
Introduction
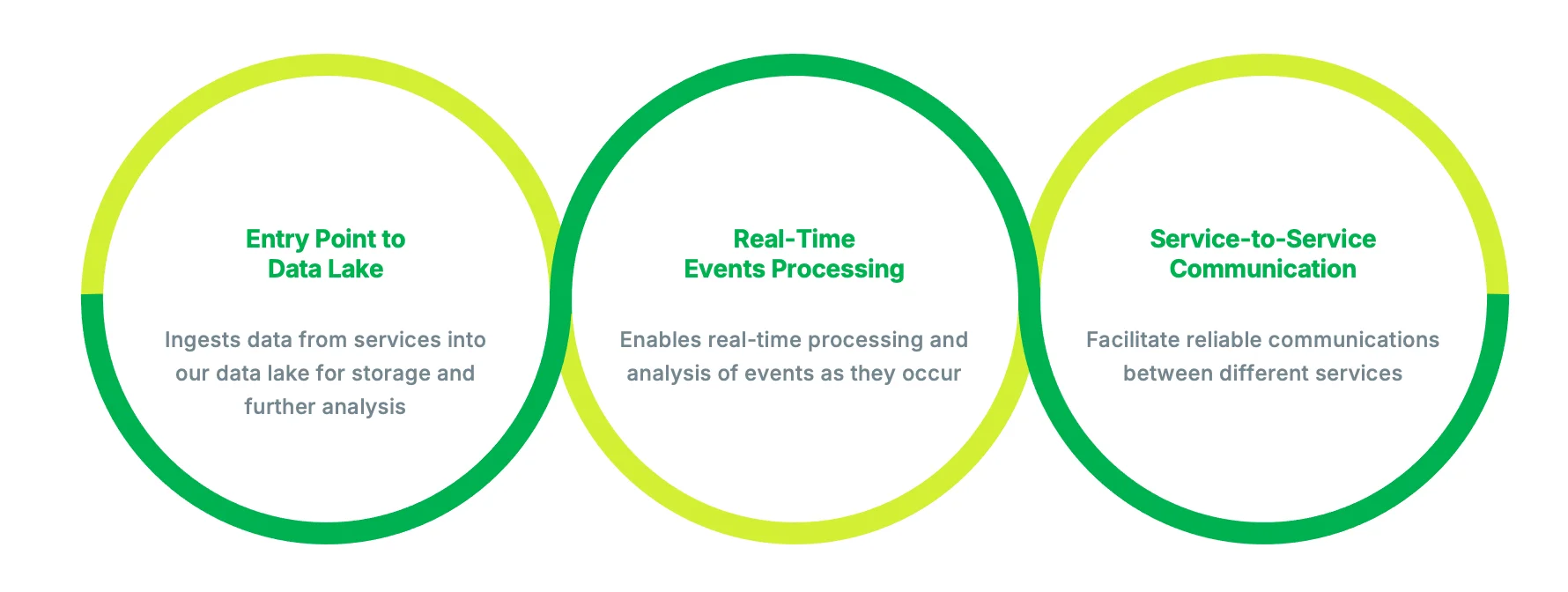
Coban, Grab’s real-time data streaming platform team, has been building an ecosystem around Kafka, serving all Grab verticals. Our platform serves as the entry point to Grab’s data lake, ingesting data from various services for storage and further analysis. It enables real-time processing and analysis of events as they occur, which is crucial for many of our applications and services. The platform drives high volume, low latency, and highly available data streaming at terabytes per hour scale.
Along with stability and performance, one of our priorities is also cost efficiency. In this article, we will explain how the Coban team has improved the efficiency and reduced the cost of the data streaming platform by introducing AutoMQ.
Problem statement
In the past, the main challenges we encountered with our Streaming platform were the following four points.
-
Difficulty in scaling compute resources : One of the main challenges was scaling compute resources, which caused spikes during partition movement and hindered operational flexibility.
-
Disks can’t scale independently which case extra operation complexity : Disk usage varied significantly across brokers. Adding storage required either scaling out the cluster or scaling up the disk on brokers, both of which were not ideal solutions.
-
Over-provisioning based on peak led to resource waste : Our current provisioning based on peak usage led to lower optimization of cloud resources during off-peak periods, resulting in higher costs and inefficiencies.
-
High-risk partition rebalancing : Partition rebalancing during cluster maintenance led to prolonged periods of increased latency, impacting overall system performance and user experience.
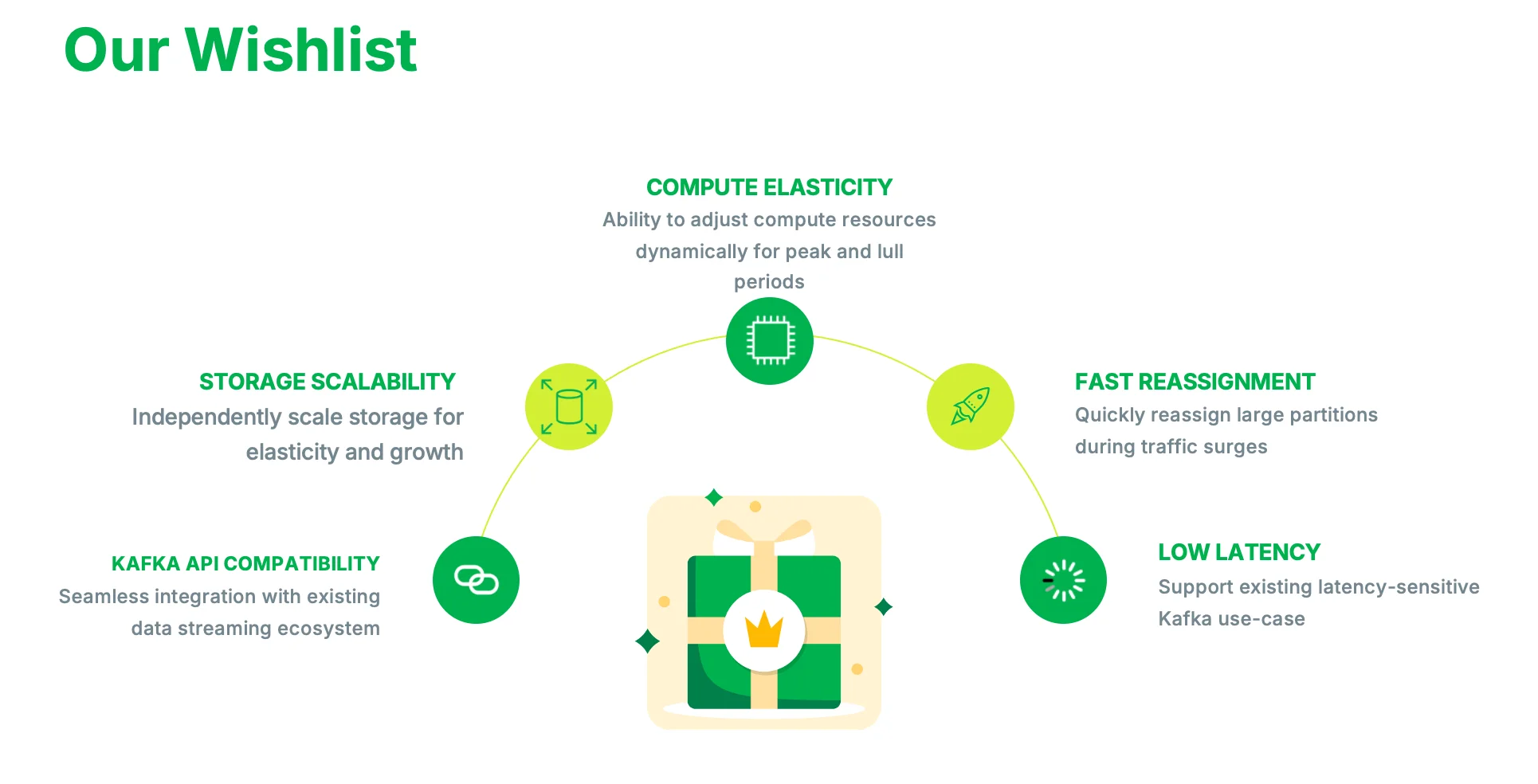
Given these challenges, we needed a solution that could address these issues effectively. This brings us to our wishlist and the reasons why we chose AutoMQ.
-
Great Elasticity : We wanted the ability to adjust compute resources dynamically to accommodate peak and lull periods without causing disruptions.
-
Separation of Storage and Compute : It was essential to have the capability to independently scale storage to handle elasticity and growth efficiently.
-
Excellent Compatibility with Kafka : Seamless integration with Grab’s existing data streaming ecosystem was crucial to avoid major overhauls and disruptions.
-
Fast and Stable Partition Migration Capabilities : The ability to quickly reassign large partitions during traffic surges was important to maintain performance and reliability.
-
Low Latency : Supporting existing latency-sensitive Kafka use-cases was a priority to ensure a smooth user experience.
Solution
To address the challenges mentioned earlier and meet our needs, we adopted AutoMQ, a cloud native Kafka solution with great elasticity and performance.
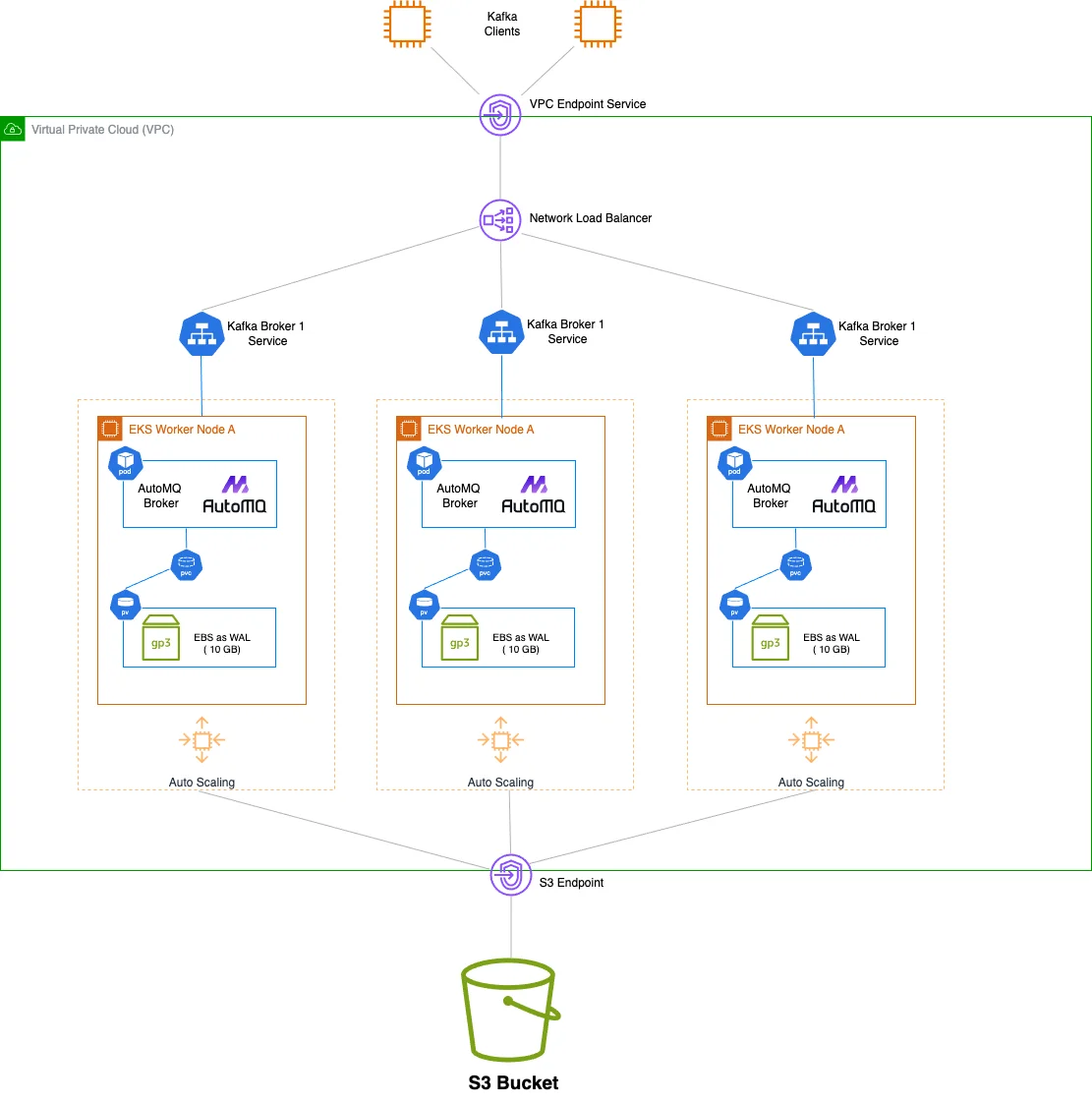
Figure 3 shows the new architecture of the Streaming Platform after adopting AutoMQ. AutoMQ is 100% compatible with Apache Kafka, so we can easily switch from the past architecture to the new architecture using AutoMQ. AutoMQ adopts a shared storage architecture based on WAL and S3. In this deployment, AutoMQ uses EBS WAL—by introducing a fixed-size EBS volume as WAL, it can provide very high performance and low latency write capabilities without incurring additional cost burdens. (AutoMQ also supports S3 WAL, the default for AutoMQ Open Source, which writes WAL data directly to object storage.) All written data will be stored in an S3 Bucket, enjoying the advantages brought by S3.
Why AutoMQ?
Clusters can be scaled quickly and efficiently
Our past architecture actually is based on replication as such the compute elasticity is not that great. When we are moving between nodes, data is actually moved between brokers and that actually causes challenges that we face. With AutoMQ, the data is read from the shared storage which is across the brokers. When the cluster needs to be scaled, AutoMQ does not need to move partition data between brokers. The move of partitions during scaling will be completed in a few seconds. In this way, the clusters can be scaled easily.
AutoMQ uses on-demand S3 shared storage
AutoMQ uses object storage like S3 to store data. S3 is an on-demand storage service. When the user needs more retention, we don't need to scale the brokers and local disks manually like we used to.
Fast Partition Reassignment
Reassigning large partitions is fast with AutoMQ, as only a small amount of metadata needs to be synchronized to complete the switch. This feature is mainly due to AutoMQ's cloud-native architecture design. Unlike Apache Kafka, which ensures data persistence through the ISR multi-replica mechanism, AutoMQ offloads data persistence to cloud storage. Since the cloud storage service itself internally already has multi-replica and error correction code technology, it can provide high data persistence and availability, so there is no need to introduce multi-replica within AutoMQ Broker. AutoMQ follows the cloud-first design philosophy, transitioning from the past hardware-dependent design to cloud service-dependent design, greatly leveraging the potential and advantages of the cloud.
Low latency
A low-latency Streaming Platform is crucial for Grab's customer experience. Object storage services like S3 are not designed for low-latency writes. AutoMQ cleverly relies on a fixed-size (10GB) EBS block storage to provide single-digit millisecond write latency. By using Direct I/O to bypass the write overhead of the file system, and due to its cloud native architecture, it avoids the network overhead of internal partition replicas, providing extremely high write performance.
100% Kafka Compatibillity
AutoMQ reuses the computation layer code of Apache Kafka and passes all test cases of Apache Kafka, achieving 100% Kafka compatibility. This allows us to switch to AutoMQ very easily without adjusting the existing Kafka infrastructure or rewriting the Client code. This can greatly reduce the cost and risk of switching architectures.
Evaluation and Deploy in Production
To ensure that AutoMQ meets our expectations, we evaluated it from three dimensions: performance, reliability, and cost-effectiveness. First of all, we're focusing on performance. We've conducted benchmarks with different configurations, such as different replication factors and different acknowledgement configurations for producers, to see how well they suit our needs. We're trying to understand if there are any learnings we need to adapt to, or any nuances and niches we need to be prepared for or be aware of. Similarly, with regard to reliability, we also conduct test cases and benchmarks for use cases such as failover, or when there's a failure in the infrastructure, to test for graceful failover scenarios for planned maintenance or something more disruptive when there's unexpected failures. Lastly, we consider cost-effectiveness. AutoMQ behaves well and has passed all our benchmarks and test cases. And then we were confident to move on to implement it in the real use cases we have at Grab.
In the past, we used the community's Kafka Operator Strimz to help us operate and manage Kafka clusters on Kubernetes. We expanded the capabilities of this Operator to support integration with AutoMQ. This work mainly includes supporting the creation, mounting, and authorization of WAL Volumes, and integrating AutoMQ with Strimz. Moreover, we also familiarized ourselves and learned some new knowledge about AutoMQ, such as S3, WAL related metrics, and so on, so that we can better use and manage these AutoMQ clusters in production environments.
Outcomes
After adopting AutoMQ, our streaming platform has seen significant improvements in the following aspects:
-
Boost in Throughput : With data replication moved from inter-broker to cloud-based storage replication, we observed a 3x increase in throughput per CPU core. The cluster is now one of the largest in terms of throughput within our fleet.
-
Cost Efficiency : Initial figures show a cost efficiency improvement of 3x .
-
Efficient Partition Reassignment: Partition reassignment for the entire cluster now takes less than a minute , compared to up to 6 hours in our past setup.
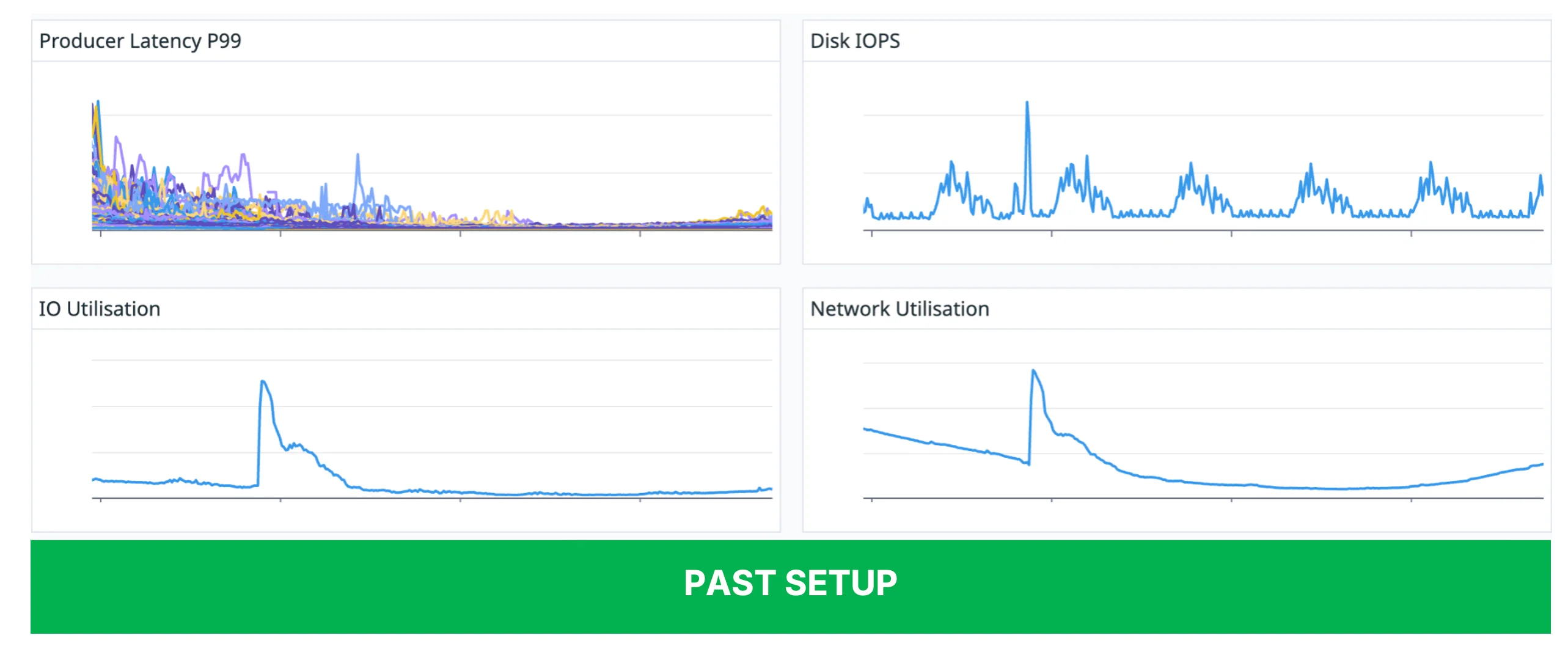
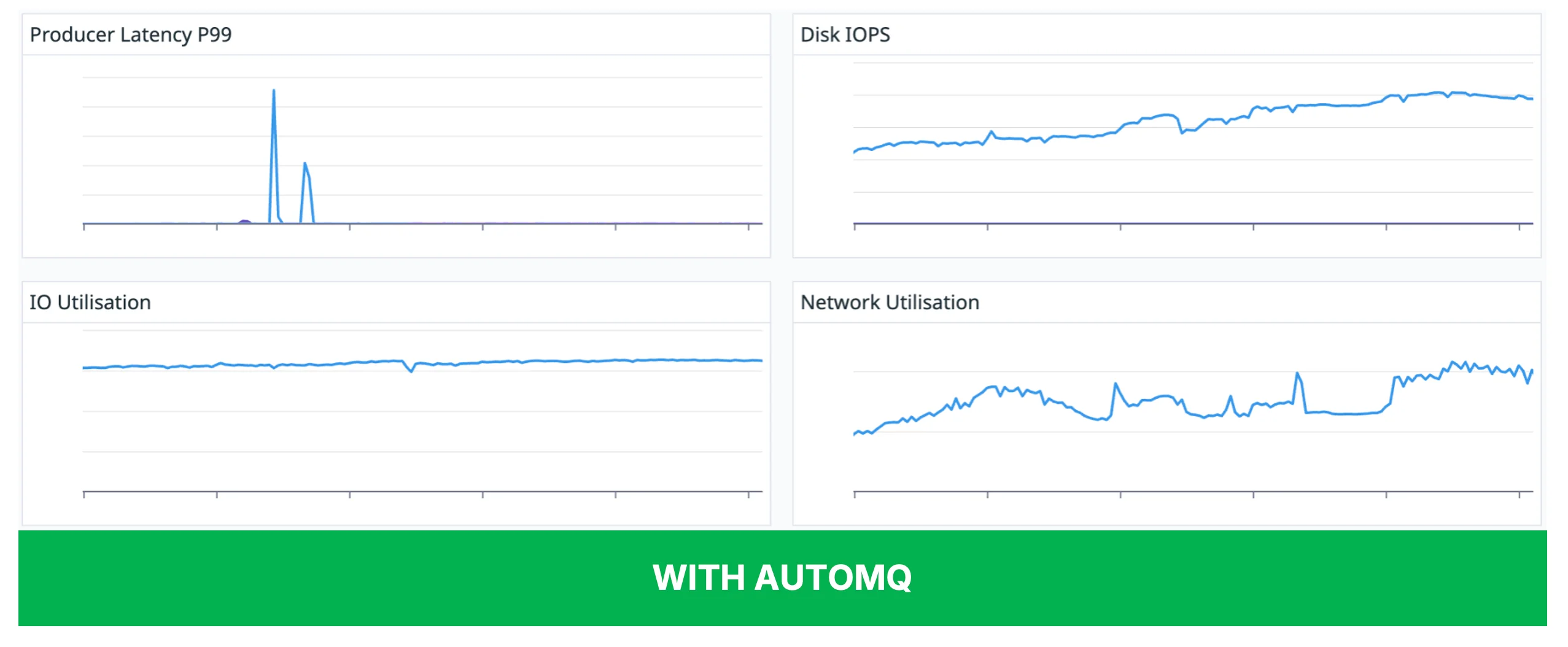
Figures 4 and 5 show the differences in key performance indicator changes when the old and new architectures perform broker elasticity. The new architecture with AutoMQ not only completes the expansion very quickly, but also brings less performance jitter, making the cluster more stable.
After we have moved towards the shared storage architecture with AutoMQ, as compared to the previous architecture, it enables very fast partition reassignment. Each partition reassignment takes only seconds. Thanks to this, we also enhance the stability of our brokers, as there is no data to be replicated among brokers when we move the partition. This means there is no surge in I/O as well as network utilization, no data to be moved among brokers, so it is more stable. There are no more spikes in our operations.
Because the reassignment is very fast, it also reduces the impact on the client, as we no longer observe any prolonged latency increase for both our producers as well as consumers. Thanks to the shared storage architecture, we can now independently scale our storage. Previously, when there was a need for us to scale the storage, we had to either add additional brokers to the cluster or scale up the storage on a per-broker basis. This not only increased the cost for us, as when we provision new brokers there would be unneeded or underutilized compute capacity that we didn't really need, but also when we scaled the cluster, we needed to trigger a rebalance, which increased latency for both our producer and consumer clients and affected our stability.
Future
We have managed to benefit from that in that aspect. We would like to go through some of the future enhancements we are looking to further enhance our efficiency.
First of all, we would like to further enhance our utilization efficiency in terms of compute capacity. There is another feature baked into AutoMQ that we have yet to utilize, which is called Self-Balancing. This is something similar to an open-source product called Cruise Control that people often use with Apache Kafka. Self-Balancing will trigger rebalancing as needed periodically, so that our compute capacity can react better during both peak and off-peak periods.
Secondly, we will continue to optimize cost-effectiveness. Now that we are able to tolerate more frequent disruption and it's not as costly or is quite negligible for us to perform partition reassignment, we can look into auto scaling and spot instances so that we can realize some cost savings. During peak periods, our cluster can scale up and subsequently during off-peak or low periods, we can scale down, which will further enhance our utilization efficiency and subsequently cost efficiency. We are also looking into reducing cross AZ traffic between clients and brokers through another type of streaming storage engine in AutoMQ called S3 WAL. In addition, AutoMQ also provides a feature called Table Topic, which allows the streaming data of the Topic to be stored directly on S3 in the iceberg table format, and can take advantage of the S3 Table feature recently released by AWS. We are also planning to look into that, so that we can reduce the redundancy of some of our data pipelines that will no longer be needed as we introduce table topics into our use.
Lastly, since AutoMQ has been working so well for us at Grab, we are looking to further the adoption and migrate more use cases to AutoMQ.


