As modern data architecture evolves from simple data warehousing to the Data Lakehouse , enterprises are no longer just seeking massive storage scale—they demand a balance between high-performance analytics and low-cost management. When building this foundation, architects face a primary decision: the "Format War." Which of the three major open-source table formats—(iceberg, delta, hudi) —is best suited for the current business landscape?
This article provides an in-depth comparison of Apache Iceberg, Delta Lake, and Apache Hudi across architecture, ecosystem compatibility, and performance. Furthermore, it reveals a critical insight: once the format is chosen, how to solve the more hidden and difficult challenge of "Data Ingestion" using next-generation cloud-native architecture.
Overview of the Contenders
Before diving into the comparison, it is essential to understand the core philosophy behind these three formats. They all aim to bring database-like ACID transaction capabilities and metadata management to data lakes (such as Amazon S3 and GCS).
Apache Iceberg: The Standard of Openness
Originally developed by Netflix, Apache Iceberg was designed to solve performance bottlenecks for ad-hoc queries on massive datasets stored in S3.
-
Core Philosophy: Iceberg is highly abstract and engine-neutral. It does not bind to any specific compute engine, aiming to be the universal standard for table formats.
-
Key Features: It is renowned for its elegant metadata layer design, supporting powerful Schema Evolution (allowing table structure changes without rewriting data files). Its unique Hidden Partitioning feature enables query engines to automatically prune unnecessary partitions, significantly improving efficiency and reducing user complexity.
Delta Lake: Performance and Reliability
Open-sourced by Databricks, Delta Lake was initially deeply tied to the Spark ecosystem but has gradually moved towards universality.
-
Core Philosophy: Delta Lake emphasizes extreme query performance and data reliability. It strictly guarantees ACID properties via Transaction Logs and is a strong candidate for building high-performance Lakehouses.
-
Key Features: It leverages Z-Ordering (multi-dimensional clustering) and Data Skipping technologies to excel in query optimization. For batch processing scenarios that rely heavily on the Spark ecosystem and demand high data quality, Delta Lake is often the first choice.
Apache Hudi: The Streaming Pioneer
Apache Hudi (Hadoop Upserts Deletes and Incrementals), developed by Uber, was designed from the ground up to handle immediate updates and deletions for large datasets.
-
Core Philosophy: Hudi focuses on the Streaming Data Lake , specifically optimizing for Change Data Capture (CDC) and near-real-time analytics.
-
Key Features: It offers Copy-on-Write (CoW) and Merge-on-Read (MoR) primitives, allowing users to balance write latency against query performance. For businesses requiring minute-level data freshness and frequent Upsert operations, Hudi has a natural advantage.
In-depth Comparison
To help you make an informed choice, here is a side-by-side comparison of (iceberg, delta, hudi) across key dimensions:
| Dimension | Apache Iceberg | Delta Lake | Apache Hudi |
|---|---|---|---|
| Ecosystem | Excellent. Widely integrated by Snowflake, AWS Athena, StarRocks, Flink, and Trino. It is currently the most "neutral" choice. | Spark First. While support for Flink/Trino is growing, its best experience is still tied to the Spark/Databricks ecosystem. | Streaming First. Excels in Flink and Spark Streaming integration, but configuration for general query engines can be complex. |
| Schema Evolution | Most Mature. Supports column addition, deletion, renaming, and type promotion without affecting old data. | Supported. Supports basic schema changes, but complex evolution scenarios can be cumbersome. | Supported. Focuses mainly on schema validation and evolution during write operations. |
| Performance Focus | Query Planning. Optimized for metadata scanning of massive datasets, suitable for PB-scale warehousing. | Read Throughput. High read concurrency and throughput via storage optimization and caching. | Writes & Updates. Superior Upsert performance, ideal for streaming data with heavy updates/deletes. |
Recommendation:
-
If you prioritize architectural flexibility and multi-engine compatibility (e.g., using Flink for ingestion and Trino for queries), Iceberg is the safest bet.
-
If your tech stack is deeply reliant on Spark and focuses on batch processing performance, Delta Lake should be prioritized.
-
If your business involves high-frequency streaming Upserts or CDC synchronization, Hudi is the expert in the field.
From "Format Selection" to "Ingestion Challenge"
Selecting a Table Format is only the first step toward a modern data platform. Whether you ultimately choose (iceberg, delta, hudi) (with Iceberg often winning for its openness), you will immediately hit another wall: How to efficiently and cost-effectively inject massive real-time data into the data lake?
In traditional streaming architectures, importing real-time data streams from Kafka into a data lake often requires paying a heavy "ETL Tax" and facing hidden cost black holes.
Challenge 1: Bloated Architecture (The "ETL Tax")
To convert data from Kafka to Iceberg/Delta/Hudi, enterprises typically introduce heavy middleware components.
-
You may need to deploy extensive Kafka Connect clusters or write and maintain complex Flink/Spark Streaming jobs.
-
These components increase system complexity and points of failure. When upstream schemas change, the entire ETL pipeline often requires downtime for adjustments, sacrificing business agility.
Challenge 2: Hidden Cost Black Holes
Beyond explicit compute costs, traditional architectures hide significant network and storage waste:
-
Cross-Zone Traffic Costs: In cloud environments, traditional Kafka is usually deployed across Availability Zones (AZs) for high availability. Data replication between Brokers and cross-zone reads during ETL processes generate expensive inter-zone traffic fees.
-
Double Storage & Resource Over-provisioning: Data is stored once in Kafka and again in the Data Lake. Worse, to handle occasional peak traffic, enterprises often over-provision Kafka compute and storage resources based on peak loads, leading to extremely low utilization during off-peak hours.
Challenge 3: The Latency vs. Complexity Trade-off
This is a dilemma:
-
To reduce ETL complexity, many teams settle for T+1 batch processing, sacrificing data freshness.
-
To pursue real-time ingestion, one must handle complex Exactly-Once semantics and small file compaction, causing operational difficulty to skyrocket.
As seen in the comparison, while the table format solves "how to store," "how to transport" remains a bottleneck. We need an innovative solution to simplify this pipeline and eliminate intermediate steps.
AutoMQ & Table Topic
To thoroughly solve these challenges, AutoMQ has emerged. As a next-generation cloud-native Kafka service based on Object Storage (S3), AutoMQ not only reshapes streaming storage architecture but provides a shortcut to the data lake via its revolutionary Table Topic feature.
Table Topic: Stream is Table, Zero-ETL Ingestion
AutoMQ introduces the concept of Table Topic . To the user, it remains a standard Kafka Topic supporting high-throughput streaming writes. However, under the hood, AutoMQ utilizes a built-in Schema Registry and stream storage engine to automatically parse incoming data and convert it into Apache Iceberg table format stored on S3 in real-time.
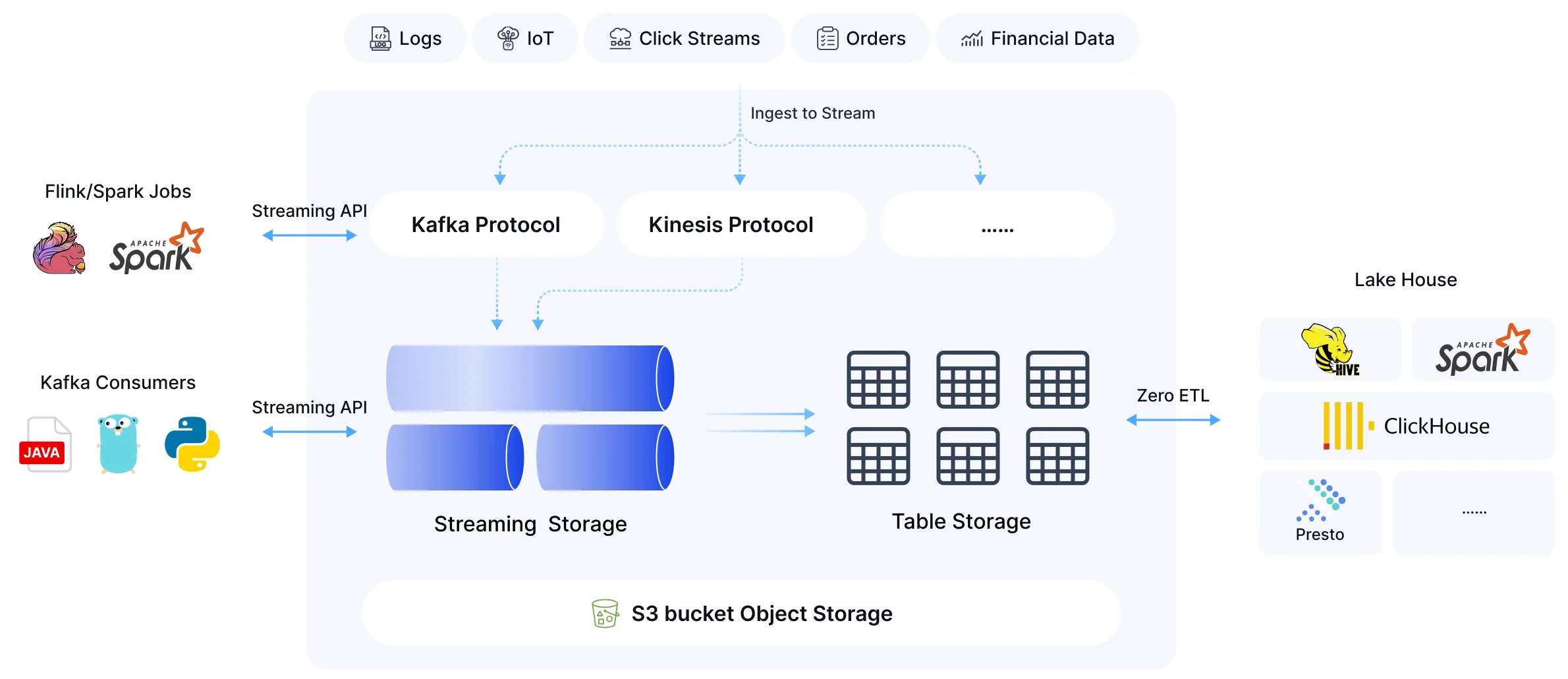
This design delivers disruptive advantages:
-
Zero-ETL: The conversion from stream to lake is automatically handled by the AutoMQ kernel, eliminating the need for Kafka Connect, Flink, or Spark jobs. You no longer need to maintain fragile ETL pipelines.
-
Real-time Visibility: Seconds after data is written to the Topic, it is available for query as an Iceberg table by analytics engines (like Athena or Trino), enabling a true Real-time Lakehouse.
-
Automatic Schema Evolution: When upstream business data structures change, Table Topic automatically synchronizes the Iceberg metadata, ensuring pipeline robustness.
Cloud-Native Foundation: Extreme Elasticity & 90% Cost Reduction
Powering the Table Topic capability is AutoMQ's unique S3-based stateless architecture .
-
Seconds-level Elasticity (Auto-Scaling): Unlike traditional Kafka, which requires hours for data replication during scaling, AutoMQ adopts a storage-compute separation architecture where Brokers are stateless. This allows partition reassignment to complete in seconds, easily handling sudden traffic spikes during ingestion.
-
Extreme Cost Efficiency:
-
Storage Savings: Leverages S3 to replace expensive local disks, offering affordable storage costs.
-
Traffic Savings: Through optimized multi-point read/write architecture, AutoMQ eliminates cross-availability zone (Cross-AZ) traffic costs within the cloud environment.
-
Total Savings: By combining S3, zero resource over-provisioning, and spot instance utilization, AutoMQ helps enterprises cut Kafka costs by up to 90% .
-
100% Kafka Compatible
Despite the cloud-native refactoring of the underlying architecture, AutoMQ maintains 100% compatibility with the Apache Kafka protocol. This means your existing producer applications and ecosystem tools can migrate seamlessly without code changes, allowing you to transition smoothly to a Zero-ETL architecture while enjoying new technological benefits.
Conclusion & Call to Action
In the competition among (iceberg, delta, hudi) , Apache Iceberg is becoming the de facto standard for building Data Lakehouses due to its openness and ecosystem advantages. However, for enterprises pursuing an efficient data strategy, simply choosing the right format is not enough.
AutoMQ redefines the standard for streaming data ingestion. Through Table Topic , it removes the technical barrier between streams and lakes, simplifying complex ETL pipelines into a simple configuration. This not only saves you 90% on infrastructure costs but also liberates your data team from heavy operational burdens to focus on creating business value.
Don't let cumbersome ETL pipelines be the bottleneck of your data architecture. Embrace the new paradigm of Zero-ETL ingestiontoday.
👉 [Click here to start using AutoMQ for free] AutoMQ and experience the speed of building a real-time Data Lakehouse with a single click via Table Topic.


