
A new release, a new milestone for Kafka on cloud! We’re excited to announce AutoMQ 1.5.0 — the first and only open-source Kafka distribution fully running on Amazon S3, licensed under Apache 2.0 . Since going open source, AutoMQ has gained significant attention and adoption from developers and enterprises worldwide.
Kafka deployments on cloud face major challenges: high costs, scaling difficulties, expensive cross-AZ traffic, and limited control. Many teams rely on costly managed or closed-source solutions, sacrificing flexibility and transparency. That’s why we open sourced AutoMQ — to offer a truly cloud-native, production-grade, and openly accessible Kafka solution that puts control back in users’ hands and removes barriers for innovation.
With AutoMQ 1.5.0, users get a fully controllable, license-free Kafka that runs on S3 with low cost, high elasticity, and strong stability , without changing protocols or tooling. This release also introduces zero cross-AZ traffic, native Kafka–Iceberg Table mapping, and cloud-native consumer group rebalancing, making it easier than ever to run scalable, cost-efficient streaming workloads in the cloud.
Let’s take a closer look.
From Streams to Tables: Making Kafka and Iceberg Talk Natively
When building modern data platforms, many teams struggle to get real-time Kafka data into data lakes smoothly. The usual method—using tools like Spark or Flink to write into Apache Iceberg—is complex, costly, and adds latency. It also brings engineering headaches like schema changes, file compaction, and unreliable ETL pipelines that often break.
At AutoMQ, we think there's a better solution. That’s why we created Table Topic —a simpler, more stable, and real-time way to connect Kafka with Iceberg.
Introduced in AutoMQ 1.5.0 , Table Topic is a native binding mechanism that connects Kafka Topics directly to Apache Iceberg tables. Unlike conventional solutions that depend on external jobs, Table Topic is built into AutoMQ itself. Thanks to AutoMQ’s stateless architecture, it can continuously write Kafka message streams into Iceberg tables in real time—no Flink, Spark, Connect, or middleware required. With just a single configuration, users can materialize streaming data as structured table records, complete with automatic schema registration, evolution, field type mapping, and support for upserts. Leveraging the high throughput of S3 and AutoMQ’s fine-grained scheduling, Table Topic achieves real-time ingestion at several GiB/s while continuously compacting small files to optimize query performance—delivering true zero-ETL from Kafka to your data lake.
