Messaging systems have become the backbone of modern digital infrastructure. From streaming analytics and IoT telemetry to payment processing and fraud detection, organizations rely on publish/subscribe (Pub/Sub) systems to transmit data seamlessly across distributed environments.
Two of the most recognized names in this space are Apache Kafka and various Pub/Sub systems such as Google Cloud Pub/Sub and AWS SNS/SQS. Both enable efficient data movement between services, but they differ in design, scalability, and operational philosophy. As enterprises evolve toward cloud-native architectures, understanding these differences is critical for balancing performance, reliability, and cost.
This article explores Pub/Sub vs. Apache Kafka, their architectures, strengths, and trade-offs, before introducing how AutoMQ, a cloud-native and Kafka-compatible platform, helps enterprises achieve high scalability and cost efficiency without the operational complexity of traditional systems.
Key Takeaways
-
Pub/Sub offers simplicity, automatic scaling, and low maintenance, ideal for lightweight, event-driven workloads.
-
Apache Kafka delivers high throughput, durability, and replay, perfect for complex, high-volume data pipelines.
-
Both systems have trade-offs: Pub/Sub can become costly at scale, while Kafka demands significant operational management.
-
AutoMQ bridges the gap as a cloud-native, diskless Kafka on S3, combining Kafka’s power with Pub/Sub’s elasticity.
-
The future of data streaming lies in elastic platforms, cost-savvy, and cloud-optimized, and AutoMQ leads that transformation.
What Is the Publish/Subscribe (Pub/Sub) Pattern?
The publish/subscribe (Pub/Sub) pattern is a widely used messaging model that enables asynchronous communication between different parts of a system. Instead of sending data directly from one service to another, Pub/Sub introduces two main roles, publishers and subscribers, that interact through topics.
-
Publishers send (or publish) messages to a topic without knowing who will receive them.
-
Subscribers listen to (or subscribe to) a topic and receive messages whenever they are published.
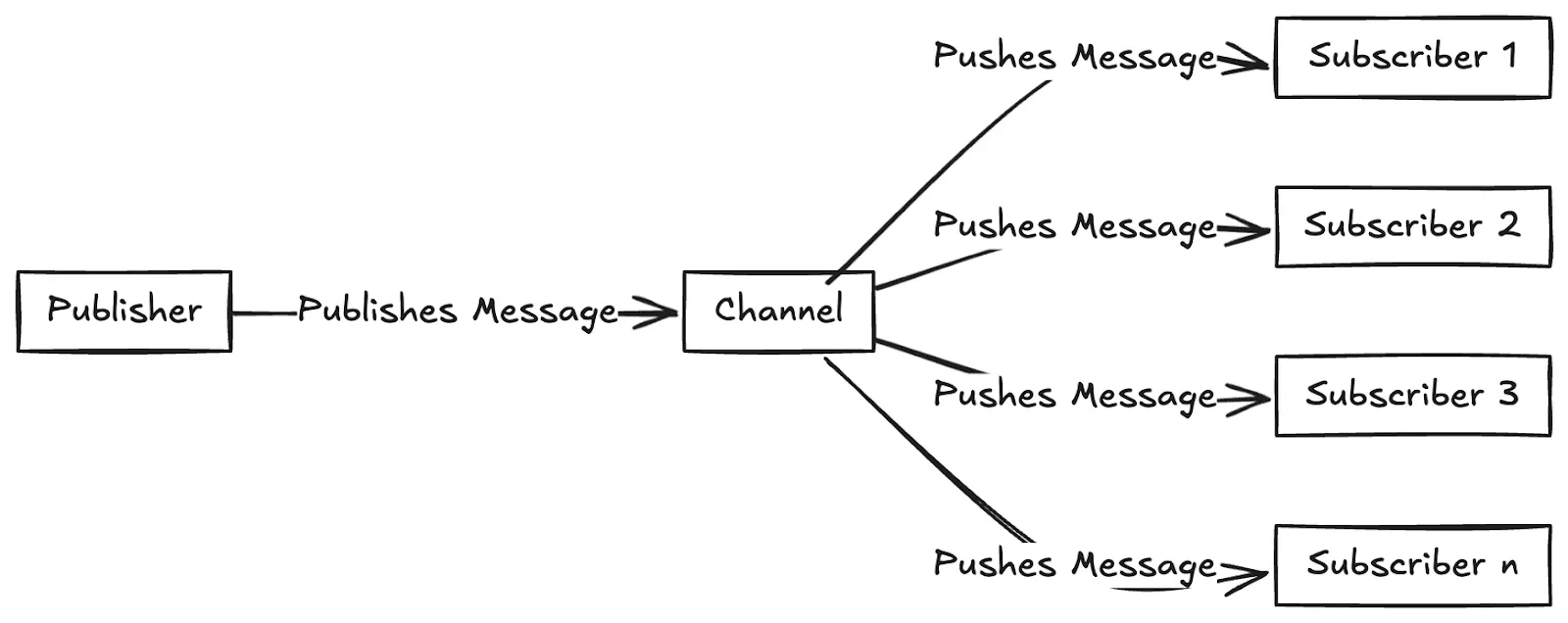
This model decouples producers and consumers, allowing each to scale independently. It’s the backbone of many event-driven architectures where systems need to react instantly to new data, such as notifications, log aggregation, telemetry, or real-time updates in cloud applications.
Modern Pub/Sub services like Google Cloud Pub/Sub, Amazon SNS/SQS, and Azure Event Grid simplify the process by handling infrastructure, scaling automatically, and ensuring message delivery with built-in redundancy. However, these managed systems typically prioritize simplicity and scalability over deep configurability, which can limit advanced control over data retention, replay, or message ordering.
What Is Apache Kafka?
Apache Kafka is an open-source, distributed event streaming platform originally developed by LinkedIn and later contributed to the Apache Software Foundation. It has become the de facto standard for building high-throughput, real-time data pipelines and streaming applications.
Unlike simple Pub/Sub systems, Kafka is designed as a durable, scalable commit log. It organizes messages into topics, which are divided into partitions distributed across multiple servers known as brokers. Each message is stored sequentially on disk, enabling consistent ordering and reliable replay whenever needed.
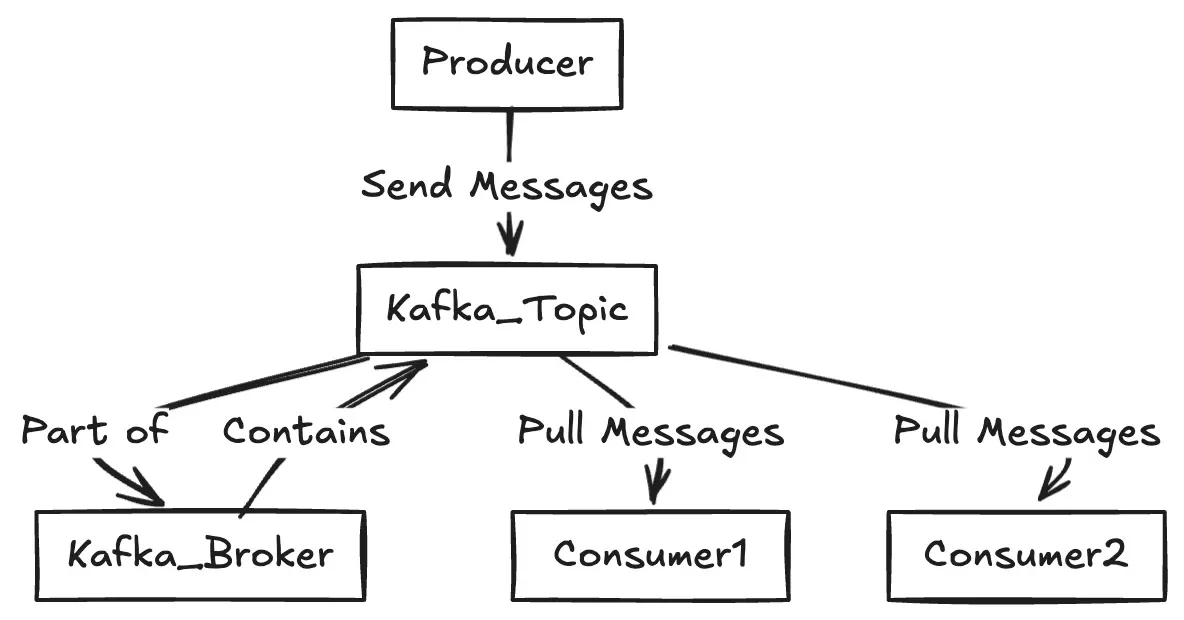
Kafka’s architecture supports three key capabilities:
-
High throughput and low latency: capable of handling millions of events per second.
-
Persistent storage and replay: messages can be retained for hours, days, or indefinitely.
-
Stream processing and integrations: a rich ecosystem, including Kafka Connect, Kafka Streams, and Schema Registry, makes it easy to integrate data across systems.
Because of these strengths, Kafka is used by thousands of companies for log aggregation, metrics collection, microservice communication, real-time analytics, and fraud detection. However, its shared-nothing architecture, which couples compute and local storage, can make cloud scaling, replication, and cost management complex in modern environments.
Pub/Sub vs. Apache Kafka
Pub/Sub and Apache Kafka often come down to the trade-off between simplicity and control. Both follow the same publish/subscribe pattern, moving data between independent applications in real time, but they’re designed for very different environments. Pub/Sub systems like Google Cloud Pub/Sub and Amazon SNS/SQS prioritize ease of use and seamless cloud scaling, while Kafka was built for enterprises that need deep control, data persistence, and stream processing at scale.
Understanding these differences helps teams align their choice with business priorities, whether that’s fast time-to-market, operational efficiency, or long-term flexibility.
Feature-by-Feature Overview
| Category | Pub/Sub (e.g., Google Cloud Pub/Sub) | Apache Kafka |
|---|---|---|
| Deployment Model | Fully managed, serverless cloud service | Open-source platform, self-hosted or managed by third parties |
| Architecture | Abstracted infrastructure that hides brokers and partitions | Distributed log with brokers, topics, and partitions |
| Scalability | Auto-scales automatically with demand | Scales horizontally by adding brokers; requires planning |
| Data Retention & Replay | Short-term retention (hours to days); limited replay | Long-term retention (days to months); full replay from any offset |
| Message Ordering | Best-effort or per-key ordering | Strict ordering within partitions |
| Latency & Throughput | Predictable, low latency for moderate workloads | Optimized for massive throughput and sub-millisecond latency |
| Operations & Management | Minimal maintenance, handled by the provider | Requires tuning, monitoring, and upgrades by internal teams |
| Cost Model | Pay per request and data transfer | Pay for infrastructure, replication, and storage usage |
| Cloud Flexibility | Bound to specific cloud ecosystems | Portable across on-premises, hybrid, and multi-cloud environments |
| Ecosystem & Integrations | Tight integration with its own cloud services | Rich open-source ecosystem (Kafka Streams, Connect, Schema Registry) |
Scalability and Elasticity
Pub/Sub systems shine where workloads are unpredictable. They automatically scale up or down with traffic, removing the need for capacity planning. Kafka requires adding brokers and rebalancing partitions manually, which can be complex, but allows greater control for predictable, heavy workloads.
Performance and Latency
Kafka’s distributed log architecture delivers ultra-low latency and high throughput, ideal for analytics pipelines, fraud detection, or event sourcing. Pub/Sub prioritizes simplicity and stability, maintaining consistent latency suitable for notifications, telemetry, or background processing.
Data Durability and Replay
Kafka’s persistent storage gives it an edge in data replay and recovery, allowing systems to rebuild state or reprocess events anytime. Pub/Sub focuses on transient message delivery, which limits historical traceability.
Operational Complexity
Pub/Sub hides infrastructure behind APIs, making it maintenance-free. Kafka, while powerful, demands continuous tuning and monitoring, but rewards users with complete control and flexibility.
Cost Efficiency
Pub/Sub charges per message and transfer, potentially expensive for high-volume workloads. Kafka’s costs arise from compute, storage, and replication, often leading to over-provisioning. Both models can become costly without elasticity or automation.
When to Choose Pub/Sub, When to Choose Kafka
Both Pub/Sub and Apache Kafka are excellent for real-time data delivery, but they shine in different scenarios. Understanding when to use which can save organizations from unnecessary cost or complexity.
Choose Pub/Sub When:
-
You need simplicity and fast deployment.
-
Workloads fluctuate significantly and need automatic scaling.
-
You’re fully invested in a single cloud provider (e.g., GCP, AWS).
-
You prefer low operational overhead over detailed control.
-
You manage moderate volumes and value predictable, pay-as-you-go pricing.
Choose Apache Kafka When:
-
You need full control and configurability.
-
Data durability and replay are mission-critical.
-
You process very high data volumes.
-
You require strict ordering and consistency.
-
You need multi-cloud or hybrid deployment flexibility.
Decision Checklist
| Priority | Recommended Platform |
|---|---|
| Fast setup, minimal management | Pub/Sub |
| Complex event streaming and data pipelines | Kafka |
| Strict ordering and replay needs | Kafka |
| Variable workloads and auto-scaling | Pub/Sub |
| Deep integration with a specific cloud | Pub/Sub |
| Multi-cloud or hybrid architecture | Kafka |
| Long-term cost efficiency and flexibility | Kafka-compatible cloud-native solution (e.g., AutoMQ) |
For many enterprises, the ideal solution is neither pure Pub/Sub nor self-managed Kafka; it’s a Kafka-compatible, cloud-optimized platform that combines ease of use, elasticity, and cost control.
Introducing AutoMQ: The Evolved Kafka-Compatible Option
As enterprises modernize their data infrastructure, many face a trade-off between Pub/Sub’s simplicity and Kafka’s control. AutoMQ bridges this gap as the only low-latency, diskless Kafka® on S3, purpose-built for the cloud era.
AutoMQ reimagines Kafka with a shared storage architecture that separates compute from storage, enabling brokers to scale elastically in seconds, without rebalancing or data movement. This approach delivers the performance of Kafka with the elasticity and efficiency of a managed cloud service.
Unlike partial alternatives, AutoMQ is 100% Kafka API compatible. Organizations can migrate seamlessly without changing client code, connectors, or tools like Kafka Connect, Schema Registry, or Strimzi Operator.
By eliminating intra-cluster replication, AutoMQ achieves zero cross-AZ traffic costs, addressing one of the biggest expenses in cloud Kafka deployments. It also leverages low-latency block storage (EBS, FSx) for acceleration, achieving single-digit millisecond latency for demanding workloads.
Real-world adopters, such as Grab, have reported up to 3× cost efficiency improvements and significantly faster scaling times after implementing AutoMQ.
AutoMQ offers flexible deployment models:
-
BYOC (Bring Your Own Cloud): Deploy entirely within your own VPC for full data privacy and pay-as-you-go flexibility.
-
AutoMQ Software: A self-managed enterprise option for Kubernetes or on-premises environments.
Best Practices for Adopting the Right Data Streaming Platform
Selecting between Pub/Sub, Apache Kafka, or a Kafka-compatible platform like AutoMQ requires balancing scalability, performance, and operational efficiency. The following best practices can help guide that choice.
Define Your Use Case Clearly
Identify your streaming goals, real-time analytics, notifications, or data pipelines.
-
Pub/Sub fits lightweight, event-driven tasks.
-
Kafka suits complex, high-volume processing.
-
AutoMQ blends both for scalable, cloud-native workloads.
Assess Operational Capacity
Consider how much infrastructure management your team can handle. Kafka requires ongoing tuning and monitoring, while managed or BYOC platforms like AutoMQ simplify operations without losing control.
Prioritize Elasticity and Cost Control
Workloads fluctuate; your platform should scale accordingly. Pub/Sub auto-scales but can grow costly; Kafka offers control but risks over-provisioning. AutoMQ enables scaling in seconds and pay-as-you-go pricing to align cost with usage.
Ensure Data Durability and Replay
If you need to reprocess historical data or recover from failures, Kafka and AutoMQ offer durable storage and replay, while most Pub/Sub systems do not.
Check Integration Compatibility
Your platform should connect easily with data lakes, analytics tools, and workflow engines. AutoMQ maintains full Kafka ecosystem compatibility, supporting existing connectors and operators.
Adopt Cloud-Native Design
Avoid simply “lifting and shifting” Kafka to the cloud. Modernize with architectures that separate compute from storage for better performance and cost efficiency.
The right data streaming choice depends on your team’s expertise, workload patterns, and growth plans. Platforms like AutoMQ now make it possible to achieve Kafka-grade reliability with Pub/Sub-like simplicity, built for the elasticity of the cloud.
Conclusion
The debate between Pub/Sub and Apache Kafka reflects how organizations manage data in the cloud era. Pub/Sub excels in simplicity and elasticity, while Kafka offers unmatched durability and ecosystem depth. Yet, both can become expensive or complex at scale.
That’s why enterprises are embracing AutoMQ, a cloud-native, Kafka-compatible platform that merges Kafka’s reliability with Pub/Sub’s scalability and efficiency. With AutoMQ, teams can scale in seconds, eliminate replication costs, and simplify streaming operations, all without rewriting a single line of Kafka client code.
AutoMQ delivers that evolution, combining the scalability of Pub/Sub with the reliability of Kafka, purpose-built for the cloud.
Still struggling with skyrocketing Kafka bills and the "ops tax" of manual disk management? It's time to stop babysitting your clusters. Try AutoMQ Cloud for Free and experience how diskless architecture slashes costs and automates scaling—no credit card required. See how others made the switch in our case studies or explore the project on GitHub.


