


.png)
TL;DR
The 24/7 digital asset economy runs on real-time data. For industry leaders like Coinbase, Apache Kafka is the foundational platform for processing this constant flow of information. This blog explores Coinbase's specific Kafka use cases and the architectural challenges they faced at scale.
Why Real-Time Data Streaming is Non-Negotiable in Finance
In an environment where asset prices and transactions occur continuously, traditional data processing methods like nightly batch jobs are insufficient. Request-response systems also face challenges in broadcasting data to a large number of internal and external consumers. The financial industry requires a persistent, immutable log of events. This ensures that every transaction and market event is recorded in a durable and ordered manner, which is essential for auditing, system-wide consistency, and recovery [1]. An event-streaming platform effectively serves as the central nervous system for a modern financial services company, capturing every event and making it available for real-time processing and analysis across the organization [2].
Core Use Cases: Kafka as Coinbase's Data Backbone
At Coinbase, Kafka is not a peripheral tool but a core component of its data infrastructure, supporting a wide array of business-critical functions.
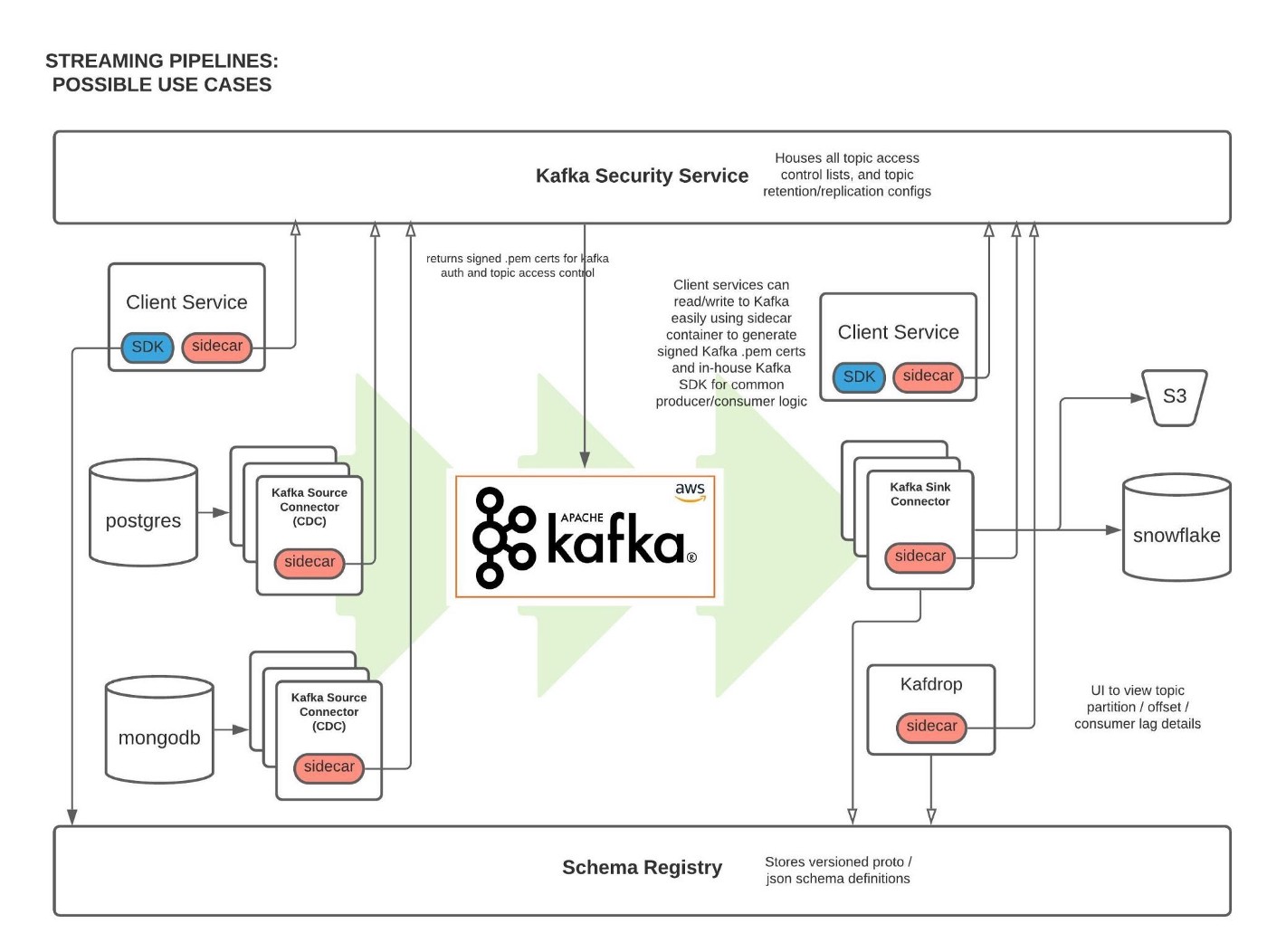
Real-Time Market and Transaction Data
The most direct application is the processing and distribution of the immense flow of real-time data. This includes:
Market Data: Order books, price ticks, and trade executions generated by matching engines.
User Transactions: Deposits, withdrawals, and trade activities.
Kafka topics are used to decouple the producers of this data (the core transaction and matching systems) from the many consumers. This allows user-facing frontends, mobile apps, and internal dashboards to subscribe to relevant data streams without directly querying or burdening the primary production systems.
Enabling a Decoupled, Event-Driven Architecture
Kafka is instrumental in Coinbase's move away from traditional point-to-point integrations and toward a more flexible, event-driven microservices architecture [4]. In this model, instead of services calling each other directly, they communicate asynchronously by producing and consuming events from Kafka topics. This decoupling allows different teams and services to develop and scale independently. A new service that needs access to transaction data can simply subscribe to the relevant Kafka topic, without requiring changes to the core systems that produce that data [4].
Data Integration for Analytics and Compliance
Kafka serves as a high-throughput pipeline for downstream data integration. Data from Kafka topics is streamed into other systems, such as data warehouses, data lakes, and analytics platforms [5]. This integration supports several key functions:
Real-time Business Intelligence: Powering dashboards that monitor business health and user activity.
Fraud Detection: Allowing security systems to analyze transaction patterns in real-time to identify and block suspicious activity.
Compliance Reporting: Creating reliable data pipelines for the data required for regulatory and compliance audits [5].
The Challenge: Evolving Kafka for Massive Scale
As Coinbase's user base and data volumes grew, its data streaming infrastructure faced substantial operational challenges.
The Operational Hurdles of Self-Management
The company's engineering teams initially ran large, self-managed Kafka deployments. However, this came with a high operational cost [4]. Teams spent a considerable amount of time and resources on complex, manual tasks. These included provisioning new clusters, executing multi-step version upgrades, and performing delicate partition rebalancing to manage data load. This operational toil became a bottleneck, slowing down product teams that relied on the data platform [3, 4].
The Strategic Renovation: A Cloud-Native Shift
To address these issues, Coinbase initiated a "renovation" of its Kafka infrastructure. The primary goal was to reduce this operational overhead, improve reliability, and empower developer teams to build and deploy services more quickly [4]. This involved a strategic move toward a more cloud-native posture, leveraging the automation and scalability offered by cloud environments [3]. This was not just a simple migration but an architectural overhaul. Key internal improvements included:
Building standardized client libraries to ensure consistent and reliable interaction with Kafka.
Enhancing observability with better monitoring and alerting.
Using Infrastructure as Code (IaC) to automate the management and deployment of their data streaming platforms [4].
The AutoMQ Perspective: Solving the Cloud Conundrum
The journey described by Coinbase's engineering teams is a familiar one. Many organizations adopt Kafka for its powerful streaming capabilities but later encounter the operational and cost complexities of scaling it in the cloud [3, 4]. The challenges Coinbase faced—such as high operational toil for version upgrades and complex partition rebalancing—are common pain points that can consume valuable engineering resources [4].
These operational hurdles often stem from Kafka's original architecture, which couples compute (the brokers) and storage (the data on local disks). In a dynamic cloud environment, this coupling creates friction. When an organization needs to scale compute resources, add new brokers, or perform a routine version upgrade, it often triggers a slow and resource-intensive data rebalancing process. This is because data partitions must be physically copied from old brokers to new ones, a procedure that can strain networks, impact performance, and require careful manual oversight—the very definition of the "operational toil" that Coinbase sought to reduce [4].
Coinbase's strategic decision to "renovate" its infrastructure and move toward a more cloud-native posture highlights a clear industry need [4]. The goal is to retain the powerful Kafka protocol, which has become a de facto standard, but deploy it on an architecture that is truly designed for the cloud. This means achieving elasticity, reliability, and cost-efficiency without the associated management burden.
This is the core problem AutoMQ is built to solve. By re-architecting Kafka to be stateless and explicitly separating compute from storage, AutoMQ directly addresses these cloud-native challenges. In this model:
Brokers become stateless: They no longer manage persistent data on local disks. Instead, data is streamed directly to durable, low-cost cloud object storage.
Compute and storage scale independently: This is the key to cloud-native efficiency. Teams can scale compute resources up or down in seconds to meet real-time processing demands, without ever having to move or rebalance data. Storage scales automatically within the cloud's object storage layer.
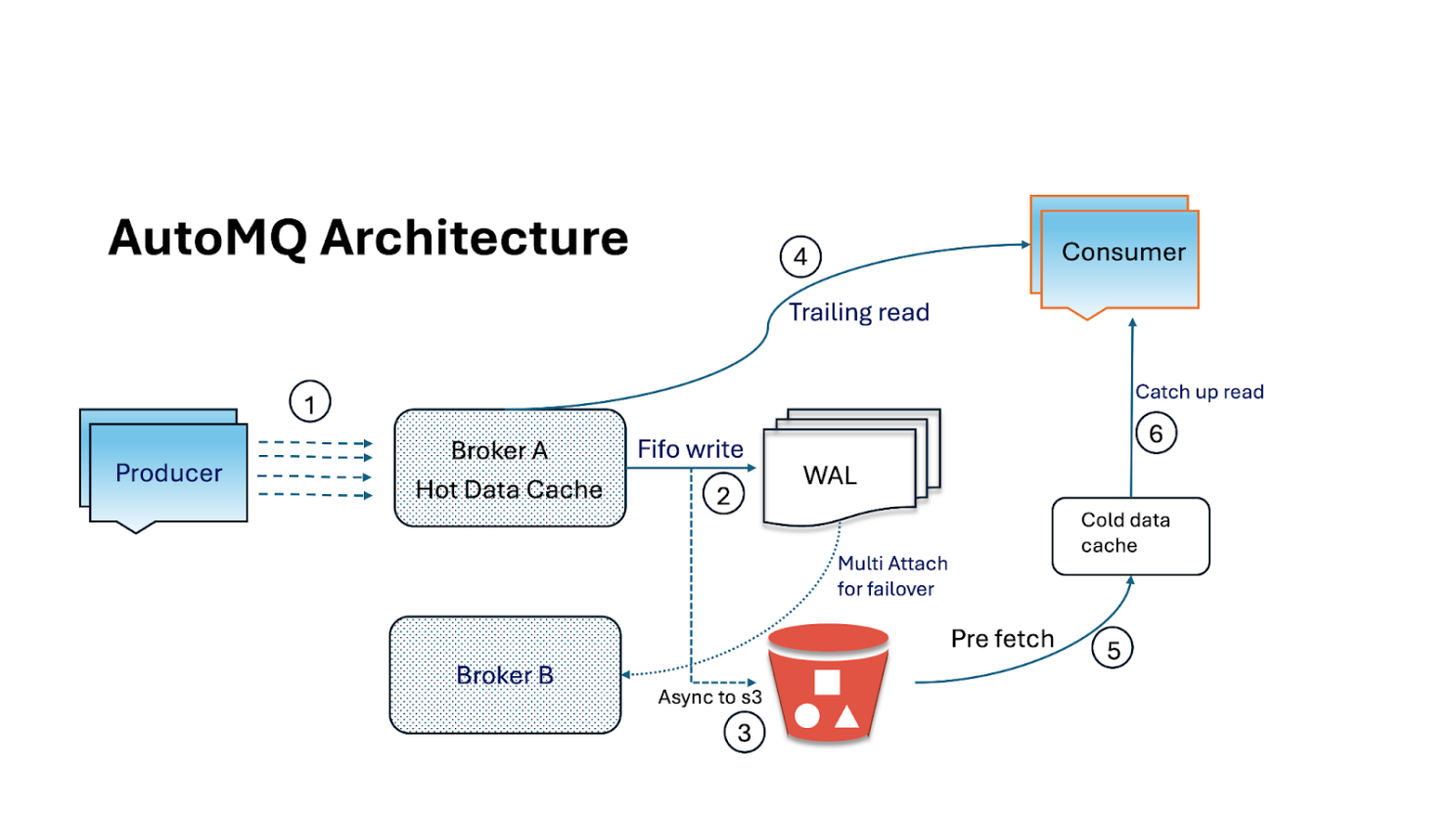
This architectural shift directly solves the pain points identified in the blog. Tasks that were operationally complex, like the rebalancing and upgrades Coinbase tackled [4], become simple and fast. There is no data to copy when scaling, making elasticity near-instantaneous. This approach not only improves cost-efficiency by eliminating the need to over-provision expensive block storage but also, more importantly, allows engineering teams to focus on their primary goal: building data-driven products and empowering developers [4], rather than managing the underlying complexity of data infrastructure.
Conclusion
For a company at the center of the digital asset economy, a data streaming platform is more than just infrastructure; it is a core component of its business strategy. As demonstrated by the use cases at Coinbase, Apache Kafka provides the foundation for real-time products, a decoupled microservices architecture, and critical analytics and compliance functions [4]. Their journey also highlights a critical lesson: as a business scales, the underlying data platform must evolve to handle cloud-native challenges of cost and operational complexity. Investing in a truly modern and scalable streaming platform—one that embraces a cloud-native architecture like AutoMQ—is essential for enabling faster product development, ensuring system resilience, and maintaining a long-term innovative edge.
References
Apache Kafka and Blockchain – Comparison and a Kafka-native Implementation
How Stablecoins Use Blockchain and Data Streaming to Power Digital Money

Interested in our diskless Kafka solution AutoMQ? See how leading companies leverage AutoMQ in their production environments by reading our case studies. The source code is also available on GitHub.
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
JD.comx AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging





