Running Kafka on AWS isn’t just about throughput or uptime; it’s about cost control. As data volumes grow, the bill for Amazon Managed Streaming for Apache Kafka (MSK) often scales faster than expected. Each message stored, every broker kept online, and every byte crossing an Availability Zone adds up.
MSK simplifies operations but hides complex economics. You pay for compute hours, storage, and network traffic, even when workloads fluctuate. For teams that over-provision to stay safe, this means paying for idle capacity most of the month.
Understanding where that money goes is the first step to optimizing it. In this guide, we’ll break down how MSK pricing works, which factors drive cost, and how to lower them without sacrificing reliability.
And for organizations exploring alternatives, we’ll also look at how AutoMQ helps teams cut cloud streaming costs dramatically while keeping the same developer experience.
Key Takeaways
-
MSK pricing grows fast because of its architecture, constant brokers, replicated storage, and cross-AZ traffic.
-
Cost optimisation helps, but long-term savings are limited by Kafka’s design assumptions.
-
AWS charges accumulate through broker hours, EBS storage, and data transfer; understanding these layers is crucial for control.
-
AutoMQ, fully Kafka-compatible, removes those structural costs by using shared cloud storage instead of local disks.
What Is Amazon MSK and Its Pricing Structure
Amazon Managed Streaming for Apache Kafka (MSK) is AWS’s managed Kafka service. It removes the operational burden of deploying, scaling, and patching Kafka clusters, but not the cost complexity behind them.
MSK pricing is built on three core dimensions: brokers, storage, and data transfer.
-
Broker cost – You pay hourly for each broker instance. The instance type and region define the rate. For example, an m7g.large broker costs roughly $0.15–$0.20 per hour in most US regions. Larger brokers multiply that quickly.
-
Storage cost – Charged per GB-month for the data retained in Kafka topics. The default EBS storage costs around $0.10 per GB-month, increasing with replication.
-
Data transfer – Inbound traffic is free, but cross-AZ replication and outbound data trigger standard AWS data transfer fees.
If you use MSK Serverless, pricing shifts from infrastructure to usage:
-
Cluster hours ($0.75/hr)
-
Partition hours ($0.0015/hr)
-
Data in/out ($0.10/GB in, $0.05/GB out)
The result is flexibility for variable workloads, but still significant cost accumulation for sustained traffic or large retention windows.
MSK simplifies Kafka operations, yet its pricing layers often behave like hidden multipliers; small inefficiencies can compound into thousands per month.
Cost Drivers and Hidden Expenses in MSK Setups
MSK pricing looks straightforward, but the real cost hides in how Kafka runs under the hood. Most teams discover the overspend only after production scales.
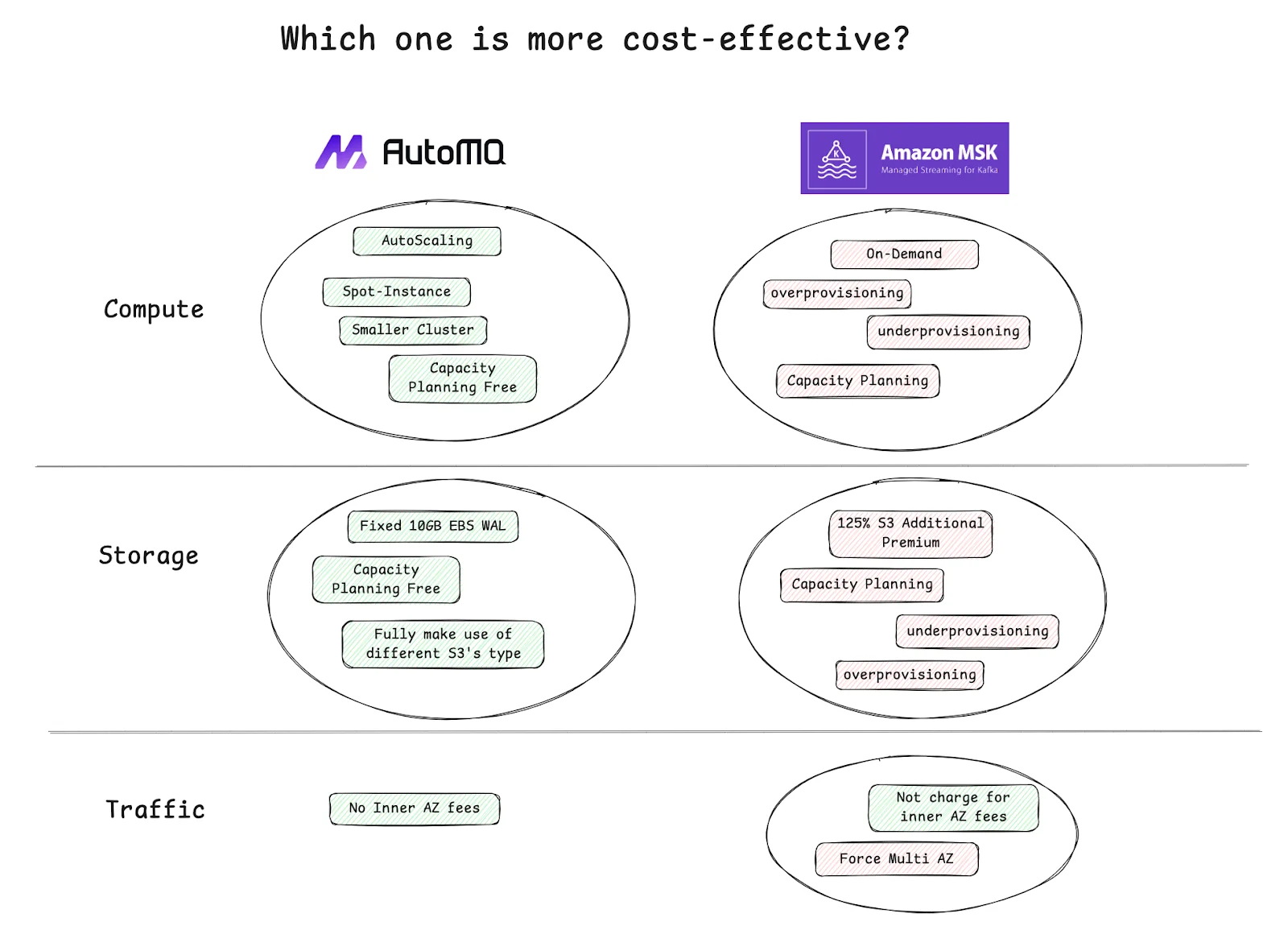
Over-provisioned Brokers
Kafka workloads spike unpredictably. To avoid throughput drops, engineers reserve extra brokers. Those brokers stay mostly idle, yet AWS charges full hourly rates. A 10-broker cluster scaled for peak traffic might sit at 30 % utilization for weeks.
Storage Growth and Retention
Kafka’s strength is data retention, but MSK charges for every retained byte. With replication factors of three, 1 TB of topic data can consume 3 TB of paid storage. Long retention policies multiply that cost quietly over time.
Cross-AZ Replication Traffic
Each replica written across Availability Zones incurs standard AWS network fees. For heavy workloads, this line item can exceed 50 % of the total MSK bill.
Scaling Complexity
Adding or shrinking brokers in a provisioned MSK cluster isn’t instantaneous. To maintain balance, clusters often stay oversized, consuming unnecessary compute and storage.
Serverless Overhead
Serverless MSK avoids fixed brokers, but pricing per partition-hour and data volume can grow faster than expected for steady traffic.
In short, MSK cost grows not from one factor, but from architecture inertia . Kafka’s design assumes stable, always-on resources; in the cloud, that assumption turns into persistent spend.
How to Optimise MSK Cost
Cutting MSK cost starts with visibility. Once you know what drives spend, small architectural shifts make a big impact.
Right-size Your Brokers
Review throughput metrics regularly. If CPU or network stays below 50 %, scale down. Choose Graviton-based brokers (m7g or r7g), AWS reports up to 24 % lower cost and 29 % higher throughput for the same workload.
Adjust Retention Policies
Retention defines how long Kafka keeps messages. A 7-day policy might be enough for most analytics streams. Every extra day multiplies storage and replication cost. Align retention with real business recovery needs, not habit.
Rebalance Storage Tiers
Older messages rarely need SSD speed. Use smaller EBS volumes or reduce the replication factor on non-critical topics. Monitor broker disk usage to prevent automatic over-provisioning.
Minimise Cross-AZ Traffic
Co-locate producers and brokers in the same Availability Zone when possible. Each cross-AZ replica adds network charges that MSK doesn’t discount.
Consider Serverless for Bursty Workloads
If traffic fluctuates sharply, MSK Serverless can reduce idle time costs. But for steady 24/7 traffic, provisioned clusters still win.
Use AWS Cost Tools
Enable Cost Explorer and CloudWatch metrics to spot wasted capacity early.
Optimisation isn’t about trimming performance, it’s about aligning infrastructure with reality. Right-sized clusters maintain throughput while turning unused capacity into direct savings.
When It Might Be Time to Consider an Alternative
Even after careful tuning, MSK costs often stay stubbornly high. That’s because the pricing model reflects Kafka’s original design, long-running brokers, local disks, and multi-replica writes. In a cloud environment, that rigidity turns into overhead you can’t fully optimise.
If your Kafka bill keeps climbing despite right-sizing, it’s time to look at alternatives built for the cloud era. One such option is AutoMQ, a 100 % Kafka-compatible platform designed to cut the underlying structural costs that MSK inherits.
AutoMQ keeps the Kafka experience intact, same API, same ecosystem tools, but changes how storage and compute behave. Instead of locking data to broker disks and paying for idle replicas, it offloads persistence to object storage like Amazon S3. That simple shift removes the need for cross-AZ replication and the EBS storage footprint that drives most MSK bills.
For teams running multi-region or high-retention pipelines, these design choices translate directly into cost savings. You don’t rewrite applications. You just stop paying for architectural inefficiency.
When cost, elasticity, and simplicity start outweighing the comfort of “managed,” AutoMQ becomes worth a close look.
High-Level Cost-Comparison (MSK vs AutoMQ)
Understanding MSK pricing is easier when you see what changes with a different architecture. AutoMQ doesn’t just reduce rates; it removes entire cost categories that MSK cannot.
Here’s a simplified view of the difference:
| Cost Component | AWS MSK (Provisioned) | AutoMQ (Kafka-Compatible) |
|---|---|---|
| Broker Cost | Always-on EC2 instances are billed hourly | Stateless brokers scale up or down in seconds |
| Storage Cost | EBS is charged per GB-month × replication | Object storage (e.g., S3) billed once, no replication overhead |
| Network Cost | Cross-AZ replication incurs AWS data transfer fees | Shared storage removes cross-AZ traffic |
| Scaling Cost | Manual partition rebalancing; hours to expand | Instant metadata scaling; seconds to expand |
| Operational Overhead | Constant capacity planning and patching | Fully automated elasticity and balancing |
In one benchmark published by AutoMQ, running a 1 GiB/s Kafka workload cost $226,671 per month on AWS. The same workload on AutoMQ costs $12,899, a 17× reduction. These figures include broker, storage, and data-transfer costs under equivalent throughput.
JD.com’s production case shows similar results: 50 % lower storage cost, 33 % less bandwidth cost, and scaling time reduced from hours to minutes.
AutoMQ doesn’t make Kafka cheaper by discounts; it changes the underlying cost structure that makes Kafka expensive in the cloud.
Considerations Before Migrating or Switching
Switching from MSK to a new Kafka-compatible platform is a shift in how your data infrastructure operates. Before you act, weigh these points carefully.
Compatibility and Tooling
AutoMQ is fully Kafka API compatible, which means producers, consumers, and ecosystem tools, like Kafka Connect, Schema Registry, and Strimzi Operator, continue working without code changes. Still, test critical workloads in a pilot to confirm behavior under your retention and latency settings.
Migration Planning
Moving large clusters requires coordination. Use phased migration, start with low-risk topics, and expand once metrics confirm stability. Verify data offsets, consumer lag, and monitoring integrations early.
Operational Model
AutoMQ offers both BYOC (Bring Your Own Cloud) and Software options. Decide if you want full control or a managed setup within your own VPC. This impacts governance, compliance, and support workflows.
Performance and Workload Fit
Latency-sensitive applications may require tuning or the use of acceleration storage (e.g., EBS as WAL). Batch or analytics pipelines, on the other hand, benefit immediately from AutoMQ’s diskless scaling and S3-based storage.
Cost Verification
Model costs using your actual throughput, retention, and replication needs. The 10× savings figure is real in many cases, but it depends on traffic shape and data retention patterns.
Final Words
AWS MSK delivers the convenience of managed Kafka, but that convenience comes with a cost that scales quickly. Brokers, storage, and cross-AZ traffic create a pricing model that grows faster than most teams expect.
Optimising helps: right-sizing, trimming retention, and monitoring usage can all slow the climb. Yet for many organisations, MSK’s architecture itself limits how far costs can fall.
That’s where AutoMQ offers a new direction. It keeps the Kafka experience intact but redefines how it runs in the cloud, no disks, no replica overhead, no inter-zone traffic. Users like JD.com have shown that these changes can translate into real-world savings and faster scaling.
Understanding MSK pricing is about recognising when the model no longer fits your workload. And when that point comes, a Kafka-compatible alternative like AutoMQ may not just cut costs; it can reshape how your data streaming platform operates.
Still struggling with skyrocketing Kafka bills and the "ops tax" of manual disk management? It's time to stop babysitting your clusters. Try AutoMQ Cloud for Free and experience how diskless architecture slashes costs and automates scaling—no credit card required. See how others made the switch in our case studies or explore the project on GitHub.


