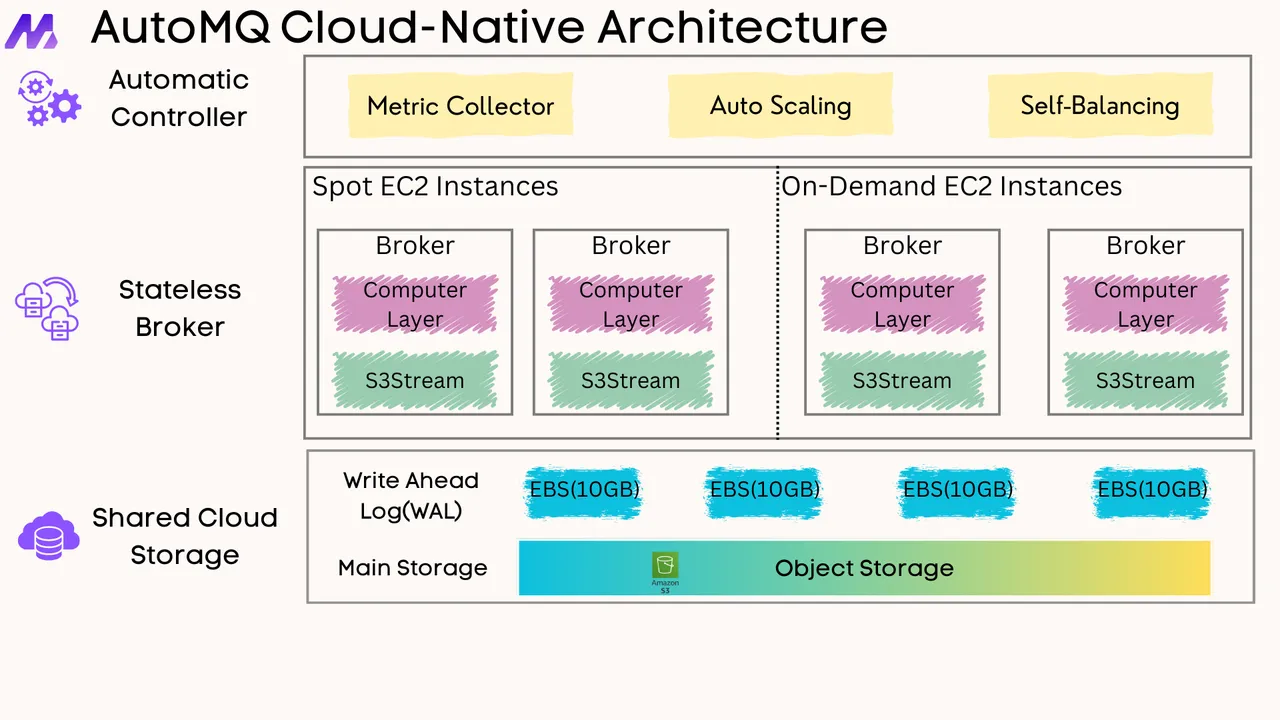
.png)
Overview
Apache Kafka has become the backbone for real-time data streaming, powering everything from microservices communication to large-scale analytics. When deploying Kafka, a critical architectural decision is whether to go with a single-cloud or a multi-cloud setup. Both approaches have their merits and challenges, and the right choice depends heavily on your specific needs and organizational strategy. Let's break them down.
What is Apache Kafka? A Quick Refresher
Before we dive into cloud deployment models, let's briefly recap what Kafka is. At its core, Kafka is a distributed event streaming platform capable of handling trillions of events a day [1]. It allows you to:
Publish and subscribe to streams of records, similar to a message queue or enterprise messaging system.
Store streams of records in a fault-tolerant, durable way.
Process streams of records as they occur.
Key components include brokers (servers that form the Kafka cluster), topics (categories or feed names to which records are published), partitions (topics are split into these for scalability and parallelism), producers (applications that publish data to topics), and consumers (applications that subscribe to topics and process the data).
Single-Cloud Kafka: Simplicity and Integration
A single-cloud Kafka deployment means your entire Kafka infrastructure, including brokers, Zookeeper/KRaft controllers, and potentially the applications producing and consuming data, resides within a single cloud provider's ecosystem (e.g., AWS, Azure, or GCP).
![Cloud Service Providers [10]](https://static-file-demo.automq.com/6809c9c3aaa66b13a5498262/69099d9e062604d45cfe27fa_67480fef30f9df5f84f31d36%252F685e67846af15227ba5e5c61_hOi4.png)
How it Works
You can deploy Kafka in a single cloud in a few ways:
Self-Managed: You provision virtual machines (VMs) in the cloud provider and install/configure Kafka yourself. This gives you maximum control but also maximum operational overhead.
Managed Service: Most major cloud providers offer managed Kafka services. These services handle much of the operational burden like patching, scaling, and broker provisioning, allowing you to focus on your applications.
Kubernetes-based Deployment: Using Kubernetes (like EKS, AKS, or GKE) to deploy and manage Kafka, often via operators, can offer a balance of control and automation [2].
Advantages of Single-Cloud Kafka
Simplicity: Managing infrastructure within one cloud environment is generally simpler in terms of networking, security configuration, and identity management.
Lower Network Latency: If your producers, consumers, and Kafka brokers are all within the same cloud region, or even availability zone, you'll typically experience lower network latency and higher throughput [3].
Cost Efficiency (Potentially): Data transfer costs within the same cloud provider, especially within the same region, are often lower than inter-cloud data transfer costs [4]. Leveraging a cloud provider's managed service can also sometimes be more cost-effective than self-managing due to economies of scale.
Easier Integration: Seamless integration with other native services (e.g., storage, monitoring, serverless functions) offered by the same cloud provider is a significant plus.
Simplified Operations & Monitoring: Using a single cloud provider's tools and dashboards can streamline operations and monitoring [5].
Disadvantages of Single-Cloud Kafka
Vendor Lock-in: Relying heavily on a single cloud provider's services can lead to vendor lock-in, making it difficult or costly to migrate to another provider or an on-premises solution later.
Regional Outages: If the specific cloud region where your Kafka cluster is deployed experiences an outage, your data streaming capabilities can be significantly impacted unless you've engineered for multi-region failover within that single cloud, which adds complexity.
Data Sovereignty Constraints: If you need to store and process data in specific geographic locations where your chosen cloud provider doesn't have a strong presence, it can be challenging.
Limited Flexibility for Specific Needs: You might find that another cloud provider offers a specific service or pricing model that's better suited for a particular part of your workload, but you're constrained by your single-cloud choice.
Multi-Cloud Kafka: Resilience and Flexibility
A multi-cloud Kafka deployment involves running your Kafka clusters or components of your Kafka ecosystem across two or more cloud providers. This can take several forms, from stretching a single Kafka cluster across clouds (less common and technically challenging) to having separate Kafka clusters in different clouds that replicate data between them.
How it Works
Achieving a multi-cloud Kafka setup typically involves data replication mechanisms to keep data synchronized across clusters in different clouds. Common approaches include:
Active-Passive: One Kafka cluster in a primary cloud serves live traffic, while a replica cluster in a secondary cloud is kept in sync for disaster recovery. If the primary fails, traffic switches to the passive cluster.
Active-Active: Kafka clusters in multiple clouds are all active and serving traffic, often for different applications or geographic regions. Data might be replicated bidirectionally or in a specific topology (e.g., hub-spoke).
Stretched Clusters (across regions/zones within one cloud, sometimes attempted across clouds): While stretching a single Kafka cluster across different cloud providers is generally not recommended due to high latency and complexity, multi-region stretched clusters within a single provider are more common for high availability. The principles can sometimes be adapted for multi-cloud thinking, but inter-cloud latency is a killer.
Data Replication Tools:
MirrorMaker 2: An Apache Kafka tool for replicating data between Kafka clusters. It's designed for cross-cluster replication and can be configured for various multi-cloud scenarios [6].
Proprietary Replication Solutions: Some Kafka vendors offer advanced replication technologies that provide features like exactly-once semantics, offset synchronization, and easier management for multi-cluster and multi-cloud setups.
Kafka Connect: Can be used with appropriate connectors to sink data from a Kafka cluster in one cloud and source it into another, or into other systems across clouds.
Advantages of Multi-Cloud Kafka
Avoiding Vendor Lock-in: Distributing your workload across multiple clouds reduces dependency on a single provider, giving you more negotiation leverage and flexibility.
Enhanced Resilience and Disaster Recovery: If one cloud provider experiences a major outage, you can failover to your Kafka cluster in another cloud, ensuring business continuity.
Data Sovereignty and Compliance: Easily deploy Kafka clusters in specific geographic regions offered by different cloud providers to meet data residency and sovereignty requirements.
Leveraging Best-of-Breed Services: Use the best services from each cloud provider for different parts of your application stack. For example, one cloud for its AI/ML capabilities and another for its database offerings, with Kafka connecting them.
Geo-distribution and Lower Latency for Global Users: Serve users from a Kafka cluster located in a cloud provider and region closest to them, reducing latency for global applications.
Disadvantages of Multi-Cloud Kafka
Increased Complexity: Managing infrastructure, security, networking, and data replication across multiple cloud environments is significantly more complex [7]. Different APIs, CLIs, and management consoles add to the learning curve and operational burden.
Higher Costs:
Data Egress/Ingress: Data transfer costs between cloud providers can be substantial and are a major factor to consider [4].
Operational Overhead: Increased complexity often translates to higher operational costs due to the need for specialized skills and more sophisticated management tools.
Replication Tooling: Licensing costs for proprietary replication tools or the operational cost of managing open-source tools can add up.
Data Consistency Challenges: Ensuring data consistency and managing exactly-once semantics across clusters in different clouds can be challenging, especially with high network latencies. Replication lag is a key concern.
Security Management: Implementing and managing consistent security policies, identity and access management (IAM), and encryption across multiple cloud providers requires careful planning and robust tooling [8]. A Zero Trust approach is often recommended but adds its own layer of implementation complexity [9].
Performance Overheads: Network latency between cloud providers can impact replication speed and overall application performance. This needs to be thoroughly tested.
Monitoring and Observability: Achieving a unified view of your Kafka deployment across multiple clouds requires integrating different monitoring systems or investing in a multi-cloud observability platform [5].
Side-by-Side Comparison
| Feature | Single-Cloud Kafka | Multi-Cloud Kafka |
|---|---|---|
| Complexity | Lower | Higher |
| Cost | Potentially lower (less data egress, simpler ops) | Potentially higher (data egress, complex ops, tooling) |
| Vendor Lock-in | Higher risk | Lower risk |
| Resilience/DR | Dependent on single provider's regional DR capabilities | Higher (provider diversity) |
| Performance | Generally better (lower intra-cloud latency) | Can be impacted by inter-cloud latency |
| Security Management | Simpler (single security model) | More complex (multiple security models to integrate) |
| Scalability | Good within the provider's limits | Good, can scale across providers |
| Data Sovereignty | Limited by provider's footprint | More flexible, choose providers based on regional presence |
| Operational Mgmt. | Simpler, unified tooling | More complex, potentially disparate tooling |
| Integration | Easier with native cloud services | More complex to integrate services across clouds |
Best Practices
For Single-Cloud Kafka:
Leverage Managed Services: Offload operational tasks to reduce management overhead and focus on application development.
Multi-AZ Deployments: Always deploy your Kafka cluster across multiple Availability Zones (AZs) within a region for high availability.
Monitor Key Metrics: Keep a close eye on broker health, topic/partition status, consumer lag, and resource utilization.
Implement Robust Security: Use encryption in transit (TLS) and at rest, configure ACLs properly, and integrate with the cloud provider's IAM.
Right-size Resources: Continuously monitor and adjust broker sizes, storage, and network capacity to optimize costs and performance.
Schema Management: Use a schema registry to manage and evolve your data schemas effectively.
For Multi-Cloud Kafka:
Choose Replication Wisely: Select a data replication tool and strategy (e.g., MirrorMaker 2, vendor solutions) that meets your consistency, latency, and operational requirements [6]. Understand the trade-offs of each.
Automate Everything: Use Infrastructure as Code (IaC) tools like Terraform to manage resources consistently across clouds.
Unified Observability: Invest in monitoring and logging solutions that can provide a single pane of glass across all your cloud environments [5].
Consistent Security Posture: Implement consistent security policies, network segmentation, and identity management across clouds. Consider Zero Trust principles [9].
Thoroughly Test Failover: Regularly test your disaster recovery and failover procedures to ensure they work as expected.
Manage Data Consistency: Be acutely aware of replication lag and its impact. Design consumers to handle potential eventual consistency or implement patterns to achieve stronger guarantees if needed.
Optimize Data Transfer: Minimize inter-cloud data transfer where possible. Process data close to its source or destination if feasible.
Consider Data Governance: Establish clear data governance policies, especially for data lineage and compliance in a distributed environment.
Common Issues and Considerations
Network Latency (Multi-Cloud): Inter-cloud network latency is a significant hurdle for synchronous operations and can impact replication lag.
Data Synchronization Failures (Multi-Cloud): Replication tools can fail or fall behind. Robust monitoring and alerting are crucial.
Offset Management in DR (Multi-Cloud): Ensuring consumers pick up from the correct offset after a failover to a replica cluster requires careful configuration of replication tools or consumer-side logic.
Configuration Drift (Multi-Cloud): Maintaining consistent configurations across clusters in different environments can be challenging without strong automation.
Cost Overruns (Both, but especially Multi-Cloud): Unexpectedly high data transfer costs or inefficient resource utilization can blow budgets.
Complexity of Upgrades (Both): Upgrading Kafka brokers, especially in large or geographically distributed setups, requires careful planning to avoid downtime.
Consumer Group Rebalancing: Can cause temporary processing pauses. Understand its triggers and tune appropriately.
Conclusion: Which Path to Choose?
The decision between single-cloud and multi-cloud Kafka isn't one-size-fits-all.
Choose Single-Cloud Kafka if:
Your organization is primarily committed to one cloud provider.
Simplicity of operations and tight integration with a specific cloud ecosystem are paramount.
Your disaster recovery needs can be met by multi-region setups within that single cloud.
You want to minimize upfront complexity and operational overhead, especially if using a managed service.
Choose Multi-Cloud Kafka if:
Avoiding vendor lock-in is a strategic imperative.
You require the highest levels of resilience against provider-wide outages.
You have strict data sovereignty requirements that necessitate using different providers in different regions.
You need to leverage unique best-of-breed services from multiple cloud providers.
Your application is globally distributed and benefits from users accessing Kafka endpoints in the nearest cloud.
Ultimately, evaluate your organization's technical capabilities, risk tolerance, budget, and strategic goals. Start with a clear understanding of your data streaming needs and then map those to the strengths and weaknesses of each cloud deployment model. Both approaches can be successful when implemented thoughtfully with a keen eye on the associated trade-offs.
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
JD.comx AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging