Introduction: The Data Engine Behind the World's Largest Crypto Exchange
The cryptocurrency industry operates in a 24/7, high-stakes environment defined by massive data volumes and extreme volatility. For any company in this space, the ability to process, analyze, and act on data in real time is not just a competitive advantage—it is a core business necessity .
At the heart of this data-driven world stands Binance, the world's largest crypto exchange. Its operations, which span spot trading, futures, options, and a vast ecosystem of financial services, are entirely dependent on a stable, highly scalable, and low-latency data processing infrastructure . The central nervous system for this complex operation is Apache Kafka, which forms the backbone of their real-time streaming data pipelines .
Kafka acts as the foundational data backbone for the exchange, handling the immense flow of information required to keep the global marketplace running. By examining Binance's specific, large-scale use cases, we can gain a clear understanding of Kafka's profound capabilities. More importantly, we can also see the severe architectural and operational challenges that emerge when this traditional platform is pushed to its absolute limits at a "hyper-scale" level.
The Critical Role of Kafka at Binance
At Binance, Kafka is not a supplementary tool; it is a mission-critical component that powers the core product. Its application is woven into every facet of user experience and internal operations.
-
Market Data Dissemination: This is perhaps the most visible use case. Every trade, every update to the order book, and every price tick for thousands of trading pairs must be captured and broadcast to millions of users simultaneously . Kafka serves as the high-throughput pipeline that ingests this data from the matching engine and streams it to all downstream consumers .
-
Real-time Risk and Fraud Detection: In the financial world, security is paramount. Binance has detailed its use of real-time machine learning models to combat fraud, such as account takeovers . Kafka is the essential component that feeds their "streaming pipeline" . This enables real-time feature engineering and processing to prevent what they call "model staleness," ensuring that risk engines can immediately detect and block suspicious activities to protect users .
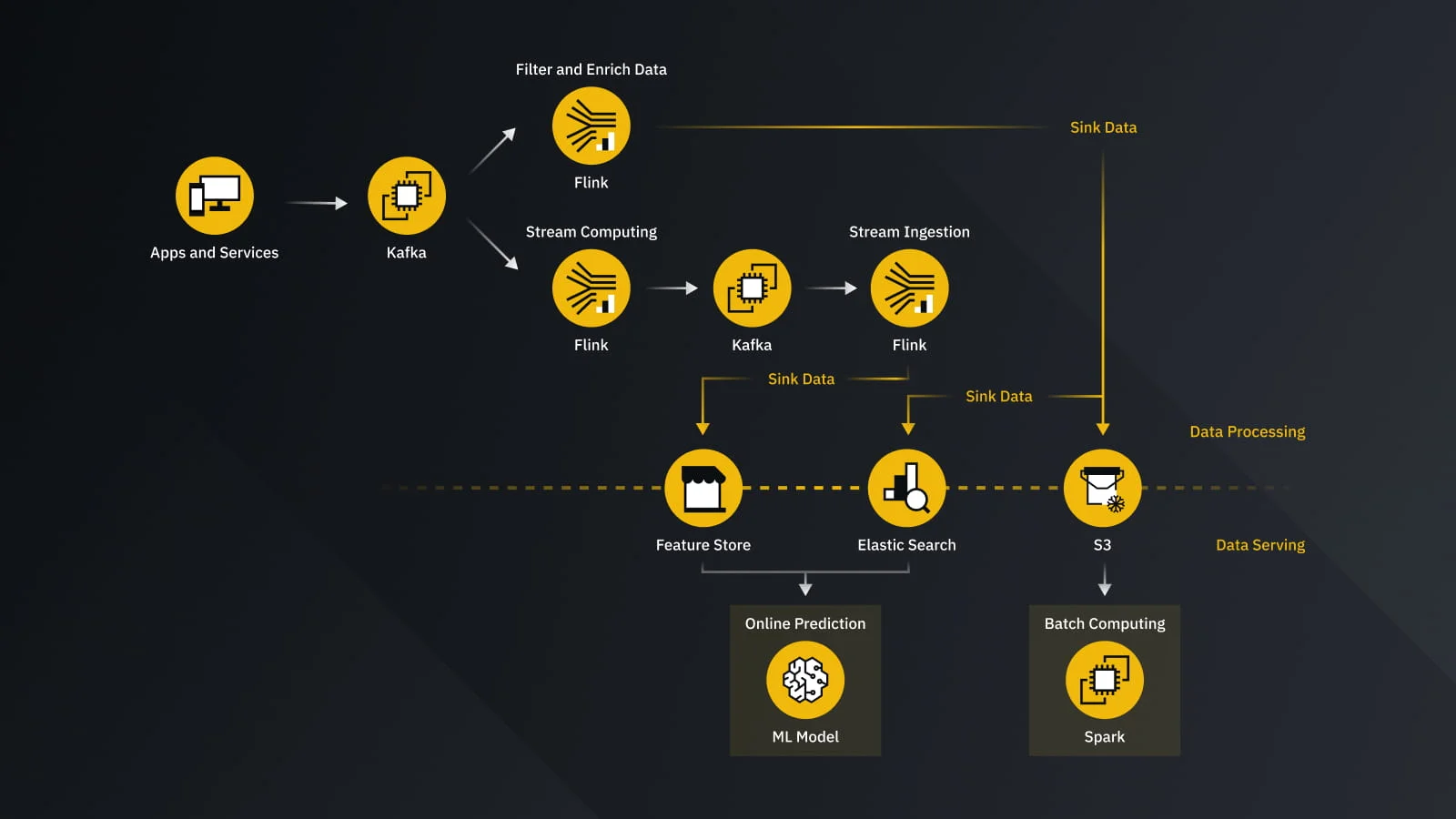
- User Data Processing: Every action a user takes, from placing an order to checking their balance, generates data. Kafka streams handle this continuous influx of events, such as withdrawals, deposits, and trades, ensuring that user dashboards are updated instantly and balance calculations are accurate .
The Operational Bottleneck of Hyper-Scale Kafka
While Kafka is powerful, its traditional architecture was not designed for the elasticity and cost model of the modern cloud. Running complex, multi-stage streaming pipelines for mission-critical tasks like fraud detection, as Binance does , exposes the operational pain points of running Kafka at scale.
-
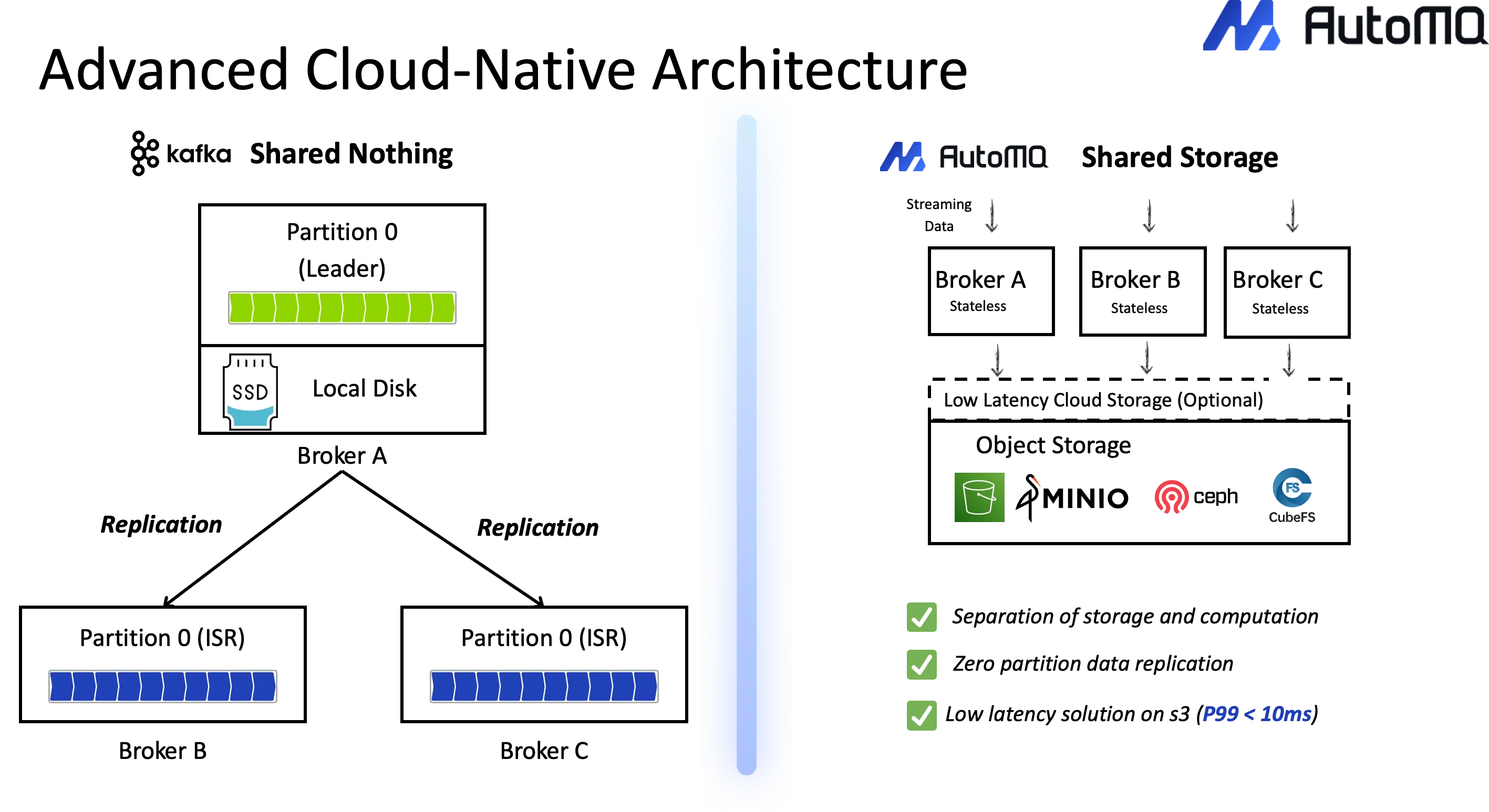
The Scaling Nightmare: In a traditional "shared-nothing" architecture, Kafka's data is tightly coupled to the local disks of specific brokers. When a cluster needs more capacity to handle a market surge, one cannot simply add a new, stateless machine. An operator must perform a "partition rebalancing," a slow and risky process of physically copying massive amounts of data across the network from old brokers to new ones. This procedure is manual, resource-intensive, and can take hours or even days, making rapid responses to market volatility nearly impossible.
-
Cost and Operational Inefficiency: To ensure stability and prevent "noisy neighbor" problems (where one use case impacts another), organizations are often forced to deploy many separate, isolated clusters. This strategy is extremely inefficient. Each cluster must be over-provisioned with excess compute and storage to handle its own individual traffic peak. This results in massive resource waste across the organization and a ballooning cost structure, particularly from expensive block storage and inter-AZ data replication traffic.
The Cloud-Native Imperative: Solving Kafka’s Architectural Limits
The challenges described above are not unique; they are the inherent symptoms of running Kafka's traditional architecture in the cloud. The fundamental problem is the coupling of compute (the broker) and storage (the local disk).
This is precisely the problem that modern, cloud-native Kafka implementations like AutoMQ were built to solve. By re-architecting Kafka from the ground up, AutoMQ decouples compute from storage, leveraging reliable and inexpensive object storage (like S3) as the primary data store. This single architectural shift directly addresses all the critical pain points seen at hyper-scale.
-
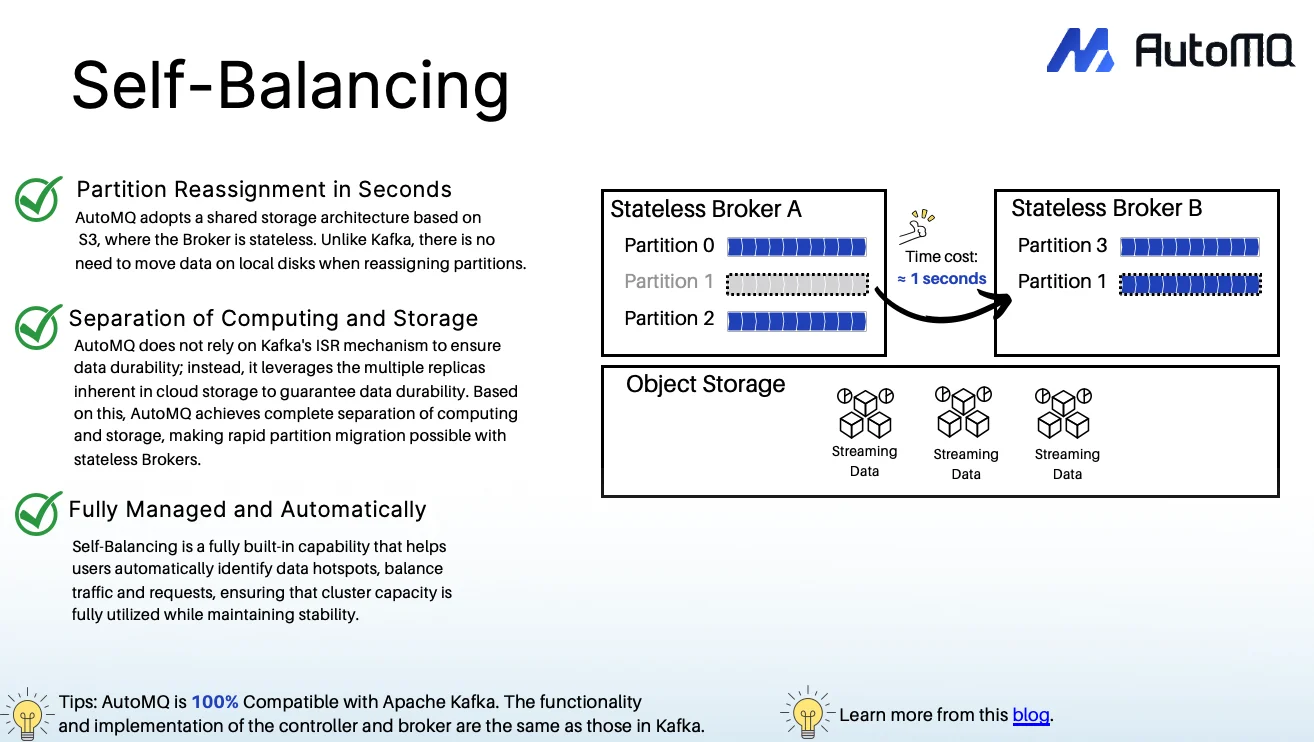
Instant, Effortless Elasticity: AutoMQ's brokers are stateless. This completely eliminates the data-copying nightmare of partition rebalancing. Partition reassignment becomes a near-instant metadata change that completes in seconds. This allows scaling time to drop from hours in a traditional setup to just seconds, enabling true, on-demand auto-scaling.
-
Massive Cost Reduction: The traditional model of over-provisioned clusters is financially unsustainable. AutoMQ tackles this by cutting Kafka TCO by up to 90%. First, it replaces expensive, provisioned block storage with low-cost, pay-as-you-go object storage. Second, its architecture is designed to zero out the costly inter-availability-zone (AZ) network traffic that plagues traditional Kafka replication, further reducing operational expenses.
-
True Serverless Operations: Managing numerous complex clusters is an operational burden. AutoMQ is designed as a fully managed, "zero-ops" service. With built-in capabilities like self-balancing to automatically eliminate hotspots and self-healing to manage failures, it removes the manual, complex cluster management, allowing engineering teams to focus on building products, not managing infrastructure.
Conclusion: The Future of Real-Time Streaming
Binance's experience in building real-time fraud detection systems provides a clear blueprint for the future of data streaming. It demonstrates that while the Kafka protocol is the undisputed standard, its traditional implementation is buckling under the demands of cloud-native, hyper-scale applications.
The future does not lie in endlessly patching an architecture that was built for on-premise data centers. It lies in modern platforms like AutoMQ that embrace a cloud-native design from the ground up. AutoMQ offers the best of both worlds: it remains 100% compatible with the Apache Kafka protocol , protecting all existing ecosystem investments. However, by running on a decoupled, shared-storage architecture, it delivers the financial-grade, low-latency performance required (p99 < 10ms) while finally solving the core, real-world challenges of elasticity, cost, and operational management that global leaders face every day.