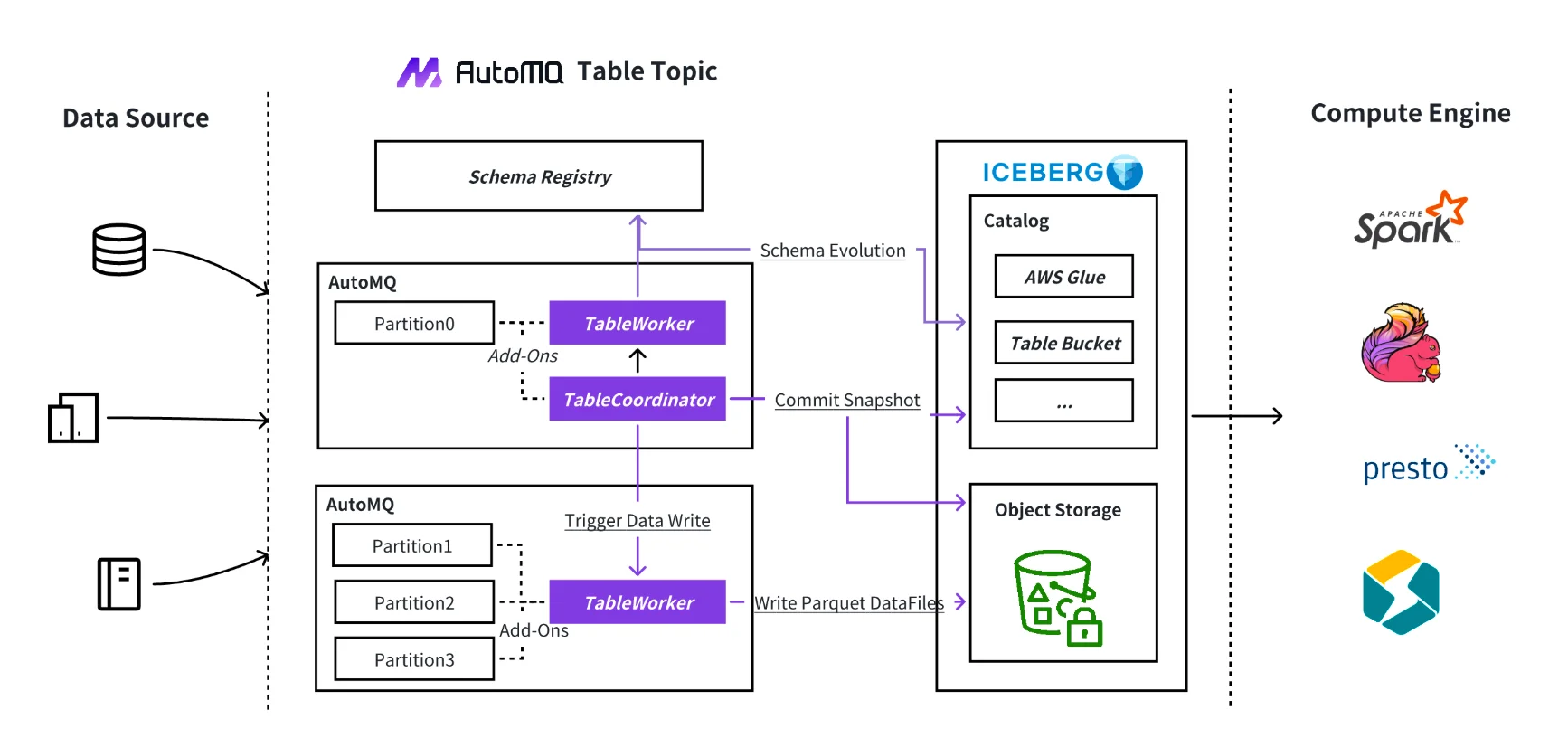
Table Topic isn’t just a performance boost—it redefines how Kafka data flows into data lakes. AutoMQ is the only open-source Kafka-to-Iceberg solution that runs natively on S3, delivering fresh, query-ready data without extra tools. It’s ideal for CDC, real-time analytics, and audit logs, where data is instantly available in table format. This simplifies your architecture, lowers compute costs, and bridges the gap between streaming and analytics.
For a deep dive into how Table Topic enables Kafka-to-Iceberg streaming without ETL, check out our article: Stream Kafka Topic to the Iceberg Tables with Zero-ETL
Rewriting Kafka Economics: Zero Cross-AZ Traffic
If you’ve run Kafka in the cloud, you know the pain: cross-AZ data transfer costs add up quickly . Every replica, every fetch, every consumer request traveling between zones—it’s both expensive and hard to control.
To address this, AutoMQ redesigned Kafka architecture using S3-based shared storage. By decoupling compute and storage, AutoMQ eliminates the need for direct data synchronization between Brokers across zones, fundamentally removing cross-AZ traffic. This architecture tackles production, replication, and consumption paths with targeted, traffic-isolating mechanisms:
-
Intercepting and Redirecting Production Traffic AutoMQ introduces an intelligent proxy layer at the Broker level that detects Produce requests originating from other AZs in real time. Instead of sending these requests directly across zones, the proxy uses S3 as an intermediary and establishes a cross-zone proxy channel to forward them to the appropriate partition Leader Broker. As a result, producers only need to communicate with Brokers within their local AZ, avoiding any cross-zone traffic.
-
Eliminating Cross-AZ Replication Traffic In traditional Kafka, Brokers replicate data across AZs, resulting in high volumes of cross-zone traffic. AutoMQ eliminates this by using S3 as a unified shared storage layer and leveraging erasure coding to create data replicas distributed across different AZs. With this approach, there is no need for direct data replication between Brokers, and cross-AZ replication traffic is completely eliminated.
-
Localizing Consumption Traffic AutoMQ deploys read-only partitions in each AZ, in addition to the Leader partition. Consumers can read data directly from these local read-only partitions, which access the data written by the Leader via S3 in real time. This local access model ensures consumers stay within their AZ, thereby avoiding cross-zone data reads.
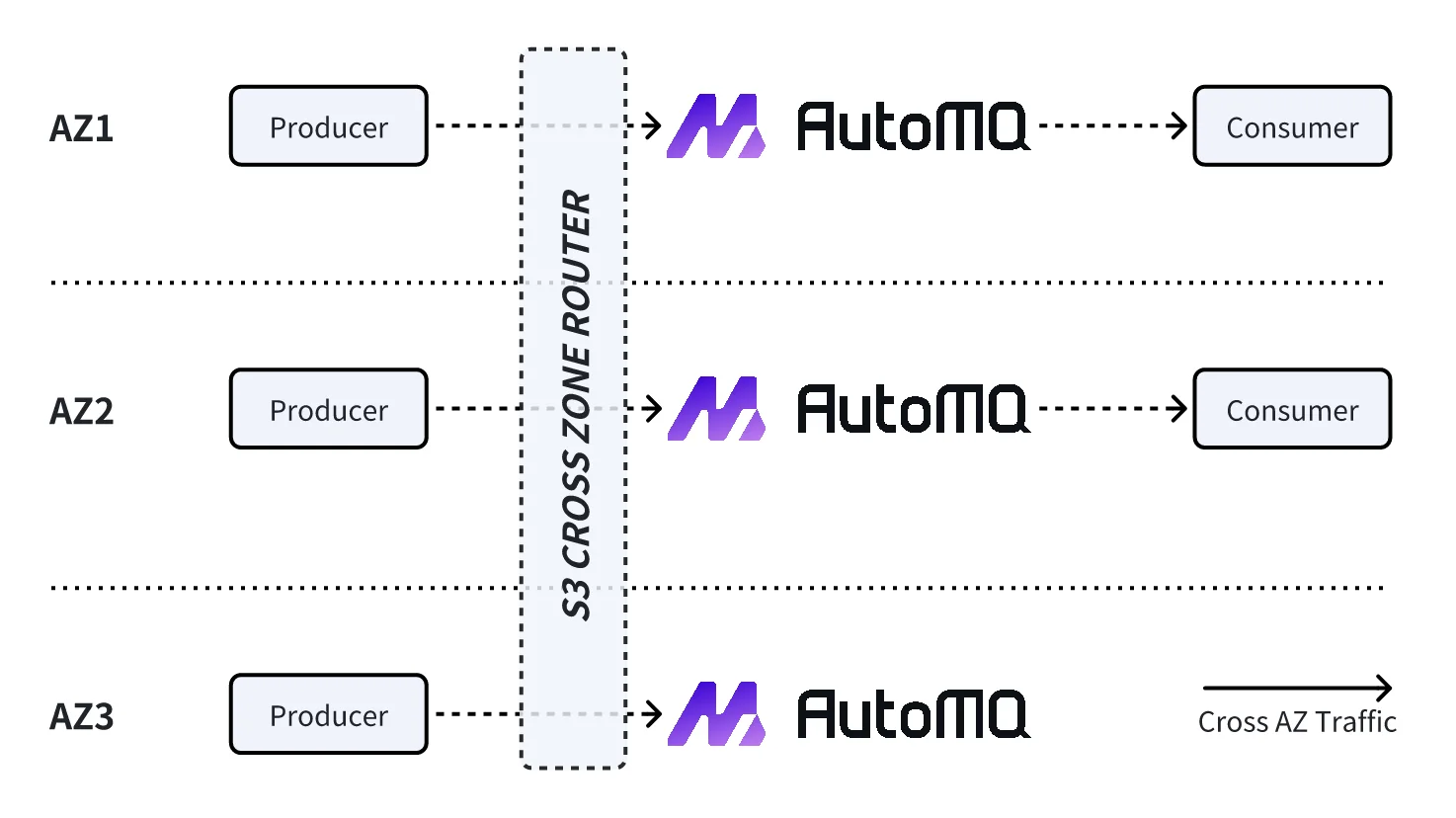
Through this redesigned architecture, AutoMQ achieves true zero cross-AZ traffic across production, replication, and consumption phases. This significantly reduces cloud Kafka operating costs—saving up to 60–70% on cross-zone data transfer—while lowering latency, avoiding network bottlenecks, and improving overall cluster stability. At the same time, it enhances fault tolerance, simplifies operations, and supports flexible horizontal scaling—offering a truly cloud-native Kafka experience.
Bitnami-Compatible Kubernetes deployment
Deploying and operating Kafka on Kubernetes often comes with a steep learning curve, complex configurations, and manual scaling challenges. While tools like Strimzi and KUDO offer operator-based solutions, they require deep knowledge of both Kafka internals and Kubernetes management.
With AutoMQ 1.5.0, we now offer Bitnami-compatible container images , enabling users to deploy AutoMQ directly using Bitnami’s Kafka Helm charts—without additional modifications. This makes it easier than ever to run a stateless, S3-native Kafka alternative on Kubernetes. You benefit from AutoMQ’s simplified architecture and elasticity while using the familiar Bitnami deployment workflow.
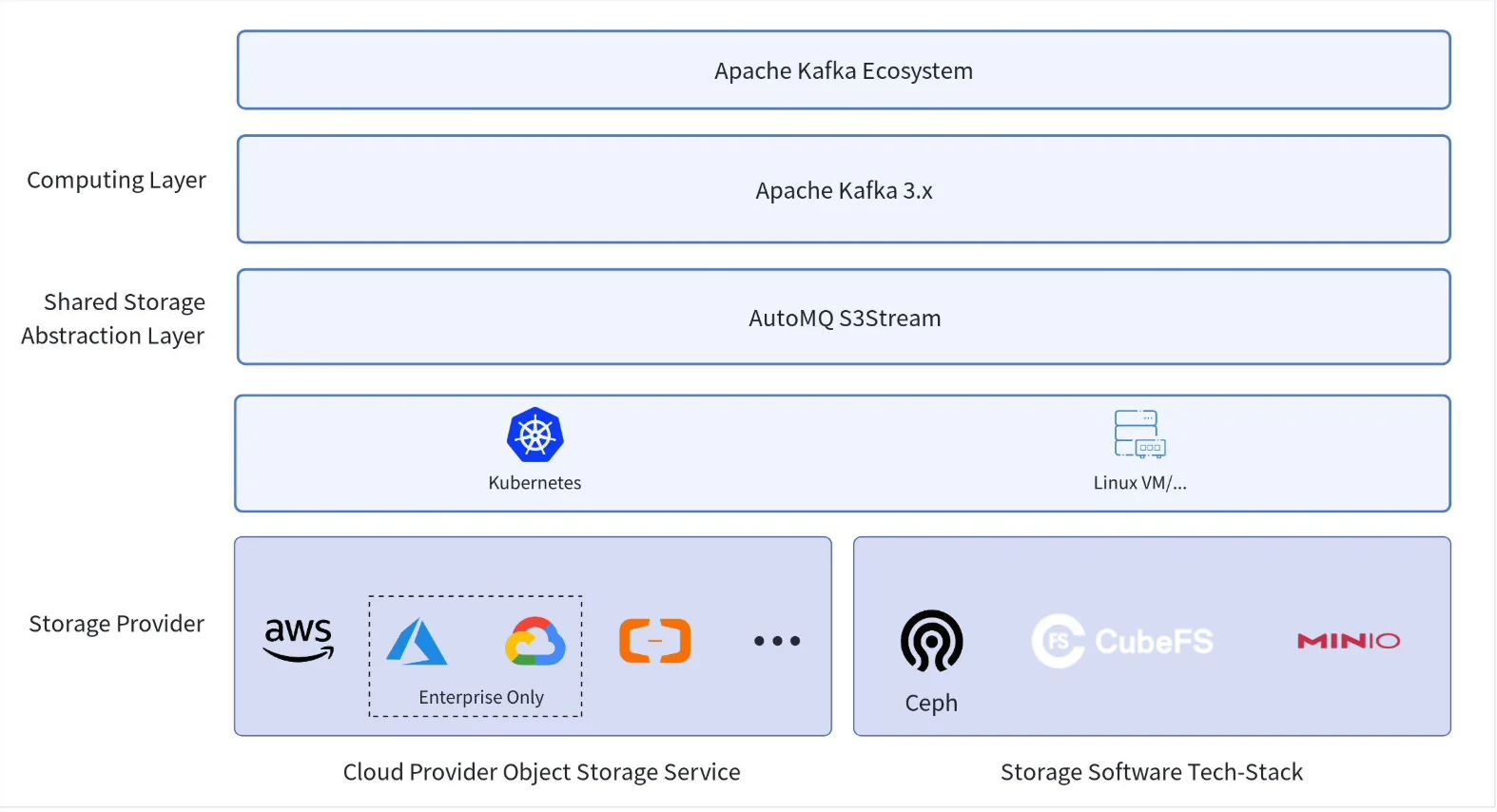
By combining AutoMQ’s cloud-native, stateless design with Bitnami’s widely adopted Kubernetes charts, users gain the best of both worlds: easy deployment, simplified management, and seamless scalability on any Kubernetes platform—including AWS EKS, GKE, and on-prem environments. Whether you’re migrating from Apache Kafka or starting a new streaming platform, this integration accelerates your Kubernetes journey with minimal effort and maximum performance.
Learn more about deploying AutoMQ on Kubernetes
AutoMQ 1.5.0 brings powerful new features—from zero cross-AZ traffic cost and native Kafka-to-Iceberg mapping (Table Topic) to Bitnami Helm chart support and cloud-native consumer rebalancing—all designed to simplify your architecture, cut costs, and enhance scalability.
Check out the Full Release Notes to explore how AutoMQ makes running Kafka in the cloud easier and more efficient.
Unlock Powerful Features with AutoMQ 1.5.0
Since open-sourcing, AutoMQ has attracted strong attention from developers and cloud-native architects alike. Several enterprises have already explored our capabilities in depth, successfully validated them across diverse production scenarios, and are now building long-term partnerships with us. More and more companies are joining the AutoMQ community, embracing the future of cloud-native Kafka.
We warmly invite you to be part of this transformation. AutoMQ is fully open-source, free to use, and protocol-compatible with Kafka—no migration of your existing toolchain required. You can seamlessly replace traditional Kafka deployments with AutoMQ today.
And if you're ready to dive in, we’ve made it even easier: click the Quick Start guide below to deploy AutoMQ with just one click and kickstart your journey to cloud-native Kafka!



