At first glance, Apache Kafka and Apache Iceberg seem to come from different worlds. Kafka is built for velocity—a high-speed message bus optimized for low-latency, small-payload data in motion. Iceberg is built for analytics—a table format optimized for large-scale, immutable, and structured data at rest. Their core design principles are almost antithetical.
Despite this, the industry is converging on a powerful idea: unifying these two. The goal is to create a seamless data continuum, a single architecture where data is available from the moment of creation (real-time) to its entire history (batch analytics). No more data silos, no more "Where do I query?"
For this reason, nearly every major data vendor is racing to build the definitive bridge. In this modern architecture, Kafka serves as the real-time "front door," while Iceberg acts as the long-term "system of record." However, connecting this bridge is fraught with technical hurdles. Let's examine the four most significant challenges:
-
Challenge 1: The "File Size" Mismatch and Latency: Kafka excels at handling millions of tiny messages per second (e.g., ~16KB). Iceberg, to ensure query performance, demands large, columnar files (e.g., ~512MB). The most common way to bridge this is to buffer the small messages, waiting for enough data to accumulate before writing a large file. This buffering, by definition, introduces latency. Your "real-time" data in Iceberg might be 15 minutes old or more, defeating the purpose.
-
Challenge 2: The "Housekeeping" Burden: An Iceberg table is not a "set it and forget it" destination. To maintain query performance, it requires constant, background maintenance. As small files land in the table, they must be periodically merged into larger ones via Compaction. Simultaneously, Iceberg's time-travel feature creates metadata Snapshots with every write, which must be Expired and cleaned up to prevent performance degradation. This is a significant operational load.
-
Challenge 3: The Risk of Data Duplication: The moment you create a separate "copy" of data from your stream for analytics, you've created two potential points of failure. This traditional ETL approach opens the door to data corruption, schema mismatches, and data loss. It fundamentally breaks the "single source of truth" promise, forcing teams to constantly reconcile the "real-time" view with the "analytical" view.
-
Challenge 4: The "Partition" Terminology Trap: This is a subtle but critical problem. In Kafka, a "partition" is a unit of parallelism—a separate log that allows for concurrent consumers. In Iceberg, a "partition" is a physical data layout strategy, grouping data by date or category to speed up queries. Confusing the two, or failing to translate from Kafka's partitioning to a meaningful Iceberg partition strategy, can lead to disastrously slow queries that scan the entire table.
The Solutions
There are two general approaches to the Kafka -> Iceberg flow today: copy-based and zero-copy . Let's first look at the copy-based systems.
Copy Based Solutions
These solutions treat Kafka as the source for an analytically focused Iceberg copy.
1. Confluent (TableFlow)

TableFlow is a managed Kafka -> Iceberg flow from Confluent Cloud. It automates many tasks, including schema mapping, file compaction, and metadata publishing .
-
Pros: Provides a "turn-key," fully managed experience, especially for existing Confluent Cloud customers. It automates many complex tasks like schema mapping and file compaction.
-
Cons: This convenience comes at a high cost, as TableFlow is significantly more expensive than its competitors. It also locks you into the Confluent ecosystem.
2. Kafka Connect (Iceberg Sink)
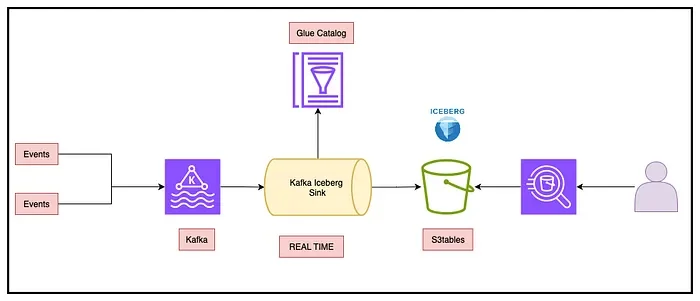
The Iceberg Kafka Connect Sink connector is an open-source, mature, and feature-rich option for ingesting records from Kafka to Iceberg tables .
-
Pros: It is open-source, mature, and feature-rich. It allows users to leverage the entire, robust Kafka Connect ecosystem
-
Cons: It has a steep learning curve for teams not already running a Kafka Connect estate. More importantly, it only handles data transport; crucial table maintenance must be built and managed separately.
3. WarpStream (TableFlow)
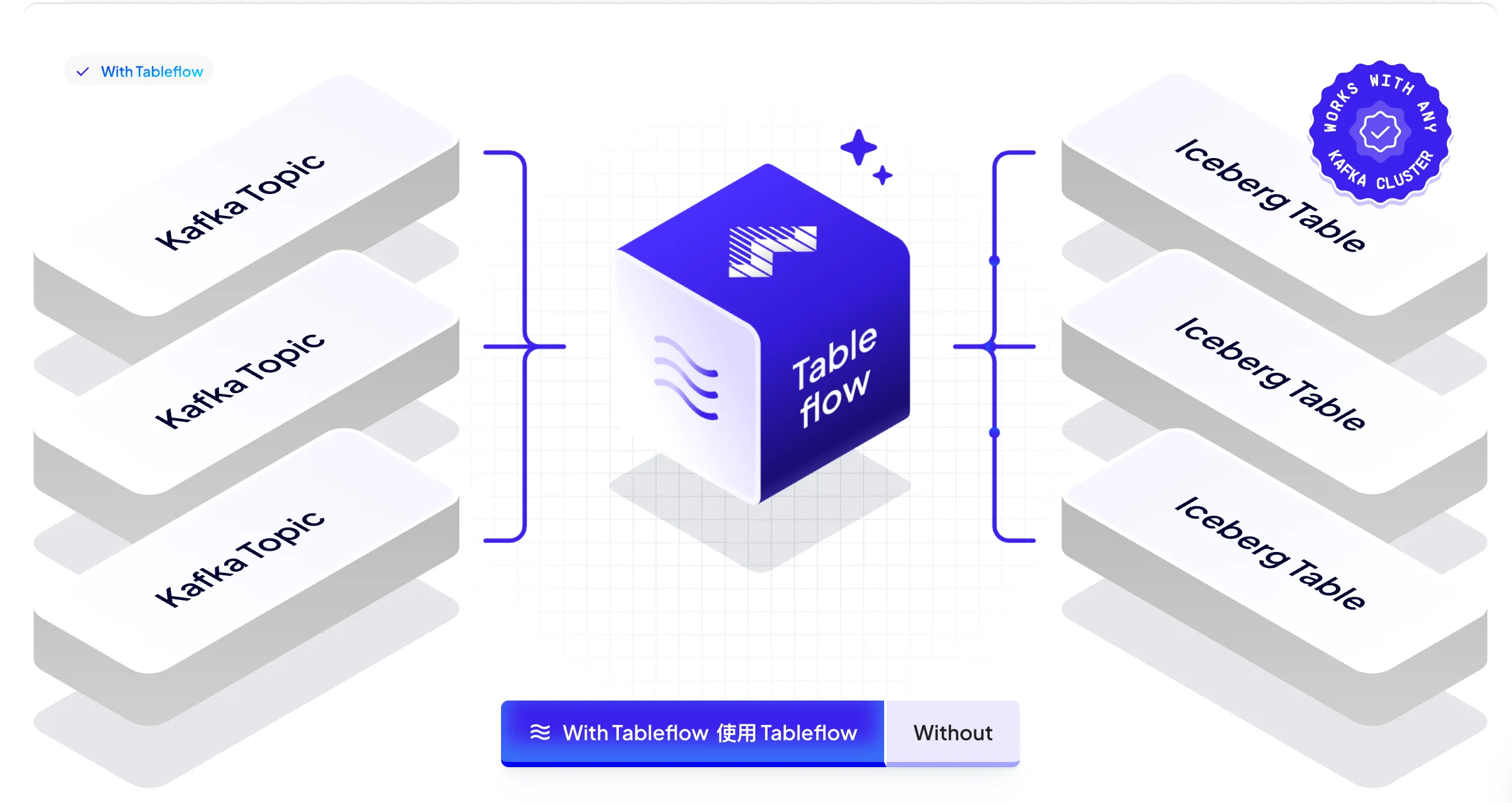
WarpStream's TableFlow is a fully packaged, BYOC (Bring Your Own Cloud) solution for materializing Iceberg tables. It can source from any Kafka-compatible cluster and supports external catalogs .
-
Pros: Emphasizes simplicity, openness, and a low-cost, BYOC (Bring Your Own Cloud) model. It is flexible, able to source from any Kafka-compatible cluster.
-
Cons: As a newer entry, it is less battle-tested than established competitors. It forces a trade-off between its open model and the more mature, enterprise-grade governance found in locked-in solutions.
4. Redpanda (Iceberg Topics)
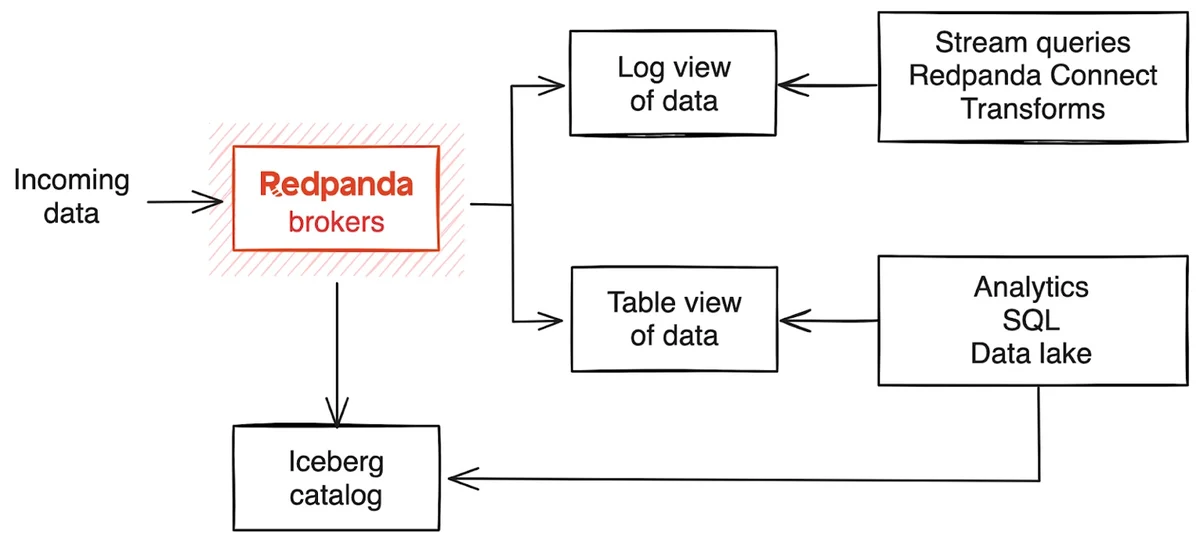
Redpanda’s Iceberg Topics feature persists topic data directly into Iceberg table format from within the broker, without a separate connector. It also handles automated snapshot expiration and custom partitioning .
-
Pros: Offers very fast time-to-value by building the feature directly into the broker. It also automates some maintenance tasks like snapshot expiration.
-
Cons: It has a major limitation in its inability to backfill data from existing topics. Furthermore, this is an enterprise feature that requires a paid commercial license.
Zero Copy Solutions
This class of solutions integrates Kafka and Iceberg more closely, typically by sharing storage to eliminate copies. This promises reduced cost and improved consistency.
5. Aiven (Iceberg Topics)
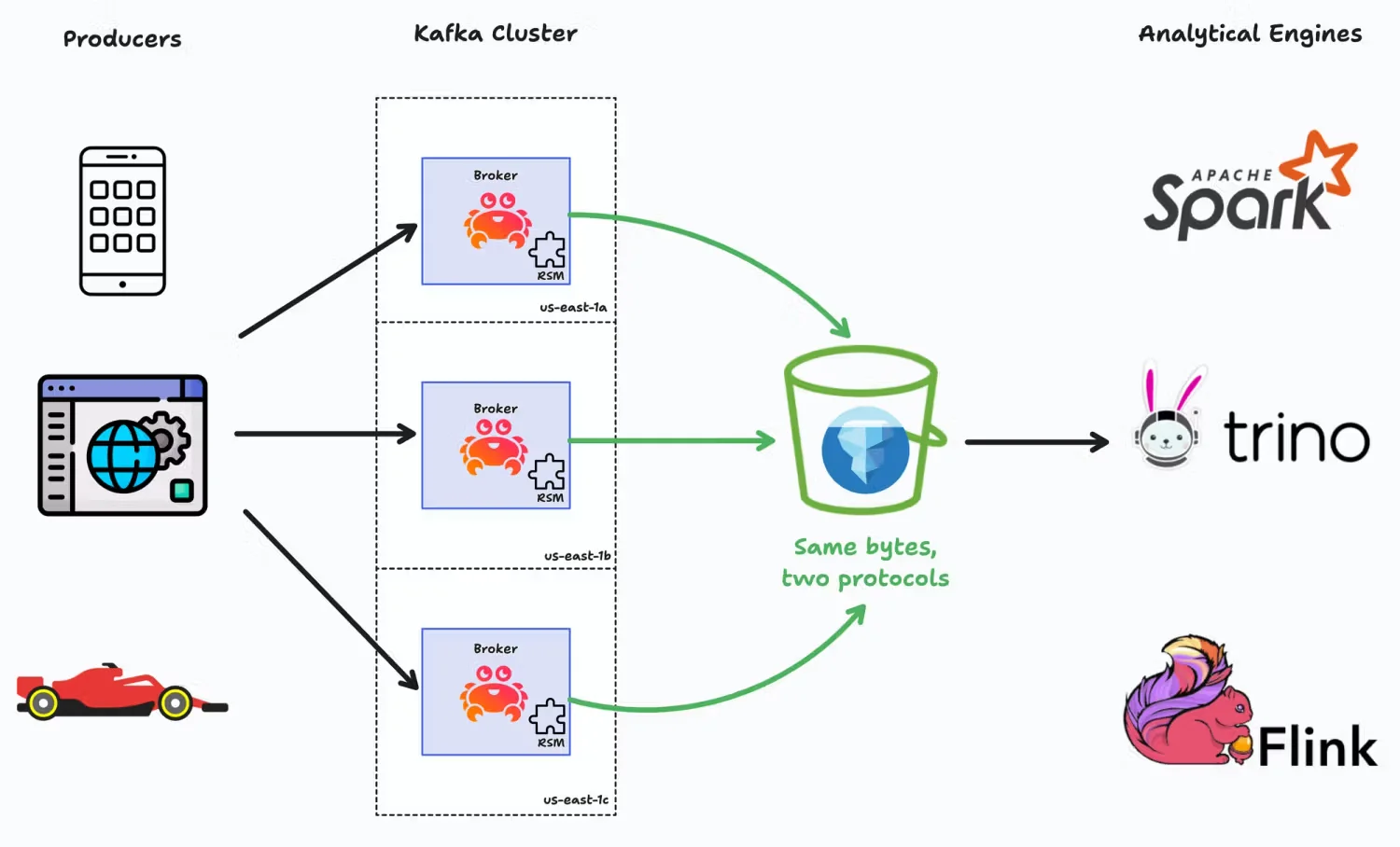
Aiven’s solution adds native Iceberg support to Apache Kafka using its custom tiered storage mechanism. It splits data into a "hotset" (Kafka) and a "coldset" (Iceberg) .
-
Pros: Natively integrates Iceberg support into Apache Kafka using its existing tiered storage mechanism.
-
Cons: The reliance on tiered storage (designed for cold data) introduces significant data lag, often >24 hours. Like Kafka Connect, it does not handle compaction or snapshot expiration, which must be managed externally.
6. Streambased
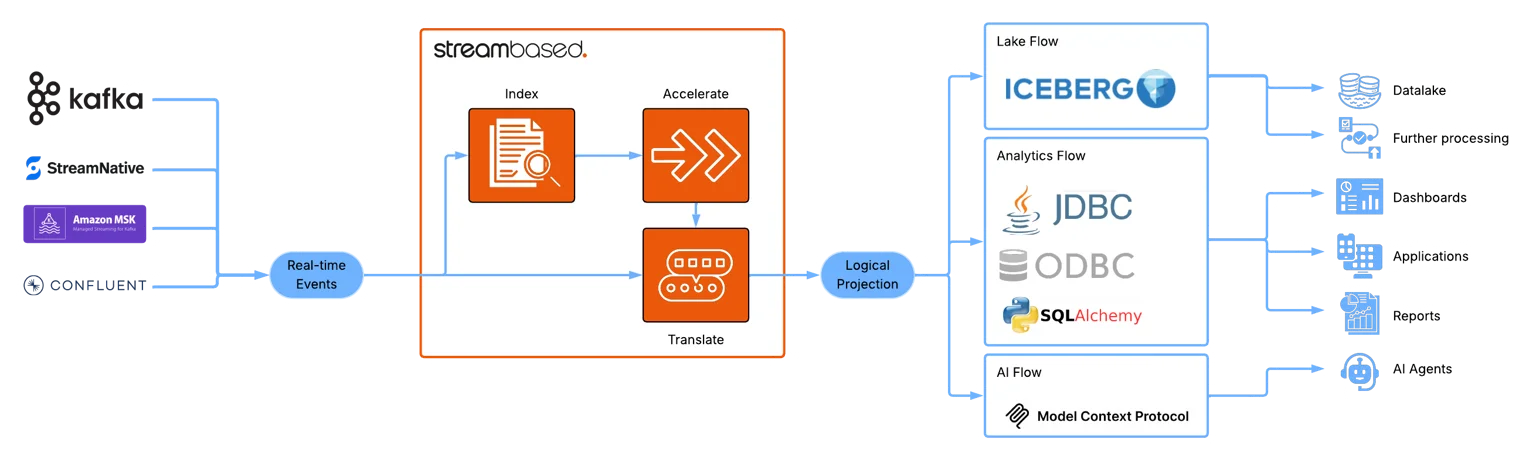
Streambased takes a different approach. It maintains a "hotset" in Kafka and a "coldset" in Iceberg. At query time, it fetches the hotset data, transforms it to Iceberg on the fly, and combines it with the coldset .
-
Pros: Guarantees zero lag by definition, as data is transformed "on the fly" at query time, making it ideal for real-time analytics.
-
Cons: This architecture couples the conversion load to the Iceberg query load, which can create performance bottlenecks during heavy analytics. It also sits as an extra proxy layer, adding another complex component to manage.
7. Bufstream
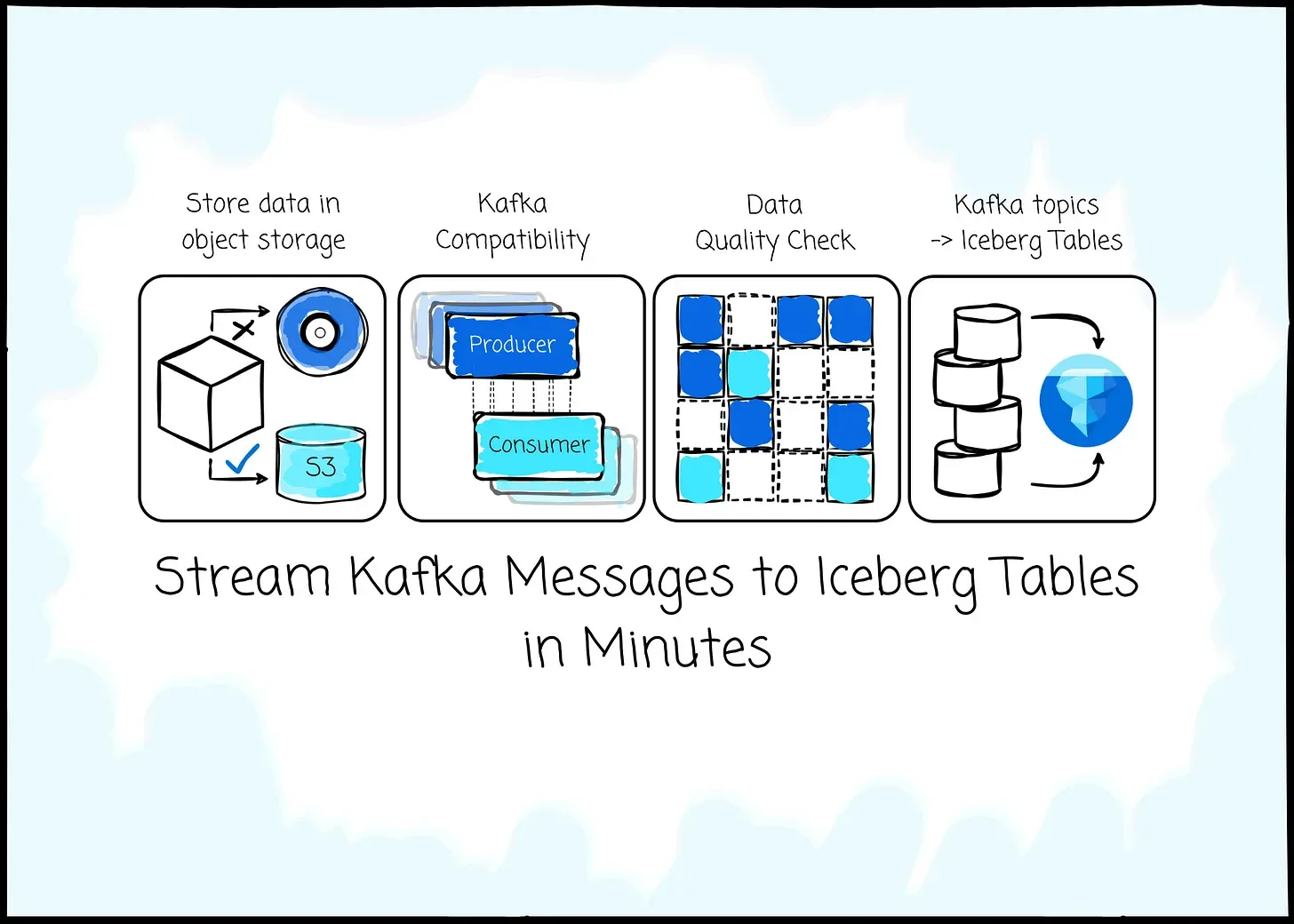
Bufstream is a Kafka-compatible platform that writes Parquet files to object storage by the broker on produce, sharing them with both Iceberg and Kafka readers. This avoids duplicating data .
-
Pros: Achieves a true zero-copy layout by having the broker write Parquet files directly, eliminating data duplication.
-
Cons: This architecture comes at a high performance cost: producer latency (P99) is typically 3-5x higher than traditional Kafka. The resulting Iceberg data is also read-only and cannot be rewritten.
8. StreamNative (Ursa)
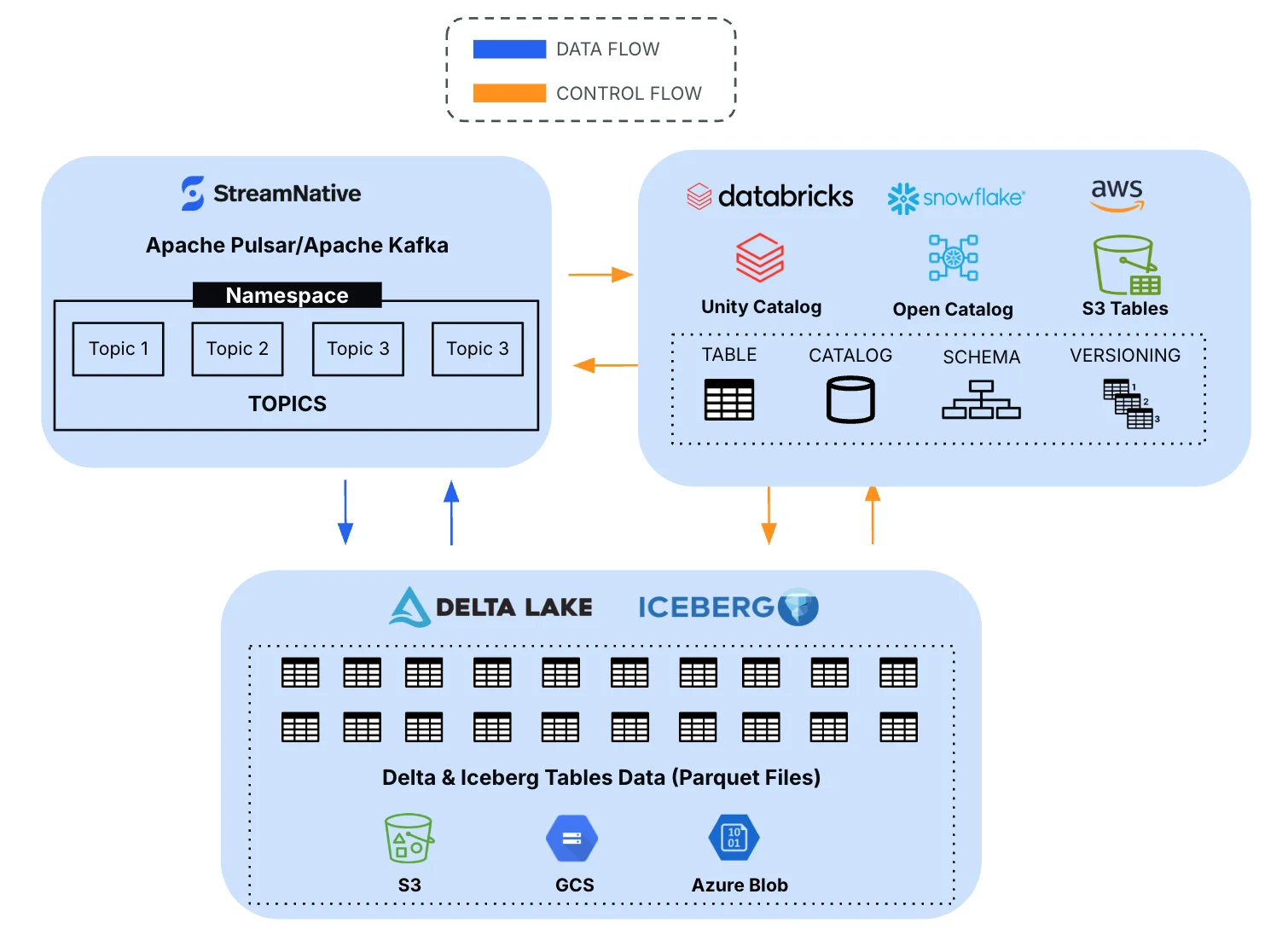
Ursa is a "lakehouse-native" engine that's Kafka-API compatible , using a stateless Pulsar-like architecture . It writes data to open formats like Iceberg via a two-stage storage: a WAL (for ingestion) and Parquet files (for analytics).
-
Pros: Supports zero-copy and has an efficient index spanning both WAL and Parquet.
-
Cons: Lacks Kafka's topic compaction and transactions . The two-stage process also introduces data latency and doesn't automatically handle data compaction or snapshot expiration.
A 9th Way: The Cloud-Native Architecture (AutoMQ)
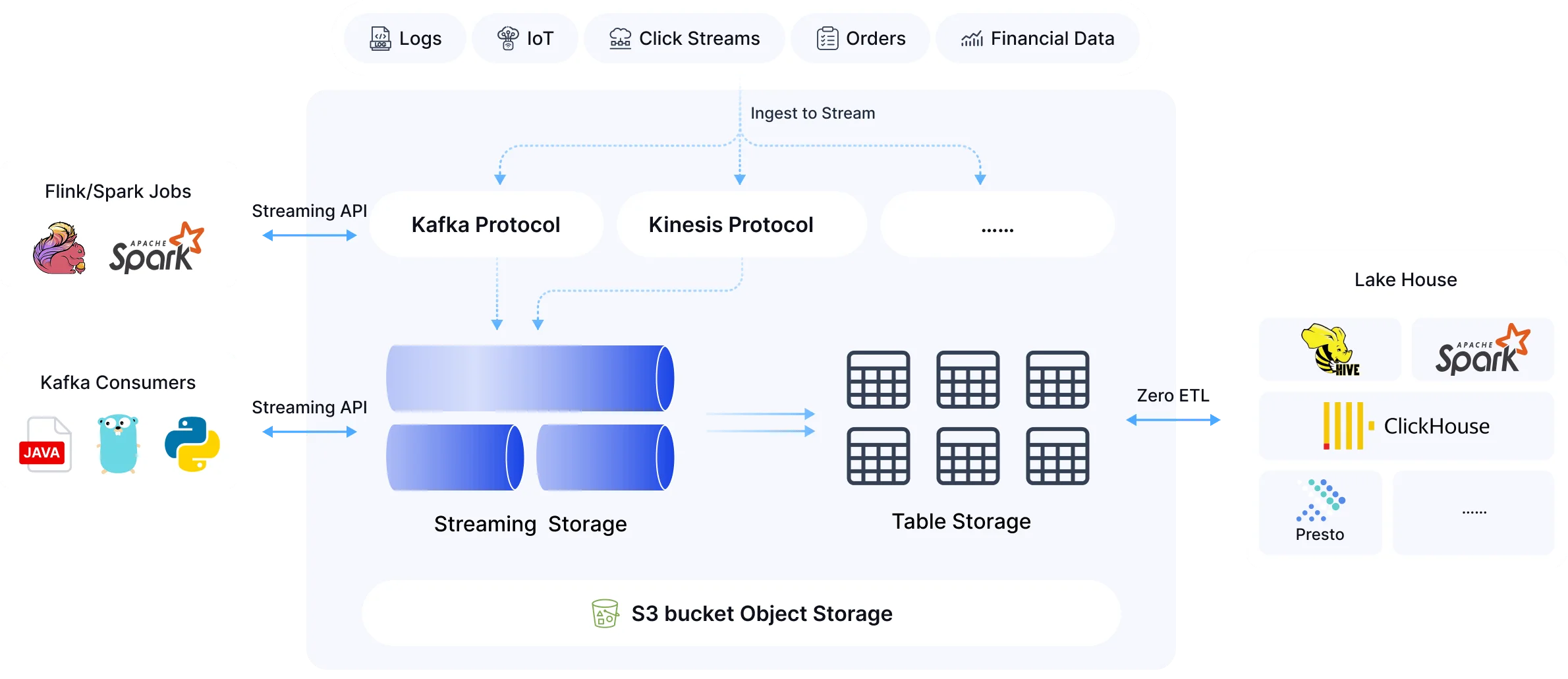
AutoMQ pioneers a true cloud-native Kafka architecture, completely reshaping data flow. Instead of retrofitting the legacy architecture, it achieves seamless, high-performance integration with Iceberg by 100% decoupling compute and storage—with stateless brokers and data stored directly on S3.
The brilliance of this architecture lies in its design, which bypasses traditional Kafka limitations. For instance, technical experts at Confluent have pointed out the flaws in the traditional "zero-copy" mechanism. AutoMQ's stateless model does not rely on this conventional zero-copy approach, thereby inherently avoiding all its drawbacks and achieving simpler, more efficient cloud-native data processing.
This design directly solves all 4 issues:
-
Solves Cost & Maintenance: By using S3 for primary storage, AutoMQ slashes TCO by up to 90% compared to traditional Kafka. Its stateless brokers enable seconds-level elasticity and zero-effort operations. Critical maintenance like partition migration is instant because no data is copied. It also eliminates cross-AZ data transfer costs.
-
Solves Data Freshness: Despite using object storage, AutoMQ's optimized I/O path delivers millisecond-level P99 latency (under 10ms). It provides built-in, "Zero-ETL" streaming to Iceberg, ensuring data is available in the data lake with near-zero lag, solving the freshness problem without micro-batching.
-
Solves Single Source of Truth: The flow to Iceberg is an integrated feature, not a copy-based connector, ensuring data consistency.
-
Solves Adoption Risk: AutoMQ is 100% Kafka-compatible , enabling zero-downtime migration from existing clusters.
This cloud-native approach fundamentally changes the trade-offs. You no longer have to choose between low latency, low cost, and low operational overhead.
Solution Summary
All solutions have building blocks, but the choice is driven by which trade-off you are willing to accept.
-
For open-source, DIY control → Kafka Connect Sink is flexible but ops-heavy. AutoMQ also provides a 100% open-source, Apache 2.0 solution.
-
For vendor simplicity → Redpanda and Confluent offer simple integration if you can accept the vendor lock-in and high cost.
-
For maximum data freshness → AutoMQ's built-in, low-latency stream and query-time federation guarantee near-zero lag.
-
For maximum compatibility → AutoMQ's 100% Kafka wire-protocol compatibility ensures it works with any existing Kafka deployment.
-
For cost-efficient scalability → AutoMQ's stateless, S3-based architecture is purpose-built for this, offering unrivaled cost efficiency and elasticity at scale.
Conclusion
The convergence of Kafka and Iceberg is no longer a distant vision; it's the default expectation. The industry's approaches show a spectrum of trade-offs between cost, complexity, and freshness.
While copy-based systems introduce lag and zero-copy systems introduce new complexities, a new generation of cloud-native architecture—represented by AutoMQ—suggests that it's possible to eliminate these trade-offs entirely. The unification of streaming and analytics is here, and it runs best on an architecture built for the cloud.


