
Author: Gao Shengyuan, Senior DevOps Engineer, Tencent Music Entertainment (TME)
Background
Tencent Music Entertainment Group (TME) is a pioneer in China's online music and entertainment industry, offering two primary services: online music and music-centric social entertainment. TME has an extensive user base in China and operates some of the country's most well-known mobile audio products, including QQ Music, Kugou Music, Kuwo Music, WeSing, and Lazy Audio.
Technical Architecture
For a platform like Tencent Music Entertainment (TME) with its massive user base, efficient data flow, processing, and analysis are foundational to unlocking data value and supporting rapid business growth. In this data ecosystem, Kafka plays a crucial role as the core data infrastructure. It serves as more than just a pipeline connecting data producers and consumers; it is also key in building observability systems and data platforms, decoupling upstream and downstream services, and simplifying workflows. The introduction of Kafka allows data sources and applications to evolve independently, without concern for each other's implementation details. It also enables business units to consume data in real-time on-demand and flexibly handle various peripheral processing logic, which is essential for supporting TME's diverse business scenarios and high-speed growth.
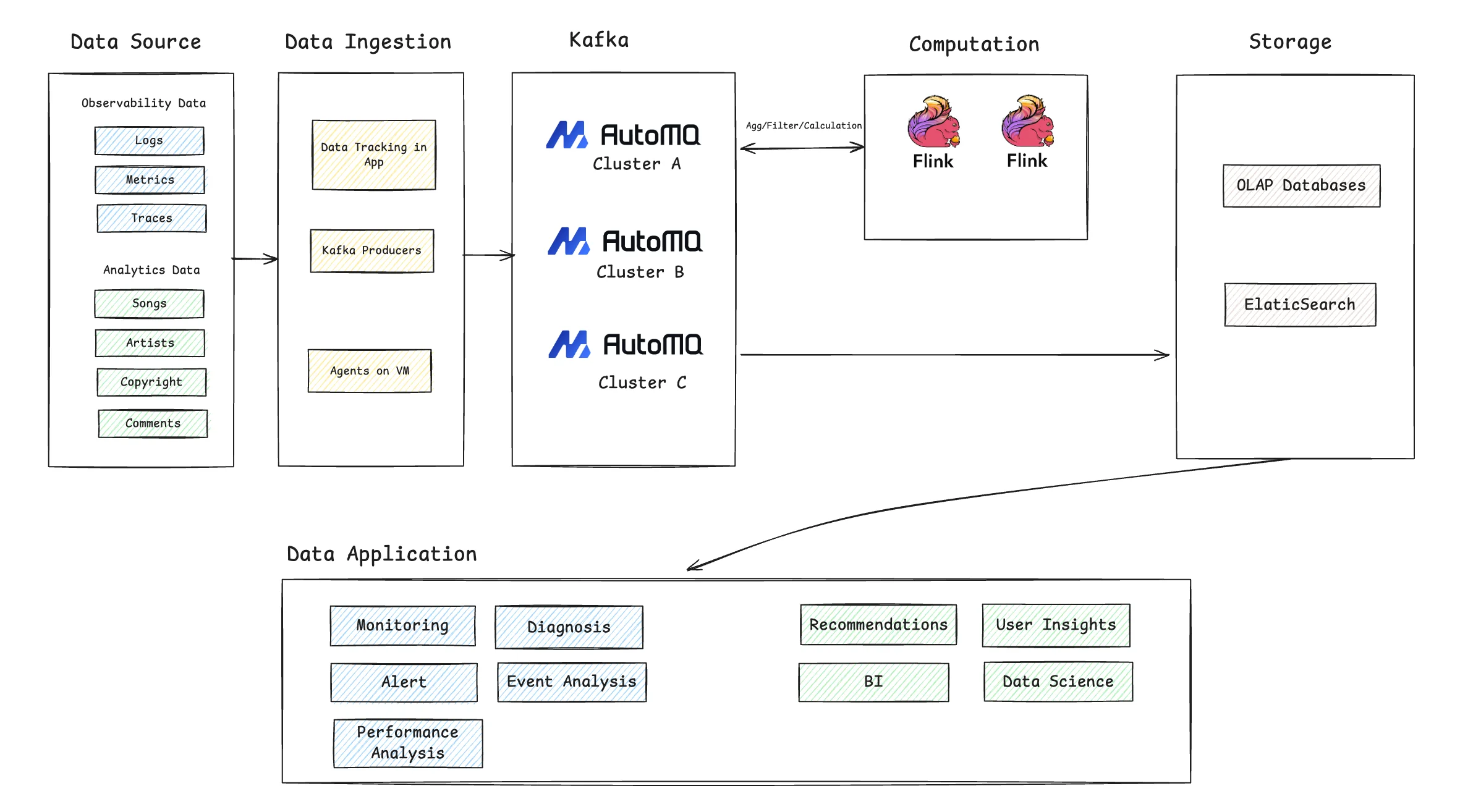
The following diagram illustrates the modern, real-time data streaming architecture TME has built on AutoMQ. The entire data flow begins with collection from data sources, passes through data ingestion, the Kafka streaming system, real-time computation, and storage, ultimately serving various upper-level data applications. The specific process is as follows:
-
Data Source: Data sources are divided into two main categories. The first is observability data , including massive volumes of service logs, key metrics, and trace information. The second is analytics data , covering business metadata like songs, artists, and copyrights, as well as user behavior data such as plays and comments.
-
Data Ingestion: TME's internal "Data Channel" platform acts as the unified entry point for all data ingestion. This platform encapsulates various reporting methods, such as service instrumentation and Kafka Producers. Its core value lies in the pre-processing it performs before data enters AutoMQ, including region and business differentiation, field filtering, security authentication, and intelligent routing. This process not only ensures that only compliant and accurate data enters the core system but also significantly improves ingestion efficiency and data governance. Different types of data are collected and reported through corresponding components. For example, applications use integrated SDKs for tracking, business services report data via standard Kafka Producers, and agents deployed on virtual machines collect various system logs and metrics.
-
Streaming System (Kafka): All ingested data flows into the AutoMQ clusters, which serve as the core data bus. Here, AutoMQ handles peak data loads from various business lines, providing high-throughput, low-latency, and reliable data streams for downstream computation and storage. By deploying multiple AutoMQ clusters (like Clusters A, B, and C in the diagram), TME achieves business isolation and granular management.
-
Computation: Before being written to final storage, data typically passes through an optional real-time computation layer. TME uses Flink as its primary computation engine to perform real-time aggregations, filtering, and complex calculations on the raw data streams from Kafka. This step is key for implementing real-time monitoring alerts, data cleansing, and pre-processing. For example, a Flink job might consume data from AutoMQ Cluster A, process it, and then write the results back for other services to use.
-
Storage: After real-time processing, the data is written to different storage systems to meet various query demands. A portion of the data flows into an OLAP database for subsequent interactive analysis and BI reporting. Another portion, especially logs and trace data, is written to Elasticsearch to support fast search and issue diagnostics.
-
Data Application: At the top of the architecture are the various data applications that directly serve the business and technical teams. These applications can be broadly divided into two categories:
-
Observability Applications: Built on real-time data streams, these applications provide powerful real-time monitoring and alerts, intelligent fault diagnosis, and event and performance analysis to ensure business stability.
-
Data Analytics Applications: Utilizing processed data to drive high-level business decisions, including personalized recommendations, user insights, Business Intelligence (BI) analysis, and data science modeling, to achieve data-driven, refined operations.
-
Kafka Challenges
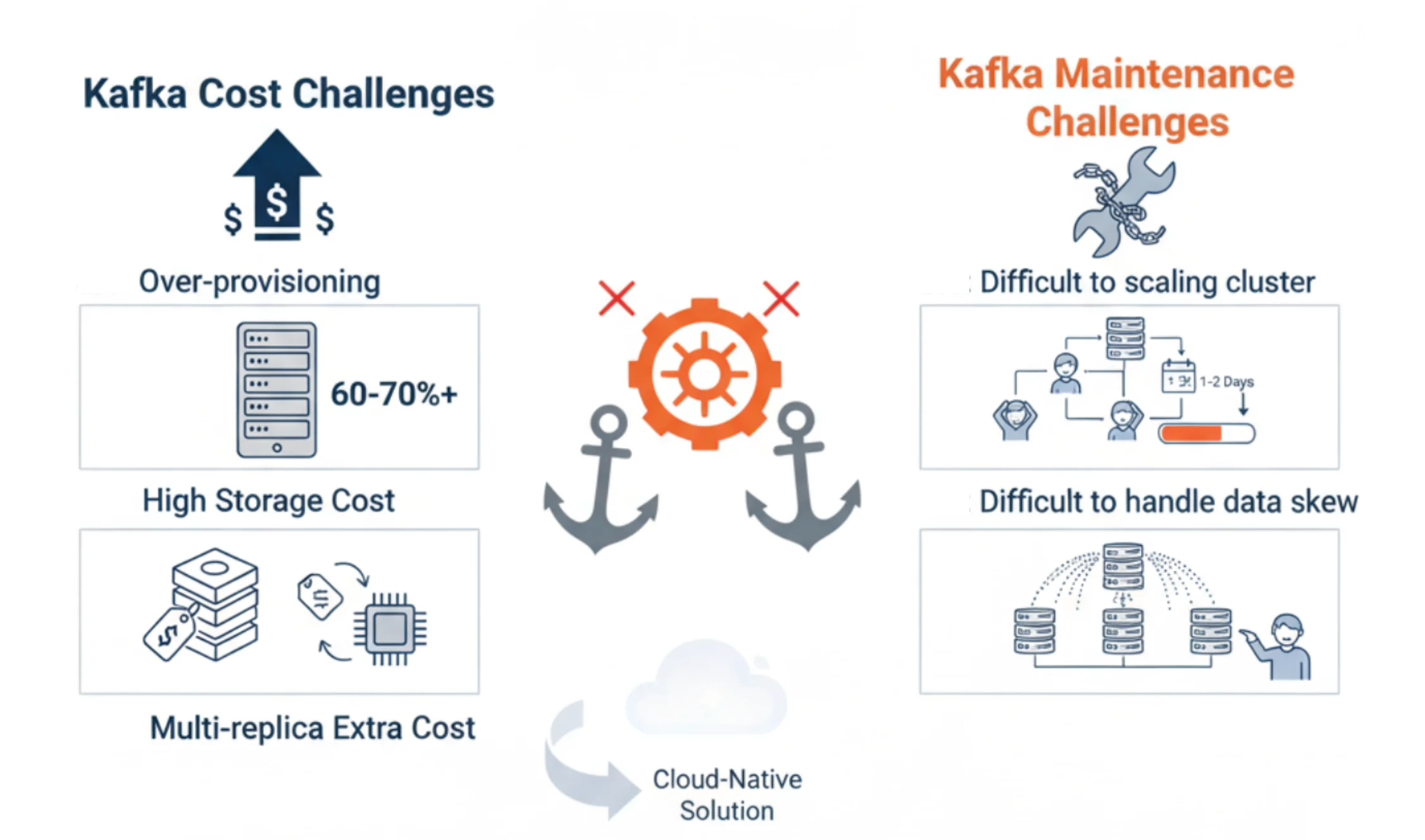
As TME's applications like QQ Music and Kugou Music continued their high-speed growth, data volumes scaled exponentially. Consequently, the Kafka clusters, serving as the central hub for all data streams, faced increasingly severe challenges. These challenges were primarily concentrated in two key areas: cost and operations.
Mounting Cost Pressures
At TME's scale of business, Kafka's cost issues became particularly prominent, manifesting in the following areas:
-
High Costs fromResource Overprovisioning: Due to Kafka's coupled storage and compute architecture, cluster resources for compute and storage must be scaled in lockstep. To accommodate peak business traffic, the resource reservation watermark in the production environment often needs to be maintained at 30%-40%, or even higher. This means a significant amount of server resources remains idle most of the time, resulting in substantial waste.
-
Persistently High Storage Costs: To guarantee data TTL (Time-To-Live) and high-concurrency read/write performance, Kafka broker nodes typically require multiple large-capacity, high-performance local disks. Expensive storage media and extensive resource reservation jointly drive up the cluster's Total Cost of Ownership (TCO).
-
Extra Overhead from the Multi-Replica Mechanism: While Kafka's built-in multi-replica mechanism ensures high data reliability, it introduces additional CPU overhead on the broker nodes during partition data synchronization. This not only increases resource consumption but also places higher demands on machine specifications, indirectly leading to rising hardware costs.
High Operational Costs
Under the traditional Kafka architecture, the operations team faced immense challenges, particularly in cluster elasticity and routine maintenance.
-
Scaling Operations are Disruptive and Labor-Intensive: As the business grows, cluster scaling is a common occurrence. However, Kafka's scaling process is cumbersome and lengthy. Business units must first submit and await approval for an expansion request. The operations team then has to wait for off-peak hours to perform the operation to avoid impacting online services. The most time-consuming part of this process is the partition data migration, which generates significant network and disk I/O and takes a vast amount of time. Furthermore, team members must dedicate considerable effort to verifying that traffic is correctly and evenly balanced onto the new broker nodes. The entire scaling process typically takes about a full day to complete, relies heavily on manual intervention, and is both time-consuming and risky.
-
Handling Data Hotspots is Difficult: Beyond planned scaling, when unexpected data hotspots occur, the operations team must also intervene manually. This involves adjusting producer-side write strategies to distribute the traffic and prevent a single broker or partition from becoming overloaded. This manual approach is not only slow to respond but also complex to execute, introducing potential risks to system stability.
These persistent cost and operational difficulties placed a heavy burden on the Kafka operations team and became a bottleneck restricting the further development of the data infrastructure. Consequently, the search for a next-generation Kafka solution—one that was more elastic, cost-effective, and operationally friendly—was put on the agenda.
Why We Chose AutoMQ
When evaluating next-generation Kafka solutions, our team had several clear objectives. After in-depth technical research and comparison, we concluded that AutoMQ was the solution best positioned to meet our current and future needs.
-
Solving Operational Bottlenecks with Rapid Elasticity: Our biggest pain point was the inefficiency and high risk of scaling traditional Kafka. AutoMQ's storage-compute separated architecture transforms brokers into stateless nodes, with data residing in object storage. For us, the most immediate benefit is that partition migration can be completed in seconds. Cluster scaling no longer requires lengthy data rebalancing. The entire process can be automated, cutting down a manual operation that used to take one or two days to just a few minutes, dramatically improving our operational efficiency.
-
Achieving Architectural Cost Reduction While Ensuring Stable Performance: Cost was another core consideration. AutoMQ's architecture allows us to scale compute and storage resources independently. This means we no longer need to over-provision expensive compute instances to handle peak traffic. At the same time, moving data from local disks to much cheaper object storage directly reduces storage overhead. This architectural change addresses the cost problem at its root, rather than just applying a minor fix.
-
Truly Kubernetes-Native: Our infrastructure is in the process of fully embracing Kubernetes. The stateful nature of traditional Kafka makes it difficult to fully leverage the advantages of Kubernetes in resource scheduling and fault recovery. AutoMQ's stateless brokers, however, work perfectly with Kubernetes and can be scheduled freely just like any other application. This paves the way for us to migrate our entire Kafka service to K8s in the future, helping to maximize resource utilization.
-
Native Iceberg Support Simplifies Data Lake Ingestion: One of our future data platform plans is to build a streaming data lake based on Apache Iceberg. AutoMQ's forward-thinking design in this area was a significant bonus. Its "Table Topic" feature can directly stream topic data into the Iceberg table format and store it in object storage. This means we can eliminate the need for a separate Flink or Spark job for data transformation and ingestion, significantly simplifying our data stack's architecture and maintenance costs.
-
A Smooth and Seamless Migration Path: The biggest risk in replacing core infrastructure is the migration process itself. AutoMQ's promise of 100% Kafka protocol compatibility was crucial. It meant that all our existing producer and consumer application code would require zero changes. Furthermore, the monitoring, operational, and security facilities we've built over the years could also be integrated seamlessly. This provided us with a low-risk, low-cost migration plan, which was the fundamental guarantee for the project's successful implementation.

Evaluation and Migration Process
For such a critical infrastructure upgrade, a rigorous, phased evaluation and migration plan was essential. Our goal was to ensure that AutoMQ's stability, performance, and compatibility would meet or even exceed our expectations under real-world production loads. The entire process was divided into two distinct phases: load validation and production migration.
Load Validation Phase
We designed two typical business scenarios to stress-test AutoMQ, covering our primary load models:
-
June 2025 - High-Throughput Scenario Validation: We first launched a cluster to handle high data throughput with relatively low QPS (Queries Per Second). The purpose of this test was to validate AutoMQ's performance and stability in handling massive, sustained data writes and reads, paying special attention to its network I/O and object storage interactions.
-
July 2025 - High-QPS Scenario Validation: Next, we deployed a second cluster to handle a high-QPS business workload characterized by small individual message sizes. This scenario focused on testing AutoMQ's performance limits in managing high-frequency metadata requests, client connection management, and its small I/O aggregation capabilities.
During these two months, we conducted a comprehensive evaluation of AutoMQ using various constructed test loads. The results were clear: AutoMQ demonstrated excellent stability across all stress scenarios, and its key performance indicators, such as throughput and latency, fully met our production environment requirements. This gave us the confidence to officially begin the production migration.
Production Migration Phase
Starting in August 2025, we formally began migrating our production business traffic to AutoMQ. Thanks to AutoMQ's 100% compatibility with the Apache Kafka protocol, the entire process was exceptionally smooth and completely transparent to our business units, requiring no additional development or adaptation on our part.
We followed a standard three-step procedure to ensure zero data loss and uninterrupted service:
-
Switch Producers: We first modified the producer client configurations, pointing their bootstrap servers to the new AutoMQ cluster. This was carried out via a rolling update, allowing online traffic to be smoothly rerouted as new data began to flow continuously into AutoMQ.
-
Drain the Old Cluster: After all producers were switched, the old Kafka cluster stopped receiving new data. We kept the consumers running on the old cluster until they had processed all the backlogged historical data.
-
Switch Consumers: Once we confirmed the old cluster was fully drained, we performed another rolling update to modify the consumer client configurations, pointing them to the new AutoMQ cluster. The consumers were configured to start from the earliest available offset in the new cluster, ensuring a seamless transition and maintaining data processing continuity.
Deployment and Results
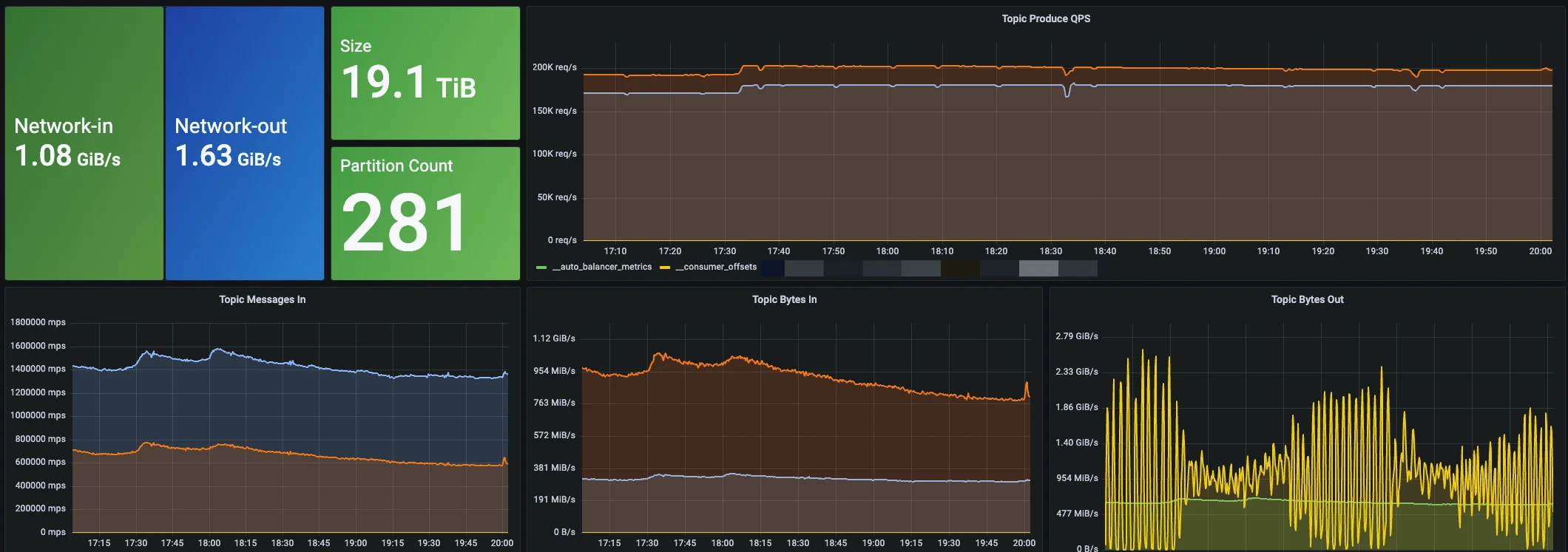
Following a smooth migration, AutoMQ is now running stably in our internal environment, handling core production traffic. To date, we have launched a total of six AutoMQ clusters, supporting a combined peak write throughput of 1.6 GiB/s and a peak QPS of approximately 480K.
To provide a more intuitive look at its operational performance, the following diagram shows a monitoring overview of one of our larger production clusters:
After migrating to AutoMQ, we achieved significant benefits that perfectly resolved the core pain points we had experienced with traditional Kafka.
-
Drastic Cost Reduction: The most direct and significant benefit came from cost optimization. AutoMQ's innovative storage-compute separated architecture fundamentally solved the cost issues caused by traditional Kafka's bundled resources. We no longer need to over-provision compute resources for peak traffic, and by persisting data to object storage, we have also dramatically reduced storage overhead. Factoring in savings from both compute and storage, TME's average Kafka cluster costs have been reduced by over 50%.
-
Gaining "Near-Instant" Rapid Elasticity: The scaling challenges that previously plagued our operations team are a thing of the past with AutoMQ. Since adding new broker nodes no longer requires time-consuming data migration, the entire process has become exceptionally fast. Leveraging AutoMQ's snear-instant partition migration and its built-in self-balancing mechanism, we can now smoothly add 1 GiB/s of throughput capacity to a cluster in just tens of seconds. This extreme elasticity means we can confidently handle any sudden surge in business traffic, providing a solid and flexible infrastructure guarantee for TME's future growth.

Future Outlook
Looking back on this technological upgrade, AutoMQ's performance in TME's production environment has been impressive. Whether it's the stability under high loads, the excellent performance metrics, or the tangible results in cost reduction, efficiency gains, and operational simplification, it has fully met and even exceeded our operations team's expectations. This successful implementation has validated the immense value of AutoMQ's cloud-native architecture in the Kafka streaming domain.
Based on this success, we have established a clear roadmap for future evolution, which we will pursue in order of priority:
-
Full-Scale Migration of Remaining Clusters: We will accelerate the migration of our remaining Kafka clusters. The plan is to move all clusters serving our full-scale observability and multi-dimensional analytics services to AutoMQ, maximizing cost benefits and unifying our operational systems.
-
Implementing Stream-to-Lake Ingestion: In terms of data architecture evolution, we will begin implementing AutoMQ's Table Topic feature. By fully leveraging its native support for Iceberg, we will build a more concise, efficient, and real-time stream-to-lake ingestion pipeline, providing stronger support for our high-level data analytics services.
-
Standardizing and Promoting AutoMQ: We plan to establish AutoMQ as a standardized infrastructure component within TME. We will actively promote its adoption in a wider variety of business scenarios, allowing more business lines to benefit from the extreme elasticity and low-cost advantages of the new architecture.
-
Moving Towards a Full Kubernetes-Native Deployment: Finally, leveraging AutoMQ's innately stateless and cloud-native characteristics, we will begin exploring and implementing the migration of our entire Kafka service to Kubernetes. This will help us further enhance the automation and overall utilization of our resources, driving TME's data infrastructure toward a fully cloud-native future.


