
If you're looking for a cost-effective and highly flexible Kafka service without vendor lock-in, AutoMQ is an excellent choice.
Background
What is AutoMQ
AutoMQ[1], inspired by Snowflake, is a Kafka alternative designed with a cloud-first approach. AutoMQ innovatively redesigns the storage layer of Apache Kafka® based on cloud architecture. It achieves a 10x cost reduction and 100x improvement in elasticity by separating durability to EBS and S3, while maintaining 100% compatibility with Kafka and offering better performance than Apache Kafka®.
What is AWS MSK
AWS MSK [2], or Amazon Managed Streaming for Apache Kafka, is a managed cloud service provided by AWS. Essentially, AWS MSK is a rehost of the open-source Apache Kafka® on the cloud, but AWS additionally provides tiered-storage and a Serverless version.
Stream systems are a critical component of data infrastructure, and selecting the right one is essential for building a modern data stack. This article provides a comprehensive comparison of AutoMQ and MSK across multiple dimensions, helping readers quickly grasp their differences and select the appropriate stream system for their needs.
TL;DR
The differences between AutoMQ, AWS MSK, and AWS MSK Serverless can be illustrated in the following diagram. If you are interested in the detailed comparison, please continue reading the subsequent sections.
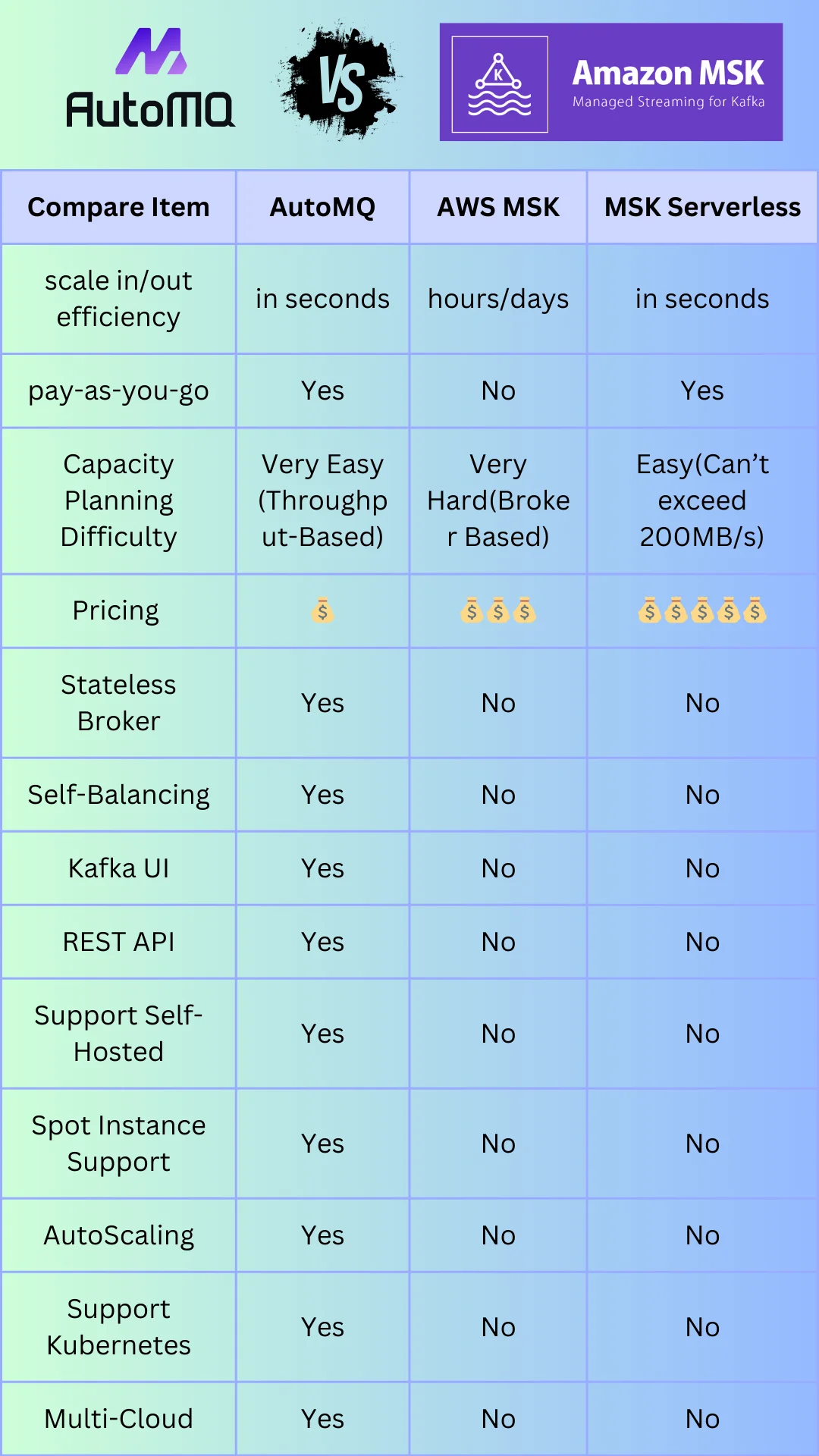
Elastic vs Non-Elastic vs Pseudo-Elastic
The cornerstone of Cloud-Native and Serverless: Elasticity
Over years of development, cloud-native technologies and Public Cloud have permeated various industries, becoming the foundation of modern data stacks. The concept of cloud-native mainly comes from CNCF's definition [4] and cloud providers' definitions [5]. Regardless of the definition, true cloud-native applications are emphasized to have elasticity. Elastic applications can quickly and efficiently adjust the resources they consume based on workload; non-native applications require cumbersome capacity assessments based on peak loads and overprovisioning for peak workloads. The following three diagrams [5] aptly illustrate the difference in resource usage between cloud-native and non-cloud-native applications. Non-cloud-native applications often adopt the overprovisioning strategy shown in Figure a for capacity planning. For example, in Apache Kafka, to ensure the service can support peak throughput and maintain low latency, users must first evaluate the relationship between cluster machine specifications and the supportable write throughput, then determine the cluster size needed for peak throughput. Additionally, they must reserve 30%-50% extra cluster capacity to handle unexpected "black swan" traffic, resulting in significant wastage of computing and storage resources. Conversely, using the underprovisioning approach shown in Figure b for capacity planning fails to support high-load scenarios, affecting business operations. True cloud-native applications, as depicted in Figure c, scale with elasticity, meaning resource consumption is pay-as-you-go. One of the greatest values of the cloud is its near-infinite resources and rapid resource provisioning and deallocation. When you no longer need these cloud resources, they must be promptly released; when needed, resources can be quickly provisioned via cloud APIs. Only by achieving this level of elasticity can the advantages of Public Cloud be fully realized.
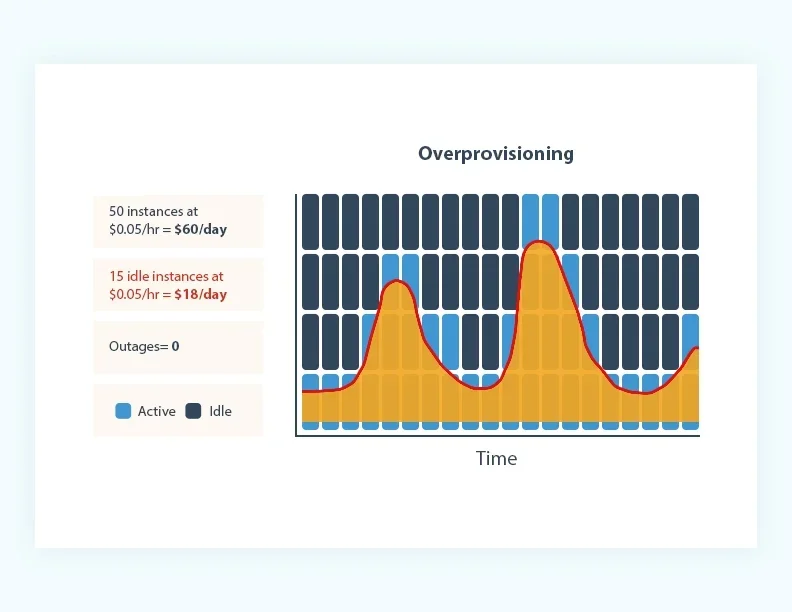
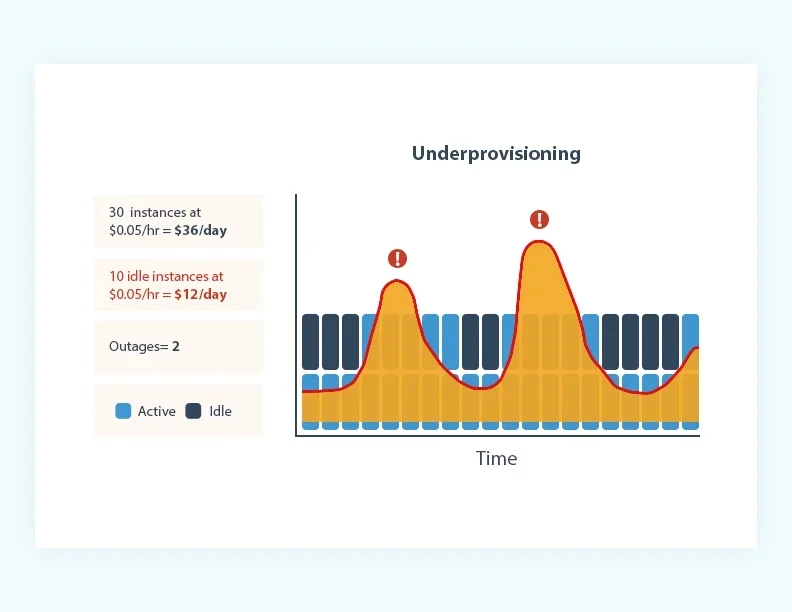
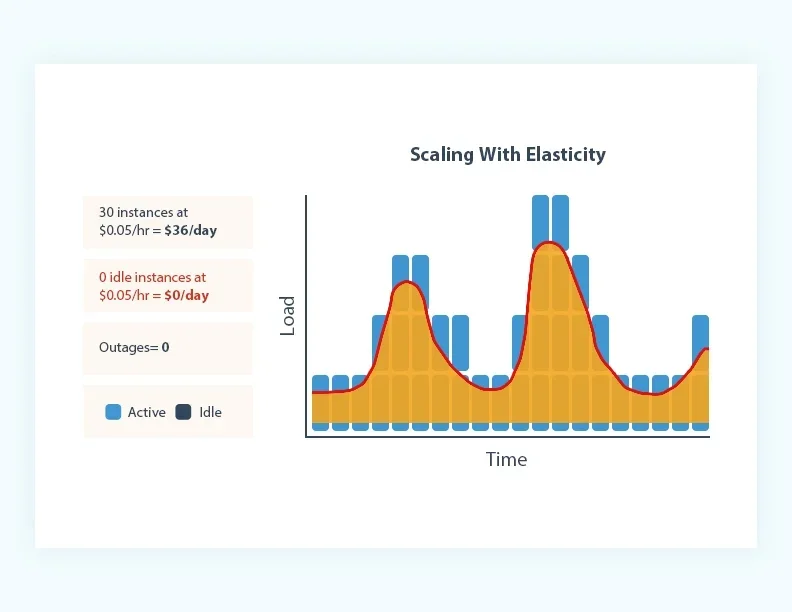
Comparison of Elasticity Capabilities
Conclusion: AutoMQ > MSK Serverless >>> AWS MSK

-
AutoMQ : AutoMQ fundamentally reimagines Apache Kafka's storage layer for cloud-native environments. By embracing a cloud-first approach, it offloads persistence to mature cloud storage services like EBS and S3. The primary distinction from Apache Kafka is that the entire computation layer is stateless. This statelessness makes the architecture highly elastic. Within this elastic architecture, AutoMQ can leverage cloud technologies like Spot instances and auto-scaling to significantly reduce costs while also operating more efficiently on Kubernetes. It is the only product among the three that truly achieves cloud elasticity, eliminating all the costs and operational complexities associated with Kafka's lack of elasticity.
-
AWS MSK Serverless : MSK Serverless is essentially pseudo-elastic because its elasticity is fundamentally based on AWS pre-allocating capacity for users, creating the illusion of being serverless. Since the underlying architecture is still the integrated storage-compute model of Apache Kafka, there is no real technological breakthrough. The costs incurred by this pre-allocated capacity are ultimately reflected in the user's actual bill. Several objective facts demonstrate the pseudo-elastic nature of MSK Serverless.
-
MSK Serverless supports only 200MB/s write and 400MB/s read [8] : Clearly, there is cluster isolation between tenants, with each cluster reserving a peak capacity of 400MB/s to create the illusion of being serverless. This limited elasticity means that MSK Serverless is applicable in very limited scenarios.
-
By default, a maximum of 120 partitions is allowed, with each partition supporting up to 250GB and a data retention period of one day [9] : This is also evidently a limitation set by AWS to control costs. Since MSK Serverless still uses Apache Kafka's technical architecture at its core, it cannot achieve true auto-elasticity. Therefore, it can only provide the so-called serverless experience through quota limits and pre-allocated capacity. Under these default constraints, users can only apply MSK Serverless to low-traffic business scenarios, making it difficult to adapt to future business growth.
-
-
AWS MSK : AWS MSK, as a cloud-hosted Kafka cluster, offers significant convenience compared to self-managed clusters in terms of cluster creation and monitoring integration. However, its elasticity capabilities remain as weak as those of Apache Kafka. Users must plan for peak loads and reserve sufficient capacity to ensure workloads continue to function smoothly as they grow. Due to the lack of elasticity, this pre-reservation of resources can lead to several side effects:
-
Capacity evaluation significantly increases TCO : AWS MSK is billed based on Broker specifications. Many users overlook the complexity and challenges associated with capacity evaluation. To ensure the stability of production systems, developers need to spend a significant amount of time testing performance across different Broker specifications to accurately assess the cluster capacity required for peak throughput. Factors such as replica count, read/write ratio, network bandwidth, SSD IO bandwidth, and retention time must be considered for their impact on writable throughput, substantially increasing deployment costs. Moreover, if future scaling is required, a new capacity evaluation must be conducted. This evaluation is a labor-intensive and high-cost task, significantly increasing the TCO for users of AWS MSK.
-
Pre-reserved capacity leads to resource wastage : Accurately evaluating and predicting read/write throughput is very challenging. To avoid efficiency issues when scaling AWS MSK, users can only pre-reserve capacity based on peak throughput. Additionally, to account for unforeseen traffic spikes (common in e-commerce scenarios), users need to reserve an additional 30%-50% capacity. Imagine if a user's average write throughput is 100MB/s, to handle peak throughput of 1GB/s, they need to provision a cluster that can handle 1.3GB/s to 1.5GB/s, resulting in 92% of the cluster capacity being wasted.
-
Scaling Impacts on Business Read/Write Operations, Unable to Meet Future Business Changes : Business operations are continually evolving. Even with pre-allocated capacity, it's inevitable that cluster capacity will need to be adjusted in the future. Among the customers of AutoMQ services, there are real cases from new energy vehicle companies and e-commerce firms. These companies typically experience marketing events, such as new model releases or discount promotions, during which the Kafka clusters need to handle significantly higher traffic than usual. This necessitates scaling the Kafka clusters up during the events and scaling them down once the events are over. This process poses a high-risk and potentially disruptive operation for businesses. For AWS MSK, the scaling period involves substantial data replication between brokers. This process can take hours to days, and more critically, the read and write operations of the moving partitions can be affected during the reassignment. Each time scaling is required, the development personnel responsible for AWS MSK operations are not only anxious about capacity adjustments but also need to inform and coordinate with business teams, bearing the potential production and consumption disruptions caused by the reassignment. Furthermore, if a failure occurs due to scaling, AWS MSK users typically have no recourse to mitigate the impact. The author once performed a scale-down operation on an AWS MSK cluster and had to wait over three hours, during which the operation could not be interrupted and had to be completed in its entirety.
-
AWS MSK (Serverless) does not support Kubernetes.

Kubernetes is a significant innovation in the cloud-native technology field and the culmination of cloud-native technologies. Kubernetes leverages cloud-native container technology, elasticity, IaC (Infrastructure as Code), and declarative APIs to provide enterprises with a standardized, general-purpose, and efficient cloud-native technology foundation. By adhering to cloud-native best practices and migrating applications that align with cloud-native principles to Kubernetes, enterprises can benefit from its efficient automated operations, resource management, and rich ecosystem. For instance, core services on Alibaba Cloud predominantly run on K8s. Utilizing Kubernetes in enterprises of a certain scale can yield greater benefits. Many of AutoMQ's large-scale clients are extensively using K8s or migrating their core data infrastructure to K8s.
AutoMQ has excellent support for K8s. In the Apache Kafka community, there are outstanding products like Bitnami and Strimzi within the K8s ecosystem. Developers in these communities have also called for support of AutoScaling [10] [11]. However, due to the inherent monolithic architecture of Apache Kafka, it is challenging to achieve horizontal scaling on K8s. Deploying Apache Kafka on K8s essentially rehosts the Kafka from an IDC data center to K8s without truly leveraging K8s' advantages. Conversely, AutoMQ supports a stateless Kafka Broker by cloud-native transformation of Kafka's storage layer. You can deploy AutoMQ on AWS EKS [12] and utilize K8s ecosystem products like Karpenter [13] and Cluster AutoScaler [14] to support AutoMQ's auto-scaling.
Currently, AutoMQ supports deployment on your own K8s, whereas AWS MSK and MSK Serverless do not support deployment on your K8s. If you aim to deploy Kafka services on K8s in the future to better collaborate with your other applications, AutoMQ is the recommended choice.
Cost Advantage
When it comes to pricing, we will not compare AWS MSK Serverless's price advantage. AWS does not provide the pricing for MSK Serverless in its price calculator. It has numerous limitations and is significantly more expensive than AWS MSK. The pricing model of AWS MSK Serverless is different from that of AutoMQ and AWS MSK, contributing to its high cost. Besides the fixed instance holding cost, it charges based on user traffic [17], with inbound traffic costing $0.1/GB and outbound traffic costing $0.05/GB. Assuming a 1:1 production-consumption ratio and a daily data write of 100TB, the actual cost would be $15,360 per day, almost matching AutoMQ's monthly subscription fee. Therefore, we will compare the pricing between AutoMQ and MSK.
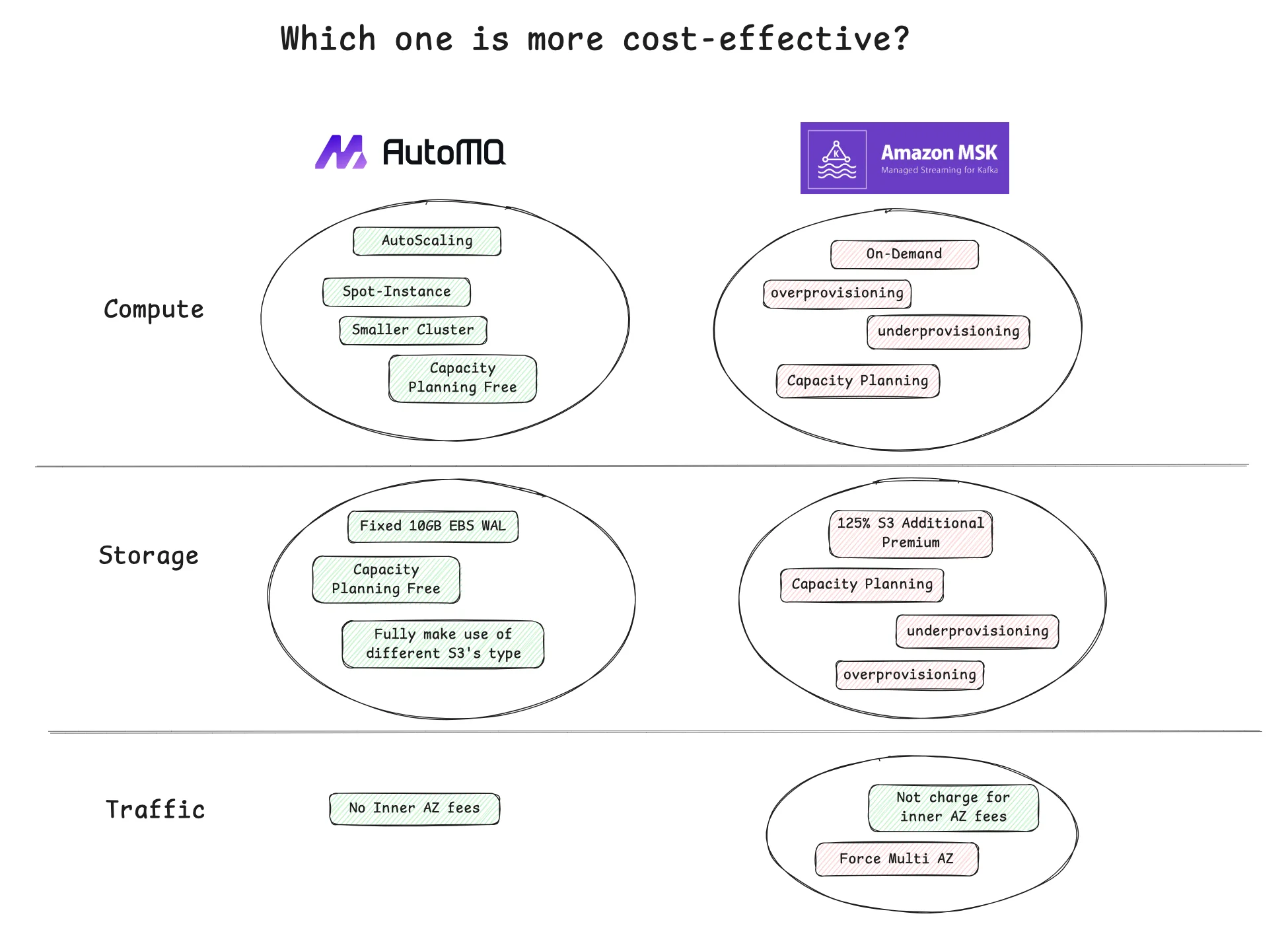
-
Compute Layer : AWS MSK uses the Apache Kafka technology stack at its core, making it unable to help users reduce costs as effectively as AutoMQ.
-
Spot Instances : For example, in AWS cn-northwest-1, the on-demand price for an r6i.large instance is ¥0.88313/hour, while the price for a Spot instance is ¥0.2067/hour. In this example case, using Spot instances can save 76% of the cost compared to on-demand instances.
-
AutoScaling : Because AutoMQ’s computing layer is stateless, it provides a foundation for AutoScaling. For AWS MSK, due to its inherent lack of elasticity, scaling operations are extremely risky and time-consuming. Regular scaling operations are already difficult to implement, let alone achieving AutoScaling. AutoMQ can quickly AutoScale to provide resources that match actual load changes, thereby reducing resource waste and lowering costs. The more volatile the user traffic, the more cost savings achieved through AutoScaling.
-
Compared to MSK, AutoMQ can handle greater read and write throughput with fewer machines : On AWS, machine network bandwidth is correlated with its specifications. Only larger instance types can utilize higher network bandwidth. Assuming a 1:1 write model, for every unit of incoming write traffic, AutoMQ's outbound traffic includes one unit of consumer consumption traffic and one unit of write-to-S3 traffic. In the same scenario with AWS MSK using tiered storage, in addition to the same consumer and S3 write outbound traffic as AutoMQ, there is an additional 2 units of traffic for replication between brokers. Therefore, for a single broker, AutoMQ only needs an EC2 instance that can handle 2 units of outbound traffic bandwidth, while MSK requires an EC2 instance that can handle 4 units of outbound traffic bandwidth. This allows AutoMQ to use much smaller instance types than MSK to handle the same read and write throughput.
-
No need for capacity planning, reducing manpower costs : AutoMQ Business Edition offers throughput-based billing. Users do not need to worry about the relationship between the cluster's capacity and the underlying computing, storage, and network resources. AutoMQ's technical experts spend significant time helping users select the optimal instance type and configuration. Whether creating new clusters or scaling, users do not need to spend time and manpower reassessing the relationship between resource consumption and throughput capacity.
-
-
Storage Layer : While MSK reduces local disk storage costs to some extent through tiered storage, its integrated compute-storage architecture still brings the following cost disadvantages:
-
Uncontrollable local disk space usage in MSK : Tiered storage in MSK still requires the last LogSegment of a partition to reside on local disk, with a default size of 1GB. In a production environment, it is challenging to control how many partitions should exist on a single Broker and predict their growth. Cluster maintainers face difficulties making accurate capacity assessments, such as determining the amount of local disk to configure per Broker. To ensure uninterrupted read and write operations, it is necessary to reserve 30%-50% additional local storage space during capacity assessments. Despite this, future data skew may cause high partition counts on a single Broker, impacting read and write traffic due to disk I/O contention. AutoMQ, with its built-in self-balancing component, can reassign partitions within seconds, avoiding data skew. Only a fixed 10GB EBS size is required as WAL. Using a 10GB GP3 volume on AWS incurs no cost due to the Free-Tier.
-
MSK has significant premium on object storage tiering : The pricing for MSK tiered storage is $0.06/GB per month, while AutoMQ, using object storage even including API call fees, costs approximately $0.024/GB per month. This results in a premium of up to 125% for MSK storage.
-
MSK lacks customization capabilities for S3, limiting cost-saving potential on object storage : MSK's tiered storage does not expose S3 to users, preventing them from configuring and using more cost-effective S3 types. For instance, in the Singapore ap-southeast-1 region, the storage cost for the Standard tier is $0.023/GB beyond 500TB. With AutoMQ, you can choose the S3 Intelligent tier, whose Archive Instant Access tier has an access cost of $0.005/GB, requiring only 22% of the Standard tier's storage cost to store the same amount of data.
-
No capacity assessment needed, reducing manpower costs : Using MSK requires manually testing, validating, and assessing the amount of local disk required for each Broker. In contrast, AutoMQ does not require users to perform cluster capacity assessments, similar to the compute layer.
-
-
Network :
- MSK forces multi-AZ, resulting in high testing costs : This is often an overlooked hidden cost. Besides the production environment, users often need to deploy various test and prerelease environments. MSK mandates the use of multi-AZ deployment. When conducting stress tests in a testing environment, AWS charges significantly for cross-AZ traffic. For example, if a stress test writes 100 TB of test traffic, with a cross-AZ traffic fee of $0.02 per GB, you will incur an additional cost of $2048. By using AutoMQ, you can choose a single-zone deployment for your testing environment, saving a substantial amount of money.
Service Support Comparison
AutoMQ > AWS MSK = AWS MSK Serverless

In terms of service support and assurance, AutoMQ offers the following two notable differences compared to AWS MSK, aside from having a slightly higher SLA:
- AutoMQ Business Edition provides free direct support from technical experts : Most major cloud providers do not offer direct interaction with their core product development teams to customers as this significantly increases their costs. If you use AWS MSK, your support requests will pass through multiple handlers before reaching the core development team. AutoMQ Business Edition offers more user-friendly commercial support, allowing direct consultation, troubleshooting, and diagnosis with the core development team, and rapid intervention in emergencies. Shorter and more professional support means your queries will receive better quality responses, reducing the time your staff spends on problem-solving and significantly lowering the overall TCO. Notably, this commercial technical support from AutoMQ is included in your business subscription at no extra cost.
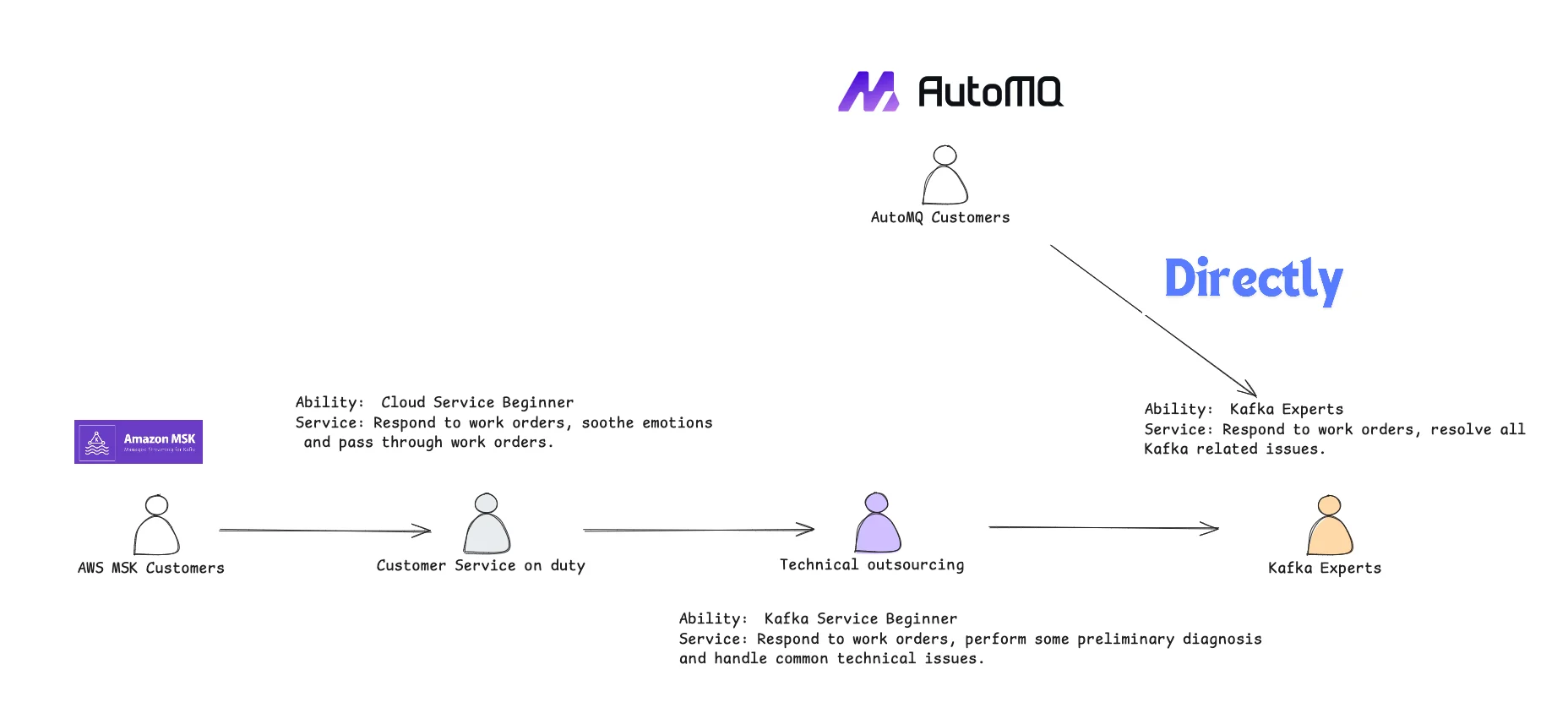
-
AWS MSK does not take responsibility for issues within Apache Kafka itself : The AWS MSK SLA explicitly states that it does not handle internal issues related to the Apache Kafka engine. This is unacceptable for many enterprises, as the primary reason for purchasing commercial products is to completely delegate this service capability to the vendor. Imagine a highly likely scenario where a critical bug is introduced in Apache Kafka 3.x, affecting the normal receipt and dispatch of messages. MSK, upon diagnosing that the bug is due to the internal engine of Apache Kafka, will not fix it nor compensate the user. The user’s only option is to identify which version of Apache Kafka does not have this bug and either downgrade or upgrade to a version that fixes it. Deciding which version to upgrade or downgrade to, whether MSK provides that version, and whether the adjusted version introduces new issues are all decisions that the user must make and execute. In contrast, with AutoMQ, for such critical bugs, the AutoMQ team will provide a fix within a week of discovering the issue in the community, assist, and guide users in upgrading versions, and take responsibility for all problems arising within the Apache Kafka engine. If you are considering using AutoMQ in a critical production environment, ask yourself the following questions:
-
If you encounter Kafka issues in projects using Amazon MSK or Amazon MSK Serverless, who is responsible and assumes the risk?
-
What is your response to security incidents related to the Apache Kafka open-source project?
-
How to Resolve Performance or Scalability Issues (Client and Server Side)?
-
-
Faster Apache Kafka Community Follow-Up Efficiency : As a professional Kafka service provider, AutoMQ provides fix versions on a weekly basis for critical issues and bugs. For major release versions of the Apache Kafka community, AutoMQ ensures the gap is controlled within about a month. Based on our understanding of AWS MSK, their follow-up speed for major release versions of Apache Kafka is significantly slower, often taking several months or even half a year.
Non-Cloud Vendor Lock-In, Multi-Cloud Support
AutoMQ >> MSK=MSK Serverless
AutoMQ does not have vendor lock-in issues. By choosing AutoMQ, users can freely choose which cloud provider to deploy AutoMQ on. Different cloud providers have their own unique product matrices and core strengths. Using AutoMQ allows users to fully leverage the advantages of multi-cloud. When users have multi-cloud deployment capabilities, they can not only fully utilize multi-cloud advantages but also have stronger bargaining power when using cloud providers' services. For example, it is well-known that AWS charges high fees for cross-availability zone network traffic. However, on Azure and Alibaba Cloud, cloud providers do not charge users for cross-availability zone traffic. If users deploy AutoMQ on Azure, they can take advantage of Azure's no-charge policy for cross-availability zone traffic and save a significant amount of costs.
In the long run, choosing AutoMQ, which avoids cloud vendor lock-in, can keep enterprises' technical architecture flexible enough to better adapt to the ever-changing cloud environment in the future.
References
[1] AutoMQ: https://github.com/AutoMQ/automq
[2] AWS MSK(Serverless): https://docs.aws.amazon.com/msk/latest/developerguide/getting-started.html
[3] CNCF Cloud-Native: https://github.com/cncf/toc/blob/main/DEFINITION.md
[4] AWS What is Cloud-Native: https://aws.amazon.com/what-is/cloud-native/
[5] What Is Cloud Elasticity?: https://www.cloudzero.com/blog/cloud-elasticity/
[6] The Pro’s and Con’s of using AWS MSK Serverless: https://mantelgroup.com.au/the-pros-and-cons-of-using-aws-msk-serverless/
[7] When NOT to choose Amazon MSK Serverless for Apache Kafka?:https://www.kai-waehner.de/blog/2022/08/30/when-not-to-choose-amazon-msk-serverless-for-apache-kafka/
[8] Amazon MSK FAQs: https://aws.amazon.com/msk/faqs/
[9] Create more partitions and retain data for longer in your MSK Serverless clusters:https://aws.amazon.com/cn/blogs/big-data/create-more-partitions-and-retain-data-for-longer-in-your-msk-serverless-clusters/
[10] [bitnami/kafka ] Auto Scaling: https://github.com/bitnami/charts/issues/22733
[11] How to scaling up Kafka Broker: https://github.com/strimzi/strimzi-kafka-operator/issues/1781
[12] Using AutoMQ to Optimize Kafka Costs and Efficiency at Scale: https://aws.amazon.com/cn/blogs/china/using-automq-to-optimize-kafka-costs-and-efficiency-at-scale/
[13] Karpenter:https://karpenter.sh/
[14] autoscaler: https://github.com/kubernetes/autoscaler
[15] AutoMQ SLA: https://docs.automq.com/automq-cloud/support/service-level-agreement
[16] AWS MSK SLA:https://aws.amazon.com/msk/sla/
[17] AWS MSK and Confluent. Are they really Serverless?: https://upstash.com/blog/aws-msk-confluent-serverless
[18] AWS EC2 types: https://aws.amazon.com/ec2/instance-types/?nc1=h_ls


