


.png)
Running Kafka on GCP sounds simple until real workloads hit. You face the same three killers every team runs into: scaling that lags behind traffic spikes, cross-zone charges that inflate your bill, and an operational burden that grows faster than your cluster.
Most teams don’t want to babysit brokers or guess capacity. They want Kafka that works inside their GCP environment, stays predictable, and avoids hidden costs. That’s why managed Kafka on GCP has become a priority for teams that need reliable, cost-efficient streaming.
This article breaks down what matters when choosing a managed Kafka service in GCP, how different deployment models compare, and where AutoMQ fits for teams that want cloud-native Kafka without giving up control of their environment.
Key Takeaways
Running Kafka on GCP is costly and rigid when it relies on legacy, disk-bound architectures and cross-AZ replication.
Most managed Kafka vendors reduce ops work but still run outside your VPC, limit control, and carry the same cost patterns.
AutoMQ changes the model by deploying entirely inside your GCP VPC, eliminating cross-AZ replication traffic, and scaling in seconds.
You keep full control of your network, storage, IAM, and data while offloading Kafka’s operational burden.
The Managed Kafka Landscape on GCP
GCP gives you several ways to run Kafka, but none of them are truly “set it and forget it.” You can deploy open-source Kafka on Compute Engine or GKE, but you’ll spend your time dealing with broker failures, rebalancing partitions, tuning storage, and chasing scaling issues. The platform doesn’t reduce Kafka’s operational drag.
On the other side are managed Kafka vendors, Confluent Cloud, Aiven, Instaclustr, Redpanda Cloud, and others. They remove part of the workload, but you trade that for higher cost, opinionated architectures, and reduced control. Most also run outside your VPC, adding compliance concerns and forcing their network paths onto your bill.
GCP’s own Managed Service for Apache Kafka simplifies provisioning, but it still uses traditional Kafka underneath. You inherit the same scaling limits, disk-bound behavior, and cross-zone costs.
What to Look For in a Managed Kafka Service on GCP
When you choose a managed Kafka service on GCP, you’re not just picking a tool; you’re picking the operational model your entire data pipeline will depend on. So you need to evaluate the service with a cold, pragmatic checklist, not a glossy marketing lens.
True Kafka API compatibility: Anything less than 100% compatibility creates migration friction, breaks your tooling, and forces workarounds. A managed service must let you keep your existing producers, consumers, connectors, and ecosystem without rewriting or revalidating core components.
Deployment inside your VPC, not the vendor’s: Data location isn’t a footnote. Running Kafka inside your own VPC means you keep full control of security boundaries, IAM, routing, and compliance. If the vendor runs the data plane outside your VPC, you lose that control and pay for their network paths.
Cloud-native scaling that actually keeps up: Traditional Kafka scaling is slow, risky, and operationally heavy. A managed service should scale quickly, ideally in seconds, not force you into overnight maintenance windows or oversized clusters “just in case.”
Predictable network cost, especially across zones: Cross-AZ traffic is where most Kafka bills explode. A managed service should minimize or eliminate cross-zone replication traffic, not hide it inside vague pricing tiers.
Operational offload without losing visibility: “Managed” should mean the vendor handles the work: monitoring, patching, failover, node replacements, and upgrades. But you also need clarity, logs, metrics, and insights that let you understand what the system is doing.
Seamless integration with GCP ecosystems: IAM, VPC networking, GKE, BigQuery, GCS, Cloud Logging, and Kafka needs to plug into these cleanly. A managed service that forces awkward workarounds or separate identity models becomes a long-term liability.
A cloud-aligned architecture, not a datacenter port: If a service is simply running legacy Kafka behind the curtain, you inherit all the same pain: disk bottlenecks, slow failover, heavy replicas, and rigid cluster boundaries. A modern service should be engineered for cloud dynamics, elasticity, shared storage, and low-overhead operations.
How AutoMQ Delivers Managed Kafka on GCP
AutoMQ approaches the “managed Kafka on GCP” problem from a different angle. Instead of running a vendor-controlled Kafka cluster you access remotely, AutoMQ deploys the control plane and data plane inside your own GCP VPC. You keep ownership of your environment, network, and data paths, while AutoMQ provides the management layer, automation, and operational tooling you expect from a cloud service.
Deployment happens through the GCP Marketplace, not a custom script or proprietary hosting setup. You launch the AutoMQ BYOC environment directly into your VPC, configure your VPC and subnet settings, and assign the service account you want AutoMQ to use. AutoMQ then provisions the control plane, generates initial credentials, and exposes a dedicated console endpoint. Nothing leaves your VPC except the Ops data you explicitly allow, system logs, and metrics stored in a separate GCS bucket you control.
This model solves three problems at once.
First, it removes data-residency concerns by keeping everything in your VPC. Second, it eliminates the hidden cross-AZ costs created by legacy multi-replica ISR architectures.
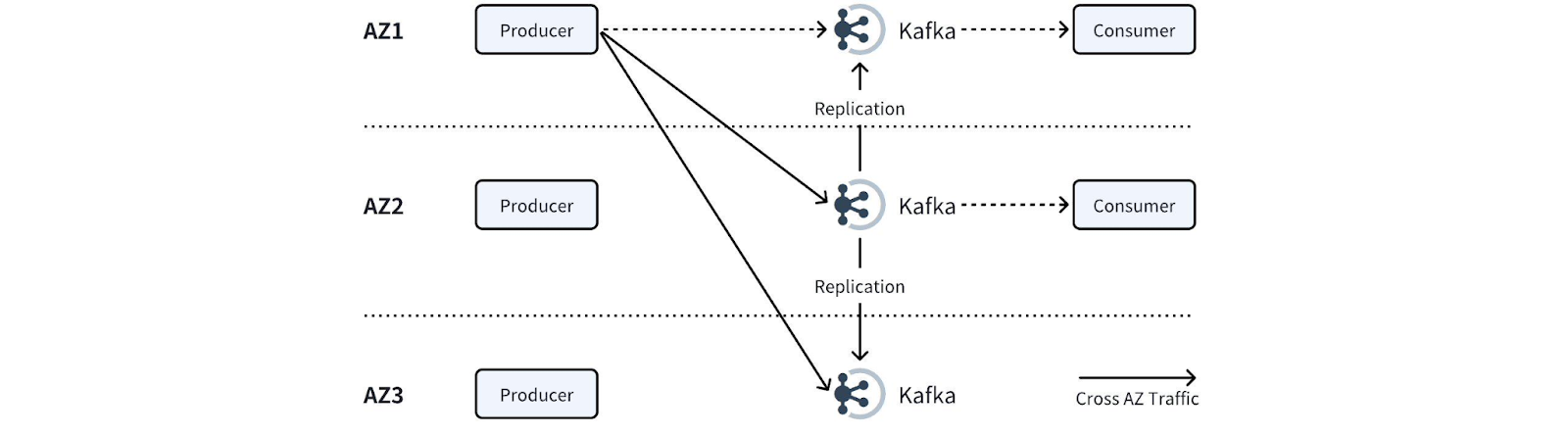
And third, it gives you the operational convenience of a managed service, automated scaling, health monitoring, and cluster operations, without giving up control of your environment.
Deployment Walk-Through
Deploying AutoMQ on GCP isn’t a science experiment. The process is structured, predictable, and built around GCP-native components you already understand. Here’s the high-level flow, stripped down to the parts that actually matter.
Prepare Your VPC for the Automq Environment
AutoMQ installs directly into your VPC, so you start by selecting the network and subnets you want to dedicate to the control plane. Each subnet needs enough available IPs, at least a four-digit count, so you don’t run into scaling limits later. One critical step here: enable private access to Google APIs. AutoMQ interacts heavily with GCS, so routing those calls through the private network avoids unnecessary public egress charges. It’s a one-time DNS and routing setup, but it saves you real money.
Launch Automq from The GCP Marketplace
From the Marketplace listing, you click Launch and fill in a short parameter form:
Deployment name
Service account
Region and zone
VPC and subnet
Console CIDR
Ops bucket and data bucket (two separate buckets)
Instance type for the control plane VM
AutoMQ deploys the environment, creates the control-plane components, and outputs everything you need: endpoint URL, username, password, environment ID, VPC ID, and deployment zone.
Log In to the Automq Console
Once deployed, you access the console using the endpoint provided in the output. The first login forces you to rotate the default password. After that, you’re inside a dedicated control plane that lives entirely in your VPC.
Grant Operational Authorization
AutoMQ never touches your data bucket. But the system still generates logs and performance metrics that need to be monitored. You grant read-only access to the Ops bucket so AutoMQ can provide proactive monitoring, stability checks, and troubleshooting support. This authorization is limited, auditable, and can be revoked at any time.
Prepare Your GKE Cluster
The data plane runs on GKE. You create a GKE cluster in the region you selected and configure it with the size and node pools you want. Once it’s ready, you connect it to the AutoMQ console.
Deploy The Automq Cluster Onto GKE
From the AutoMQ console, you link the GKE cluster and deploy a Kafka cluster with your chosen settings. AutoMQ handles provisioning, broker scheduling, and cluster initialization. At this point, your Kafka cluster is running inside your own VPC, fully managed, and backed by AutoMQ’s cloud-native architecture.
Begin Operating Kafka Through the Automq Console
You now manage everything, cluster scaling, topic configuration, monitoring, and maintenance, through AutoMQ’s console or API. The difference is that Kafka now behaves like a cloud service: elastic, streamlined, and insulated from the heavy operational patterns of legacy deployments.
The Benefits
Most managed Kafka options remove a few operational headaches but introduce new ones, higher subscription fees, unpredictable cross-zone charges, and architectures that limit control. AutoMQ flips that equation. Running inside your GCP VPC with a cloud-native design improves cost efficiency, performance, and operational control at the same time.
Cost
Traditional Kafka pays a steep penalty for replication. Every write triggers multi-AZ copies, and the bandwidth cost often exceeds compute. AutoMQ’s shared-storage architecture removes ISR replication, wiping out the internal cross-AZ traffic that inflates Kafka bills.
Performance
Legacy Kafka is disk-bound and slow to adapt to load spikes. AutoMQ separates compute and storage, making brokers stateless, scaling faster, and rebalancing lighter.
Control
Other managed services push traffic into the vendor’s VPC. AutoMQ keeps the full deployment inside your. IAM, routing, and buckets stay under your ownership, and Ops access is read-only and temporary.
Scalability
With no local disk coupling, AutoMQ scales in seconds and avoids oversized clusters or risky maintenance windows.
Operational
AutoMQ handles failovers, monitoring, and rebalancing while staying in your infrastructure, giving you simplicity without losing governance.
Comparing AutoMQ vs GCP Native & Other Managed Kafka Solutions
Choosing a managed Kafka service on GCP always comes down to the same trade-offs: cost, control, performance, and operational overhead. Most vendors force you to sacrifice one to gain another. AutoMQ doesn’t. Here’s the blunt comparison.
AutoMQ vs GCP’s Managed Service for Apache Kafka
GCP’s service simplifies provisioning and integrates with IAM and logging, but it still runs traditional Kafka. You inherit the same issues: rising cross-AZ replication costs, slow scaling tied to partition rebalancing, and disk-bound brokers that slow failover.
AutoMQ removes ISR replication across zones, eliminates cross-AZ traffic, and enables scaling in seconds, while running entirely inside your VPC.
AutoMQ vs Confluent Cloud
Confluent delivers strong tooling and turnkey operations, but you pay for it through high throughput pricing, vendor-controlled infrastructure, restricted network control, and aggressive cross-AZ billing. Your cluster lives in their VPC, not yours.
AutoMQ provides a managed experience without moving your data out of your VPC. You control buckets, routes, IAM, and traffic patterns.
AutoMQ vs Aiven, Instaclustr, and similar vendors
These services improve deployment but still run the data plane in their network and rely on legacy multi-replica architectures. Scaling stays slow, and network costs stay unpredictable.
AutoMQ removes local-disk coupling and offloads durability to cloud storage, eliminating cross-AZ replication.
AutoMQ vs self-managed Kafka on GCP
Self-managed Kafka gives control but demands heavy operational effort, failovers, rebalancing, storage expansion, and capacity planning.
AutoMQ preserves control while offloading complex operations, behaving like a cloud service inside your infrastructure.
When Managed Kafka on GCP Is Right For You
Managing Kafka on GCP isn’t for every team. It’s for teams hitting specific pain points tied to growth, compliance, or operational load. If any of the scenarios below sound familiar, you’re in the right zone.
Your workloads spike unpredictably: When traffic swings hard, self-managed Kafka becomes a liability. You either overprovision or fail under pressure. Fast elasticity removes that gamble.
You’re tired of firefighting operational overhead: Broker restarts, log cleanup, storage expansion, rebalancing, and patching drain engineering time. If SREs spend more time maintaining Kafka than improving reliability, managed Kafka pays for itself.
You need Kafka inside your GCP: VPC Regulated teams can’t push sensitive data into a vendor’s network. You need Kafka under your IAM boundary with auditable access paths, exactly where AutoMQ’s BYOC model fits.
You’re fighting cross-AZ network bills: Write-heavy workloads inflate networking costs. Removing replication traffic is a direct cost-cutter.
You’re adopting microservices: Microservices need a fast, predictable messaging layer, not a fragile one.
You want Kafka without lock-in: You need 100% Kafka compatibility, not a proprietary variant.
You’re scaling beyond what self-managed teams can support: Large Kafka clusters require distributed-systems expertise. Managed Kafka avoids that burden.
Conclusion
Kafka is powerful, but most GCP deployments rely on outdated, disk-bound architectures that scale slowly and generate heavy cross-AZ costs. Managed services try to help, but many only mask the underlying limitations.
AutoMQ takes a different path. It delivers a fully managed experience while keeping everything inside your GCP VPC, giving you control of your network, data, and security. Its cloud-native, shared-storage design removes cross-AZ replication costs and enables fast, flexible scaling.
If you want Kafka that actually fits GCP, elastic, efficient, and operationally light, AutoMQ gives you that without the usual trade-offs.
Interested in our diskless Kafka solution, AutoMQ? See how leading companies leverage AutoMQ in their production environments by reading our case studies. The source code is also available on GitHub.
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
JD.comx AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging






