maintain performance.
A self-balancing system continuously monitors utilization and automatically redistributes partitions to even out the load. Coupled with fast scaling, where brokers can join or leave the cluster in seconds, you get an agile infrastructure that adapts without manual rebalancing or downtime.
AutoMQ achieves this with stateless brokers and built-in self-balancing. In Grab’s deployment, partition reassignment dropped from six hours to under one minute, improving both cost efficiency and cluster stability.
Adopt a Kafka-Compatible, Cloud-Native Streaming Platform
After exhausting tactical fixes, the final, and most transformative, way to cut Pub/Sub cost is to choose the right foundation. A Kafka-compatible, cloud-native streaming platform lets you keep your existing ecosystem while gaining modern cost efficiency.
Platforms like AutoMQ offer:
100% Kafka API compatibility, so all your tools, clients, and connectors continue working.
Elastic, diskless architecture that scales compute independently of storage.
Zero interzone cost by leveraging shared cloud storage instead of inter-broker replication.
Lower operational overhead through stateless design and self-balancing.
Why AutoMQ Is a Strong Path for Cost Savings
Now, it becomes clear that lasting savings depend on architecture. Traditional Kafka deployments struggle with high replication overhead, interzone traffic, and complex scaling, all of which inflate cloud expenses. AutoMQ addresses these challenges by reengineering Kafka for the cloud era.
Diskless Kafka on Shared Storage
AutoMQ is the only low-latency, diskless Kafka® running on S3. It separates compute from storage through a shared storage architecture, allowing data to be written once to object storage services like S3 or regional EBS and accessed by all brokers. This approach eliminates the need for multiple replicas and enables true elasticity; brokers can scale in or out within seconds, without data migration or rebalancing.
Because cloud storage already provides durability and redundancy, AutoMQ removes the overhead of Kafka’s multi-replica ISR mechanism, reducing both infrastructure cost and operational complexity.
Zero Interzone Cost
Running Kafka across availability zones often leads to steep network bills. A typical workload writing at 0.1 GB/s with three replicas can generate over $14,000 per month in cross-AZ traffic fees on AWS. AutoMQ eliminates this problem by leveraging regional cloud storage so that producers write within their own zone, avoiding any internal cross-AZ replication. The result is zero interzone traffic cost while maintaining data reliability.
100% Kafka-Compatible and Easy to Adopt
AutoMQ is fully compatible with Apache Kafka APIs. It passes all official Kafka test cases and retains the original compute layer, ensuring that existing tools, including Strimzi Operator, Kafka Connect, and Schema Registry, work without modification. This makes migration seamless and eliminates vendor lock-in, allowing teams to adopt AutoMQ without rewriting applications or retraining developers.
Proven Results at Grab
A real-world example comes from Grab, whose data streaming platform faced issues with over-provisioning, slow scaling, and high maintenance costs. After switching to AutoMQ, Grab achieved:
3× cost efficiency improvement
3× increase in throughput per CPU core
Partition reassignment reduced from six hours to under one minute
These results demonstrate how AutoMQ’s cloud-native design turns static, resource-intensive Kafka clusters into elastic, cost-efficient streaming platforms.
Final Thoughts
Cutting Pub/Sub costs requires more than small optimizations; it demands smarter architecture. From batching and compression to automating scaling and streamlining operations, every layer contributes to savings. Yet the most impactful results come from adopting a cloud-native, Kafka-compatible platform like AutoMQ, which eliminates cross-AZ traffic, scales in seconds, and ensures zero vendor lock-in.
By combining efficiency, elasticity, and proven 3× cost savings in production, AutoMQ offers a clear path to modernize data streaming. To explore real-world performance or deployment options, visit AutoMQ
Interested in our diskless Kafka solution, AutoMQ? See how leading companies leverage AutoMQ in their production environments by reading our case studies. The source code is also available on GitHub.
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
JD.comx AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging






