.png)
Introduction
Apache Kafka has cemented its position as the de facto standard for real-time event streaming. Its power lies in its ability to handle high-throughput, low-latency data streams reliably. However, as data volumes continue to explode, the traditional architecture of Kafka presents significant operational challenges, particularly concerning storage costs and scaling elasticity. For engineers and architects managing these critical systems, the future of Kafka operations is being reshaped by two transformative trends: Tiered Storage and the more revolutionary Diskless Architecture .
This blog post delves into these architectural evolutions, exploring how they address the limitations of traditional Kafka and pave the way for a more scalable, cost-effective, and cloud-native future.
The Challenge: Kafka's Tightly-Coupled Foundation
In a traditional Apache Kafka deployment, the broker is a stateful component. Each broker is responsible for both processing (handling producer and consumer requests) and storing data on its local disks. This tight coupling of compute and storage has been fundamental to Kafka's performance, as it leverages sequential disk I/O for fast writes and reads.
However, this design creates several operational hurdles as clusters grow:
Prohibitive Storage Costs: To maintain performance, brokers require expensive, high-performance disks (like SSDs). As topics retain more data—for analytics, compliance, or event sourcing use cases—the storage cost can become a dominant factor in the total cost of ownership.
Inflexible Scaling: When you need more storage capacity, you must add more brokers. This means you are also scaling compute, even if your processing load hasn't changed. Conversely, if you need more processing power for a high-traffic topic, you are forced to provision additional storage that may sit underutilized. This lack of independent scaling leads to resource inefficiency.
High Operational Overhead: Data rebalancing is a major pain point. When a broker is added, the cluster must move massive amounts of partition data across the network to the new broker to distribute the load. This process is resource-intensive, risky, and can significantly impact cluster performance. Similarly, recovering from a broker failure requires replicating its data, a slow and often manual process.
These challenges have driven the community and ecosystem to rethink Kafka's core architecture, leading to innovations that decouple its fundamental components.
Evolution 1: Tiered Storage - Decoupling Old and New Data
Tiered Storage is the first major step in this evolutionary journey. It directly tackles the problem of data retention costs by acknowledging that not all data needs to be stored on expensive, high-performance disks forever. This concept was officially introduced to the Apache Kafka project through Kafka Improvement Proposal 405 (KIP-405) [1].
Concept
Tiered Storage introduces a two-layer data management system within the Kafka cluster:
Hot Tier: This is the traditional storage layer. Data is first written to the local, high-performance disks of the Kafka brokers. This tier is optimized for low-latency writes and reads of the most recent data.
Cold Tier: This is a secondary, more cost-effective storage layer, typically a cloud-native object store like Amazon S3 or Google Cloud Storage. After a configurable period or size threshold, older data segments are moved from the hot tier to this remote storage.
This approach creates a logical, unified log that spans both local and remote storage, allowing for virtually infinite, cost-effective data retention.
How It Works
The implementation of Tiered Storage relies on a new component within the broker called the Remote Log Manager. Its job is to handle the lifecycle of log segments in remote storage.
The data flow is as follows:
Producers write data to Kafka brokers as usual. The data lands in the active log segment on the broker's local disk (the hot tier).
Once a log segment is rolled (based on time or size), it becomes eligible for offloading.
The broker asynchronously copies the inactive segment to the designated object store (the cold tier).
After the data is successfully copied and validated, the local copy of the segment can be deleted, freeing up valuable disk space on the broker.
For consumers, this process is largely transparent. When a consumer requests data, the broker first checks if the required segment is in its local cache or on its local disk. If the data is found, it's served immediately. If the data is older and has been moved to the cold tier, the broker fetches it from the object store and then serves it to the consumer. This might introduce a slight increase in latency for fetching historical data, but it's a small trade-off for the immense cost savings.
![Proposed High Level Design [1]](https://static-file-demo.automq.com/6809c9c3aaa66b13a5498262/69099d433e0b3299ad5a3f2e_67480fef30f9df5f84f31d36%252F685e6536032bcb896d0703b6_VRa5.png)
Benefits of Tiered Storage
Massive Cost Reduction: Object storage is significantly cheaper than the high-performance disks used in brokers. By moving the bulk of your data to a colder tier, you can drastically reduce storage costs, especially for long-term retention use cases.
"Infinite" Retention: Organizations are no longer forced to delete valuable historical data due to cost constraints. This unlocks new possibilities for analytics, machine learning model training, and replaying historical events.
Improved Elasticity: With the bulk of the data offloaded, brokers become "lighter." This makes scaling the cluster much easier and faster. Adding a new broker doesn't require it to immediately store terabytes of historical topic data.
Evolution 2: Diskless Architecture - The Next Frontier
While Tiered Storage is a significant improvement, it still leaves brokers as stateful components. The ultimate vision for a truly cloud-native Kafka is a Diskless Architecture , where compute and storage are fully disaggregated. This idea is being explored within the community, notably through proposals like KIP-1150, which imagines a new "object storage topic" type.
Concept
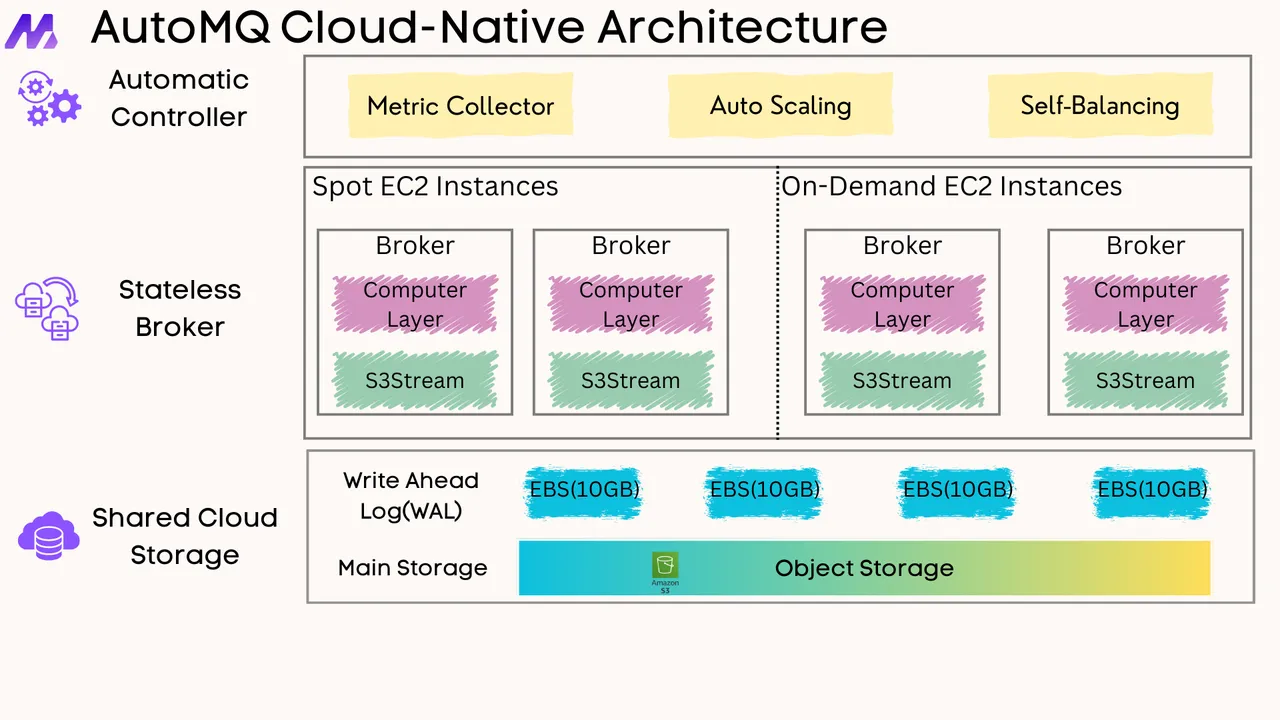
In a diskless model, Kafka brokers evolve into truly stateless compute nodes. Their primary responsibility is to handle the Kafka protocol, manage client connections, and coordinate access to data. The single source of truth for all log data—both recent and historical—becomes a durable, scalable object store.
Local disks on the broker are not eliminated entirely but are relegated to a secondary role, serving as a cache for hot data to maintain low-latency performance for real-time consumers. This completely flips the traditional model on its head: the log lives in object storage, and the broker simply provides a performant access layer to it.
How It Works (Conceptual)
The mechanics of a fully diskless architecture represent a fundamental paradigm shift:
Write Path: When a producer sends a message, the lead broker would write it directly to the object store. To mitigate the higher latency of object storage writes, data could be buffered in memory and written in larger, optimized chunks. A write-ahead log (WAL) might also be used to ensure durability before the data is committed to the object store.
Read Path: When a consumer requests data, the broker checks its local cache first. If the data is present, it's served immediately with low latency. If it's a cache miss, the broker fetches the required data from the object store, serves it to the consumer, and potentially populates its cache for future requests.
Stateless Brokers: Since the data's source of truth is in shared object storage, the brokers themselves hold no unique data. They are interchangeable compute units.
Benefits of a Diskless Architecture
The operational benefits of this model are profound:
Extreme Elasticity and Scalability: Compute and storage scale completely independently. Need more throughput? Spin up more stateless brokers in minutes. Need more storage? Object storage scales limitlessly without any intervention required on the Kafka cluster itself.
Instantaneous Rebalancing: This is the holy grail of Kafka operations. Because brokers are stateless, there is no partition data to move when a broker is added or removed. Rebalancing becomes a near-instantaneous process of reassigning partition leadership, eliminating one of the most significant operational burdens of traditional Kafka.
Enhanced Durability and Availability: This architecture leverages the extremely high durability guarantees (e.g., 99.999999999% or "eleven nines") of modern object storage systems, far exceeding what is practically achievable with broker-based replication.
Simplified Operations: Broker failures become non-events. A failed broker can simply be replaced by a new one without a lengthy and complex data recovery process. This dramatically simplifies cluster management and reduces operational toil.
Challenges and The Road Ahead
Achieving a diskless architecture without sacrificing the performance Kafka is known for is a significant engineering challenge. The primary hurdle is latency—object stores inherently have higher latency than local disks for both reads and writes. Overcoming this requires sophisticated caching strategies, intelligent pre-fetching algorithms, and an optimized write path.
While this architecture is still a forward-looking proposal for the official Apache Kafka project, its principles are so compelling that some emerging, Kafka-compatible streaming platforms have already been built from the ground up on this stateless, object-storage-native foundation.
A Comparative Look
The table below summarizes the key differences between the three architectures.
| Feature | Traditional Kafka | Kafka with Tiered Storage | Diskless Kafka (Conceptual) |
|---|---|---|---|
| Architecture | Tightly Coupled Compute & Storage | Partially Decoupled Storage | Fully Decoupled Compute & Storage |
| Primary Storage | Local Broker Disks | Local Disks (Hot) & Object Store (Cold) | Object Store |
| Broker State | Stateful | Stateful | Stateless (with Local Cache) |
| Scaling | Coupled (Scale brokers) | Semi-Independent | Fully Independent |
| Data Rebalancing | Slow, Complex, I/O Intensive | Faster (less local data) | Near-Instantaneous |
| Cost Model | High (Expensive disks) | Optimized (Cheap object storage) | Highly Optimized (Pay-for-use) |
| Ideal Use Case | Real-time, short retention | Real-time + long-term analytics | Cloud-native, highly elastic workloads |
Conclusion: The Future is Decoupled
The journey from a tightly-coupled architecture to Tiered Storage and ultimately towards a Diskless model marks a clear and necessary evolution for Apache Kafka. This path aligns perfectly with the broader trends in modern data systems, where the disaggregation of compute and storage is becoming the standard for building scalable, cost-effective, and operationally simple cloud-native services.
For organizations today, Tiered Storage is the practical and readily available solution to the pressing problem of infinite and affordable data retention. It unlocks immense value from historical data without breaking the bank.
Looking forward, the Diskless Architecture represents the long-term vision. It promises a future where Kafka clusters are as elastic and easy to manage as any other modern cloud application, freeing engineers from the heavy operational burden of managing stateful infrastructure and allowing them to focus on building innovative real-time applications. The future of Kafka is undeniably decoupled, and it's a future that is brighter and more scalable than ever before.
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
JD.comx AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging