In 2026, the data streaming landscape looks nothing like it did a few years ago. Real-time data isn't optional anymore; it's the backbone of AI-driven products, analytics pipelines, and user experiences. Companies are re-evaluating how they run Kafka in the cloud, and two names dominate that decision: Confluent Cloud and Amazon MSK.
Both offer "managed Kafka," but their philosophies and trade-offs are miles apart. Confluent focuses on a complete enterprise-grade data streaming platform. MSK stays closer to native Apache Kafka, deeply tied to AWS infrastructure. Each has strengths and painful limitations that become obvious at scale.
This shows how Confluent vs MSK stack up for 2026: cost, elasticity, vendor control, and long-term flexibility. And by the end, you'll see why a new generation of Kafka-compatible solutions, led by AutoMQ, may redefine what "managed Kafka" means next.
Key Takeaways
-
Confluent Cloud delivers the most complete enterprise-grade Kafka experience, but its pricing and complexity make it heavy for fast-moving, cost-sensitive workloads.
-
Amazon MSK simplifies Kafka on AWS but remains bound by slow scaling, hidden cross-AZ costs, and single-cloud lock-in.
-
Both solutions were built for yesterday’s infrastructure realities, not for the scalable and cost-efficient data environments of 2026.
-
The future belongs to Kafka platforms that scale instantly, cost less, and run anywhere.
Overview of Confluent Cloud
Confluent Cloud isn't just Kafka hosted somewhere. It's a complete data streaming platform built around Kafka, with layers of governance, connectors, stream processing, and enterprise controls. The pitch is clear: "run Kafka without running Kafka."
Confluent manages everything: brokers, scaling, schema registry, ksqlDB, and observability, across AWS, GCP, and Azure. It's cloud-agnostic and fully managed, designed for enterprises that value control, compliance, and ecosystem maturity over cost. For large organizations with complex integrations, it's smooth. You get advanced SLAs, audited compliance, and deep monitoring without needing an internal Kafka team.
But the trade-off is steep. Confluent Cloud pricing scales fast, especially for high-throughput workloads. Networking and storage costs can multiply quickly, and since Confluent runs on public cloud infrastructure, you still pay for cross-AZ replication, egress traffic, and storage expansion. Elastic scaling is managed through predefined tiers, not instant auto-scaling.
In short, Confluent Cloud delivers a premium Kafka experience for teams willing to pay for it. It's the enterprise-grade, belt-and-suspenders version of Kafka, reliable, feature-rich, but expensive and sometimes rigid. The real question is whether that model still makes sense as data volumes and cost sensitivity explode in 2026.
Overview of Amazon MSK
Amazon Managed Streaming for Apache Kafka (MSK) takes a different path. Instead of building a platform around Kafka, AWS keeps it simple; MSK is Kafka as an AWS-native service. You spin up clusters through the AWS console, integrate with IAM, CloudWatch, and KMS, and get a managed Kafka experience that fits neatly into existing AWS workloads.
That simplicity is MSK's biggest draw. It's built for teams already committed to AWS who want to offload Kafka maintenance, no patching, no manual scaling of brokers, no security configuration from scratch. It supports standard Kafka APIs, so migrations are straightforward.
But MSK's tight AWS integration is also its ceiling. It locks you into the AWS ecosystem, making multi-cloud or hybrid setups a pain. Elastic scaling is slow, resizing clusters can take hours, and partition rebalancing often needs manual oversight. Cross-AZ replication adds significant network cost, which quickly stacks up for high-throughput use cases.
Operationally, MSK feels like a halfway house: less maintenance than self-hosted Kafka but far from truly cloud-native elasticity. For moderate workloads tied to AWS, it's a pragmatic choice. But for teams needing fast scaling, cost agility, or vendor independence, MSK's comfort zone can become a cage.
Key Comparison: Confluent vs. MSK
The "Confluent vs MSK" debate isn't about features, it's about fit. Both deliver Kafka as a service, but they solve different problems. In 2026, where elasticity, cost control, and independence define strategy, those differences matter more than ever.
Cost Efficiency
Confluent Cloud sits at the premium end. You pay for throughput, partitions, storage, and data transfer. It makes sense when you need enterprise SLAs, multi-region replication, and governance. But at scale, those extras stack up fast. MSK is cheaper per unit until cross-AZ replication, storage growth, and idle cluster time enter the picture. Its pricing looks simple, but hidden AWS costs quickly erode that advantage.
- Verdict: Confluent costs more upfront; MSK bleeds you slowly through infrastructure.
Elastic Scaling and Operations
Confluent's managed scaling and integrated monitoring give smoother operations but limited flexibility. Scaling is predefined, not instant. MSK automates basic management, but scaling can take hours, and partition reassignments require hands-on work.
- Verdict: Neither achieves proper cloud elasticity. Both remain semi-manual under the hood.
Vendor Lock-in and Flexibility
Confluent runs on multiple clouds; you can move workloads between AWS, Azure, and GCP. MSK is AWS-only. That's fine for AWS-first teams, but a deal-breaker for hybrid or multi-cloud strategies.
- Verdict: Confluent wins on portability; MSK locks you in.
Future-Readiness
Confluent is evolving into a complete data streaming platform with governance, pipelines, and stream processing. MSK remains a pure Kafka service. In 2026, with AI and event-driven workloads surging, organizations need elasticity, cost-efficiency, and freedom, not just managed hosting.
- Verdict: Both platforms are mature. But neither fully meets 2026 demands for elastic, low-cost, cloud-native Kafka. That's the gap newer architectures, like AutoMQ, are built to close.
Why Streaming Infrastructure Is Changing
By 2026, the way organizations handle data has shifted from movement to moment. Every system, from AI inference engines to digital payments, depends on milliseconds. Real-time pipelines aren't an upgrade anymore; they're survival infrastructure.
But that shift has exposed the limits of how Kafka was initially built and how today's managed services have evolved. Companies no longer struggle to "use Kafka." They struggle to scale it, afford it, and control it.
The New Pressures Shaping Streaming in 2026
-
Elasticity over capacity: Traffic patterns spike unpredictably. Static clusters mean wasted resources and delayed scaling.
-
Cloud cost discipline: Storage, replication, and cross-AZ transfer fees are now line items that CEOs question, not engineers justify.
-
Operational lightness: SRE teams won't babysit clusters at 3 a.m. The expectation is self-healing, not manual failover.
-
Freedom to move: Multicloud and hybrid environments are the default, so lock-in is a strategic liability.
This environment reframes the Confluent vs MSK decision. Both platforms manage Kafka, but neither was designed for this level of dynamism. Confluent adds enterprise power at a premium. MSK offers AWS convenience at the cost of agility. Both still carry the legacy of coupled storage, static scaling, and growing bills.
The winners in 2026 won't be whoever "hosts Kafka better." They'll be the ones who reinvent Kafka for the cloud era, elastic in seconds, cost-efficient by design, and free from ecosystem traps. That's the lens to evaluate every managed Kafka option through, and it's exactly where AutoMQ begins to separate itself.
Why AutoMQ Stands Out in 2026
If Confluent and MSK represent managed Kafka's past decade, AutoMQ represents what comes next. It rethinks Kafka for the cloud era, keeping everything developers love about Kafka's API and ecosystem, while removing the architectural baggage that makes it expensive and slow to scale.
AutoMQ is built on a diskless, shared-storage architecture, meaning brokers are stateless and data lives on cloud object storage like S3. That design instantly solves Kafka's most significant pain points: storage cost, scaling time, and operational overhead.
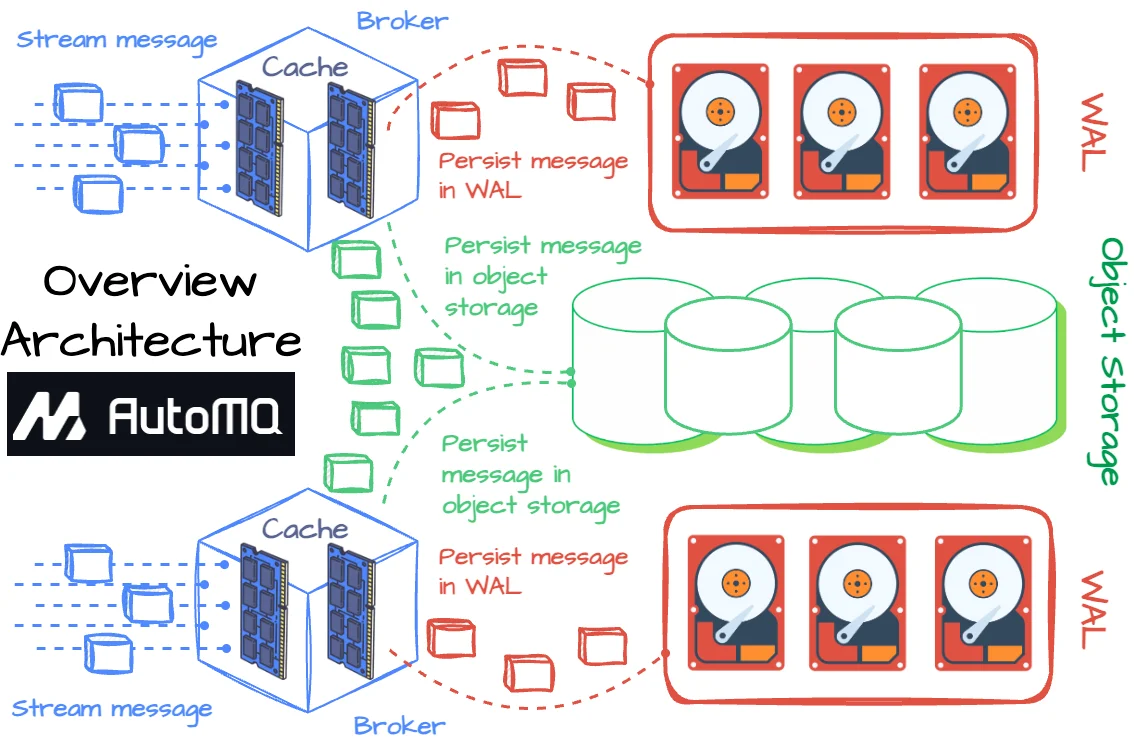
The result is a system that scales in seconds, self-balances automatically, and cuts total costs dramatically, up to 17× lower than Kafka, according to AutoMQ benchmarks and case studies like XPENG Motors, which reduced their Kafka-related costs by over 50%.
Because AutoMQ is 100% Kafka API compatible, teams don't need to rewrite code or lose ecosystem tools; it just runs faster and cheaper. It supports BYOC (Bring Your Own Cloud) deployment, giving enterprises complete control of data privacy while still enjoying a fully managed experience.
In short, AutoMQ brings what Kafka should have been in the first place: elastic, cost-efficient, and cloud-native. It's not a replacement for Kafka; it's the evolution of it. And for organizations making infrastructure decisions in 2026, that evolution matters more than ever.
Conclusion
Both Confluent and MSK pushed Kafka forward, but they're still bound by yesterday's assumptions about infrastructure and scale. In 2026, teams no longer want "managed Kafka." They want elastic Kafka, affordable Kafka, and Kafka without lock-in.
Confluent delivers enterprise power at a premium. MSK delivers AWS convenience with constraints. Neither truly adapts to the cloud-native reality where workloads scale unpredictably, budgets are tighter, and speed is everything.
That's where AutoMQ stands apart. It delivers Kafka's power with none of its legacy cost or rigidity. Fully compatible, instantly scalable, and cloud-ready by design, AutoMQ is the logical next step for teams that have outgrown traditional managed services.
Still struggling with skyrocketing Kafka bills and the "ops tax" of manual disk management? It's time to stop babysitting your clusters. Try AutoMQ Cloud for Free and experience how diskless architecture slashes costs and automates scaling—no credit card required. See how others made the switch in our case studies or explore the project on GitHub.


